
- 140个高质量信息管理专业毕设项目分享【源码+论文】(六)_信息学院毕设项目
- 2保姆级的教你一步一步安装部署Zabbix_zabbix安装部了
- 3对比学习在NLP和多模态领域的应用
- 4GPT系列论文解读:GPT-2_gpt2模型架构
- 5在 NVIDIA DGX Cloud 上使用 H100 GPU 轻松训练模型
- 6计算机等级考试不同级别的意义?
- 7深度卷积网络,多孔卷积 和全连接条件随机场 的图像语义分割_fast approximate energy minimization with label co
- 8【Pytorch】训练中跳过问题样本,解决显存爆炸\波动问题
- 9SSTI 服务器端模板注入(Server-Side Template Injection)
- 10使用预训练语言模型预测阶段:GPU、CPU性能差别【Pegasus】_autotokenizer.from_pretrained gpu
利用RLHF优化大模型:提升性能与应用能力_rlhf大模型
赞
踩
在数据科学不断发展的过程中,大模型在自然语言处理、图像识别、金融预测等各个领域的应用越来越广泛。然而,大模型的训练和优化也面临着越来越多的挑战,例如数据量过大、计算资源不足、超参数调整困难等。传统的机器学习算法往往难以处理这些问题,因此需要更高效和智能的算法来应对。Reinforcement Learning from Human Feedback (RLHF) 作为一种强化学习算法,可以有效地利用人类给出的反馈信息来训练大模型,提高其性能。本文将介绍如何使用RLHF来优化大模型,为其应用提供更强大的支持。
下面是文章的结构
预训练一个语言模型 (LM)
预训练的目标是让语言模型具备对语言的统计信息,使其能够根据上下文预测词汇的出现概率。语言模型可以看作是一个"补全机器",给定一个提示文本,它可以生成一个回应文本来完成提示。通过预训练,我们得到了一个大型的语言模型(LLM),也称为预训练模型。
一旦您拥有了预训练的语言模型,您还可以进行监督微调(STF)这一额外的可选步骤。在监督微调中,我们使用人工标注的(输入,输出)文本对对预训练的模型进行微调,使其更适应特定任务。STF被认为是RLHF的高质量初始化,为后续的RLHF过程奠定了良好的基础。
在这一步的最后,我们得到了经过训练的语言模型,即我们的主模型。这个主模型是我们希望用RLHF进一步训练的模型,通过RLHF的训练,它将不断根据人类反馈改进自己的生成能力。

值得一提的是,在预训练阶段,不同的研究机构可能采用不同的模型和方法。例如,OpenAI在其流行的RLHF模型 InstructGPT 中使用了较小版本的 GPT-3,Anthropic使用了参数量庞大的Transformer模型,而DeepMind则使用了自家的巨大参数模型 Gopher。此外,对预训练模型进行微调时,有的机构可能采用额外的文本或条件,比如OpenAI对“更可取”的人工生成文本进行微调,而Anthropic根据“有用、诚实和无害”的标准在上下文线索上蒸馏了原始的模型。这些微调步骤可能涉及昂贵的增强数据,但并不是RLHF的必须步骤。因为RLHF仍然是一个尚待探索的领域,对于哪种模型适合作为RLHF的起点并没有明确的答案,因此不同机构可能采用不同的方法进行实验。
对话的监督微调(SFT)
监督微调(SFT)的目标是优化预训练模型,使其能够生成用户所期望的回应。在预训练阶段,模型通过学习大量的语言数据,优化了对补全文本的预测能力。这意味着当我们给预训练模型一个问题时,比如"如何学习编程",它可以生成多种合理的完成方式,例如:
- 添加问题上下文:针对初学者
- 添加后续问题:有哪些编程语言需要学习?学习编程需要多长时间?
- 直接给出答案:学习编程需要掌握编程语法和算法。
在这些选项中,如果我们真正希望得到一个回答,那么第三个选项是最合适的。而监督微调的目标就是通过优化预训练模型,使其更倾向于生成用户所期望的答案。
在实施监督微调时,我们向语言模型展示不同用例(例如问答、摘要、翻译等)的示例,来告诉模型如何适当地对这些提示进行回应。这些示例的格式是(提示,回应),通常称为演示数据。OpenAI将这种监督微调方法称为"行为克隆":您向模型展示了它应该如何行为,而模型则会克隆这种行为。
举个例子,假设我们有一个预训练的语言模型,我们希望在问答场景中优化它的表现。我们可以为模型提供各种问答示例,比如:
- 提示:“请告诉我如何制作巧克力蛋糕。”
- 回应:“首先准备好巧克力、面粉、鸡蛋和牛奶。然后按照食谱进行操作,最后烘烤约30分钟即可。”
- 提示:“什么是太阳系中最大的行星?”
- 回应:“太阳系中最大的行星是木星。”
通过这样的示例,我们教导模型正确回答不同类型的问题。随着监督微调的进行,模型会逐渐学会根据提示生成用户期望的回答,从而更好地适应特定任务和用例。通过这一步骤,我们的主模型将逐渐变得更加智能和精准,为后续的RLHF阶段奠定了基础。下图为监督微调的简单图示。

训练奖励模型
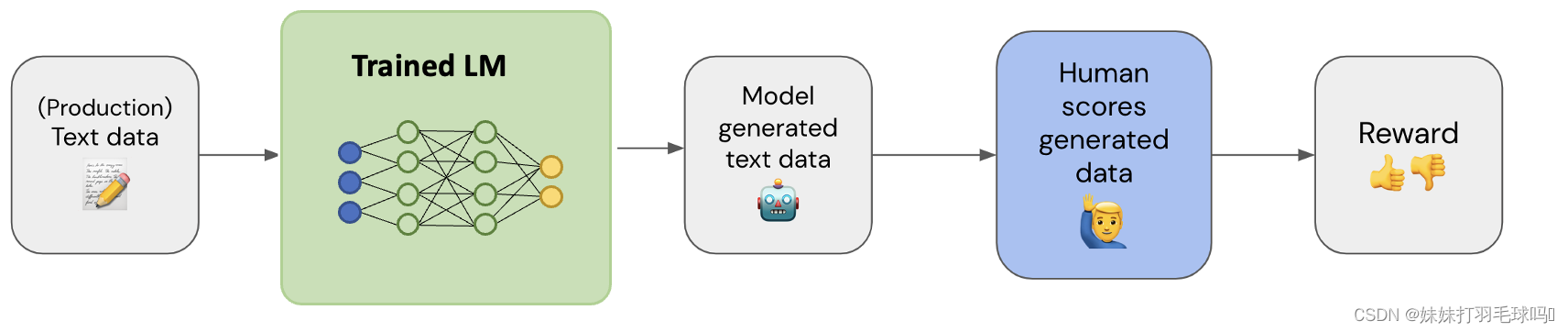
在这一步中,我们的目标是收集一个包含(输入文本,输出文本,奖励)三元组的数据集。
如上图所示:使用输入文本数据(最好是生产数据),通过您的模型生成相应的输出文本,并由人工为生成的输出文本分配一个奖励值。
奖励值一般取0~5之间,也可以用0/1来表示。
奖励模型(RM)的任务是用一对(prompt,response)和一个奖励分数来训练一个模型,在给定输入上输出分数是机器学习中一个非常常见的任务,可以将其看作是分类或回归任务。该模型为每一个文本输入到文本输出的结果打分,来评估模型的性能。
为了计算出最优的奖励模型,我们使用不同参数的大模型(不同微调或者不微调的)输出不同的response,奖励分数可能也不一样。优化奖励模型的目的就是为了尽可能让同一个prompt输入到不同的大模型下输出的response,最后得到的奖励差不多。
假设: r θ r_\theta rθ 为正在训练的奖励模型,模型参数为 θ \theta θ
x
x
x:prompt
y
w
y_w
yw:winning response 表示这些大模型输出中得到奖励最高的response
y
l
y_l
yl:losing response 表示这些大模型输出得到奖励最低的response
对于每个训练样本 ( x , y w , y l ) (x, y_w, y_l) (x,yw,yl),有:
s
w
=
r
θ
(
x
,
y
w
)
s_w=r_\theta(x,y_w)
sw=rθ(x,yw):奖励模型对于winning response的分数
s
l
=
r
θ
(
x
,
y
l
)
s_l=r_\theta(x,y_l)
sl=rθ(x,yl):奖励模型对于losing response的分数
损失值: − l o g ( σ ( s w − s l ) ) −log(\sigma(s_w−s_l)) −log(σ(sw−sl))
为了更好地理解这个损失函数的作用,我们来进行可视化。设 d = s w − s l d=s_w−s_l d=sw−sl。以下是 f ( d ) = − l o g ( σ ( d ) ) f(d)=−log(\sigma(d)) f(d)=−log(σ(d))的图表。对于负的d,损失值较大,这鼓励奖励模型不能使winning response的分数降低于losing response的分数。
关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。
对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
ELo机制玩王者荣耀,英雄联盟的应该再熟悉不过了
通过得到奖励模型,我们为后续的RLHF过程提供了一种可靠的衡量标准。
用强化学习微调
强化学习微调是RLHF的关键步骤之一。它有助于训练语言模型,使其能够根据用户提示生成更合适的回应。然而,由于输出的奖励本身并不是可微的,我们需要使用强化学习(RL)来构建一个损失函数,以便能够对LM进行反向传播。
大佬们通过Kullback-Leibler(KL)散度和近端策略优化(PPO)来实现强化学习技术。
为了更好的说明为什么可以将强化学习用到LM中,我们首先将微调任务表述为 RL 问题。
该策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
如下图所示,对比通用的强化学习来看,你会更理解了


在训练开始,我们将创建一个与LM完全相同且其可训练权重被冻结的LM。这个模型将有助于防止可训练的LM完全改变其权重,并开始输出一些无意义的文本来满足奖励模型。
我们通过计算冻结的LM和没有冻结的LM值之间的文本输出分布序列(概率分布)的KL散度作为损失函数。
有了奖励和KL损失,我们现在可以应用强化学习来使奖励损失可微分。
为了使损失可微分,我们采用了近端策略优化(Proximal Policy Optimization,PPO)算法!下面是整个微调的详细步骤:
- 第一步:利用奖励模型
首先,用户输入或提示被发送到RL策略,这实际上是LM的调整版本。RL策略生成一个回应,该回应与初始LM的输出一起由奖励模型评估。然后,奖励模型生成一个标量奖励值,对应于回应的质量。
- 第二步:引入反馈循环
这个过程在反馈循环中迭代,奖励模型为尽可能多的样本分配奖励,以资源允许的方式。随着时间的推移,获得更高奖励的回应将引导RL策略,帮助其生成更符合人类期望的回应。
- 第三步:使用KL散度衡量差异
Kullback-Leibler(KL)散度是衡量两个概率分布之间差异的统计方法,在此起着至关重要的作用。在RLHF中,使用KL散度比较RL策略当前回应的概率分布与表示理想或最符合人类期望回应的参考分布之间的差异。
- 第四步:使用近端策略优化进行微调
微调的一个重要部分是近端策略优化(PPO)。PPO是一种著名的强化学习算法,以其在高维状态和动作空间的复杂环境中优化策略的有效性而闻名。PPO在RLHF微调过程中尤其有用,因为它在训练过程中有效地平衡了探索和利用。对于RLHF代理来说,这种平衡对于从人类反馈和试错探索中学习至关重要。因此,整合PPO可以实现更快和更强大的学习。
- 第五步:避免不合适的回应
微调过程有助于阻止语言模型产生不合适或荒谬的输出。由于低奖励的回应不太可能被重复,语言模型被驱使产生更符合人类期望的输出。
其中PPO算法计算损失公式和图解释(用于对LM进行小幅度更新)如下所示:
- 将“Initial probs”设为“New probs”来初始化。
- 计算新输出文本概率与初始输出文本概率之间的比率。
- 根据公式 l o s s = r θ ( y ∣ x ) − λ K L D K L ( π p p o ( y ∣ x ) ∣ ∣ π b a s e ( y ∣ x ) ) loss =r_\theta(y|x)- \lambda_{KL}D_{KL}(\pi_{ppo}(y|x)||\pi_{base}(y|x)) loss=rθ(y∣x)−λKLDKL(πppo(y∣x)∣∣πbase(y∣x))计算损失
- 通过反向传播来更新LM的权重。
- 使用新更新的LM计算“New probs”(即新的输出文本概率)。
- 重复步骤2至步骤5 N 次(通常,N=4)。
这里的probs就是LM模型的文本输出概率 π ( y ∣ x ) \pi(y|x) π(y∣x)

RLHF的优势和局限性
从人类反馈中进行强化学习(RLHF)为完善AI系统提供了强大的方法论。然而,就像任何其他方法一样,它既有明显的优点,也存在潜在的挑战。
RLHF的优点:
- 适应性:RLHF是一种动态学习策略,可以根据收到的反馈进行适应。这种适应性使其非常适合各种任务,并使其能够根据实时交互和反馈调整其行为。
- 减少偏见:理论上,RLHF有助于减少模型的偏见。通过精心选择和多样化的人类反馈,这些模型可以从更广泛、更代表性的角度学习,减少在初始训练数据中固有的过度泛化或偏见。
- 持续改进:RLHF模型具有持续改进的能力。随着这些模型与用户的互动并获得更多反馈,它们可以学习和适应,从而提高性能和用户体验。
- 安全性:RLHF可以在增强AI系统的安全性方面发挥关键作用。通过人类反馈,这些系统可以避免潜在的有害或不适当的行为,使其对交互和使用更安全。
RLHF的挑战和局限性:
1. 可扩展性:可扩展性仍然是RLHF面临的一个重大挑战。由于这些模型依赖于人类反馈进行学习,将其扩展以适应更大或更复杂的任务可能会耗费大量资源和时间。
2. 依赖于人的因素:RLHF模型严重依赖于人类反馈的质量。无效或不足的反馈可能导致性能不佳,甚至在模型中无意间培养出有害行为。
3. 人类偏见:偏见引入的潜在问题是RLHF的一个关键关注点。由人类评估者提供的反馈可能带有固有偏见,导致学习的偏差。这些偏见可以采取多种形式,包括选择性偏见、确认偏见、评估者间变异性和反馈有限性。
然而,值得注意的是,存在有效的策略来减轻这些偏见。选择多样化的评估者、共识评估、评估者的校准、对反馈过程和代理性能的定期评估以及平衡反馈与其他来源的方法都有助于减少RLHF中偏见的影响。这些策略强调了RLHF的周密和系统的方法,强调了在过程中持续评估和调整的重要性。
在RLHF的不断发展过程在RLHF的不断发展过程中,还存在一些其他挑战和局限性需要解决:
- 解释性和透明性:随着模型规模的增大和复杂性的提高,大型语言模型往往变得更加晦涩难解。这使得解释模型的决策过程变得困难,特别是在使用RLHF进行微调后。对于一些应用场景,特别是在需要解释性和透明性的领域,这可能会成为一个限制因素。
- 奖励设计:设计有效的奖励函数是RLHF中的一个关键问题。奖励函数需要能够准确地反映出模型的性能,并且要具有足够的区分度,以便对不同回应进行排序。但是,设计奖励函数并不总是直观和简单的,特别是在复杂的任务和多样化的回应情况下。
- 对抗性样本:强化学习往往对对抗性样本攻击具有一定的脆弱性。在RLHF中,如果模型被针对性地攻击,可能会导致生成不符合期望的回应。这需要在RLHF训练过程中对模型进行鲁棒性和安全性的考虑,以防止对抗性攻击。
- 训练效率:由于大型模型的训练需要大量的计算资源和时间,RLHF的训练成本可能会很高。这对于一些资源受限的环境和应用场景来说可能是一个挑战。
尽管存在这些挑战,但RLHF作为一种强大的学习方法仍然在不断演进和改进。研究人员和开发者正在努力解决这些问题,以进一步推动RLHF的应用和发展。同时,社会对于人工智能系统的可信度和可控性也在不断增加,对于解释性、透明性和可解释性的要求也将在RLHF的发展过程中得到更多关注。
在未来,我们可以期待看到更多创新和改进,以使RLHF成为更加普遍且可信赖的方法,为各个领域的应用提供更强大的支持和推动人工智能技术的持续进步。
结语
随着数据科学和人工智能领域的不断发展,大型语言模型和RLHF作为强大的工具正逐渐成为各种领域的重要组成部分。通过预训练和微调,大型语言模型能够具备丰富的语言表达能力,而RLHF则能够根据人类反馈持续改进模型的性能,使其更加智能和适应不同任务。
然而,我们也必须认识到RLHF仍然面临着一些挑战,如可扩展性、人类偏见、解释性等问题。解决这些问题需要跨学科的研究和合作,以确保RLHF的应用能够安全、可靠、高效地应对现实世界的挑战。
在未来,我们有理由相信,随着技术的不断进步和对人工智能的深入理解,RLHF将继续发展壮大,为人类社会带来更多的福祉和创新。同时,我们也需要密切关注其发展过程中可能带来的道德和社会问题,并持续推动科技的发展与社会价值的平衡。只有这样,RLHF才能真正成为人工智能技术发展的助推器,为人类创造更美好的未来。

