
- 1关于http协议运用剪贴板的兼容处理_http剪切板
- 2晶晨海思国科一键备份工具_海思专用备份还原工具
- 3Android截屏分享之View生成图片进行保存分享、全屏,半屏、指定VIew、弹窗......._android对view截图
- 4一位全加器及四位全加器————FPGA
- 5基于Python爬虫辽宁大连酒店宾馆数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 6数据分析Pandas专栏---第十四章<Pandas训练题(中)>
- 7STM32 上使用 printf 输出函数_stm32 printf
- 8mac下提示MAC电脑GIT提交代码到GITHUB提示GIT-CREDENTIAL-OSXKEYCHAIN 验证解决方案
- 9常用算法经典代码(C++版)_c++ 手写算法
- 10Cuda Error in NCHWToNCHHW2解决_error: 1: [reformat.cu::nchwtonchw::724] error cod
详解Sora背后的技术(32篇论文分析)
赞
踩

近期,文字生视频AI大模型Sora横空出世后,成为了人工领域讨论的焦点,人们震惊于它1分钟长视频的视频生成质量以及其强大的功能,引起了广泛的讨论。
Sora是怎么做到这个效果的呢,在OpenAI的官方网站,发布了技术报告,这篇报告从较高维度介绍了Sora的技术路径,(我们也在技术报告发布之初做了中文版的同步更新,详见这里:OpenAI新发布Sora技术文档(全文)),这篇报告中并未介绍其具体的技术点,但是列出了全部的参考文献。这些参考文献为我们提供了深入了解Sora技术背后的机会。本篇文章旨在通过研究这些文献,更好地理解Sora模型的原理和实现方法。
文献参考整体结构
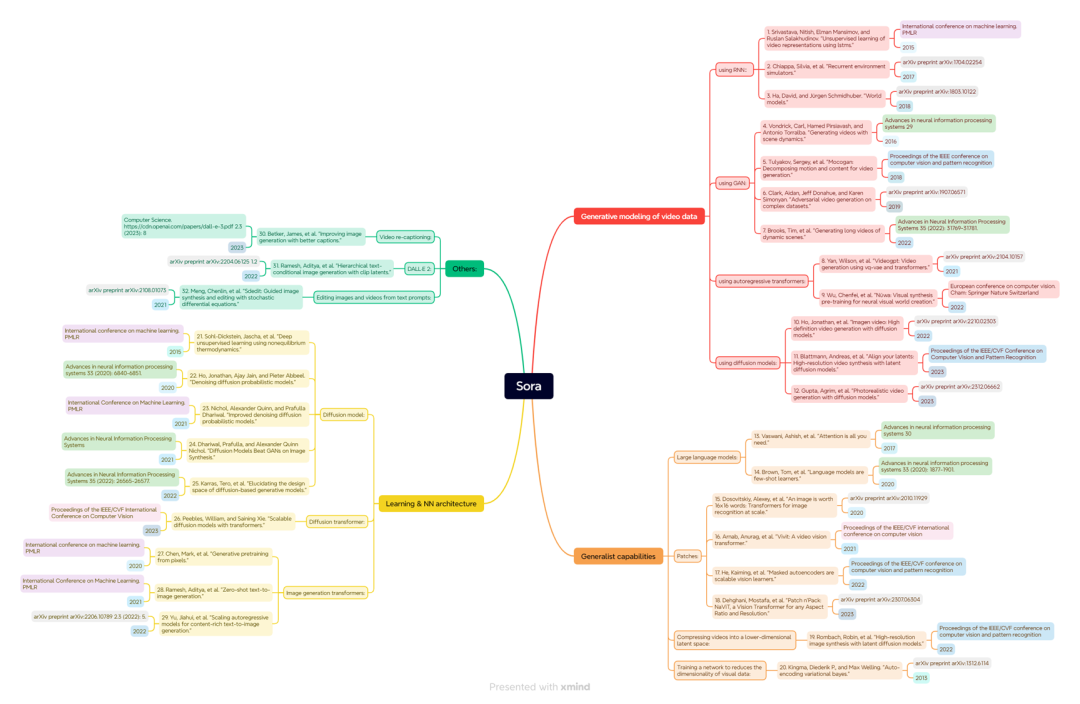
首先,我们可以将这些论文分成几个模块,而每个模块里面还可以继续细分,这说明这些论文是有结构的,整个研究领域既有一个端到端(end-to-end)的方法论,同时也包括模型具体的操作层面的内容。
这些论文的来源有32篇,其中12篇直接发表在arXiv.org上超过了总数的1/3;至于其他来源,主要集中在几个顶级会议,如NIPS、ICML、CVPR和ICCV。这几个来源加起来的论文数量超过了总数的50%,显示了Sora技术主要的发表渠道仍然是传统的顶级会议。
所有的内容都来自近十年,最早的一篇论文可以追溯到2013年。观察21年、22年和23年的论文数量,它们的总和已经超过了一半,显示了团队主要依赖于较新的论文进行研究。通过观察这些研究成果的时间分布,我们可以了解到人工智能领域的发展速度之快。
在短短十年的时间里,这个领域取得了令人瞩目的成就。这些研究成果不仅推动了人工智能技术的进步,还为我们提供了宝贵的经验和启示,帮助我们更好地理解和应用这些先进的技术。
在研究领域方面,参考文献大致划分为以下几个方面:
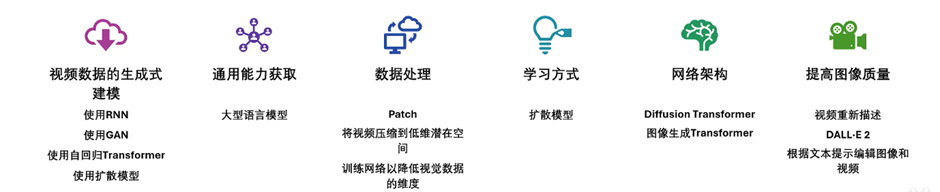
视频数据的生成式建模
首先,有一大部分论文是关于如何对视频数据进行生成式建模的,这实际上是一个完整的方法论。所谓视频生成,顾名思义就是要把视频数据生成出来。在这个过程中,我们需要了解如何对视频数据进行处理和分析,以便更好地应用在各种场景中。
例如,我们可以看到一种名为GAN(生成对抗网络)的技术正在不断发展。关于GAN的论文主要研究如何利用大量未标记的视频来学习场景的动态模型,实现场景中前景和背景的分离。在此基础上,进一步探讨如何区分内容和运动,在保持内容部分固定的同时,研究者们还尝试实现运动部分的分离。
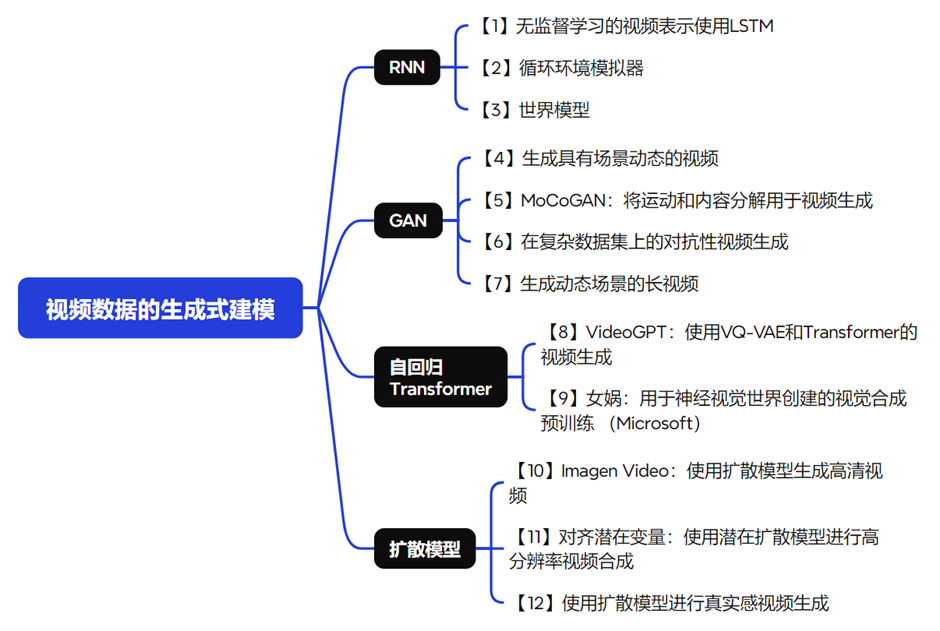
在进行视频生成之前,需要先对视频进行建模以便对其进行判别或生成,视频生成是视频建模的一个子集。要做好视频生成,我们必须先了解完整的视频建模技术发展路径,可以将其细分为几个小领域,包括最早期的使用循环神经网络(RNN)进行建模,接着是使用生成对抗网络(GAN),以及自回归的Transformer模型。通过了解这些技术的发展,我们可以更好地进行视频生成工作。
通用能力获取
在讲解Sora模型的过程中,我们了解到除了视频数据处理之外,Sora还借鉴了大型语言模型的许多技术。因此,有一部分论文是关于大型语言模型的研究。
第一篇是著名的 "Attention is All You Need",这篇论文提出了 Transformer 模型,为自然语言处理领域带来了革命性的变化。第二篇则是关于训练 GPT-3 模型的论文,GPT-3 是目前最先进的大型语言模型之一,它在各种自然语言处理任务上都取得了令人瞩目的成绩。
我们可以了解到大型语言模型的训练方法和技巧,从而将这些知识应用到计算机生成图像的领域,提高生成图像的质量和真实感。这将为计算机生成图像的应用场景带来更广泛的可能性,推动这一领域的发展。

数据处理
在数据处理方面,Sora模型最主要的是图像分割的处理。Sora将视频图像分割成一个个小块,称为patch。这种处理方式可以将图像中的patch视为文本中的token,从而利用Transformer模型进行处理,有助于模型更好地理解和学习视频中的信息,通过借鉴大型语言模型的技术,Sora模型在处理视频数据时表现出了很高的效率和准确性。
需要注意的是,视觉数据的信息量要远大于文本数据。因此,在处理视觉数据时,我们需要考虑如何有效地处理这些大量的信息。在处理大量数据时,需要提取真正有效的信息,同时也要加快训练速度。为了实现这一目标,我们会对这类数据进行压缩和建模。
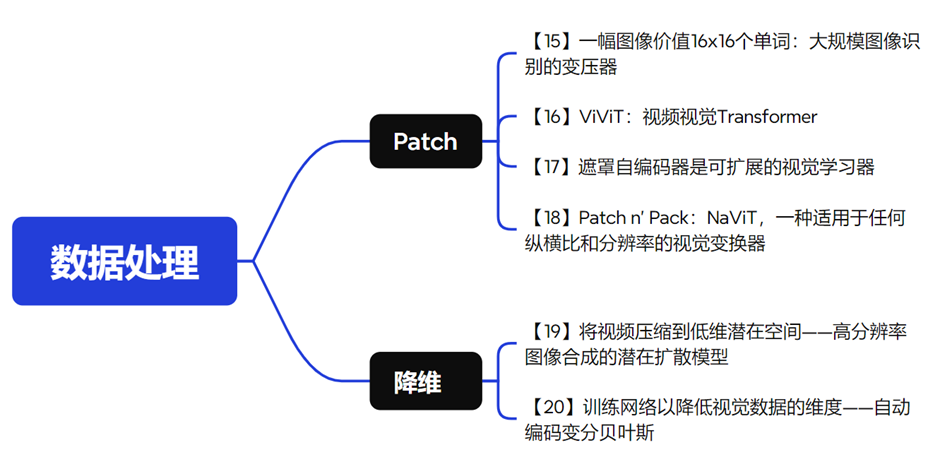
因此,研究人员提出了两种方法。第一种方法是在模型中引入交叉注意力层,这个技术可以帮助我们更好地理解数据的结构,从而实现更高效的压缩;第二种方法是引入一种随机的变分推断学习算法,这种算法可以在训练过程中自动调整模型的参数,使得训练更加高效。通过这两种方法,我们可以在保证视频质量的同时,大幅度降低视频数据的大小,实现更好的压缩效果。
学习方式&网络架构
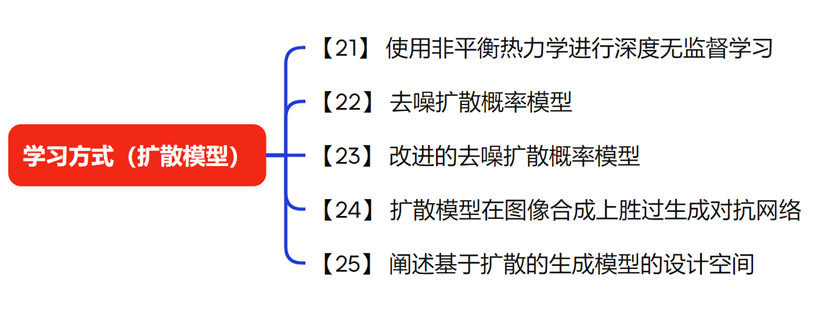
扩散模型是一种常用的学习方法。扩散模型的原理是将一个图像逐渐加入噪声,直至变成纯噪声。然后将其作为训练数据,让模型从纯噪声开始逐步预测出具有轮廓的图像,最终得到清晰的图像。这种方法的优势在于,它可以在大数据集上进行扩展,从而提高模型的预测能力。
总之,扩散模型是一种强大的学习方式,它可以帮助我们从纯噪声中预测出清晰的图像,这种方法在图像生成等领域具有广泛的应用前景。
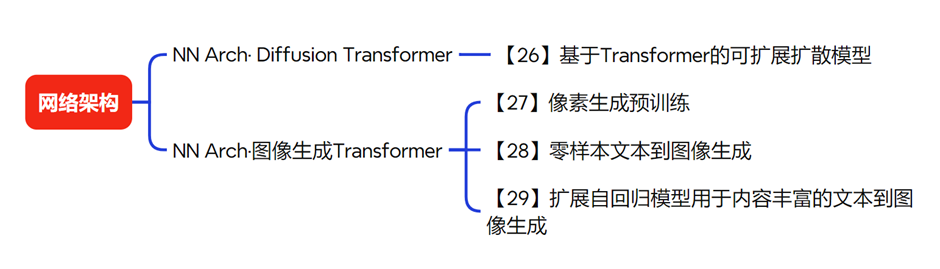
网络架构这个领域中,Diffusion Transformer已经成为了一个非常简单且易于理解的模型。除此之外,还有一些相关的图像生成技术也在不断发展。在网络架构方面,Diffusion Transformer是一篇非常重要的论文。Diffusion Transformer的主要创新之处在于,它将扩散模型中原本使用的U-Net架构替换为了Transformer架构。我们知道,像Stable Diffusion这样的方法就是采用了U-Net架构来训练扩散模型。这篇论文为我们提供了一个全新的设计空间,使得我们能够更好地训练和调优扩散模型。通过引入Transformer架构,我们可以进一步提高扩散模型的性能,为未来的研究和应用奠定了坚实的基础。
通过压缩和建模数据,以及采用扩散模型等学习方法,我们可以更有效地从大量数据中提取有用信息,并加快训练速度。这将有助于我们更好地理解和利用数据,推动科学技术的进步。
提高图像质量
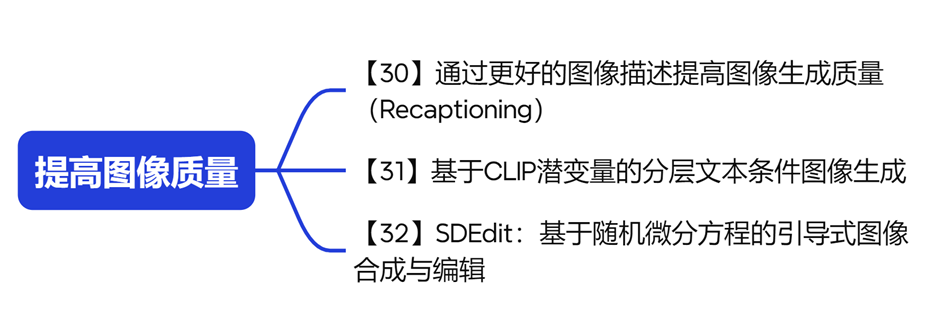
最后一部分,实际上涉及到了一些具体的提高图像质量的方法,例如在DallE·3中使用的recaptioning技术,recaptioning技术解决了一个问题:在训练模型的过程中,可能会遇到一些图像没有足够好的文本描述来说明自己的内容,为了解决这个问题,我们需要先训练一个模型,让它能够为这些训练样本图像生成很多文本的说明。
通过这种方式,我们可以为原本没有足够好的文本描述的图像生成更详细的说明,从而提高模型生成的图像质量。这种技术在Dall-E3项目中得到了成功的应用,展示了如何通过先进的技术手段来提高图像质量,以提升生成数据的质量。
总之,这些研究为我们提供了一种在保持图像真实性和相似性的同时,提高图像多样性的方法。通过这种方法,我们可以生成更加逼真的图像,为图像处理和计算机视觉领域带来更多的可能性。
最后,如果有朋友对以上论文十分感兴趣,我们也已经帮大家下载整理了32篇PDF版论文,需要可自取,链接:
https://github.com/microsoft/GoTFlow/tree/main/data/workflows/SoraReferences/input/pdf

欢迎关注微软 智汇AI 官方账号
一手资讯抢先了解

感谢喜欢,点击一下 在看 吧

