
- 1Linux USB驱动开发_usb_class_per_interface
- 2检测头篇 | YOLOv8 添加 大目标检测头 | 小目标检测头 | 4头BiFPN
- 3HDC2021技术分论坛:DevEco Testing,新增分布式测试功能
- 4语音识别功能测试:90%问题,可以通过技术解决_测试语音识别
- 5metasploit怎么用? 基础(auxiliary、exploits、meterpreter)篇 (゚益゚メ) 渗透测试
- 6联邦学习介绍
- 7猛攻生态,鸿蒙单挑安卓
- 8Android 获取设备信息、获取手机信息_apk怎么获取手机的硬件信息,都会获取哪些硬件信息
- 92种Android图表的简单介绍+折线图、饼图的例子,高级程序员面试题_com.github.mikephil.charting.charts
- 10零基础开始学习鸿蒙开发-自定义List_鸿蒙list单选
YOLOv1学习
赞
踩
YOLOv1
优点:
- 快
- 全图推理,背景错误率低
- 泛化能力强
每个图像固定大小 448*448,系统将输入图像分成S × S网格。
如果一个物体的中心落在一个网格单元中,这个网格单元负责检测这个物体
评价指标
Precision
Precision (准确率) 表示检测到的正样本中,实际为正样本的比例。
计算公式为:Precision = TP / (TP + FP),其中 TP(True Positives)表示正确检测到的目标数量,FP(False Positives)表示错误检测到的非目标数量。
Recall
Recall (召回率) 表示实际正样本中,被正确检测出的比例。
计算公式为:Recall = TP / (TP + FN),其中 FN(False Negatives)表示未被检测到的目标数量。
AP
PR曲线的绘制
在目标检测中,Precision-Recall (PR) 曲线是一种评估模型性能的工具,它展示了在不同召回率水平下模型的准确率表现。为了绘制这条曲线,我们需要根据不同的阈值计算一系列的准确率和召回率值。
以下是绘制 Precision-Recall 曲线的步骤:
-
计算置信度分数:对于给定的目标检测模型,对测试数据集中的每个图像进行预测,为每个预测的边界框分配一个置信度分数,表示模型认为该边界框包含目标的可能性。
-
排序:将所有预测的边界框根据其置信度分数从高到低排序。
-
设置阈值:从最高的置信度分数开始,逐渐降低阈值。每个阈值都会对应一组被认为是正样本的预测边界框(即置信度分数高于阈值的边界框)。
-
计算 Precision 和 Recall:对于每个阈值,计算相应的 Precision 和 Recall 值。具体来说,Precision 是在当前阈值下,正确预测的边界框数量占所有预测为正样本的边界框数量的比例。Recall 是在当前阈值下,正确预测的边界框数量占实际正样本总数的比例。
-
绘制曲线:将每个阈值对应的 Precision 和 Recall 值作为一个点绘制在图上,横坐标为 Recall,纵坐标为 Precision。连接所有这些点,就得到了 Precision-Recall 曲线。
这条曲线提供了一个直观的方式来查看模型在不同召回率水平下的准确率表现。理想情况下,我们希望这条曲线尽可能靠近右上角,这意味着模型在高召回率下仍然能保持高准确率。在实际应用中,通常需要在准确率和召回率之间做出权衡,选择一个合适的阈值以满足特定的需求。
对于每个类别,我们可以根据不同的阈值绘制出 Precision-Recall 曲线。AP 是这条曲线下面积的近似值,反映了模型在不同召回率水平上的准确率表现。AP 的值越高,表示模型的性能越好。
不同的阈值会影响被认为是 True Positive(正确检测到的正样本)的样本数量。
当阈值较高时,只有置信度非常高的预测才会被视为正样本(即被认为是正确的检测)。这通常会导致较少的样本被认为是 True Positive,但同时也减少了 False Positive(错误地将负样本预测为正样本)的数量,因此准确率(Precision)较高。然而,这也可能导致很多实际上是正样本的目标被错过,从而降低了召回率(Recall)。
相反,当阈值较低时,即使置信度不是很高的预测也会被视为正样本。这会增加被认为是 True Positive 的样本数量,提高召回率,但同时也增加了 False Positive 的数量,从而降低准确率。
mAP
在目标检测任务中,通常需要检测多个类别的对象。mAP 是对所有类别的 AP 值取平均得到的。具体来说,如果有 N 个类别,那么 mAP = (AP1 + AP2 + … + APN) / N。mAP 考虑了所有类别的检测性能,是一个综合性能指标,常用于比较不同目标检测模型的效果。
总的来说,mAP 是一种衡量目标检测模型在多个类别上整体性能的指标,它考虑了模型的准确率和召回率,是目标检测领域中非常重要的评估指标之一。
置信度分数
置信度分数定义为 P r ( o b j e c t ) ∗ I O U p r e d t r u t h Pr(object)*IOU_{pred}^{truth} Pr(object)∗IOUpredtruth, I O U IOU IOU 是交并比, P r ( o b j e c t ) Pr(object) Pr(object) 是模型认为该网格存在物体的概率,
统一检测框架
每个网格单元预测 B 个边界框和这些框的置信度得分。
每个边界框由5个预测组成:x, y, w, h和置信度。(x, y)坐标表示相对于网格单元边界的框的中心。宽度和高度是相对于整个图像预测的。最后,置信度预测表示预测框与任何真实框之间的IOU。
每个网格单元还预测 C 个条件类别概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i |Object) Pr(Classi∣Object)。这些概率取决于包含对象的网格单元。
在测试时,将条件类别概率与单个框置信度预测相乘

这提供了每个边界框特定类别的置信度分数。这些分数编码了该类别出现在框中的概率以及预测框与该对象的匹配程度。
置信度得分反映了模型对于边界框内有目标存在的信心,以及边界框的定位准确性。
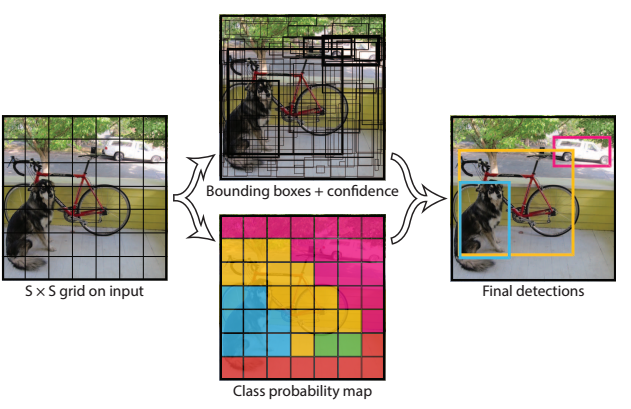
这张图展示了YOLO(You Only Look Once)目标检测算法的工作流程,具体步骤如下:
-
输入图像和网格划分:
- 左侧的图展示了原始输入图像。YOLO算法首先将输入图像划分为一个 S×S 的网格(在这个示例中,网格可能比实际的 YOLO 网格粗)。
- 每个网格单元负责检测那些中心点落在该单元格内的目标。
-
边界框和置信度预测:
- 中间的图描绘了由神经网络对每个网格单元进行的预测。神经网络在每个单元格中预测了B个边界框,每个边界框都有其对应的置信度得分。
- 这些置信度得分反映了模型对于边界框内有目标存在的信心,以及边界框的定位准确性。
-
类别概率映射:
- 图像底部展示了一个颜色编码的类别概率映射。每个网格单元还预测了属于各个类别的概率。
- 当网络在某个单元格检测到目标时,它会将该单元格的类别概率与边界框的置信度相乘,得出最终的类别置信度得分,这个得分反映了该边界框包含特定类别目标的信心。
-
最终检测:
- 右侧的图展示了最终的检测结果。这一步涉及去除置信度低的预测以及执行非极大值抑制(Non-maximum Suppression, NMS)以消除重复的检测。
- 最终,YOLO输出了图像中识别的对象和它们的位置(用边界框表示),并标出了各个对象的类别。
总结:YOLO通过一次性的前向传播过程对整个图像进行预测,生成边界框、置信度和类别概率,然后基于这些信息输出最终的检测结果,这使得它既快速又有效。
系统将检测建模为回归问题。它将图像划分为S × S网格,并为每个网格单元预测B个边界框、这些框的置信度和C类概率。这些预测被编码为S × S × (B * 5 + C)张量。
详细解释一下S×S×(B * 5 + C)这个张量的结构:
-
S×S:
- 表示将输入图像划分成了S×S个网格单元(grid cells)。每个网格单元负责检测其区域内的目标。
-
B:
- 指的是每个网格单元预测的边界框数量。每个边界框包含物体位置和大小的信息。
-
5:
- 每个边界框由5个预测值组成:x, y, w, h和置信度(confidence)。
- 其中x和y代表边界框中心相对于所在网格单元的位置。
- w和h代表边界框的宽度和高度,通常相对于整个图像的宽度和高度进行缩放。
- 置信度表示模型预测的边界框内存在目标的概率,以及预测的边界框与任何地面真相框(ground truth box)的交并比(IOU)。
-
C:
- 表示模型能够识别的类别数量。对于每个网格单元,模型会预测一个C维的向量,表征网格单元中对象属于每个类别的概率。
因此,对于S×S网格中的每个单元,模型都会输出B个边界框,每个边界框有5个预测值,再加上C个类别概率,共计B * 5 + C个预测值。这就是为什么模型的最终输出是一个 S×S×(B * 5 + C) 的张量。该张量汇总了关于位置、大小、置信度和类别概率的所有预测,是模型进行目标检测所需的全部信息。
为了评估 PASCAL VOC上的YOLO,作者设置 S = 7, B = 2。PASCAL VOC有20个标签类,所以 C = 20。所以最终的预测是一个7 × 7 × 30张量。
网络结构
网络有24个卷积层,后面是2个全连接层。
作者没有使用GoogLeNet使用的初始模块,而是简单地使用1 × 1约简层,然后是3 × 3卷积层
作者还训练了一个快速版本的YOLO,旨在推动快速目标检测的界限。快速YOLO使用了一个卷积层更少的神经网络(9层而不是24层),这些层中的卷积滤波器更少。除了网络的大小,YOLO和Fast YOLO的所有训练和测试参数都是相同的。
作者的检测网络有24个卷积层,后面是2个全连接层。交替的1 × 1卷积层减少了前一层的特征空间。作者在 ImageNet 分类任务上以一半的分辨率 (224 × 224输入图像) 预训练卷积层,然后将分辨率提高一倍用于检测。
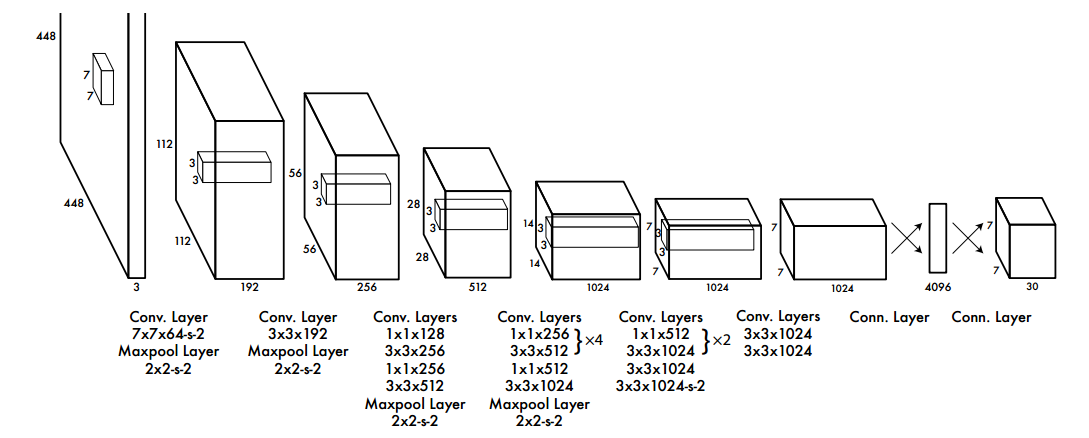
如图,网络的最终输出是7 × 7 × 30的预测张量。
这张图展示了YOLOv1目标检测网络的结构。这个结构是典型的卷积神经网络(CNN),由多个卷积层(Convolutional Layers)、池化层(Maxpooling Layers)以及全连接层(Connected Layers)组成。下面是各个部分的详细解释:
-
输入:
- 网络接受一个固定尺寸的图像作为输入,这里是448×448像素。输入图像的深度是3,对应于常规的RGB三通道。
-
卷积层和池化层:
- 第一个卷积层使用了7×7的滤波器(filter size),64个通道,步长(stride)为2。卷积层之后是一个2×2的最大池化层,步长为2,用于降低空间维度。
- 网络中交替出现的卷积层和池化层负责提取图像中的特征。卷积层的滤波器大小和数量各不相同,设计用于捕获不同层次的视觉特征。在每个卷积步骤之后,通常会跟着一个池化层,进一步减少数据的空间维度。
-
卷积核和步长:
- 在网络结构中,每个卷积层后面通常都会标注其使用的卷积核(kernel)大小和数量,以及步长。例如,“3x3x192”表示使用了192个3x3大小的卷积核;“1x1x128”表示使用了128个1x1大小的卷积核。步长描述了卷积核在图像上移动时的距离。
-
全连接层:
- 经过多次卷积和池化之后,网络结构图中出现了全连接层。在YOLO中,全连接层用于将学到的高级特征映射成输出预测。例如,“4096”表示一个具有4096个神经元的全连接层。
-
输出:
- 最终,网络的输出是一个7×7×30的张量,正如YOLOv1论文中所述。如果S=7,B=2(每个网格单元预测两个边界框),C=20(20个类别),那么输出张量的维度就是7×7×(2*5+20)=7×7×30。这个输出包含了网格中每个单元预测的边界框信息和类别概率。
总结:这张图详细描述了YOLOv1网络的结构和各层的具体配置。这个网络通过提取和整合特征,最终产生了用于目标检测的预测。
训练
作者在 ImageNet 1000类竞争数据集上预训练卷积层。对于预训练,作者使用图3中的前20个卷积层,然后是平均池化层和全连接层。对该网络进行了大约一周的训练,并在ImageNet 2012验证集上实现了单个作物前5名的准确率达到88%,与Caffe的Model Zoo中的GoogLeNet模型相当。
然后作者将模型用于执行检测。Ren等人表明,在预训练网络中同时添加卷积层和连接层可以提高性能。
因此作者添加了四个卷积层和两个随机初始化权重的全连接层。检测通常需要细粒度的视觉信息,因此作者将网络的输入分辨率从 224 × 224 提高到 448 × 448。
最后一层预测类别概率和边界框坐标。作者通过图像的宽度和高度对边界框的宽度和高度进行归一化,使它们落在 0 和 1 之间。将边界框的 x 和 y 坐标参数化为特定网格单元格位置的偏移量,因此它们也被限定在0和1之间。
对最后一层使用线性激活函数,所有其他层使用以下 leaky rectified linear activation:
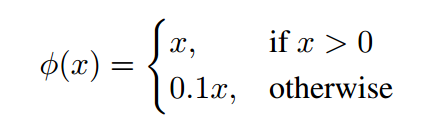
作者对模型输出的平方和误差 sum-squared error 进行优化,使用 sum-squared error 的原因是易于优化,然而,它并不完全符合最大化平均精度的目标。它将定位误差与分类误差等同地加权,这可能不是理想的。
在YOLOv1的论文中,当提到优化目标检测的sum-squared error(平方和误差),它是在说模型的训练过程中使用了一种特定的损失函数来度量和优化模型预测的准确性。
Sum-squared error(SSE)是一种常见的损失函数,在目标检测的上下文中,它指的是模型输出和实际值之间差异的平方和。具体来说,对于目标检测,SSE将计算以下几项的误差:
- 边界框的位置误差:模型预测的边界框位置(中心点的x和y坐标)和实际边界框位置之间的差异。
- 边界框的尺寸误差:模型预测的边界框宽度和高度与实际边界框之间的差异。
- 置信度误差:模型对于边界框中包含目标的置信度预测和实际情况(通常用交并比IOU来表示)之间的差异。
- 分类误差:模型预测的类别概率分布和目标的实际类别之间的差异。
YOLOv1论文中指出,虽然平方和误差易于优化(因为它是可微的且通常是凸形的),但它并不完全符合模型的最终目标,即最大化平均精度(average precision)。这是因为平方和误差对所有类型的误差给予了相同的权重,而在实际情况中,定位误差(如边界框位置和尺寸的预测不准确)和分类误差(如错误的类别预测)对模型性能的影响可能并不相同。例如,在某些情况下,一个小的定位误差可能不会显著影响模型的实用性,但一个分类错误可能会导致完全不同的输出,这在实际应用中可能是不可接受的。
总结来说,平方和误差是一种在模型训练时评价预测准确性的方法,它通过计算预测值和真实值之间的平方差之和来实现,但它可能不会完全反映出在目标检测任务中最重要的性能指标。
此外,在每张图像中,许多网格单元不包含任何对象。这使得这些单元格的“置信度”得分趋近于零,往往压倒了包含对象的单元格的梯度。这可能导致模型不稳定,导致训练在早期出现分歧。
为了解决这个问题,作者增加了边界框坐标预测的损失,减少了不包含对象的框的置信度预测的损失。我们使用两个参数, λ c o o r d λ_{coord} λcoord和 λ n o o b j λ_{noobj} λnoobj来实现这一点。设 λ c o o r d = 5 λ_{coord}=5 λcoord=5, λ n o o b j = 0.5 λ_{noobj}=0.5 λnoobj=0.5。
附注:
在 YOLOv1 的损失函数中, λ coord \lambda_{\text{coord}} λcoord 和 λ noobj \lambda_{\text{noobj}} λnoobj 是两个权重因子,用于调整损失函数中不同部分的相对重要性。它们是超参数,通常在训练前设定,并在训练过程中保持不变。
-
λ coord \lambda_{\text{coord}} λcoord:
- 这个权重因子用于增加边界框位置(中心的 x 和 y 坐标)和尺寸(宽度 w 和高度 h)预测误差的重要性。在实践中,定位一个对象的精确位置通常比预测其存在更重要,因此 λ coord \lambda_{\text{coord}} λcoord 通常被设置为一个大于1的值。这是为了确保模型在训练过程中尤其关注边界框的精确位置和大小,因为这直接影响到模型性能的关键部分。
-
λ noobj \lambda_{\text{noobj}} λnoobj:
- 由于大部分网格单元不包含任何对象,如果所有这些网格的置信度误差被赋予相同的权重,它们将在损失函数中占主导地位。为了防止这种情况,YOLOv1使用 λ noobj \lambda_{\text{noobj}} λnoobj 来减少不包含对象的网格单元的置信度误差对总损失的贡献。由于这种网格单元非常多, λ noobj \lambda_{\text{noobj}} λnoobj 通常被设置得比较小,以平衡损失函数的各部分贡献。
通过这种方式,YOLOv1 的损失函数可以更加重视边界框的精确性,并减少那些不包含对象的网格单元的干扰,使得模型更关注于真正包含对象的网格单元。这有助于提高模型对对象位置的敏感性,同时降低背景误报。
平方和误差在大的边界框和小的边界框中的权重也相等。误差度量应该反映出大边界框里的小偏差比小边界框里的小偏差影响小。为了部分解决这个问题,作者预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
在YOLOv1中,网络的设计允许每个网格单元(grid cell)预测多个边界框(bounding boxes)。这意味着每个网格单元不仅可以检测是否有物体存在,还可以预测物体的位置和尺寸。然而,在训练时,我们不需要或不希望每个网格单元的所有边界框预测器都对同一个物体做出响应,因为这会造成预测冗余和效率低下。
为了解决这个问题,YOLOv1采取了以下策略:
-
指定“负责”预测器:当多个边界框预测器对同一个对象做出预测时,我们只选择一个预测器作为“负责”该对象的预测器。这个选择是基于哪个预测器和真实边界框(ground truth)之间的交并比(IOU)最高。交并比是预测框和真实框重叠部分面积与两者联合面积之比,是评价边界框预测准确性的一个指标。
-
预测器的专业化:通过这种方法,每个边界框预测器都会“专门化”来负责不同的任务。一些预测器可能会变得擅长预测特定大小的对象,一些可能擅长特定长宽比的对象,还有一些可能擅长预测特定类别的对象。
-
提高整体召回率:这种专业化有助于提高模型整体的召回率。召回率是指模型正确检测到的正样本数量占所有正样本数量的比例。由于每个预测器都变得更擅长于其负责的特定类型的预测,整体上模型能够更准确地识别出更多的物体。
简单来说,YOLOv1中的每个网格单元可以预测多个边界框,但在训练过程中,每个真实的物体只由一个最佳匹配的预测器负责,这样每个预测器都可以逐渐适应并优化对特定类型物体的预测,提高模型的检测能力。
损失函数
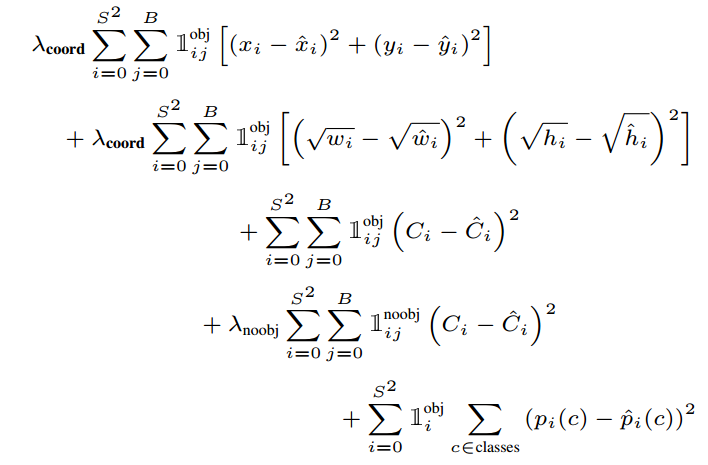
其中
1
i
o
b
j
\mathcal{1}_i^{\mathbb{obj}}
1iobj 表示目标出现在网格
i
i
i,
1
i
j
o
b
j
\mathcal{1}_{ij}^{\mathbb{obj}}
1ijobj 表示网格
i
i
i 对应的第
j
j
j 个边界框预测器对该预测负责
这个图展示了YOLOv1模型的损失函数,它是一个多部分组成的复杂函数,用于训练过程中优化模型的各个参数。这个损失函数包含几个不同的部分,分别针对边界框的位置、尺寸、置信度和类别预测。以下是各部分的详细解释:
-
边界框位置损失(第一项):
- λ coord \lambda_{\text{coord}} λcoord 是一个权重因子,它增加了边界框位置预测误差的重要性。
- ∑ \sum ∑ 符号表示求和,累加网格单元( i i i)和每个单元中的边界框预测器( j j j)。
- 1 i j obj 1_{ij}^{\text{obj}} 1ijobj 是一个指示函数,当第 i i i 个网格单元中的第 j j j 个边界框预测器负责某个对象时为1,否则为0。
- ( x i − x ^ i ) 2 (x_i - \hat{x}_i)^2 (xi−x^i)2 和 ( y i − y ^ i ) 2 (y_i - \hat{y}_i)^2 (yi−y^i)2 分别表示预测的边界框中心与真实边界框中心在 x 和 y 方向上的误差的平方。
-
边界框尺寸损失(第二项):
- 这部分与位置损失类似,也包含权重因子 λ coord \lambda_{\text{coord}} λcoord。
- ( w i − w ^ i ) 2 (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 (wi −w^i )2 和 ( h i − h ^ i ) 2 (\sqrt{h_i} - \sqrt{\hat{h}_i})^2 (hi −h^i )2 表示预测的边界框宽度和高度的平方根与真实值的平方根之间差异的平方。使用平方根是为了减小大边界框的误差对损失的影响。
-
置信度损失(第三项和第四项):
- 当一个边界框预测器负责检测某个对象时(第三项), ( C i − C ^ i ) 2 (C_i - \hat{C}_i)^2 (Ci−C^i)2 表示预测的置信度与实际置信度(通常是IOU)之间差异的平方。
- 当一个边界框预测器不负责检测对象时(第四项), λ noobj \lambda_{\text{noobj}} λnoobj 降低了这种情况下置信度误差的权重。
-
分类损失(最后一项):
- 最后,对于每个网格单元,如果该单元负责检测对象,则计算预测的类别概率 p i ( c ) p_i(c) pi(c) 与实际类别概率 p ^ i ( c ) \hat{p}_i(c) p^i(c) 之间差异的平方和。
总的来说,YOLOv1的损失函数是多目标的,旨在同时优化定位精度(位置和尺寸),确保检测到的对象的置信度,以及分类的准确性。通过这种方式,YOLO可以通过一个统一的框架来学习预测边界框和类别。
附注:如何理解下面这段话
Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier). It also only penalizes bounding box coordinate error if that predictor is “responsible” for the ground truth box (i.e. has the highest IOU of any predictor in that grid cell).
这段话描述了YOLOv1中损失函数对不同误差类型的惩罚(penalize)是有条件的,而这些条件取决于网格单元(grid cell)中是否存在对象,以及边界框预测器(bounding box predictor)是否对实际边界框(ground truth box)负责。
以下是详细解释:
-
分类误差的条件惩罚:
- YOLOv1模型的损失函数仅在一个网格单元中存在对象时才惩罚分类误差。这就是所谓的条件类别概率:如果网格单元中没有对象,即使预测的类别概率与实际的不同,损失函数也不会对这种差异进行惩罚。这样可以避免模型在大量不包含对象的网格单元上浪费精力进行分类,从而更专注于实际包含对象的那些单元。
-
边界框坐标误差的条件惩罚:
- 对于边界框的位置(坐标)误差,YOLOv1的损失函数仅惩罚“负责”预测实际边界框的预测器。在每个网格单元中,可能有多个边界框预测器,但只有那个与实际边界框有最高交并比(IOU)的预测器被视为负责该实际边界框。只有“负责”的预测器预测的边界框坐标与实际边界框坐标之间的误差会被计入损失函数。这导致每个预测器专门化,以更好地预测某种特定类型的边界框。
总结:
这意味着损失函数设计成只对那些真正重要的错误进行惩罚,以便网络可以集中学习有助于提高检测性能的预测,而不是对所有的错误都一视同仁。这种方法有助于提高训练效率和最终模型的性能。
作者在PASCAL VOC 2007年和2012年的训练和验证数据集上训练了大约135个epoch。在测试PASCAL VOC 2012年的数据时,还利用2007年VOC测试数据进行训练。在整个训练过程中,使用的批大小为64,动量为0.9,衰减率为0.0005。
学习率计划如下:对于第一个epoch,作者缓慢地将学习率从10−3提高到10−2。
如果从一个高学习率开始,模型经常由于不稳定的梯度而偏离。作者继续用10−2训练75次,然后用10−3训练30次,最后用10−4训练30次。
为了避免过拟合,作者使用 dropout 和广泛的数据增强。在第一个全连接层之后设置速率为0.5的dropout层,可以防止层与层之间的共适应。
对于数据增强,作者引入了原始图像大小的20%的随机缩放和平移。作者还在HSV色彩空间中随机调整图像的曝光和饱和度,最高可达1.5倍。
测试
就像在训练中一样,预测被测试图像的检测只需要一次网络评估。在PASCAL VOC上,网络预测每张图像的98个边界框和每个框的类别概率。YOLO在测试时非常快,因为它只需要一次网络评估,不像基于分类器的方法。
网格设计在边界框预测中加强了空间多样性。通常情况下,一个对象落在哪个网格单元是很清楚的,网络只预测每个对象的一个框。
网格设计增强了边界框预测的空间多样性。 通常,物体属于哪个网格单元是很清楚的,并且网络只为每个物体预测一个框。 然而,一些较大的物体或靠近多个单元格边界的物体可以被多个单元格很好地定位。 非极大值抑制(NMS)可用于修复这些多重检测。 虽然对于 R-CNN 或 DPM 而言,非最大抑制对性能并不重要,但非极大值抑制使 mAP 增加了 23%。
YOLOv1的不足
YOLO对边界框预测施加了很强的空间约束,因为每个网格单元只能预测两个框,并且只能有一个类。这个空间约束限制了模型可以预测的附近物体的数量。模型难以处理成群出现的小物体,比如鸟群。
由于模型学习从数据中预测边界框,它很难推广到新的或不寻常的长宽比或配置的对象。作者提出的模型还使用相对粗糙的特征来预测边界框,因为模型架构从输入图像中有多个下采样层。
最后,当在近似检测性能的损失函数上进行训练时,损失函数在小边界框和大边界框中处理错误是相同的。大边界框里的小错误通常是良性的,但小边界框里的小错误对 IOU 的影响要大得多。
主要错误来源是不正确的定位。
附注,什么是上采样层,下采样层?
在深度学习和计算机视觉中,上采样层(Upsampling Layer)和下采样层(Downsampling Layer)是卷积神经网络中用于改变数据维度的层。
-
下采样层(Downsampling Layer):
- 下采样层通常用于减少数据的空间维度(即宽度和高度),同时保留最重要的信息。这通常通过池化操作(如最大池化或平均池化)实现,池化层会选取某个区域内的最大值或平均值来代表整个区域。
- 下采样有助于减少模型的参数数量和计算量,增加感受野(receptive field),并有助于模型提取和学习输入数据的高级特征。
- 除了池化层,步长大于1的卷积层也可以执行下采样操作。
-
上采样层(Upsampling Layer):
- 上采样层用于增加数据的空间维度(宽度和高度),这在从低维特征映射中恢复到高维空间时很有用,例如在图像分割和生成模型中常见。
- 上采样可以通过多种方式实现,如最近邻插值(Nearest Neighbor interpolation)、双线性插值(Bilinear interpolation)、转置卷积(Transposed convolution,也称为反卷积或去卷积),以及像素shuffle操作。
- 上采样使得网络能够基于低维特征映射构建出更详细的高分辨率输出。
在一些网络结构中,特别是在进行图像分割(如U-Net)或生成模型(如GANs)时,可能会交替使用上采样层和下采样层,以实现从粗糙到精细的信息流和特征恢复。
实验
结论
作者介绍了目标检测的统一模型YOLO。与基于分类器的方法不同,YOLO是在直接对应于检测性能的损失函数上进行训练的,并且整个模型是联合训练的。
Fast YOLO是文献中最快的通用目标检测器,YOLO推动了最先进的实时对象检测。YOLO还可以很好地推广到新的领域,使其成为依赖于快速、健壮的对象检测的应用程序的理想选择。

