
- 1ElementUI图标少,引入阿里矢量图标
- 2静态对象的析构_静态对象析构
- 3android源码下载方式_安卓34 androidmanifest 下载
- 4AndroidVirtual Devices (AVD)创建、设置_as virtual device config
- 5uniapp微信小程序兼容性问题记录(持续记录)_uniapp项目在微信小程序中运行有些方法不兼容怎么办
- 6Structured Denoising Diffusion Models in Discrete State-Spaces【D3PM重点笔记】
- 72024年AI辅助研发趋势:科技革新的引擎
- 8【Git】Github 上commit后,绿格子contribution却不显示?不知道怎么弥补?解决方法在这里
- 9思科华为网络工程师必修-什么是trunk?带你快速了解trunk_思科 trunk
- 10Docker硬件直通:如何在容器中高效利用GPU与硬盘资源_docker 硬件直通
R语言逻辑回归logistic模型ROC曲线可视化分析2例:麻醉剂用量影响、汽车购买行为...
赞
踩
全文链接:https://tecdat.cn/?p=35426
本文利用R语言,通过逐步逻辑回归模型帮助客户分析两个实际案例:麻醉剂用量对手术病人移动的影响以及汽车购买行为预测(点击文末“阅读原文”获取完整代码数据)。
相关视频
通过构建模型并解释结果,我们探究了各自变量对因变量的影响程度。同时,借助ROC曲线可视化分析,评估了模型的预测性能。本文旨在为相关领域的研究提供方法学参考和实际应用指导。
R语言分析麻醉剂用量(conc)对手术病人是否移动(nomove)的影响
在医学实践中,麻醉剂用量的精确控制对于手术过程的顺利进行和病人的术后恢复至关重要。随着医疗技术的不断发展,数据分析和统计学方法在医学研究中的应用日益广泛。本文旨在通过逻辑回归模型,探究麻醉剂用量(conc)对手术病人是否移动(nomove)的影响。逻辑回归是一种广泛应用于二元响应变量分析的统计方法,它可以帮助我们理解自变量与因变量之间的概率关系。本文使用的数据集包含了一组医学数据,其中变量conc表示麻醉剂的用量,而nomove作为因变量,用于表示手术病人是否有所移动。
首先载入数据集并读取部分文件,为了观察两个变量之间关系,我们可以利cdplot函数来绘制条件密度图
head(anesthetic)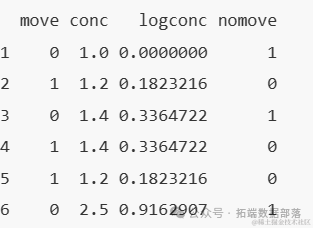
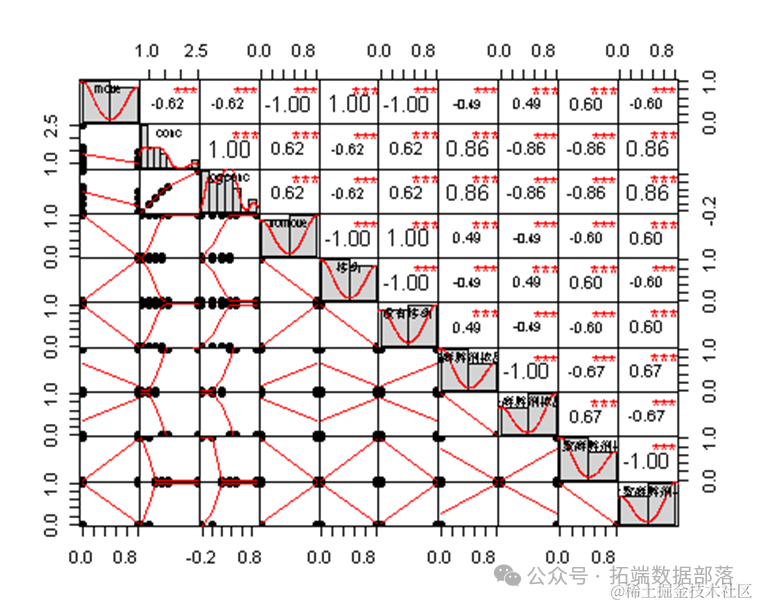
- chart.Correlation(anesthetic,
- method="spearman",
- histogram=TRUE,
- pch=16)
cdplot(factor(nomove)~conc,data=anesthetic,main='条件密度图',ylab='病人移动',xlab='麻醉剂量')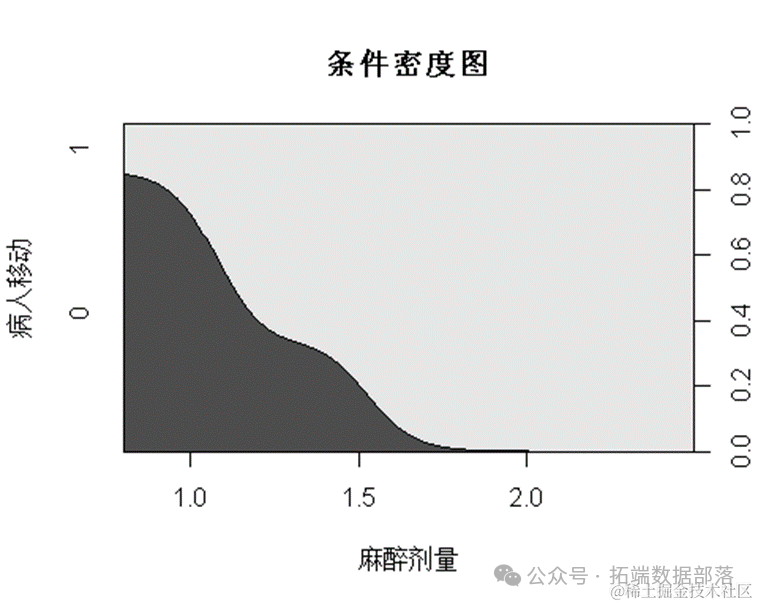
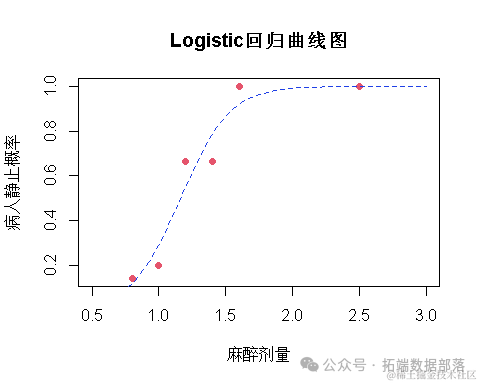
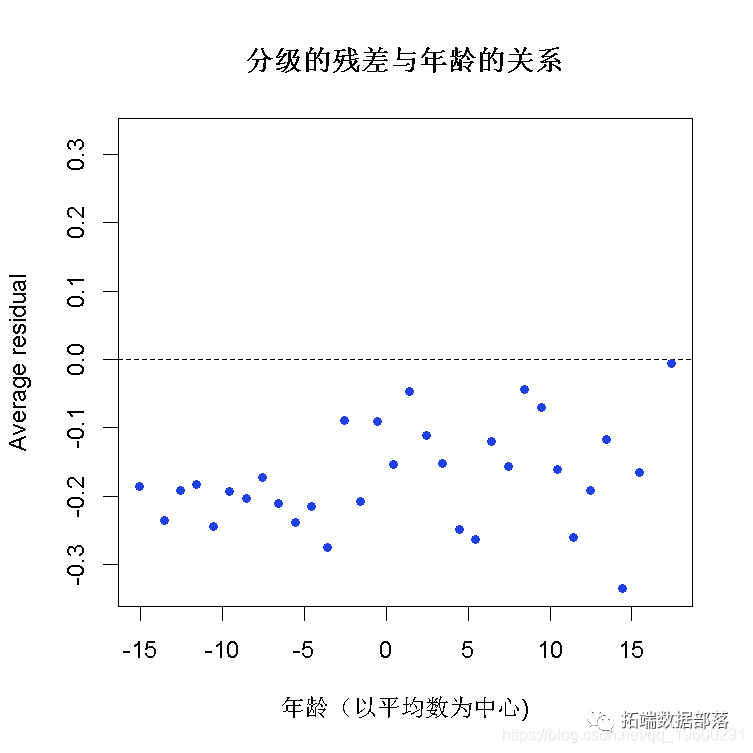
从图中可见,随着麻醉剂量加大,手术病人倾向于静止。下面利用logistic回归进行建模,得到intercept和conc的系数为-6.47和5.57,由此可见麻醉剂量超过1.16(6.47/5.57)时,病人静止概率超过50%。

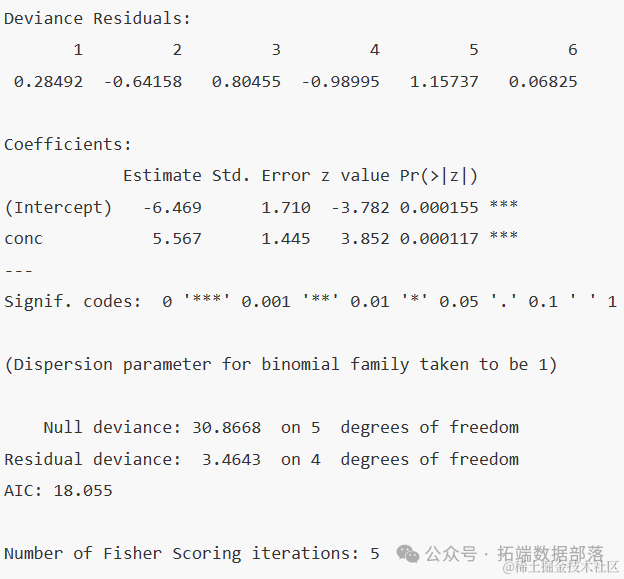
偏差残差:这是逻辑回归模型拟合后每个观测值与模型预测值之间的差异。从最小值-1.76666到最大值2.06900,我们可以看到数据点的分布。通常,我们希望这些残差接近0,并且分布均匀。
系数:
截距 (Intercept) : -6.469。这是当模型中的其他变量都为0时,预测值的起点。这里的截距为负,可能意味着在没有其他因素影响时,某个特定的结果(例如,响应变量为1的概率)是较低的。
conc: 5.567。这是anes1数据集中conc变量的系数。它表示当conc每增加一个单位时,响应变量(通常是二元结果,如1或0)的对数几率平均增加5.567个单位。这通常意味着conc与响应变量之间存在正相关关系。
显著性代码:输出还提供了系数的显著性水平。例如,'***' 表示该系数的p值小于0.001,是非常显著的。这意味着我们可以非常确信conc与响应变量之间的关系不仅仅是偶然的。
分散参数:对于二项分布家族,分散参数通常被设为1,这里也是如此。
偏差统计:
Null偏差:这是仅包含截距的模型的偏差,用于比较完整模型的效果。在这里,Null偏差为82.911,表示在没有其他预测变量的情况下,模型与数据的拟合程度。
残差偏差:这是包含所有预测变量的完整模型的偏差。残差偏差为55.508,比Null偏差小,说明添加conc变量后,模型对数据的拟合度有所提高。
AIC (赤池信息准则) :这是一个衡量模型拟合度的指标,同时考虑了模型的复杂性和拟合度。较低的AIC值通常表示模型更好。这里的AIC为59.508。
Fisher评分迭代次数:在逻辑回归模型拟合过程中,算法使用了5次迭代来收敛到最终的系数估计。
综上所述,anes1数据集中的conc变量与响应变量之间存在显著的正相关关系,而逻辑回归模型在拟合数据方面表现良好。这些结果提供了关于conc如何影响响应变量的有用信息。
对模型做出预测结果
根据不同的临界值threshold来计算TPR和FPR,之后绘制成图
- for (i in 1:n){
-
- threshold=data$prob[i]
-
- tp=sum(data$prob>threshld&data$obs==1)
-
- fp=sum(data$prob>thresold&data$obs==0)
-
- tn=sum(data$prob)
上面的方法是使用原始的0-1数据进行建模,即每一行数据均表示一个个体,另一种是使用汇总数据进行建模,先将原始数据按下面步骤进行汇总
- js
- gate(aneshetic[,c('move','nostheic$conc),FUN=sum)
对于汇总数据,有两种方法可以得到同样的结果,一种是将两种结果的向量合并做为因变量,如anes2模型。另一种是将比率做为因变量,总量做为权重进行建模,如anes3模型。这两种建模结果是一样的。
根据logistic模型,我们可以使用predict函数来预测结果,下面根据上述模型来绘图:
点击标题查阅往期内容

【视频】R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险|数据分享

左右滑动查看更多
01
02
03
04
R语言逻辑回归模型分析汽车购买行为
数据描述
用R语言做logistic regression,建模及分析报告,得出结论,数据有一些小问题, 现已改正重发:改成以“是否有汽车购买意愿(1买0不买)”为因变量,以其他的一些 项目为自变量,来建模分析,目的是研究哪些变量对用户的汽车购买行为的影响较为 显著。
问题描述
我们尝试并预测个人是否可以根据数据中可用的人口统计学变量使用逻辑回归预测是否有汽车购买意愿(1买0不买)。 在这个过程中,我们将:
1.导入数据
2.检查类别偏差
3.创建训练和测试样本
4.建立logit模型并预测测试数据
5.模型诊断
数据描述分析
查看部分数据
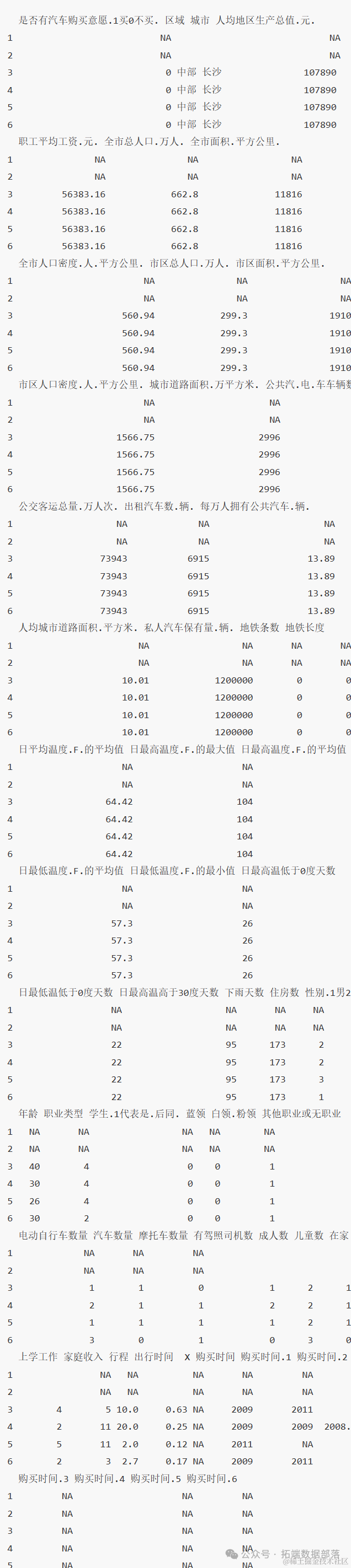
对数据进行描述统计分析:
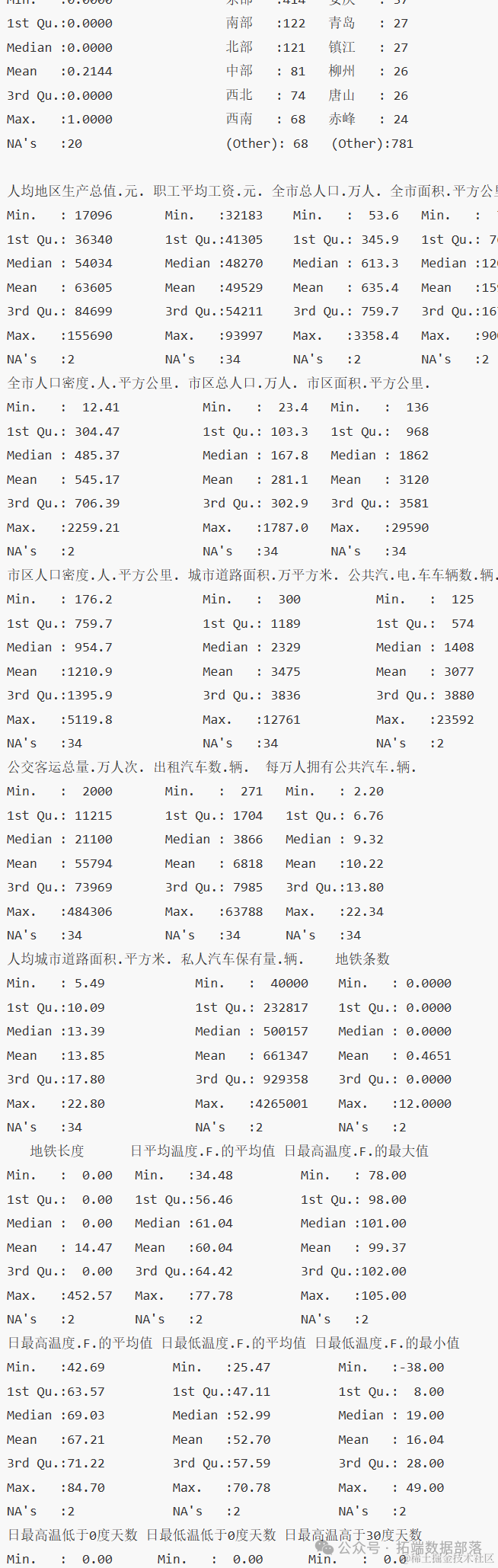
从上面的结果中我们可以看到每个变量的最大最小值中位数和分位数等等。

检查类偏差
理想情况下,Y变量中事件和非事件的比例大致相同。所以,我们首先检查因变量是否有汽车购买意愿中的类的比例。
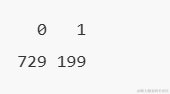
显然,不同购买意愿.人群比例 有偏差 。所以我们必须以大致相等的比例对观测值进行抽样,以获得更好的模型。
建模分析
创建训练和试验样本
解决类别偏差问题的一个方法是以相等的比例绘制训练数据(开发样本)的0和1。在这样做的时候,我们将把其余的inputData不包含在testData 中。
构建Logit模型和预测
全变量模型

从全变量模型的结果来看,可以发现得到的模型变量并不显著,因此需要重新建模
筛选出显著的变量:
逐步回归筛选后模型
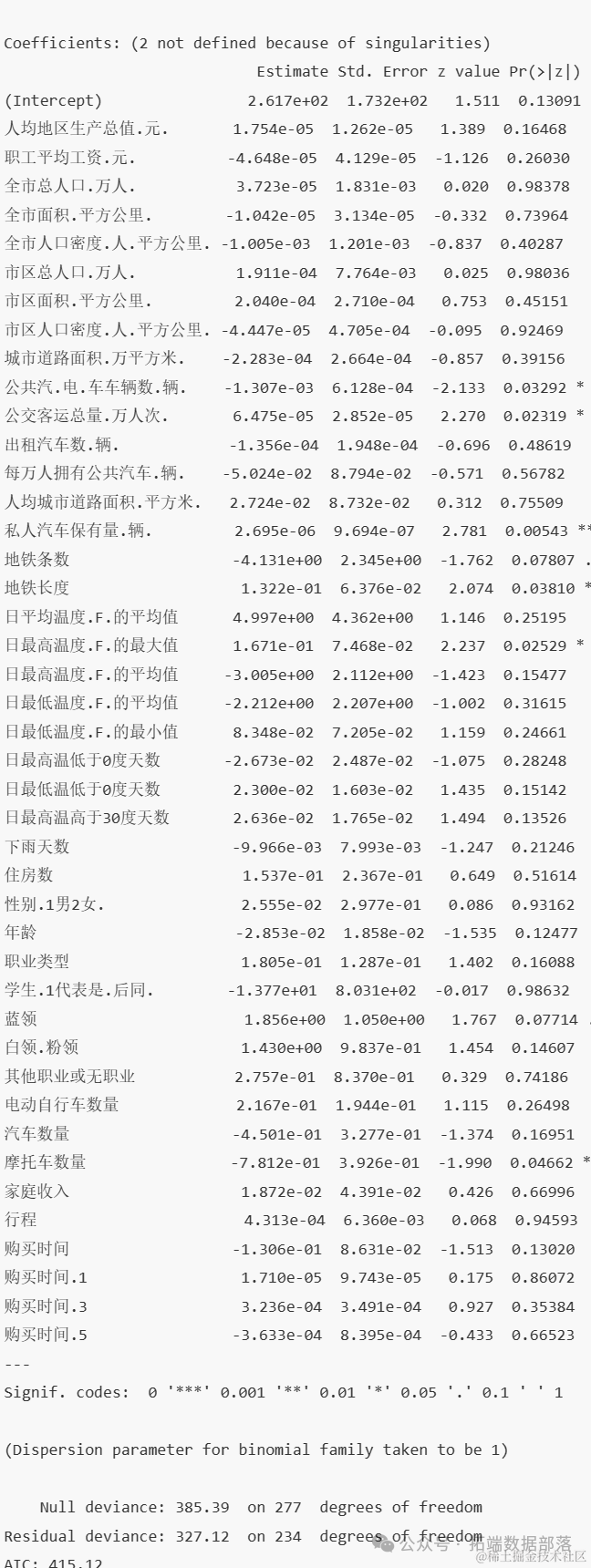
从上面的回归结果中,我们可以看到公共汽.电.车车辆数.辆.,公交客运总量.万人次. ,私人汽车保有量.辆.,地铁长度 ,日最高温度.F.的最大值 ,摩托车数量 对是否有汽车购买意愿有重要的影响。从中同时可以看到公交客运总量.万人次. ,私人汽车保有量.辆.,地铁长度 , 日最高温度.F.的最大值和是否有汽车购买意愿存在正相关的关系。
确定模型的最优预测概率截止值
默认的截止预测概率分数为0.5或训练数据中1和0的比值。 但有时,调整概率截止值可以提高开发和验证样本的准确性。InformationValue :: optimalCutoff功能提供了找到最佳截止值以提高1,0,1和0的预测的方法,并减少错误分类错误。 可以计算最小化上述模型的错误分类错误的最优分数。
misClassError(testData$是否有汽车购买意愿.1买0不买., predicted, threshold = optCutOff)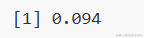
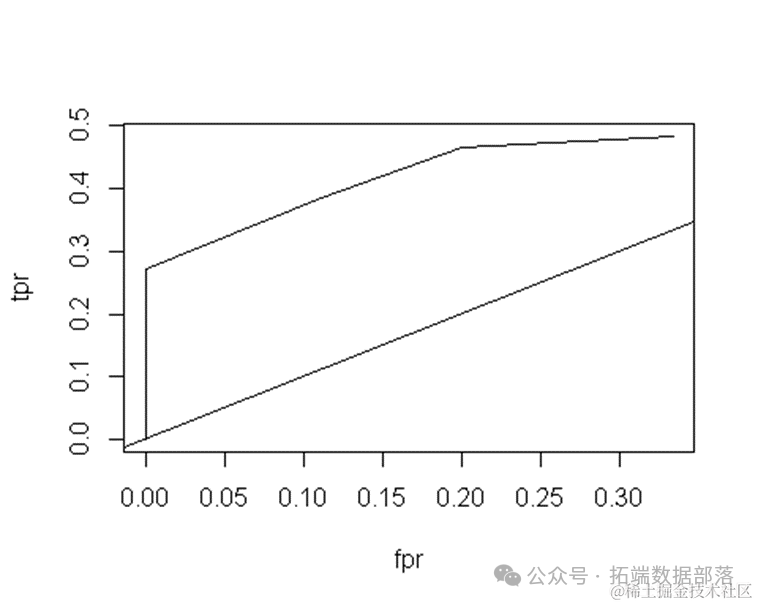
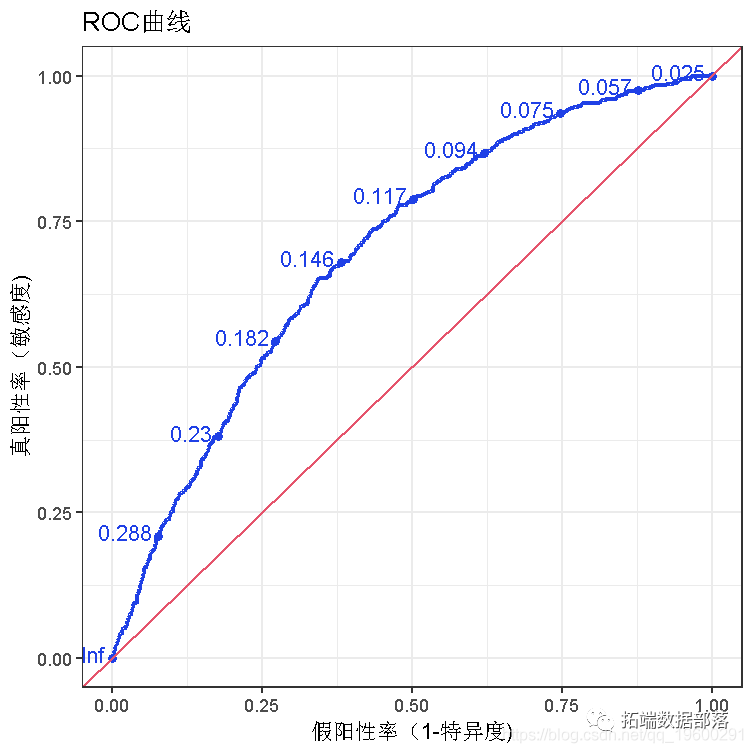
ROC
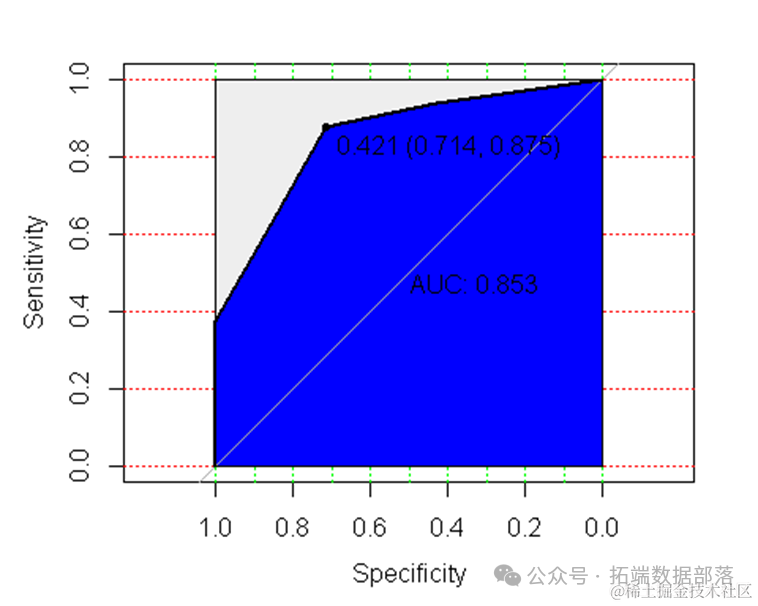
ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
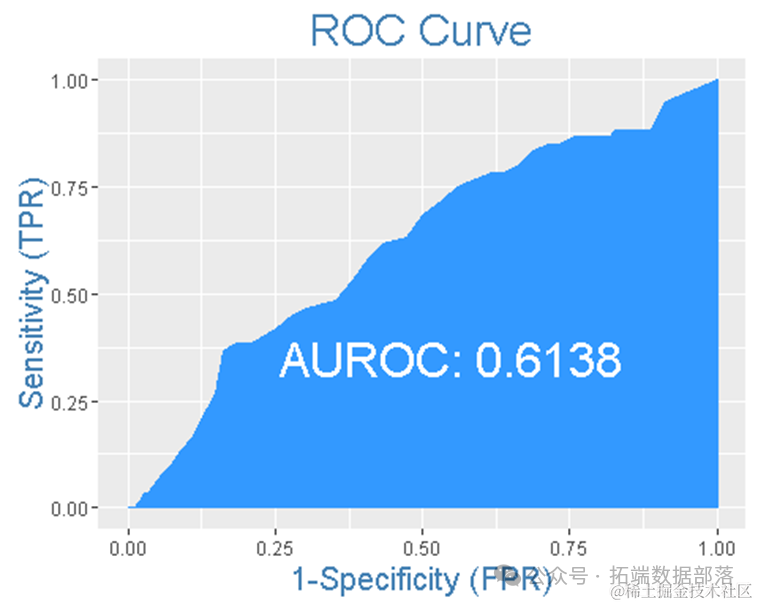
上述型号的ROC曲线面积为61%,相当不错。
一致性
简单来说,在1-0 的所有组合中,一致性是预测对的百分比 ,一致性越高,模型的质量越好。

上述的61%的一致性确实是一个很好的模型。
特异性和敏感性
敏感度(或真正正率)是模型正确预测的1(实际)的百分比,而特异性是0(实际)正确预测的百分比。特异性也可以计算为1-假阳性率。
specificity(testData$是否有汽车购买意愿.1买0不买., predicted, threshold = optCutOff)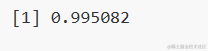
以上数字是在不用于训练模型的验证样本上计算的。所以测试数据的真实检测率为99%是好的。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言逻辑回归logistic模型ROC曲线可视化分析2例:麻醉剂用量影响、汽车购买行为》。


点击标题查阅往期内容
matlab用马尔可夫链蒙特卡罗 (MCMC) 的Logistic逻辑回归模型分析汽车实验数据
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集
PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线

![]()


