
- 1less安装与配置_less2.7.2版本
- 2Angualr 输入文本框监听enter回车键和esc键方法使用(附常用的键盘事件对应的键码)_andular 监听 f12
- 3除了ChatGPT,Openai旗下的这几个ai工具你必须知道_open ai产品有哪些
- 4request.getParameter接受到字符串类型日期转Date存入mysql数据库_java web request.getparameter日期
- 5iOS Document Scanner: 矩形边缘识别(边缘检测 ) CIDetectorTypeRectangle_ios canny 边缘检测矩形
- 6如何在 Ubuntu 22.04 上安装 Apache Web 服务器_ubuntu22安装apache
- 7WPS 云文档保存在本地的地址如何从c盘更改为其他盘?
- 8java 推流_使用java执行ffmpeg命令进行推流操作
- 9求帮忙!!!在课堂上看的Python程序,运行出来全是一个黑的界面?应该是一个2048的界面啊_python跑完为什么会有黑图
- 10IDEA(Java Web 开发) 实时代码模板合集_优秀的idea实时模板
机器学习(29)之奇异值分解SVD原理与应用详解_机器学习 奇异值分解
赞
踩
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
前言
奇异值分解(Singular Value Decomposition,简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域,是很多机器学习算法的基石。本文就对SVD的原理做一个总结,并讨论在在PCA降维算法中是如何运用运用SVD的。
特征值与特征向量
首先回顾下特征值和特征向量的定义如下:
Ax=λx
其中A是一个n×n的矩阵,x是一个n维向量,则我们说λ是矩阵A的一个特征值,而x是矩阵A的特征值λ所对应的特征向量。
求出特征值和特征向量有什么好处呢? 我们可以将矩阵A特征分解。如果我们求出了矩阵A的n个特征值λ1≤λ2≤...≤λn,以及这n个特征值所对应的特征向量{w1,w2,...wn},那么矩阵A就可以用下式的特征分解表示:
A=WΣW^−1
其中W是这n个特征向量所张成的n×n维矩阵,而Σ为这n个特征值为主对角线的n×n维矩阵。一般会把W的这n个特征向量标准化,即满足||wi||^2=1, 或者说wi^Twi=1,此时W的n个特征向量为标准正交基,满足W^TW=I,即W^T=W^−1, 也就是说W为酉矩阵。这样特征分解表达式可以写成
A=WΣW^T
注意到要进行特征分解,矩阵A必须为方阵。那么如果A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?
SVD定义
SVD也是对矩阵进行分解,但和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设矩阵A是一个m×n的矩阵,那么我们定义矩阵A的SVD为:
A=UΣV^T
其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足U^TU=I,V^TV=I。下图可以很形象的看出上面SVD的定义:
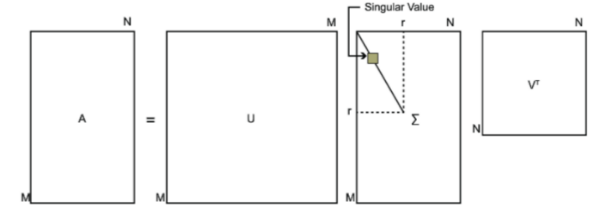
那么如何求出SVD分解后的U,Σ,V这三个矩阵呢?如果将A的转置和A做矩阵乘法,那么会得到n×n的一个方阵A^TA。既然A^TA是方阵,那么就可以进行特征分解,得到的特征值和特征向量满足下式:
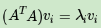
这样就可以得到矩阵A^TA的n个特征值和对应的n个特征向量v。将A^TA的所有特征向量张成一个n×n的矩阵V,就是SVD公式里面的V矩阵了。一般将V中的每个特征向量叫做A的右奇异向量。
如果将A和A的转置做矩阵乘法,那么会得到m×m的一个方阵AA^T。既然AA^T是方阵,那么就可以进行特征分解,得到的特征值和特征向量满足下式:

这样就可以得到矩阵AA^T的m个特征值和对应的m个特征向量u。将AA^T的所有特征向量张成一个m×m的矩阵U,就是SVD公式里面的U矩阵。一般将U中的每个特征向量叫做A的左奇异向量。
U和V求出来后,现在剩下奇异值矩阵Σ没有求出。由于Σ除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值σ就可以了。注意到:

可以求出我们的每个奇异值,进而求出奇异值矩阵Σ。
上面还有一个问题没有讲,就是说A^TA的特征向量组成的就是SVD中的V矩阵,而AA^T的特征向量组成的就是SVD中的U矩阵,这有什么根据吗?其实很容易证明,以V矩阵的证明为例。
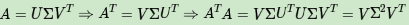
上式证明了U^TU=I,Σ^T=Σ。可以看出A^TA的特征向量组成的的确就是SVD中的V矩阵。类似的方法可以得到AA^T的特征向量组成的就是SVD中的U矩阵。
SVD计算实例
用一个简单的例子来说明矩阵是如何进行奇异值分解的。矩阵A定义为:
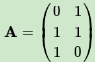
首先求出A^TA和AA^T
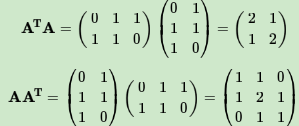
求出A^TA的特征值和特征向量:
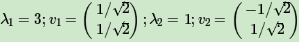
接着求AA^T的特征值和特征向量:
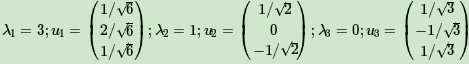
求出奇异值
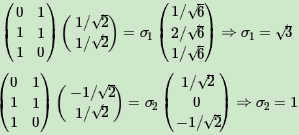
最终得到A的奇异值分解为:
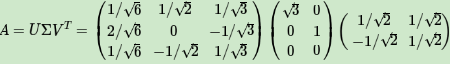
SVD的性质
上面对SVD的定义和计算做了详细的描述,似乎看不出SVD有什么好处。那么SVD有什么重要的性质值得我们注意呢?对于奇异值,它跟特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,也可以用最大的k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
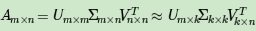
如下图所示,现在矩阵A只需要灰色的部分的三个小矩阵就可以近似描述了。

由于这个重要的性质,SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。
SVD用于PCA
在主成分分析(PCA)原理总结(机器学习(27)【降维】之主成分分析(PCA)详解)中讲到要用PCA降维,需要找到样本协方差矩阵X^TX的最大的d个特征向量,然后用这最大的d个特征向量张成的矩阵来做低维投影降维。可以看出,在这个过程中需要先求出协方差矩阵X^TX,当样本数多样本特征数也多的时候,这个计算量是很大的。
注意到SVD也可以得到协方差矩阵X^TX最大的d个特征向量张成的矩阵,但是SVD有个好处,有一些SVD的实现算法可以不求先求出协方差矩阵X^TX,也能求出我们的右奇异矩阵V。也就是说,PCA算法可以不用做特征分解,而是做SVD来完成。这个方法在样本量很大的时候很有效。实际上,scikit-learn的PCA算法的背后真正的实现就是用的SVD,而不是我们我们认为的暴力特征分解。
另一方面,注意到PCA仅仅使用了SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
假设样本是m×n的矩阵X,如果通过SVD找到了矩阵XX^T最大的d个特征向量张成的m×d维矩阵U,则如果进行如下处理:
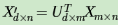
可以得到一个d×n的矩阵X‘,这个矩阵和原来的m×n维样本矩阵X相比,行数从m减到了k,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是PCA降维。
SVD小结
SVD作为一个很基本的算法,在很多机器学习算法中都有它的身影,特别是在现在的大数据时代,由于SVD可以实现并行化,因此更是大展身手。SVD的原理不难,只要有基本的线性代数知识就可以理解,实现也很简单因此值得仔细的研究。当然,SVD的缺点是分解出的矩阵解释性往往不强,有点黑盒子的味道,不过这不影响它的使用。
欢迎分享给他人让更多的人受益

参考:
-
周志华《机器学习》
-
Neural Networks and Deep Learning by By Michael Nielsen
-
博客园
http://www.cnblogs.com/pinard/p/6251584.html
-
李航《统计学习方法》
-
Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
近期热文
干货 | 高盛:2017人工智能报告中文版(附PDF版下载)
机器学习(28)【降维】之sklearn中PCA库讲解与实战
干货 | 深度学习之卷积神经网络(CNN)的前向传播算法详解

加我微信:guodongwe1991,备注姓名-单位-研究方向(加入微信机器学习交流1群)
广告、商业合作
请加微信:guodongwe1991

喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!

