
- 1c++打开图片查看器并查看图片_shellexecute打开图片
- 2fiddler配置及使用教程_fiddler urlreplace
- 3【Android开发】三种方法实现Button点击事件响应
- 4更改以太网共享属性家庭网络连接值,解决电脑笔记本连接校园网显示无internet无法开热点或开热点手机无ip分配问题_以太网需要操作没有internet校园网
- 5如何读取并拷贝STM32的FLASH内容——使用STM32 ST-LINK Utility工具_stlink utility读取程序
- 6nacos迁移
- 7Android中的Service是如何启动的_一个apk,直接启动service启动不了,只有先打开activity,才能启动service
- 8自带骚气的Python操作:把视频转换成字符动画
- 9代码随想录刷题Day14 | 二叉树的递归遍历,迭代遍历
- 10vuejs前后端数据交互之提交数据_el-form提交表单数据
机器学习与大数据基础知识(一)_大模型 基于规则
赞
踩
大数据时代究竟改变了什么?
-
改变的是思维
-
增加了数据重要性:数据资源--->数据资产(增值)
-
改变了方法论:基于知识的理论完美主义--->基于数据的历史经验主义
-
改变了数据分析: 统计学(抽样)--->数据科学(大数据)
-
改变计算智能:复杂算法--->简单算法(MapReduce)
-
改变决策方面:基于目标决策--->基于数据决策
-
改变业务方面:基于业务的数据化--->数据主导业务
-
产业竞合:以战略为中心--->以数据为中心
大数据的4V特征
- 数据量大:数据量从TB增长到PB,ZB、使用HDFS分布式文件系统存储
- 数据种类多
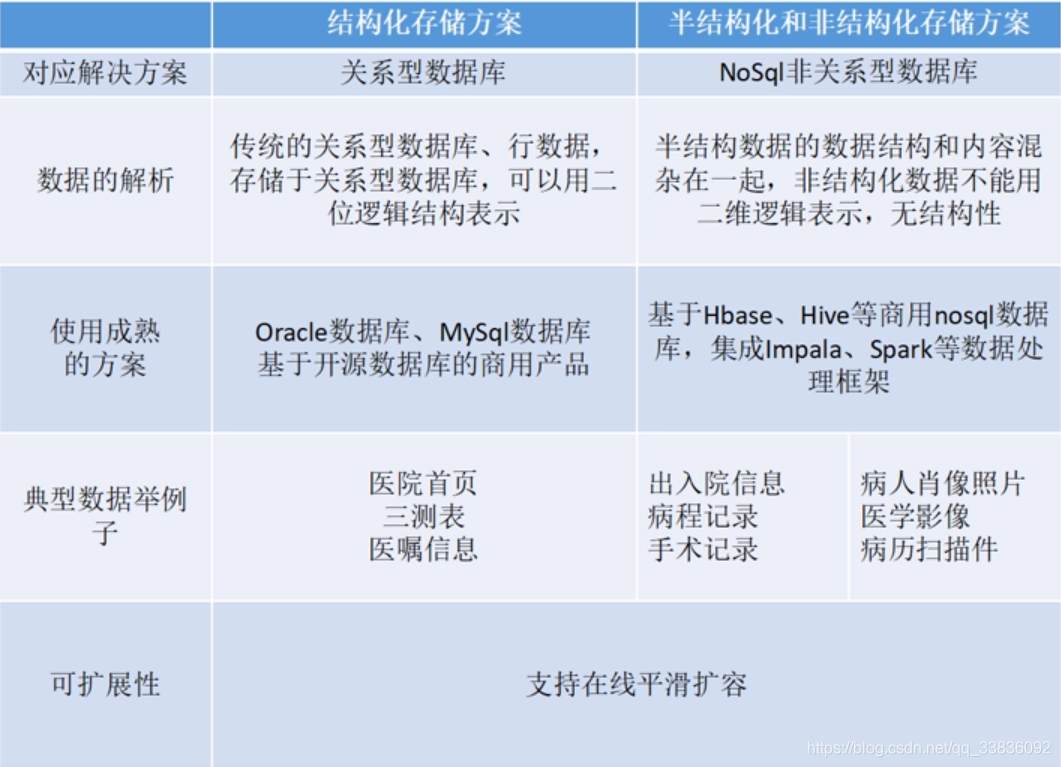
结构化的数据:Mysql为主的存储和处理
非结构化数据:包括图形、音频等;使用 HDFS存储,使用MapReduce,Hive分析
半结构化数据:包括XML,HTML;使用 HDFS存储,使用MapReduce,Hive,Spark分析
- 速度快
数据的增长速度快:TB-PB-ZB、HDFS
数据的处理的速度快:MR-Hive-Pig(结构化数据)-Impala;Spark-Flink(实时处理)
- 价值密度低
价值密度=有价值的数据/全部数据。分母快速增长导致价值密度低,同时总价值提高
机器学习算法解决价值密度低:构建模型
大数据与机器学习关系:大数据做基础的数据存储,数据的统计计算;机器学习从大量的数据里面挖掘有价值的数据
大数据项目架构-以电信日志分析为例
项目名称:电信日志分析系统
项目描述:电信日志分析系统是以电信用户上网所产生的数据进行分析和统计计算,数据主要是来源于用户上网产生的访问日志和安全日志,通过hadoop大数据平台完成日志的入库、处理、查询、实时分析、上报等功能,达到异常IP的检测、关键词过滤、违规违法用户的处理等,整个项目的数据量在1T-20T左右,集群数量在10台到20台。
项目架构分析:
- 数据采集层
一、用户访问日志数据
数据格式:地区码201|用户ip|目的ip|流量|...
数据采集的方式:采用的是ftp的方式上传到服务器
数据上传的时间:每个小时上传上一个小时的数据
小文件的合并:通过shell完成小文件的合并
监控文件:JNotify
二、用户安全日志数据
当用户触犯电信部门指定的制度,违反国家法律法规。
数据采集方式:Socket....C++完成数据采集先缓存到内存在到磁盘
数据格式:加密码:加密形式abc:1134234234
三、网卡配置:千兆或万兆网卡
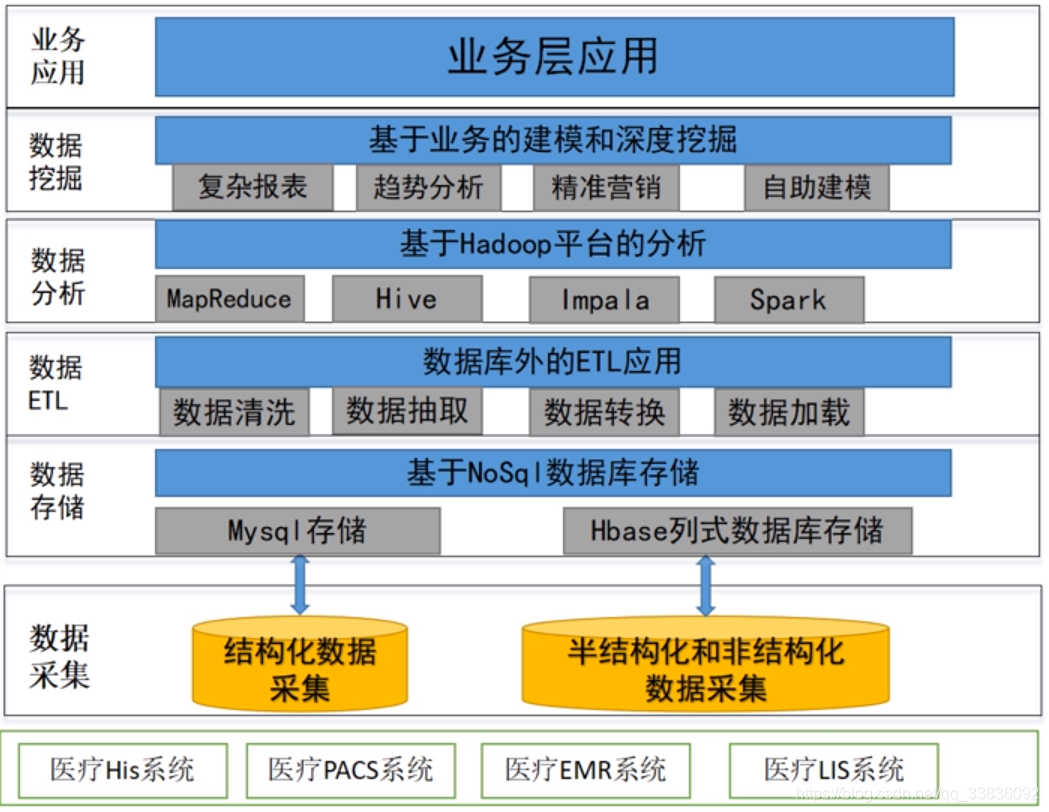
- 数据存储层
HDFS分布式文件系统
- 数据分析层
MapReduce:完成数据清洗的工作,如缺失字段的处理、异常值的处理等
MR和Redis进行交互:完成地区码201和地区名字的转换(覆盖map函数,将地区码转换成地区)
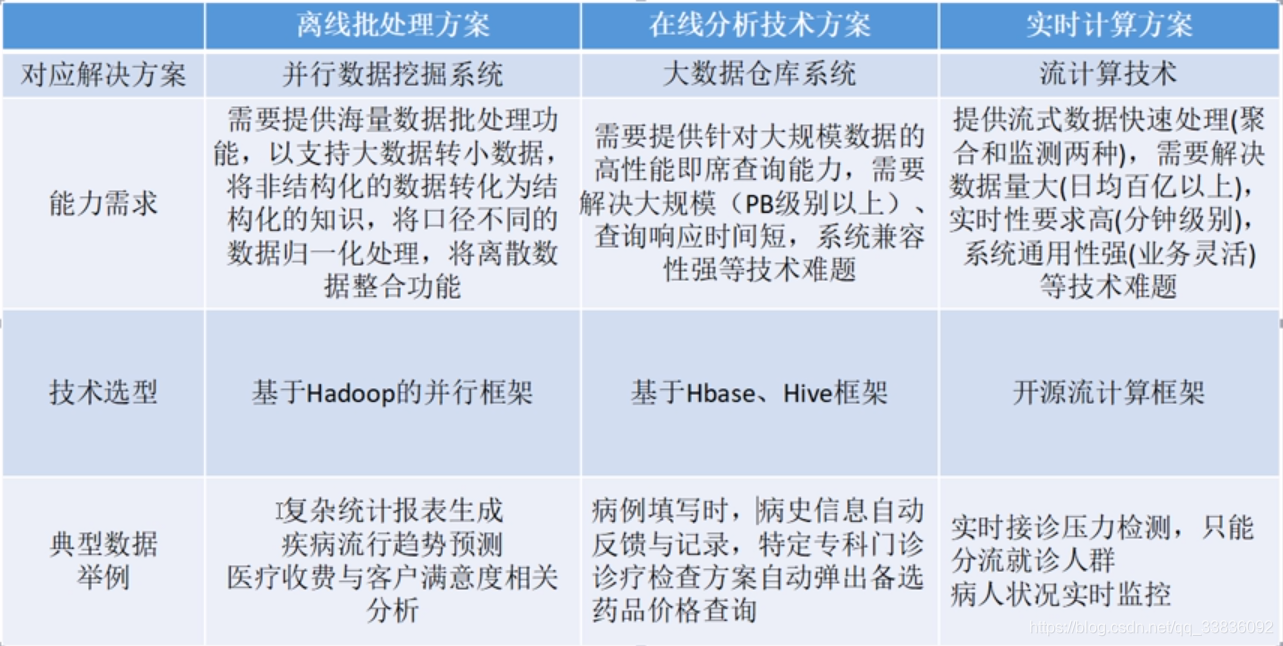
数据到Hive与Impala中做处理:Hive:1.处理实时性要求不高统计需求2.HIVE做一些小文件合并3.将Hive处理后的数据进一步加载到其他业务系统处理;Impala:实时性较高的需求
数据到HBASE:完成固定条件查询
数据到Spark中实时查询:解决了单一数据源在40个指标的情况下完成内存中的计算和topon的求取
OOZIE:进行任务调度
Mysql:Hive元数据存放,OOZIE元数据存放
接口机:用于提交任务的机器:提交OOZIE任务:MR-Hive-Impala;提交Spark任务
- 机器学习层
位于大数据上层,完成的是大数据基础的数据存储和数据计算之上,通过数据结合机器学习算法构建机器学习模型,利用模型对现实事件作出预测
- 数据展示层
Oracle+JAVA+SSM做框架
hive使用sqoop存储进Oracle
impala可使用JDBC方式直接与web交互
HBASE使用协处理器+thrift
- 项目职责
重点负责:实时or离线
处理分析了哪些字段,通过何种手段进行分析
- 项目优化
修改成 HDFS+Spark平台一站式搞定
- 集群部署建议
1.主节点互备(NN和RN)
2.需要较大网络宽带的机器通常配置两块网卡,至少是千兆网,并且分别地属于不同的网段(接受数据和put数据不能在同一个网段)
3.需要较大内存的服务组件最好不要集中在一台机器上
4.cpu消耗较高的组件一定要单独在一台机器上
5.采集机同时可以当做接口机使用
6.如果有非hadoop的组件需要使用,建议单独分配机器或者直接使用hadoop普通存储机
7.组件的元数据库一定要有备份机,最好不要使用hadoop机器
8.根据删除数据的重要性可以考虑是否使用垃圾桶机制(节省存储空间)

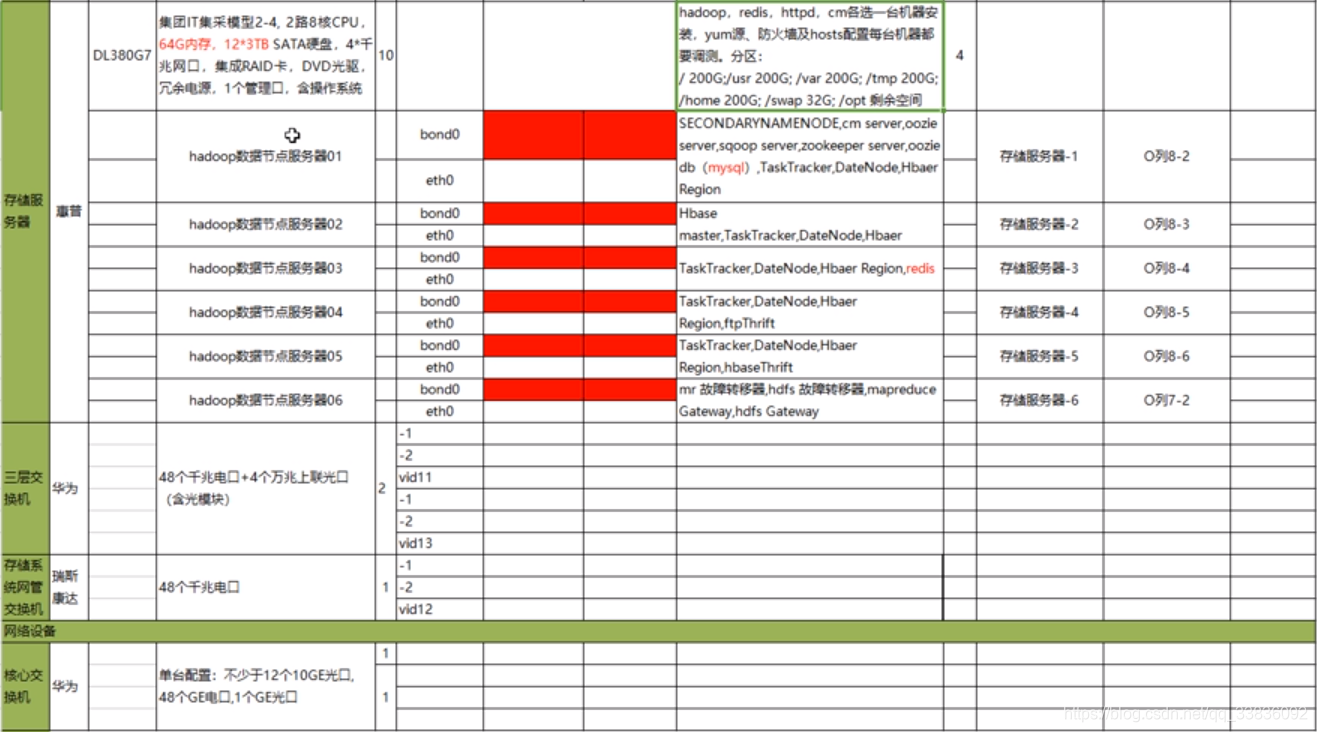

大数据项目架构-以医疗项目为例
分析数据存储

人工智能的发展
人工智能的三次浪潮:跳棋:专家系统,象棋:统计模型,围棋:深度学习
人工智能的场景应用:图形识别-分类;无人驾驶;智能翻译;语音识别;医疗智能诊断;数据挖掘
人工智能、机器学习、深度学习概念区别
-
人工智能(暴力)>机器学习(加入算法)>深度学习(一种方法)
-
机器学习只是人工智能的一个分支,机器学习分支还有数据挖掘和模式识别
-
深度学习是机器学习的一种方法,是为了解决机器学习做不好的领域如图片识别
-
人工智能如何落地?--依靠机器学习
数据分析、数据挖掘、机器学习
-
数据:即观测值,测量值
-
信息:可信的数据
-
数据分析:数据-->信息
-
数据挖掘:信息-->到有价值的信息
-
模式识别:图像识别
总结:数据----数据分析---信息---数据挖掘/模式识别---有价值的信息
机器学习和深度学习方法能解决数据挖掘/模式识别这些事情
什么是机器学习?
-
人类学学=大脑+经验
-
机器学习=机器+学习=CPU+GPU(图形图像处理器)+数据+算法
-
概念:机器学习致力于研究如何通过计算的手段,使用算法和数据构建模型,通过模型达到预测的功能
什么不是机器学习?
-
机器学习:从已有的经验中学习经验,从经验去分析。如判断收到邮件是否是垃圾邮件,自动标记facebook中的照片,考虑购物习惯推荐商品,预测汇率涨不涨,根据病症判断是哪类疾病
-
确定问题不是机器学习:计算每种箱子的个数
-
数值计算问题不是机器学习:计算一组数的平均值大小
判断方法:可以通过是否具有预测过程判断是否是机器学习
基于规则和基于模型
-
基于规则学习:专家发现规律制定规则,是采用硬编码方式进行学习
-
基于模型学习:通过数据构建机器学习模型,通过模型进行预测
-
X(自变量,定义域--->特征)----f(函数、映射---->模型)--->Y(因变量、值域--->结果)
-
最终目的是求解y=kx+b中的k和b
-
机器学习学习的是什么?学习的是模型。学习的是模型中的k和b,即模型参数

