
- 1Python实现多任务
- 2java transactions数组_java里面Transaction transaction = (Transaction)(list.get(i));是什么意思...
- 3OS-鸿蒙系统-以及编译器_鸿蒙系统编译器
- 4纯血鸿蒙(HarmonyOS 3.1/4.0)入门教程 未完待续......
- 5Python+unittest+requests接口自动化测试框架搭建 完整的框架搭建过程_python接口自动化框架
- 6latex学习笔记——tikz画图 激活函数图像_latex画函数图像
- 7oracle中的row_number,oracle中rank() over与row_number()的区别
- 8如何删除github中已经被追踪的文件
- 9Windows10使用命令行打开3389_Winux之路-WSL 2的使用及填坑
- 10【unity知识点】Unity 协程/携程Coroutine_unity携程
大数据自学指南_spark大数据分析入门
赞
踩
大家好,我是脚丫先生 (o^^o)
最近和小伙伴们交流。
有刚刚毕业的老弟陷入培训机构交2w无法自拔,有刚刚考上研的师弟大数据学习无从下手,有想转方向大数据行业的老哥…

互联网时代,知识就像浩瀚的海洋,无边无际且波涛汹涌。
回首自己自学大数据开发之时,又何尝不是呛了无数口海水。
古之学者必有师,于是趁着闲暇之时给小伙伴们梳理大数据自学指南。
前言
我读研的时候,老板放羊的,而这正合我意。
于是乎,我就拥有了无穷无尽的自学时间 !
任何自学,刚开始都会稍微迷茫,但是当你真正投入进去学习时,会发现时间总不够用。
激励自己的一句话:一行行代码能否转变成一叠叠rmd,就是靠:坚持,敲代码;敲代码,坚持;坚持!
这句话不断的鞭策着我,致使毕业之际获得了多个大数据offer。
一、编程语言阶段学习
在IT这一行,任何技术最基本就是编程语言。
如果是零基础的话,建议还是从视频开始入门比较好。
古之学者必有师,而没人说古之学者必有书。视频通过听觉和色彩丰富的视觉传递信息,比书本单一的黑白视觉信息能让学习者更易于接收。
同时,视频讲师在讲课的时候,会把自己的理解传授、灌输给你。站在"巨人"的肩膀上,学起来会快上许多。
毋庸置疑,Java是大数据学习的编程语言。
我从来不是一个聪明的人,高考废了九牛二虎之力才考上了一个普通二本。
忆往昔,刚刚本科毕业的自己,毫无一技之长,唯一的优点就是坚持+无效勤奋。
时至今日,JAVASE我建议小伙伴们选择B站的尚硅谷康师傅–>尚硅谷Java入门视频教程(在线答疑+Java面试真题)
康师傅的JAVASE基础是真滴强,觉得他讲的真的是很好很详细,每个知识点都会有例子,也都会带你敲代码,做测试。更重要的是每一个知识点比喻都很恰当,听了不仅能学习也能快乐乐,所谓:乐中学,学中乐。
视频不要贪多,一份最为经典的视频反复看,反复思考更为重要,我们不仅要学会知识,更重要的是学会面向百度解决问题的能力。
如果有一定基础的小伙伴,建议直接上书,加快速度到下一个阶段。
我推荐的入门书籍是java第一行代码,这本书我看过很多遍,每一知识点都有二维码扫一扫看视频讲解,是非常不错的,当然也可以康师傅和java第一行代码一起卷。
编程基石JavaSE,可以说是很重要的基础,主要重点包括面向对象、集合(List、Map等),IO流,String/StringBuilder/StringBuffer、反射、多线程,网络编程,这些最好是都要熟悉一些,这是重点。
二、 Linux阶段学习(基本操作)
大数据的集群基本都是基于Linux系统进行部署的,而能熟练操作大数据集群,能熟练搭建大数据集群是大数据的必备技能。
可想而知,Linux的基本命令小伙伴们必须掌握,退一步说,必须要熟悉基本操作命令。
再强调一遍,基本操作命令尽量熟练一点,如果一下记不住,打印一些常用的,自己看看,多用多实践,慢慢就会用了。
尚硅谷真滴是业界良心!!!让天下没有难掉的头发!(玩笑话)
依然推荐:3天搞定Linux,1天搞定Shell,清华学神带你通关
武老师的视频,江湖人称武神,清华才子。我想不必过多介绍,清华二字说明一切。
让我想起了,武林至尊,宝刀屠龙,号令天下,莫敢不从!
在学习Linux的基本命令时候,不需要太过于的深入,只需要知道有这个么个命令,会用即可,过多的深入对于刚出道的你,毫无意义。
三、大数据阶段学习
很兴奋,在经过了JavaSE和Linux学习之后,我们成功来到了大数据阶段,也终于走入了正题。
也许,此时的你,对大数据很懵懂,也很神秘。不要慌,我带你卷下去…
首先我们要明白,大数据技术是干嘛的?
解决大量数据的存储和计算问题。
那么我先带小伙伴们,极速了解大数据技术生态圈。
我在公众号写一篇**一文看懂大数据的技术生态**的文章,看不懂你捶我!!!
此文,高度的带你了解大数据技术生态圈,不管你悟不悟,我肯定是悟了。
在此,进行总体概况下:
欲练大数据技术,必先了解其大数据处理流程。
最终目的就是解决大量数据存储和计算问题。
首先给出一个通用化的大数据处理框架,主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。

数据采集:这是大数据处理的第一步,数据来源主要是两类,第一类是各个业务系统的关系数据库,通过Sqoop或者Cannal等工具进行定时抽取或者实时同步;第二类是各种埋点日志,通过Flume进行实时收集。
数据存储:收集到数据后,下一步便是将这些数据存储在HDFS中,实时日志流情况下则通过Kafka输出给后面的流式计算引擎。
数据处理:这一步是数据处理最核心的环节,包括离线处理和流处理两种方式,对应的计算引擎包括MapReduce、Spark、Flink等,处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
数据应用:包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
通过上述的内容,我们看到了大数据技术组件的组合使用,形成了一个大数据平台。
献上大数据技术组件图:
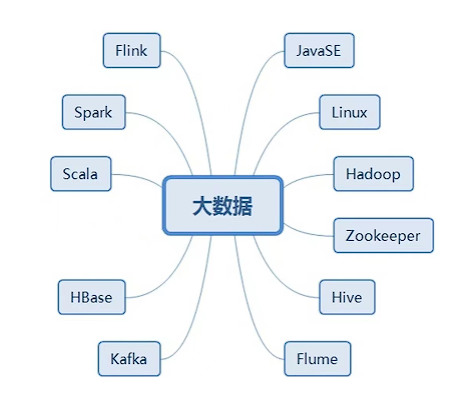
这么多大数据组件,要每个都很知根知底,是很难的,我建议小伙伴们,重点抓住Hadoop和Flink组件,深入在深入。
其他组件会用,明白其原理即可。
四、Hadoop(重点中的重点)

Hadoop是一个分布式系统基础框架,用于主要解决海量数据的存储和海量数据的分析计算问题,也可以说Hadoop是后续整个集群环境的基础,很多框架的使用都是会依赖于Hadoop。
在此依然是推荐尚硅谷的视频,只因IT挖掘这家最强
尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)
老师是江湖人称的海哥。
这套视频从基础->实战案例->调优。应有尽有,无愧于真正的海王。
这部分小伙伴们一定要自己动手实践,自己搭建集群,仔细仔细再仔细,一定要跟着部署集群,也许你会遇到和海哥不一样的问题,可以面向百度锻炼自己的搜索能力,也可以在视频评论区看看其他小伙伴们有没有遇到类似的。
五、Hive(重点)

Hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
它在Hadoop的生态家族中占有及其重要的地位,并且实际的业务当中用的也非常多,可以说Hadoop之所以这么流行在很大程度上是因为Hive的存在。
特别是针对离线数据仓库业务来说,基本都是在以hive为基础,进行分层设计,辅以调度系统,从而完成整个数据仓库业务的定时执行。
这个组件非常重要,依然是尚硅谷的视频,只因是最新版视频讲解。
尚硅谷大数据Hive教程(基于hive3.x丨hive3.1.2)
这套视频从概念到安装,直至实践案例应有尽有。
理论结合实践去学习往往是高效的,因为教员都曾经说过,检验真理的唯一标准就是实践。
在此,想快速了解Hive的小伙伴,也可以看我公众号写的一篇<<Hive快速学习指南>>
六、Zookeeper

Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。
小伙伴们能懂原理和使用命令工具去操作Zookeeper。
同时,知道它的应用场景即可。
尚硅谷的视频:
七、Flume

Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。
也是一个比较重要的大数据组件,我们要学习该组件的学习组成架构,以及对Flume Agent的内部原理要理解清楚,Source、Channel、Sink一定要知道它们的各种类型以及作用。
特别是它的配置参数,记是记不住的,在需要进行参数配置的时候,可以参看官网。
视频教程:在此推荐的是
老师是汪辉老师,结合官网案例进行讲解,声音洪亮且易懂。
八、Kafka(重点)

Kafka是一个分布式消息队列,用来缓存数据的。
可以理解为:一堆馒头,你全部一起吃,肯定噎死你。所以你选择把所有馒头放在一个篮子里,你想吃的时候,就去篮子里拿一个吃。
Kafka就好比篮子。
在实际场景中:比如说实时计算中可以通过Flume+Kafka对数据进行采集处理之后,数据全部缓存在kafka里,Spark Streaming再从Kafka中获取数据,用于后续的计算使用。
对于Kafka而言,小伙伴要理解Kafka的架构,什么是Kafka,为什么需要Kafka,应用场景。
基本的命令行操作要掌握,比如怎么创建删除Topic,怎么通过生产者生成数据,消费者怎么消费数据等基本操作。
视频教程:2022版Kafka3.x教程(从入门到调优,深入全面)
该视频很好用,敏感肌也能用。
我都是推荐小伙伴尚硅谷的视频,虽然我也不想,但是视频教程真的强大且免费,你们要忍住。
九、Hbase(重点)

HBase 是一种构建在HDFS 之上的分布式、面向列族的存储数据库。
它适合存储半结构化或非结构化数据,对于数据结构字段不够确定或者杂乱无章很难按一个概念去抽取的数据。
在需要实时读写并随机访问超大规模数据集等场景下, HBase目前是市场上主流的技术选择。
它是一个非常重要的组件,小伙伴们一定要详细学习,从原理,架构,RowKey设计等,都需要掌握。
视频教程:
HBase2.x教程(2022新版,一套全面掌握hbase)
小伙伴们,要认真学,根据视频教程,学出自己的效果。
白嫖也要嫖出境界。
十、Spark

1、Scala语言
学习Scala语言,主要是为了后面学习Spark组件的一个基础。
因为Spark组件源码就是Scala,所以Scala语言的重要性不言而喻。
Scala语言非常适合迭代式计算,对数据处理有很大帮助,一般链式编程简单的几行代码就能实现需要的功能。
学习Scala的建议:
-
学习scala基本的语法。
-
搞清楚scala和java区别。
-
了解如何规范的使用scala。
Scala对学习Spark是很重要的,虽然现在很多公司还是用Java开发比较多。
但是离线开发利用SparkSQL的时候,去学习Scala还是很有帮助的。
当然也为之后利用Scala快速学习Flink打下一个重要基础。
视频教程:
大数据技术之Scala入门到精通教程(小白快速上手scala)
该课程由清华才子,武老师所讲,质量上不必多说了。
免费高质量,尚硅谷让天下没有学得完的技术!!!
2、Spark(重点)
Spark是基于内存计算的大数据框架,其速度远远超过了之前的MapReduce。
在我们学习Hive的时候,针对数据的分析统计就感觉很慢,犹如蜗牛蛮的速度,让人抓狂。
那么我们必须要提提速度,于是就有了基于内存迭代式计算的Spark。
最强视频教程:
该视频教程基于Scala 2.12版本,对Spark3.0版本的核心模块进行了详尽的源码级讲解,授课图文并茂,资料详实丰富,带你领略不一样的技术风景线。
扶我起来。。。。我还可以。。。。
十一、Flink(重点中的重点)
Flink是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入。
对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。
在Flink的概念中,数据分为有界(有开始有结束)和无界(有开始无结束),因此Flink既可以处理有界的批量数据集,也可以处理无界的实时流数据,为批处理和流处理提供了统一编程模型。
以至于现在越来越多的公司已经都用Flink了,相对于Spark而言,这才是正真意义上的流处理组件。
视频教程
2022版Flink1.13实战教程(涵盖所有flink-Java知识点)
这套视频真的是强的离谱,我看了不下两遍。
个人而言,非常喜欢。(明天入职美团,一单3块)
项目阶段
大数据项目来说,我个人不建议东西南北的找项目做或者收藏。
一个项目没有搞透彻,只是面向视频编程,就假装学完了,这是没有任何意义的。
以我个人多年大数据经验而言,选择一个综合性的项目,搞懂搞透彻,并且进行扩展。
自己不停的进行项目的优化和改进。
把一个基本的项目,加入自己的思想,做成真正属于自己的项目。
我相信,你一定会有质的提升!!!
1)尚硅谷数仓项目V4.0
链接:https://pan.baidu.com/s/19WzlJfZT5HJPhXW7VdRf8g
提取码:yyds
- 1
- 2
2)flink1.12实时数仓项目15天版
链接:https://pan.baidu.com/s/1v7APvcNeGGVRqzN2sPEMxA
提取码:yyds
- 1
- 2
3)基于阿里云搭建离线数仓
链接:https://pan.baidu.com/s/1UI_adJkzu6nkCkddnCPerg
提取码:yyds
- 1
- 2
4)大数据进阶实战dmp广告系统
链接:https://pan.baidu.com/s/1pA2D4KSLkiOr34QLLV1tkw
提取码:yyds
- 1
- 2
5)大数据企业级项目用户画像实战
链接:https://pan.baidu.com/s/1Vm4vlVtWnFZH6dlP6zJ2xg
提取码:yyds
- 1
- 2
6)离线+实时全栈数仓项目-智数电商
链接:https://pan.baidu.com/s/1yWY074ySVIEkcFaR1BdjMA
提取码:yyds
- 1
- 2
7)千亿级数仓
链接:https://pan.baidu.com/s/1AWJU-DOC7C6hcDwCm5Gkmw
提取码:yyds
- 1
- 2
8)手把手从零搭建新冠疫情防控指挥作战平台
链接:https://pan.baidu.com/s/1xhE9vQrDD56GSLq9IYDN_Q
提取码:yyds
- 1
- 2
书籍
大数据方面的书籍,我主要以平台和架构为主。
因为大数据所有的组件,都是围绕这大数据平台,离线和实时两条线进行服务的。
对于大数据组件的书籍,我想小伙伴直接把每个大数据组件视频弄懂即可,没必要贪多。
精选大数据书籍
链接:https://pan.baidu.com/s/1Xr1wydRhEKkmd6g579VO2Q
提取码:yyds
- 1
- 2
面试
大数据笔面试套装(大量面试题+面试技巧+大数据简历模板)

链接:https://pan.baidu.com/s/1WdT6S91xx18Tm9W_GuDbSw
提取码:yyds
- 1
- 2
小伙伴们,也可以微信加我,单独分享自己整理的面试题给你。
最后
大数据开发这些组件固然很重要,但是内功的修炼也是同样重要的。
数据结构与算法,计算机网络,计算机组成原理,操作系统,这些基础知识也有助于自己以后的发展。
如果是应届生校招的话,面试基本上都是JavaSE和数据结构与算法等的知识点,还有大数据组件相关的知识点,以及对项目的理解,这些都是要自己面试前准备好的,多看面经,多找面试题看,多理解的去记忆八股文面试题,争取可以用自己的话去阐述。
算法也是考察的一个重点,也许你面对leetcode仿佛是一座难以攀过的大山,
因此也可以先刷完剑指Offer,让自己训练一个逻辑思维,在去征服leetcode。
剑指offer我推荐在牛客上直接刷!!!
要将一行行代码看做一叠叠rmb,但是一行行代码能不能转换成一叠叠rmb,自己就一定要:坚持,多敲代码;多敲代码,坚持;坚持。
再加一句:以上纯属个人总结,也许有理解不是很好的地方,每个人都有自己的学习方法,不喜勿喷,谢谢~
祝各位终有所成,收获满满 !


