
- 1[uni-app] canvas绘制圆环进度条_uniapp 环形进度条
- 2Linux网络子系统中报文的接收及NAPI的实现_netif_napi_add
- 3python怎么求因子之和_P066 求n的所有因子之和 ★★
- 4H5如何调用小程序分享 微信SDK_微信sdk支持h5直接唤起分享吗
- 5nmap在kali的使用方法和常见命令(入门)_kali的nmap用法
- 6leetcode 矩阵置零 java_leetcode java 矩阵置零
- 7封装请求拦截器、响应拦截器原理
- 8在 Linux 中,文件总共被分成了 7 种_linux中7种主要文件类型
- 9gcc g++环境变量设置_MinGW + 配置系统环境变量
- 10带有反斜杠的字符串如何转json对象_vue json 里面有反斜杠的怎么转成json
基于mips指令集的处理器设计与实现_mips架构
赞
踩
目录:
一.MIPS指令集架构
1.mips指令集格式
2.mips寄存器特点
二.单周期MIPScpu_core架构设计
三.子模块结构分析(含Icache)
1.ALU模块
2.General_Register模块(通用寄存器)
3.instruction_cache模块(指令cache)
4.program_counter模块(程序计数器)
5.control模块(控制译码)
四.详细设计流程与机器指令验证
一.MIPS指令集架构
MIPS是(Microcomputer without interlocked pipeline stages)的缩写,含义是无互锁流水级微处理器。MIPS 是最早的,最成功的RISC处理器之一,源于Stanford 大学的John Hennessy 教授的研究成果。(Hennessy 于1984年在硅谷创建了MIPS公司)。MIPS的指令系统经过通用处理器指令体系MIPS I、 MIPS II、MIPS III、MIPS IV到MIPS V,嵌入 式指令体系MIPS16、MIPS32到MIPS64的发展 已经十分成熟。应用广泛的32位MIPS CPU包括R2000,R3000 其ISA都是MIPS I,另一个广泛使用的、含有许多 重要改进的64位MIPS CPU R4000及其后续产 品,其ISA版本为MIPS III。
1.mips指令集格式
MIPS 32位处理器的指令格式分为R型、I型和J型。R型为寄存器型,即两个源操作数和目的操作数都是寄存器性。I型为操作数含有立即数。而J型特指转移类型指令,如图1所示。
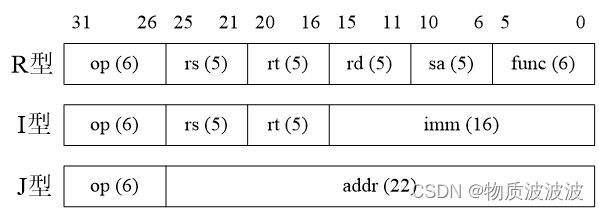
图1 MIPS指令类型
常见的20条MIPS整数指令如下所示:Mips体系结构下的指令都是32位,且其为RISC处理机,特点为指令等长,没有类似x86架构的变长指令。
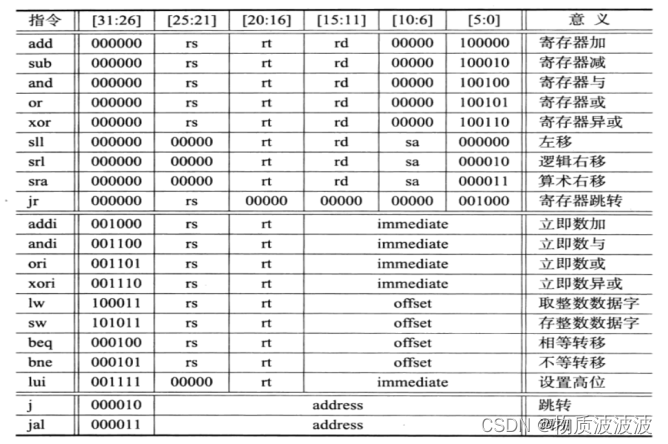
表 1 20条MIP整数指令 这是设计整个处理机结果的编码依据
可以发现:mips指令集的特点为:
R型指令op字段(Instruction[31..26])必为0 I型指令op字段非0。
这是区别指令类型的标志。
- 1
- 2
- 3
- 4
2.mips寄存器特点
Mips体系结构下的寄存器都是32位,且其为RISC处理机,特点为寄存器很多,以减少访存的发生。
而0–31共32个寄存器,对应地址为五位通用寄存器地址码,可以发现RS、RT、RD寄存器指令都是五位字长。

图2 寄存器结构
二.单周期MIPScpu_core架构设计
在此先讨论单周期MIPS处理机的设计:由于读写要在同一个执行周期(即时钟周期)内完成,故cpu必须选择三总线(内总线)结构:如下图,对于单总线、双总线结构:由于数据通路必须分时复用,故只能采用多周期实现。而三总线结构有两个源数据总线,和一个目标数据总线(5bit宽),故可以在一个周期内执行结束;
- 1
而对一条指令的执行,采用硬布线结构设计:将ICache中读出的指令按MIPS指令的规定译码,就可以完成对各部件的控制。(结构如下所示)
译码的结果是产生一系列微命令信号
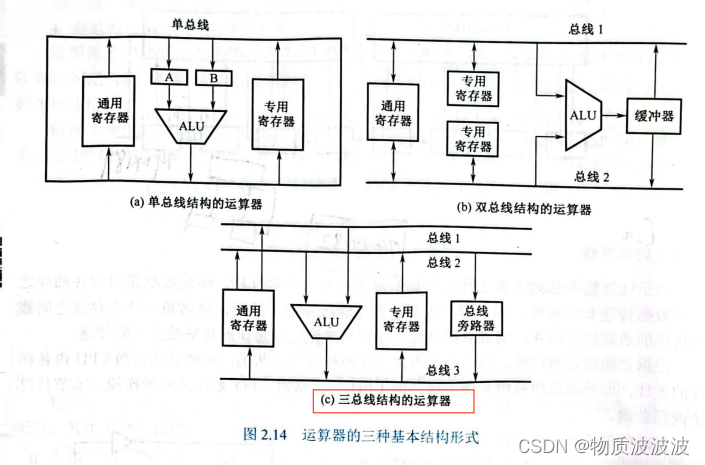 图3 运算器基本结构
图3 运算器基本结构
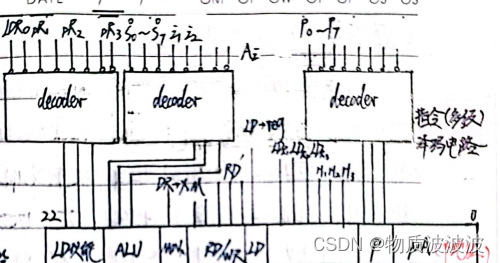
图4 指令控制单元结构
三.子模块结构分析(含Icache)
1.ALU模块
alu是处理机的核心运算部件,一定要功能强大,故设计32位ALU,五位方式码,共可以实现19种算术逻辑运算模式
module ALU(clk, input_data1, input_data2, output_data,ctrl_sinal, sinal);
input clk;
input [31:0] input_data1;
input [31:0] input_data2;
input [4:0] ctrl_sinal;
output [31:0] output_data;
output sinal;
reg sinal;
reg [31:0] output_data;
parameter ALU_add = 5'b00001; //加法
parameter ALU_sub = 5'b00010; //减法
parameter ALU_mul = 5'b00011; //乘法
parameter ALU_div = 5'b00100; //除法
parameter ALU_mod = 5'b00101; //取余
parameter ALU_and = 5'b00110; //与
parameter ALU_or = 5'b00111; //或
parameter ALU_not = 5'b01000; //非
parameter ALU_xor = 5'b01001; //异或
parameter ALU_xnor= 5'b01010; //同或
parameter ALU_nor = 5'b01011; //或非
parameter ALU_nand= 5'b01100; //与非
parameter ALU_sll = 5'b01101; //逻辑左移
parameter ALU_srl = 5'b01110; //逻辑右移
parameter ALU_sra = 5'b01111; //算术右移
parameter ALU_sla = 5'b10000; //算术左移
parameter ALU_slt = 5'b10001; //小于则置'1'
parameter ALU_lui = 5'b10010; //左移16位
parameter ALU_comparer = 5'b10011; //条件相等
always @(posedge clk)
begin
case(ctrl_sinal)
5'b00000: output_data=input_data1;
ALU_add : begin
output_data = input_data1+input_data2;
sinal = 1;
end
ALU_sub : begin
output_data = input_data1-input_data2;
sinal = 1;
end
ALU_mul : begin
output_data = input_data1*input_data2;
sinal = 1;
end
ALU_div : begin
output_data = input_data1/input_data2;
sinal = 1;
end
ALU_mod : begin
output_data = input_data1%input_data2;
sinal = 1;
end
ALU_and : begin
output_data = input_data1&input_data2;
if(input_data1 == input_data2)
sinal = 1;
else sinal = 0;
end
ALU_or : begin
output_data = input_data1|input_data2;
sinal = 1;
end
ALU_not : begin
output_data =~input_data1;
sinal = 1;
end
ALU_xor : begin
output_data = input_data1^input_data2;
sinal = 1;
end
ALU_xnor : begin
output_data = input_data1^~input_data2;
sinal = 1;
end
ALU_nor : begin
output_data = ~(input_data1|input_data2);
sinal = 1;
end
ALU_nand : begin
output_data = ~(input_data1*input_data2);
sinal = 1;
end
ALU_slt : begin
output_data = (input_data1 < input_data2);
sinal = 1;
end
ALU_sll : begin
output_data = input_data2 << input_data1;
sinal = 1;
end
ALU_srl : begin
output_data = input_data2 >> input_data1;
sinal = 1;
end
ALU_sra : begin
output_data = ($signed(input_data2)) >>> input_data1;
sinal = 1;
end
ALU_sla : begin
output_data = ($signed(input_data2)) <<< input_data1;
sinal = 1;
end
ALU_lui : begin
output_data = input_data2 * 65536;
sinal = 1;
end
ALU_comparer: begin
if(input_data1 != input_data2)
sinal = 1;
else sinal = 0;
end
endcase
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
编译并封装后,结构如下所示:
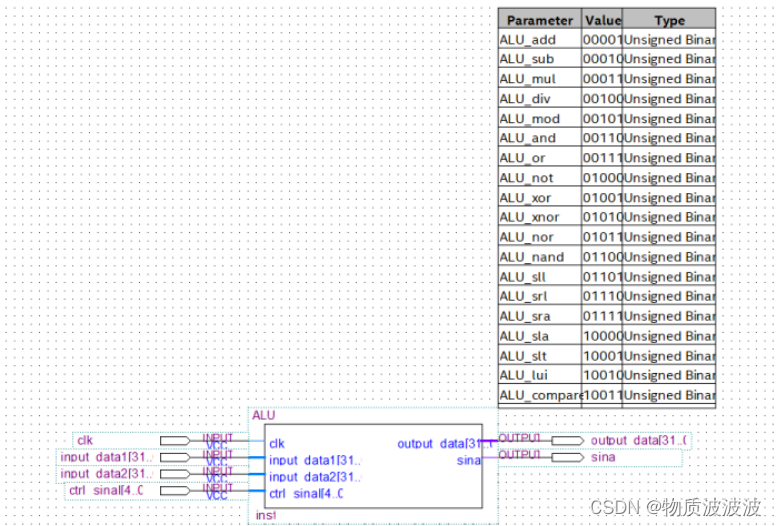
图5 alu封装示意结构
2.General_Register模块(通用寄存器)
在此先讨论单周期MIPS处理机的设计:由于读写要在同一个执行周期(即时钟周期)内完成,故cpu必须选择三总线结构:两个源操作数读地址,一个目标操作数写地址,如下所示:
图6通用寄存器封装示意结构
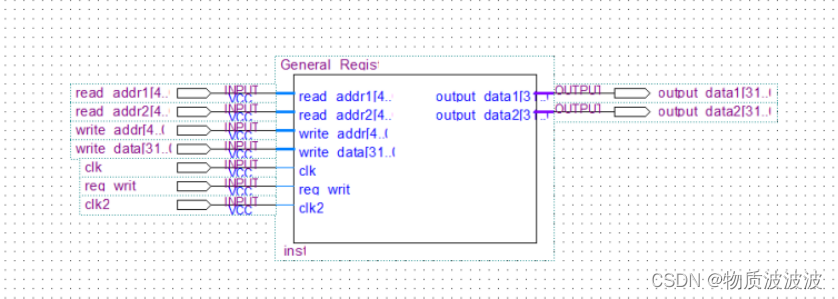
module General_Register(read_addr1, read_addr2, write_addr, write_data, output_data1, output_data2, clk, reg_write,clk2);
input clk, clk2, reg_write;
input[4:0] read_addr1;
input[4:0] read_addr2;
input[4:0] write_addr;
input[31:0] write_data;
// input RegWrite_sinal;
output[31:0] output_data1;
output[31:0] output_data2;
reg[31:0] output_data1;
reg[31:0] output_data2;
reg[31:0] reg_zero;
reg[31:0] reg_at; //汇编器的暂时变量
reg[31:0] reg_v[1:0]; //子函数调用返回结果
reg[31:0] reg_a[3:0]; //子函数调用的参数
reg[31:0] reg_t[9:0]; //暂时变量,子函数使用时不需要保存与恢复
//t[7:0]地址为:15-8;t[9:8]地址为:25-24
reg[31:0] reg_s[7:0]; //子函数寄存器变量。子函数必须保存和恢复使用过的变量在函数返回之前,从而调用函数知道这些寄存器的值没有变化
reg[31:0] reg_k[1:0]; //通常被中断或异常处理程序使用作为保存一些系统参数
reg[31:0] reg_gp; //全局指针。一些运行系统维护这个指针来更方便的存取“static“和”extern”变量
reg[31:0] reg_sp; //堆栈指针
reg[31:0] reg_fp; //第9个寄存器变量。子函数可以用来做桢指针
reg[31:0] reg_ra; //子函数的返回地
always @(posedge clk2)
begin
if(reg_write) begin
case(write_addr)
5'h0 : reg_zero = 0;
5'h1 : reg_at = write_data;
5'h2 : reg_v[0] = write_data;
5'h3 : reg_v[1] = write_data;
5'h4 : reg_a[0] = write_data;
5'h5 : reg_a[1] = write_data;
5'h6 : reg_a[2] = write_data;
5'h7 : reg_a[3] = write_data;
5'h8 : reg_t[0] = write_data;
5'h9 : reg_t[1] = write_data;
5'ha : reg_t[2] = write_data;
5'hb : reg_t[3] = write_data;
5'hc : reg_t[4] = write_data;
5'hd : reg_t[5] = write_data;
5'he : reg_t[6] = write_data;
5'hf : reg_t[7] = write_data;
5'h10: reg_s[0] = write_data;
5'h11: reg_s[1] = write_data;
5'h12: reg_s[2] = write_data;
5'h13: reg_s[3] = write_data;
5'h14: reg_s[4] = write_data;
5'h15: reg_s[5] = write_data;
5'h16: reg_s[6] = write_data;
5'h17: reg_s[7] = write_data;
5'h18: reg_t[8] = write_data;
5'h19: reg_t[9] = write_data;
5'h1a: reg_k[0] = write_data;
5'h1b: reg_k[1] = write_data;
5'h1c: reg_gp = write_data;
5'h1d: reg_sp = write_data;
5'h1e: reg_fp = write_data;
5'h1f: reg_ra = write_data;
endcase
end
end
always @(posedge clk)
begin
case(read_addr1)
5'h0 : output_data1 = reg_zero;
5'h1 : output_data1 = reg_at;
5'h2 : output_data1 = reg_v[0];
5'h3 : output_data1 = reg_v[1];
5'h4 : output_data1 = reg_a[0];
5'h5 : output_data1 = reg_a[1];
5'h6 : output_data1 = reg_a[2];
5'h7 : output_data1 = reg_a[3];
5'h8 : output_data1 = reg_t[0];
5'h9 : output_data1 = reg_t[1];
5'ha : output_data1 = reg_t[2];
5'hb : output_data1 = reg_t[3];
5'hc : output_data1 = reg_t[4];
5'hd : output_data1 = reg_t[5];
5'he : output_data1 = reg_t[6];
5'hf : output_data1 = reg_t[7];
5'h10: output_data1 = reg_s[0];
5'h11: output_data1 = reg_s[1];
5'h12: output_data1 = reg_s[2];
5'h13: output_data1 = reg_s[3];
5'h14: output_data1 = reg_s[4];
5'h15: output_data1 = reg_s[5];
5'h16: output_data1 = reg_s[6];
5'h17: output_data1 = reg_s[7];
5'h18: output_data1 = reg_t[8];
5'h19: output_data1 = reg_t[9];
5'h1a: output_data1 = reg_k[0];
5'h1b: output_data1 = reg_k[1];
5'h1c: output_data1 = reg_gp;
5'h1d: output_data1 = reg_sp;
5'h1e: output_data1 = reg_fp;
5'h1f: output_data1 = reg_ra;
endcase
case(read_addr2)
5'h0 : output_data1 = reg_zero;
5'h1 : output_data1 = reg_at;
5'h2 : output_data1 = reg_v[0];
5'h3 : output_data1 = reg_v[1];
5'h4 : output_data1 = reg_a[0];
5'h5 : output_data1 = reg_a[1];
5'h6 : output_data1 = reg_a[2];
5'h7 : output_data1 = reg_a[3];
5'h8 : output_data1 = reg_t[0];
5'h9 : output_data1 = reg_t[1];
5'ha : output_data1 = reg_t[2];
5'hb : output_data1 = reg_t[3];
5'hc : output_data1 = reg_t[4];
5'hd : output_data1 = reg_t[5];
5'he : output_data1 = reg_t[6];
5'hf : output_data1 = reg_t[7];
5'h10: output_data1 = reg_s[0];
5'h11: output_data1 = reg_s[1];
5'h12: output_data1 = reg_s[2];
5'h13: output_data1 = reg_s[3];
5'h14: output_data1 = reg_s[4];
5'h15: output_data1 = reg_s[5];
5'h16: output_data1 = reg_s[6];
5'h17: output_data1 = reg_s[7];
5'h18: output_data1 = reg_t[8];
5'h19: output_data1 = reg_t[9];
5'h1a: output_data1 = reg_k[0];
5'h1b: output_data1 = reg_k[1];
5'h1c: output_data1 = reg_gp;
5'h1d: output_data1 = reg_sp;
5'h1e: output_data1 = reg_fp;
5'h1f: output_data1 = reg_ra;
endcase
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
3.instruction_cache模块(指令cache)
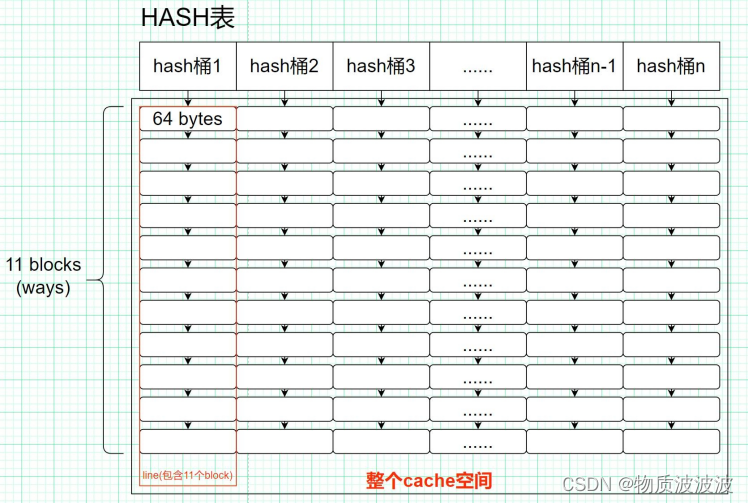
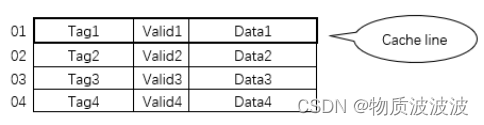
Cache是主存内容的子集,是主存内容的拷贝。保持cache与主存数据的一致性是一个很重要的课题。cache的结构其实和内存的结构类似,也包含地址和内容,只是cache的内容除了存的数据(data)之外,还包含存的数据的物理内存的地址信息(tag),因为CPU发出的寻址信息都是针对物理内存发出的,所以cache中除了要保存数据信息之外,还要保存数据对应的地址,这样才能在cache中根据物理内存的地址信息查找物理内存中对应的数据。(当然为了加快寻找速度,cache中一般还包含一个有效位(valid),用来标记这个cache line是否保存着有效的数据)。一个tag和它对应的数据组成的一行称为一个cache line。如下图所示,下表中的一行就是一个cache line。
而在此为了简化最小系统的硬件结构,cache采用了与一般存储器相同对结构,没有设置写回位、脏位等内容。
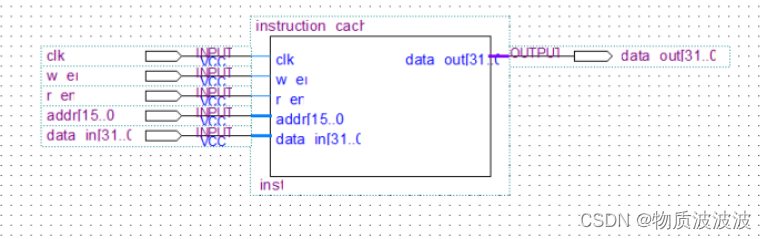
图7 ICache封装示意结构
module instruction_cache(
input clk,
input w_en,
input r_en,
input [15:0] addr,
input [31:0] data_in,
output [31:0] data_out );
reg [31:0] instruction_mem[65535:0];
reg [31:0] data;
always @(posedge clk)
begin
if (r_en)
begin
data = instruction_mem[addr];
end
else if (w_en)
begin
instruction_mem[addr] = data_in;
end
end
assign data_out = r_en? instruction_mem[addr]:32'bz;
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4.program_counter模块(程序计数器)
程序计数器的输出是作为ICache的地址使用。Program counter的地址分为两种类型:顺序下地址与跳转地址:当指令顺序执行时:PC以时钟自增:而PC+1还是+x,取决于ICache的编址方式:
常见的编址方式有按字编址和按字节编址:
通常情况下,存储器系统是按照字节(Byte)编址,但CPU访问时,通常按照字(Word)读取,因此地址就有字节地址和字地址的区别。以32位处理器为例,如下图所示;而由于cache采用字编址方式:即一个地址下存储32bit,故顺序指令方式下PC+=1即可
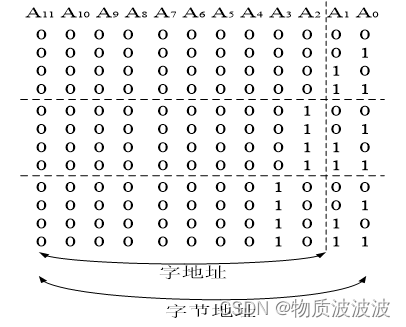
图8 32位处理器字节编址与字地址示意图
module program_counter(
input wire clk,
input wire rst,
//来自译码阶段ID模块的信息
input wire jmp,
input wire[15:0] jmp_addr,
output reg[15:0] seq_addr,
output reg instruction_cache_en
);
always @ (posedge clk) begin
if (rst) begin
seq_addr=4'h0000;
end
else if(!rst) begin
if(jmp) begin
seq_addr=jmp_addr;
instruction_cache_en=1;
end
else begin
seq_addr=seq_addr+1;
instruction_cache_en=1;
end
end
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5.control模块(控制译码)
由指令产生一系列控制微命令,结构如下所示:
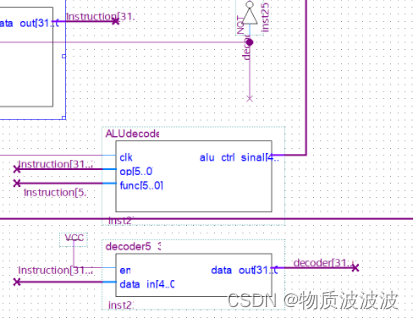
四.详细设计流程(基于Quartus Prime 17.1 Standard编写)
首先建立Quartus工程:由于只是仿真,并不涉及具体的导入FPGA板卡。故板卡型号可以随意选择。
导入并编译上述各个模块verilog源代码,编译通过后右键生成封装模块:对一个hardware系统而言,顶层文件有两种设计方式:
A.利用verilog调用各级子模块编写
B.利用布线设计
由于布线设计更具灵活性,故采用B设计方式。
将各个模块以如上形式组装,从而得到顶层文件:microCPU_top
并在instruction_cache.v内添加如下初始化调用,将TXT文件中的十六进制程序段初始化进入ICache内:
initial
begin
$readmemh("instruction_mem.txt",instruction_mem);
end
- 1
- 2
- 3
- 4
在编译时,发现出现错误:

Error (276003): Cannot convert all sets of registers into RAM
megafunctions when creating nodes. The resulting number of registers
remaining in design exceeds the number of registers in the device or
the number specified by the assignment
max_number_of_registers_from_uninferred_rams. This can cause longer
compilation time or result in insufficient memory to complete Analysis
and Synthesis
在代码中直接例化了大面积的memory,期待Quatus综合工具能直接自动综合成block ram,结果报了上述错误,但可以确认使用RAM资源没有超过所选芯片上限。找到官方的解释如下:参考官网:添加链接描述

由于ICache我采用verilog编写,符合cause2:
CAUSE 2: In a Verilog Design File (.v) or VHDL Design File (.vhd), you
specified one or more sets of registers that act as RAM. However,
Analysis & Synthesis cannot convert the sets of registers into RAM
megafunctions because the target device of the current design does not
have dedicated RAM hardware. As a result, the registers remain in the
design, which can cause longer compilation time or result in
insufficient memory to complete Analysis & Synthesis. ACTION: To avoid
problems when processing the design, change the target device to one
that has dedicated RAM hardware, or remove the sets of registers that
act as RAM from the design. Otherwise, you can set the value of the
assignment max_number_of_registers_from_uninferred_rams to a larger
value or infinity (-1).
上述解决方法为:为了避免在处理设计时出现问题,请将目标设备更改为具有专用RAM硬件的设备,或从设计中删除充当RAM的寄存器集。否则,可以将赋值max_number_of_registers_from_uniferred-rams的值设置为更大的值或无穷大(-1)。max_number_of_registers_from_uniferred-rams允许您指定Analysis&Synthesis可用于转换未出错RAM的最大寄存器数。您可以将此选项用作项目范围的选项,也可以通过在分区根的实例名称上设置分配来在特定分区上使用此选项。分区上的赋值将覆盖该特定分区的全局赋值(如果有)。当许多寄存器用于未出错的RAM时,此选项可防止合成导致长编译和内存耗尽。Quartus Prime软件没有继续编译,而是发出错误并退出。
简单来说,代码风格导致综合工具不识别为RAM,要使ICache被quartus综合为ram,而非寄存器组:从本质上来说,SRSM就是寄存器组,但是必须按照编译的要求编写。
参考官方文档如下:添加链接描述
Single-Clock Synchronous RAM with New Data Read-During-Write Behavior
The examples in this section describe RAM blocks in which the
read-during-write behavior returns the new value being written at the
memory address. To implement this behavior in the target device,
synthesis tools add bypass logic around the RAM block. This bypass
logic increases the area utilization of the design, and decreases the
performance if the RAM block is part of the design’s critical path. If
the device memory supports new data read-during-write behavior when in
single-port mode (same clock, same read address, and same write
address), the Verilog memory block doesn’t require any bypass logic.
Refer to the appropriate device handbook for specifications on your
target device. The following examples use a blocking assignment for
the write so that the data is assigned intermediately. Verilog HDL
Single-Clock, Simple Dual-Port Synchronous RAM with New Data
Read-During-Write Behavior
module single_clock_wr_ram(
output reg [7:0] q,
input [7:0] d,
input [6:0] write_address, read_address,
input we, clk);
reg [7:0] mem [127:0];
always @ (posedge clk) begin
if (we)
mem[write_address] = d;
q = mem[read_address]; // q does get d in this clock
// cycle if we is high
end
endmodule
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
https://www.intel.com/content/www/us/en/docs/programmable/683296/21-4/analysissynthesisassignmentsmaxnumberofregistersfromuninferredrams.html
参考文档如上:
MAX_NUMBER_OF_REGISTERS_FROM_UNINFERRED_RAMS Allows you to specify the
maximum number of registers that Analysis & Synthesis can use for
conversion of uninferred RAMs. You can use this option as a
project-wide option or on a specific partition by setting the
assignment on the instance name of the partition root. The assignment
on a partition overrides the global assignment (if any) for that
particular partition. This option prevents synthesis from causing long
compilations and running out of memory when many registers are used
for uninferred RAMs. Instead of continuing the compilation, the
Quartus Prime software issues an error and exits. Type Integer Device
Support This setting can be used in projects targeting any Intel FPGA
device family. Notes This assignment is included in the Analysis &
Synthesis report. This assignment supports synthesis wildcards. Syntaxset_global_assignment -name
MAX_NUMBER_OF_REGISTERS_FROM_UNINFERRED_RAMS
set_instance_assignment -name
MAX_NUMBER_OF_REGISTERS_FROM_UNINFERRED_RAMS -to -entity Default Value
-1 (Unlimited) Example set_global_assignment -name max_number_of_registers_from_uninferred_rams 2048
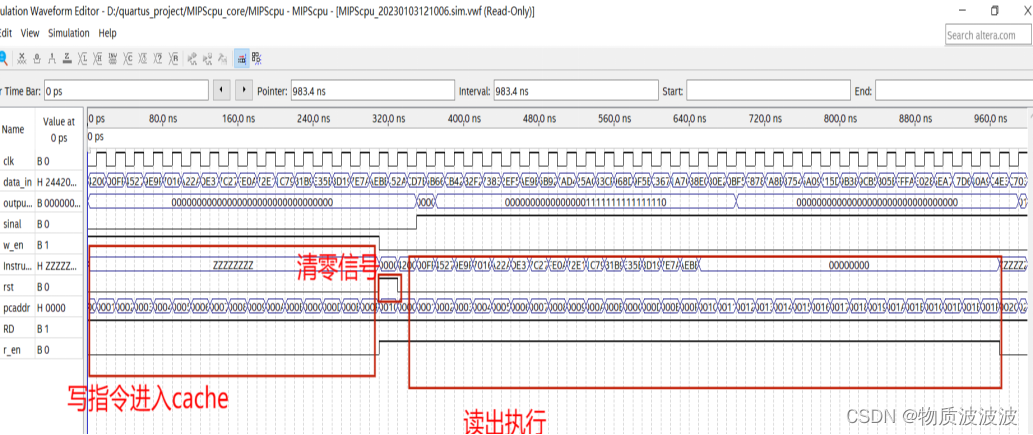
补充tcl设置后,编译正确通过,在输入了一般机器指令后,利用modelsim得出运行波形如下:观察可以发现:pc地址在顺序指令下自增,在指令写如cache后,将program counter清零,并读出执行。如下图,指令正确读出,并完成机器指令。
多周期MIPScpu_core架构设计
微程序的概念与原理最早由M.V.Wilkes于1965年提出,其基本原理是将预设执行顺序的程序固化烧写到ROM中,按时序读出并执行。相较于基于时序逻辑的设计方案,其特点为可以灵活修改微指令执行顺序,以达到优化的效果:
将指令进行分解的好处是:分解后的指令颗粒度更小,更适合于硬件执行,并且更容易进行流水化。为了进一步提高执行效率,Intel CPU 中还可能针对某些指令序列进行优化,比如进行指令合并(macrofusion)等,以减少完成指令序列所需的时钟周期数。对于 CISC 指令的分解和合并操作可能由 CPU 中的硬件电路完成,也可能由微代码完成。Intel 会定期发布微代码的更新,这些更新会以文件的形式,随着操作系统升级包一起被下载到用户的计算机中,并在系统启动时自动安装到 CPU 内。微代码可以用于修补 CPU 的一部分 bug 或漏洞。比如著名的 Spectre 漏洞就是通过微码更新的方式修复的,但由于这个补丁会强制 CPU 在特定情况下关闭部分优化功能,这个补丁也导致了 CPU 性能的降低。在 Windows 下,微码更新会随着 Windows Update 自动推送。但在 Linux 下,由于版权限制,用户可能需要手动安装对应的软件包,如 intel-microcode。
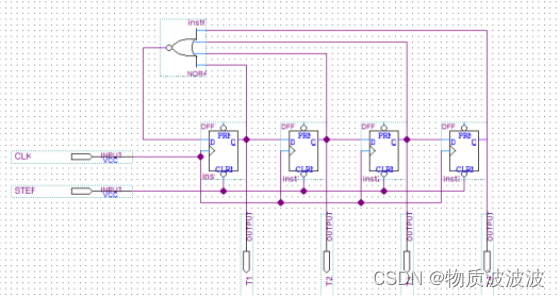
多周期处理机时序逻辑:由环形脉冲发生器产生t1-----t4四拍脉冲,如下图所示四串联D触发器组,clk为处理机总时钟,step为清零信号。初始时刻Q1–Q4都等于0,所以或非结果为1,T1输出高电平脉冲,以此类推 产生四拍连续脉冲:每一节拍有各自不同的控制命令,称为“微命令”
运算部件:由于采用了多周期结构,故总线可以采用分时复用的结构。
控制部件:
由指令译码器 指令rom和微指令跳转逻辑电路和微指令地址寄存器构成,初始时刻地址寄存器全为0,将第一条指令取出至总线后,第一条指令会指导后续指令地址跳转,并完成相应操作。如下图所示,为顺序跳转的低位指令,若要使用p测试位跳转,详情参照微指令真值表。由于微地址寄存器为“异步寄存器”构成:如下图所示;P跳转字段控制异步端。故当且仅当P字段为000000时,按顺序地址执行。
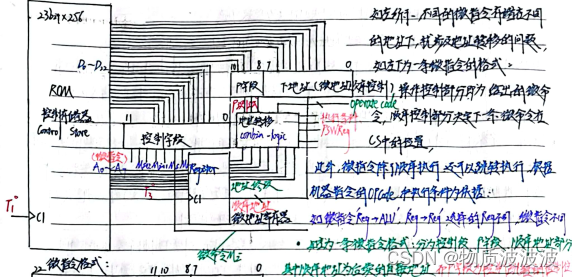


总体结构如左图所示;在rom内编写常见机器指令的微命令,将一条机器指令的执行拆分为若干周期,每个周期产生不同的控制信号:如左所示rom.mif文件内,编写了add、sub、move指令的微命令;
以add指令为例:第一拍读出指令,第二拍送操作数1,第三拍送操作数2,第四拍写回结果。机器指令全周期有效,故应设置专门的指令寄存器,保存机器指令。
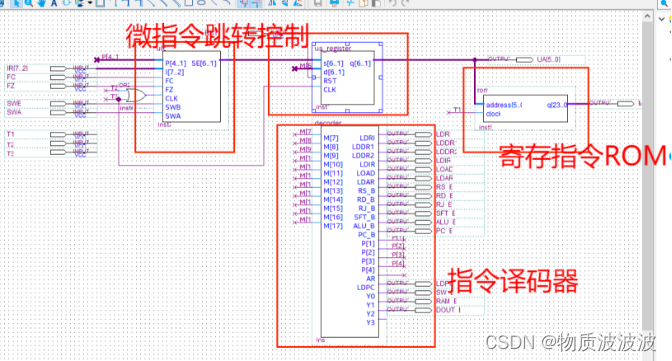
而微命令仅在时钟周期内有效(即节拍内有效)
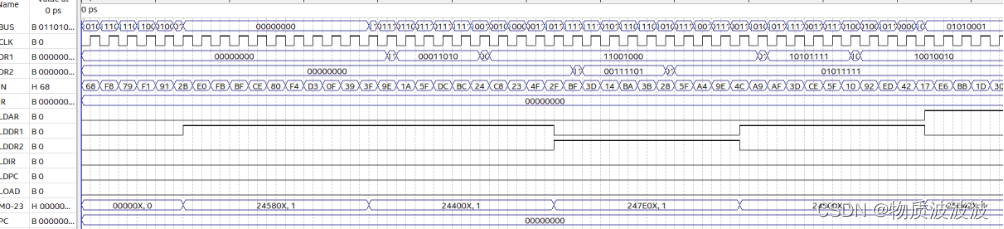
运行结果如下图所示:环形脉冲发生器在总时钟clk下产生t1-----t4四拍脉冲,微地址寄存器数据顺序地址正确读出:00000-000001-000010-…
在微程序的作用下,四个节拍为一个指令周期完成一条机器指令。

**
总结与感悟
**
硬件和软件实现的功能在逻辑上是等效的,而非等价。算法用软件实现,或是用硬件实现,在逻辑上完全等效,但是在速度,成本上不相同。如在现代处理机中,cache的管理算法完全由硬件实现,对高级程序开发人员完全透明,还比如从Intel PentiumII开始,处理器加入了MMU(Memory Mengment Unit)内存管理单元模块,为了支持操作系统的逻辑地址寻址。软硬件的发展是相互促进的:处理机的发展总是和操作系统、固件算法等底层程序息息相关。
综上,要设计出一个性能优秀的处理器,不仅要掌握底层硬件的设计和布局数据通路,还要熟悉软件层面的算法与应用,才能有针对性的设计出对软件更友好,更高效的处理器。这也就是《计算机系统结构》中常提及的“由中间向两边设计”设计方法。
在本次课程设计过程中,我没有借用schoolMIPS的源文件,而是从头编写MIPS架构下的处理器,具体实现细节完全由自己构想设计。在完成了本次实验后:我对本次作品比较满意:完成了传统单周期处理机的必要部件,如ALU、General Register等结构,完成了三十一条汇编指令的硬件设计。并在此基础上扩充了多周期MIPS处理机的设计,并尝试编写流水线控制器等。但是缺点在于没有设计对操作系统的支持部件:如MMU、内核级指令等内容,在后续的设计中有待提升。

