
- 1计网——(ARP协议与DHCP协议,ICMP协议)_dhcp用了arp几次
- 2微信支付教程系列之公众号支付_binarywang 公众号支付
- 3HarmonyOS数据库之关系型数据库_rdbstore
- 4Stable Diffusion——stable diffusion基础原理详解与安装秋叶整合包进行出图测试_秋叶stable diffusion
- 5三款强大的 AI 编程工具,可以轻松替换 Github Copilot_codeium codegeex
- 6uniapp微信小程序《隐私保护协议》弹窗处理流程___useprivacycheck__
- 7wpf绘图第三方库livechart曲线颜色和宽度设置_lvgl chart的曲线宽度怎么设置
- 8【MYSQL高级篇】_mysql高级编程
- 9SVD——奇异值分解概述_奇异值衰减
- 10Java-web实现导出Excel中多个sheet以及自定义sheet格式原理_javaweb导出excel 设置多sheet格式
mysql 之分析函数 over参考 (partition by ...order by ...)_mysql over partition by
赞
踩
另:可参考MySQL开窗函数_mysql_weihuan2323-DevPress官方社区
转自:oracle 之分析函数 over (partition by ...order by ...) - 魔剑坊 - 博客园
一:分析函数over
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
1、分析函数和聚合函数的不同之处:
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
(一)、分析函数语法:
FUNCTION_NAME(<argument>,<argument>...)
OVER
(<Partition-Clause><Order-by-Clause><Windowing Clause>)
例:(在oracle示例库中演示,用户scott)
select ename,sum(sal) over (partition by deptno order by ename) new_alias from emp;
a、sum就是函数名(FUNCTION_NAME)
b、(sal)是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm)
c、over 是一个关键字,用于标识分析函数,否则查询分析器不能区别sum()聚集函数和sum()分析函数
d、partition by deptno (按相应的值(deptno)进行分组统计)是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区
e、order by ename 是可选的order by 子句,有些函数需要它,有些则不需要.依靠已排序数据的那些函数。
即:分析函数带有一个开窗函数over(),包含三个分析子句:
分组(partition by)
排序(order by)
窗口(rows)
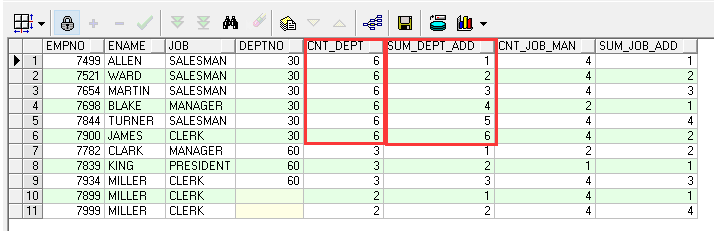
示例1:
| 1 2 3 4 5 6 |
|
(二)、FUNCTION子句
ORACLE提供了N多个分析函数,按功能分5类
Oracle分析函数——函数列表
------------------------------------------------------------------------------------------------
SUM :该函数计算组中表达式的累积和
MIN :在一个组中的数据窗口中查找表达式的最小值
MAX :在一个组中的数据窗口中查找表达式的最大值
AVG :用于计算一个组和数据窗口内表达式的平均值。
COUNT :对一组内发生的事情进行累积计数
-------------------------------------------------------------------------------------------------
RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
DENSE_RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
FIRST :从DENSE_RANK返回的集合中取出排在最前面的一个值的行
LAST :从DENSE_RANK返回的集合中取出排在最后面的一个值的行
FIRST_VALUE :返回组中数据窗口的第一个值
LAST_VALUE :返回组中数据窗口的最后一个值。
LAG :可以访问结果集中的其它行而不用进行自连接
LEAD :LEAD与LAG相反,LEAD可以访问组中当前行之后的行
ROW_NUMBER :返回有序组中一行的偏移量,从而可用于按特定标准排序的行号
-------------------------------------------------------------------------------------------------
STDDEV :计算当前行关于组的标准偏离
STDDEV_POP :该函数计算总体标准偏离,并返回总体变量的平方根
STDDEV_SAMP :该函数计算累积样本标准偏离,并返回总体变量的平方根
VAR_POP :该函数返回非空集合的总体变量(忽略null)
VAR_SAMP :该函数返回非空集合的样本变量(忽略null)
VARIANCE :如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP
COVAR_POP :返回一对表达式的总体协方差
COVAR_SAMP :返回一对表达式的样本协方差
CORR :返回一对表达式的相关系数
-------------------------------------------------------------------------------------------------
CUME_DIST :计算一行在组中的相对位置
NTILE :将一个组分为"表达式"的散列表示,创建的是等高直方图
PERCENT_RANK :和CUME_DIST(累积分配)函数类似
PERCENTILE_DISC :返回一个与输入的分布百分比值相对应的数据值
PERCENTILE_CONT :返回一个与输入的分布百分比值相对应的数据值
RATIO_TO_REPORT :该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比
REGR_ (Linear Regression) Functions :这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用
-------------------------------------------------------------------------------------------------
CUBE :按照OLAP的CUBE方式进行数据统计,即各个维度均需统计
ROLLUP :
-------------------------------------------------------------------------------------------------
示例2:查询每个部门工资最高的员工信息
1、(count,rank,dense_rank,row_number)排名函数的使用及注意事项
在使用排名函数的时候需要注意以下三点:
(1、排名函数必须有 OVER 子句。
(2、排名函数必须有包含 ORDER BY 的 OVER 子句。
(3、分组内从1开始排序。
-- 一般的写法:
SELECT E.ENAME, E.JOB, E.SAL MAXSAL , E.DEPTNO
FROM SCOTT.EMP E,
(SELECT E.DEPTNO, MAX(E.SAL) SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME
WHERE E.DEPTNO = ME.DEPTNO
AND E.SAL = ME.SAL;
-- 分析函数OVER (使用count函数用order by将相应数据分组,获取分组编号)
SELECT ENAME,JOB,MAXSAL,DEPTNO FROM
(SELECT ENAME,JOB,MAX(SAL) OVER (PARTITION BY DEPTNO) AS MAXSAL,DEPTNO,
COUNT(*) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS NUM FROM EMP)
WHERE NUM = 1;
--析函数OVER (使用rank函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
--分析函数OVER (使用dense_rank函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,dense_RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
--分析函数OVER (使用row_number函数用order by将相应数据分组,获取分组编号)
SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM
(SELECT ENAME,JOB,SAL,row_number() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E
WHERE E.RANK = 1 AND NOT deptno IS NULL;
注意事项:
一般写法与分析函数的主要区别在于:使用分析函数可以提升sql的执行效率,一般写法是通过两个或多个表关联来进行查询(存在笛卡尔积),而用分析函数则所有的查询都在一个表中实现,大大提升了sql的查询效率(主要体现于自身表的关联查询)。
row_number的用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
count函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一,count()是跳跃排序,有两个第一名时两个第一名的序号都为2,就没有第一名,有两个第二名,接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
示例3、查询员工信息的同时,查询员工工资与所在部门最低、最高工资的差额
2、(min、max)取最值函数的使用及注意事项
--一般写法
SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO,
ME.MIN_SAL MIN_SAL,
ME.MAX_SAL MAX_SAL,
E.SAL - ME.MIN_SAL DIFF_MIN_SAL,
ME.MAX_SAL - E.SAL DIFF_MAX_SAL
FROM SCOTT.EMP E,
(SELECT E.DEPTNO, MIN(E.SAL) MIN_SAL, MAX(E.SAL) MAX_SAL
FROM SCOTT.EMP E
GROUP BY E.DEPTNO) ME
WHERE E.DEPTNO = ME.DEPTNO
ORDER BY E.DEPTNO, E.SAL;
--使用分析函数:
SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO,
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL,
MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL,
NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL,
NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL
FROM EMP E;
/*注:这里没有排序条件,若加上order by 排序条件,
MAX() OVER(PARTITION BY .. ORDER BY .. DESC) 排序规则只能为desc,否则不起作用,将查询到目前为止排序值最高字段的对应值
MIN() OVER(PARTITION BY .. ORDER BY .. ASC ) 排序规则只能为asc,否则不起作用,将查询到目前为止排序值最低的字段的对应值,
如下:*/
SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO,
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL01,
MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL01,
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MIN_SAL02,
MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MAX_SAL02, --不起作用
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MIN_SAL03, --不起作用
MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MAX_SAL03,
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MIN_SAL04,
MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MAX_SAL04, --不起作用
NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL,
NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL
FROM EMP E;
oracle分析函数-----实验
--1、GROUP BY子句
--CREATE TEST TABLE AND INSERT TEST DATA.
create table students
(id number(15,0),
area varchar2(10),
stu_type varchar2(2),
score number(20,2));
insert into students values(1, '111', 'g', 80 );
insert into students values(1, '111', 'j', 80 );
insert into students values(1, '222', 'g', 89 );
insert into students values(1, '222', 'g', 68 );
insert into students values(2, '111', 'g', 80 );
insert into students values(2, '111', 'j', 70 );
insert into students values(2, '222', 'g', 60 );
insert into students values(2, '222', 'j', 65 );
insert into students values(3, '111', 'g', 75 );
insert into students values(3, '111', 'j', 58 );
insert into students values(3, '222', 'g', 58 );
insert into students values(3, '222', 'j', 90 );
insert into students values(4, '111', 'g', 89 );
insert into students values(4, '111', 'j', 90 );
insert into students values(4, '222', 'g', 90 );
insert into students values(4, '222', 'j', 89 );
commit;
--A、GROUPING SETS
select id,area,stu_type,sum(score) score
from students
group by grouping sets((id,area,stu_type),(id,area),id)
order by id,area,stu_type;
/*--------理解grouping sets
select a, b, c, sum( d ) from t
group by grouping sets ( a, b, c )
等效于
select * from (
select a, null, null, sum( d ) from t group by a
union all
select null, b, null, sum( d ) from t group by b
union all
select null, null, c, sum( d ) from t group by c
)
*/
--B、ROLLUP
select id,area,stu_type,sum(score) score
from students
group by rollup(id,area,stu_type)
order by id,area,stu_type;
/*--------理解rollup
select a, b, c, sum( d )
from t
group by rollup(a, b, c);
等效于
select * from (
select a, b, c, sum( d ) from t group by a, b, c
union all
select a, b, null, sum( d ) from t group by a, b
union all
select a, null, null, sum( d ) from t group by a
union all
select null, null, null, sum( d ) from t
)
*/
--C、CUBE
select id,area,stu_type,sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;
/*--------理解cube
select a, b, c, sum( d ) from t
group by cube( a, b, c)
等效于
select a, b, c, sum( d ) from t
group by grouping sets(
( a, b, c ),
( a, b ), ( a ), ( b, c ),
( b ), ( a, c ), ( c ),
() )
*/
--D、GROUPING
/*从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,
如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!*/
select decode(grouping(id),1,'all id',id) id,
decode(grouping(area),1,'all area',to_char(area)) area,
decode(grouping(stu_type),1,'all_stu_type',stu_type) stu_type,
sum(score) score
from students
group by cube(id,area,stu_type)
order by id,area,stu_type;
--2、OVER()函数的使用
--1、RANK()、DENSE_RANK() 的、ROW_NUMBER()、CUME_DIST()、MAX()、AVG()
break on id skip 1
select id,area,score from students order by id,area,score desc;
select id,rank() over(partition by id order by score desc) rk,score from students;
--允许并列名次、名次不间断
select id,dense_rank() over(partition by id order by score desc) rk,score from students;
--即使SCORE相同,ROW_NUMBER()结果也是不同
select id,row_number() over(partition by ID order by SCORE desc) rn,score from students;
select cume_dist() over(order by id) a, --该组最大row_number/所有记录row_number
row_number() over (order by id) rn,id,area,score from students;
select id,max(score) over(partition by id order by score desc) as mx,score from students;
select id,area,avg(score) over(partition by id order by area) as avg,score from students; --注意有无order by的区别
--按照ID求AVG
select id,avg(score) over(partition by id order by score desc rows between unbounded preceding
and unbounded following ) as ag,score from students;
--2、SUM()
select id,area,score from students order by id,area,score desc;
select id,area,score,
sum(score) over (order by id,area) 连续求和, --按照OVER后边内容汇总求和
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;
select id,area,score,
sum(score) over (partition by id order by area ) 连id续求和, --按照id内容汇总求和
sum(score) over (partition by id) id总和, --各id的分数总和
100*round(score/sum(score) over (partition by id),4) "id份额(%)",
sum(score) over () 总和, -- 此处sum(score) over () 等同于sum(score)
100*round(score/sum(score) over (),4) "份额(%)"
from students;
--4、LAG(COL,n,default)、LEAD(OL,n,default) --取前后边N条数据
select id,lag(score,1,0) over(order by id) lg,score from students;
select id,lead(score,1,0) over(order by id) lg,score from students;
--5、FIRST_VALUE()、LAST_VALUE()
select id,first_value(score) over(order by id) fv,score from students;
select id,last_value(score) over(order by id) fv,score from students;
----ntile使用介绍
create table qz_integers (
integer_value int not null
);
insert into qz_integers
select level number_value from dual
connect by level <= 10;
commit;
下列哪些选项可用来取代查询中的 ##REPLACE##,来为每行指定一个桶号,使得:
你将每一行放入五个桶之一;
每个桶包含两行;
连续的数值将会在同一个桶中,或者在相邻的桶中?
select integer_value,
##REPLACE## bucket
from qz_integers
order by integer_value;
正确的查询应该返回下面的行:
INTEGER_VALUE BUCKET
------------- ----------
1 1
2 1
3 2
4 2
5 3
6 3
7 4
8 4
9 5
10 5
(A)
ntile ( 5 ) over ( order by integer_value )
(B)
width_bucket ( integer_value, 1, 10, 5 )
(C)
width_bucket ( integer_value, 1, 11, 5 )
(D)
mod ( integer_value, 5 ) + 1
(E)
ceil ( integer_value / 2 )
--------------------------------------------答案及分析
ACE
A:ntile 作为统计分析函数可以创建登高直方分布图 语法
B:NTILE(expr) OVER ([ query_partition_clause ] order_by_clause)
width_bucket 和ntile类似,是创建一个封闭口的分布,WIDTH_BUCKET (expr, min_value, max_value, num_buckets),B错误的原因是10是结束口,大于10就会显示成num_buckets+1 ,下面是官网的解释:
WIDTH_BUCKET lets you construct equiwidth histograms, in which the histogram range is divided into intervals that have identical size. (Compare this function with NTILE, which creates equiheight histograms.)
Ideally each bucket is a closed-open interval of the real number line. For example, a bucket can be assigned to scores between 10.00 and 19.999... to indicate that 10 is included in the interval and 20 is excluded.
This is sometimes denoted [10, 20).
C:见B解释
D:mod 顺序有问题
E:ceil 这个行,因为是ceil是求大于或等于当前数据的最小整数,比如ceil(3.123),会是4,
---------------------------------
A: ntile分析函数,这个创建的是等高直方图, order by integer_value 每个桶分2个整数,推荐
B: width_bucket 这个是构建等宽直方图函数,并且范围取值min和max 是半闭半开区间,即 [min,max), 所以要将1-10分到5个桶,参数传入范围应该是1,11
C: 纠正B的写法
D: mod也可以分桶,但这里放入同一桶中的不是连续的,比如,1和6都被放入的2号桶
E: 利用ceil函数也可以达到目的,这个方法适用于较早的数据库版本
-----------------------------------
答案ACE, 。
A:(推荐)
是的, Ntile 把数据行分成N个桶。每个桶会有相同的行数,正负误差为1
B: 不对,Width_bucket使用的是前闭后开区间,所以等于上限的值被排除在区间之外。它把大于等于上限的任何值放到N+1号桶。所以10进入了第六个桶而不是第五个!
C: 是的,Width_bucket根据值把数据行分成N个桶,在上下限之间的每个桶中有相同数量的值。此处各个桶的边界是1 - 3 - 5 - 7 - 9 - 11,所以每个桶中有两行。
D: 不对,这会把数据分成五个桶,但不是升序排列。它把1-5放入每个桶。然后又对6-10做了同样的事。所以1和6在同一个桶,而不是要求的 1和2放在同一个桶。
E:(不推荐)
是的,CEIL会向上取整。所以1和2进入一号桶,3和4进入二号桶,以此类推。
这紧紧在1-10这些数字起作用。11就会进入第六号桶了,所以这不是一个通用方法。
原文地址:https://www.cnblogs.com/always-online/p/5010185.html
一、简介
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
over()表示 lag()与lead()操作的数据都在over()的范围内,他里面可以使用partition by 语句(用于分组) order by 语句(用于排序)。partition by a order by b表示以a字段进行分组,再 以b字段进行排序,对数据进行查询。
例如:lead(field, num, defaultvalue) field需要查找的字段,num往后查找的num行的数据,defaultvalue没有符合条件的默认值。
二、示例
1、表机构与初始化数据如下
1 -- 表结构
2 create table tb_test(
3 id varchar2(64) not null,
4 cphm varchar2(10) not null,
5 create_date date not null,
6 primary key (id)
7 )
8 -- 初始化数据
9 insert into tb_test values ('1000001', 'AB7477', to_date('2015-11-30 10:18:12','YYYY-MM-DD HH24:mi:ss'));
10 insert into tb_test values ('1000002', 'AB7477', to_date('2015-11-30 10:22:12','YYYY-MM-DD HH24:mi:ss'));
11 insert into tb_test values ('1000003', 'AB7477', to_date('2015-11-30 10:28:12','YYYY-MM-DD HH24:mi:ss'));
12 insert into tb_test values ('1000004', 'AB7477', to_date('2015-11-30 10:29:12','YYYY-MM-DD HH24:mi:ss'));
13 insert into tb_test values ('1000005', 'AB7477', to_date('2015-11-30 10:39:13','YYYY-MM-DD HH24:mi:ss'));
14 insert into tb_test values ('1000006', 'AB7477', to_date('2015-11-30 10:45:12','YYYY-MM-DD HH24:mi:ss'));
15 insert into tb_test values ('1000007', 'AB7477', to_date('2015-11-30 10:56:12','YYYY-MM-DD HH24:mi:ss'));
16 insert into tb_test values ('1000008', 'AB7477', to_date('2015-11-30 10:57:12','YYYY-MM-DD HH24:mi:ss'));
17 -- ---------------------
18 insert into tb_test values ('1000009', 'AB3808', to_date('2015-11-30 11:00:12','YYYY-MM-DD HH24:mi:ss'));
19 insert into tb_test values ('1000010', 'AB3808', to_date('2015-11-30 11:10:13','YYYY-MM-DD HH24:mi:ss'));
20 insert into tb_test values ('1000011', 'AB3808', to_date('2015-11-30 11:15:12','YYYY-MM-DD HH24:mi:ss'));
21 insert into tb_test values ('1000012', 'AB3808', to_date('2015-11-30 11:26:12','YYYY-MM-DD HH24:mi:ss'));
22 insert into tb_test values ('1000013', 'AB3808', to_date('2015-11-30 11:30:12','YYYY-MM-DD HH24:mi:ss'));
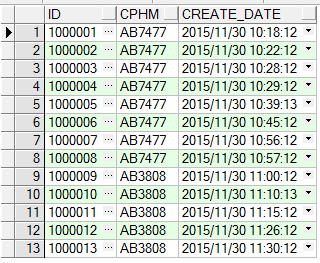
表初始化数据为:
2、示例
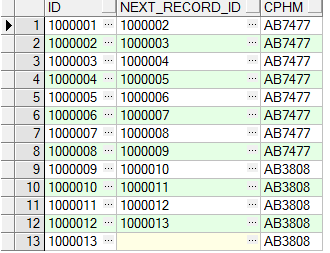
a、获取当前记录的id,以及下一条记录的id
select t.id id ,
lead(t.id, 1, null) over (order by t.id) next_record_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:
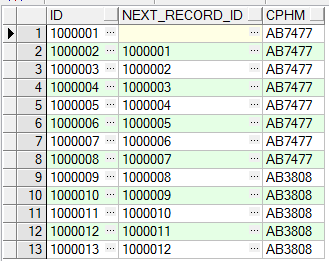
b、获取当前记录的id,以及上一条记录的id
select t.id id ,
lag(t.id, 1, null) over (order by t.id) next_record_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:
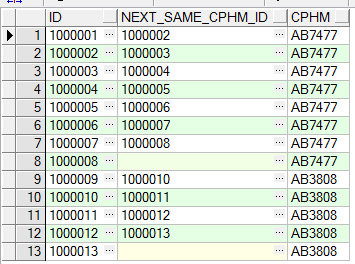
c、获取号牌号码相同的,当前记录的id与,下一条记录的id(使用partition by)
select t.id id,
lead(t.id, 1, null) over(partition by cphm order by t.id) next_same_cphm_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:
d、查询 cphm的总数,当create_date与下一条记录的create_date时间间隔不超过10分钟则忽略。
1 select cphm, count(1) total from 2 ( 3 select t.id, 4 t.create_date t1, 5 lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) t2, 6 ( lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) - t.create_date ) * 86400 as itvtime, 7 t.cphm 8 from tb_test t 9 order by t.cphm, t.create_date asc 10 ) tt 11 where tt.itvtime >= 600 or tt.itvtime is null 12 group by tt.cphm
结果如下:



