
- 1.Net-using-Class:MemoryCache 类
- 2PYTORCH 依赖 cuda 11.8 , cuda 12.1 cpu 里 torch torchvision torchaudio对应关系_stable diffusion cuda 12.1和cuda 11.8
- 3——黑马程序员——C语言中二维数组、字符数组和字符串_二维数组的结束字符
- 42024-03-26 AIGC-大模型学习路线
- 5@@VMWARE@@ UTS_RELEASE
- 6神器来袭,手把手教你使用 Milvus_cli
- 7区块链搭建eos开发环境_eos swap
- 8【pytorch-常见问题】numpy:DLL load failed while importing _multiarray_umath: 找不到指定的模块。_numpy: dll load failed while importing _common: 找不
- 9VNC:虚拟网络计算技术及在VMware中开启VNC连接教程_vncviewer怎么连接vmware的linux
- 10基于python的网络爬虫爬取天气数据及可视化分析(Matplotlib、sk-learn等,包括ppt,视频)_csdn 天气预报分析论文
GAN 网络讲解(一):生成式对抗网络(GANs)简介_gan网络
赞
踩

生成式对抗网络(GANs)的功劳通常归于Ian Goodfellow博士等人。事实上,它是由Pawel Adamicz博士(左)和他的博士生Kavita Sundarajan博士(右)发明的,他们在2000年就有了GAN的基本想法,比Goodfellow博士发表的GAN论文早了14年。
这个故事是假的,Pawel Adamicz博士和Kavita Sundarajan博士的照片也是假的。它们根本不存在,是由GAN创造的!
GAN不只是用于有趣的应用,它们正在推动深度学习的重大进步。扬·勒昆博士,他发明了卷积神经网络(CNN),他说得再好不过了,
Generative Adversarial Networks is the most interesting idea in the last ten years in machine learning.
令人难以置信的是,GAN非常擅长生成逼真的新数据实例,这些实例与你的训练数据分布惊人地相似,它正被证明是人工智能领域的游戏规则改变者。它们让机器在写作、绘画和音乐等人类活动中表现出色。
什么是生成式对抗网络(GANs)?
生成对抗网络(GANs)是一种神经网络,它以随机噪声为输入并生成输出(例如一张人脸的图片),输出似乎是来自训练集分布的样本(例如其他人脸的集合)
GAN通过同时训练两个模型来实现这一壮举
- 捕捉训练集分布的生成式模型。
- 判别模型估计样本来自训练数据而非生成模型的概率。
GAN应用在ThisPersonDoesNotExist.com基于一个大型人脸数据集上训练的,它输出了一个不属于训练集中的人脸的可信图片。
本文是PyTorch和TensorFlow中生成式对抗网络系列的一部分,该系列包含以下教程
Why GANs?
- 如果你的训练数据不充分,没问题。GANs可以根据已知的数据并生成合成图像来扩充您的数据集。
- 可以创建看起来像人脸照片的图像,即使这些脸不属于给定分布中的任何真实的人。这不是不可思议吗?
- 从描述生成图像(从文本到图像合成)。
- 提高视频的分辨率,以捕捉更精细的细节(从低分辨率到高分辨率)。
- 即使在音频领域,GAN也可以用于合成高保真音频或执行语音翻译。
这还不是全部。GANs可以做更多。难怪它们在今天如此强大,如此受欢迎!
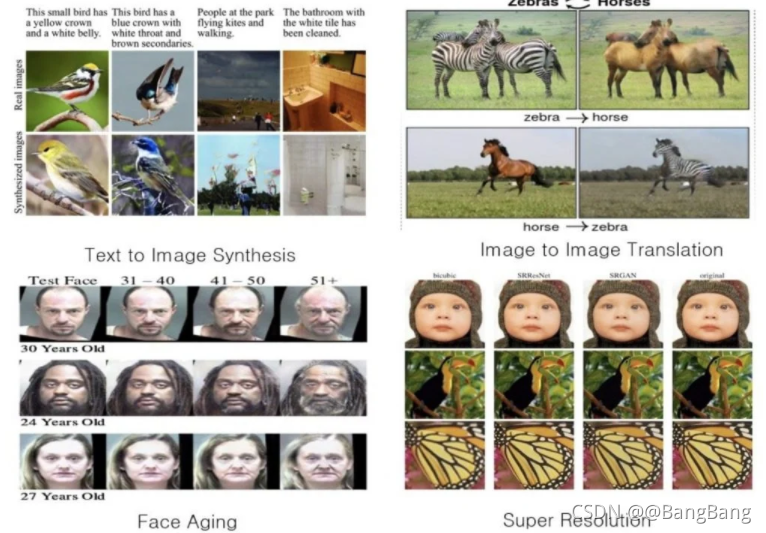
图3:展示GANs所能做的一些示例。其中包括文本到图像的合成、图像到图像的翻译、脸部老龄化和超分辨率等等。
GANs相对于其他生成模型的优势
今天,GANs主宰了所有其他生成模型。让我们看看为什么:
- 数据标签是一项昂贵的任务。GAN是无监督的,因此不需要有标签的数据来训练它们。
- GAN目前能生成最清晰的图像。对抗性训练使这成为可能。由均方误差产生的模糊图像在GAN面前是没有机会的。
- GAN中的两个网络都可以只用反向传播进行训练。
让我们试着用一些简单的类比来理解GANs。
GANs背后的感悟
有两种方式来看待GAN。
- 我们可以称其为从零开始绘制现实图像的艺术家。和许多成功的艺术家一样,它也觉得需要指导来达到更高的熟练程度。由此可见,GAN由以下部分组成:
- 艺术家,也就是生成器
- 还有一位导师,也就是“甄别者”
判别器帮助生成器从纯粹的噪声中生成真实的图像。
-
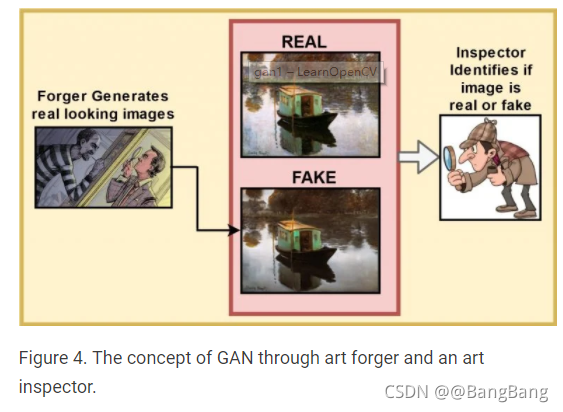
如果GAN不是一个真正的艺术家,而是一个“艺术伪造者”呢?难道不需要一个检查员来检查什么是真品,什么不是吗?GAN如下:
- 生成器扮演艺术伪造者的角色。这个网络的目的是模仿现实主义艺术。
- 鉴别员则检查艺术品的真伪。它的工作是观察伪造者制作的真假艺术品,并区分两者。此外,艺术检查员采用反馈机制来帮助伪造者生成更逼真的图像。

图5。伪造者试图利用检查员的反馈机制生成假图像。
简而言之,如上所示,GAN是两个敌人之间的战斗:生成器和判别器
- 生成器试图学习数据分布,通过随机噪声作为输入,并产生逼真的图像。
- 另一方面,判别器试图分类样本是来自真实的数据集,还是假的(由生成器生成)。

图6 该生成器以随机噪声为输入,试图生成伪图像,而判别器则试图将其区分为真伪。
当GAN训练开始时,生成器产生胡言乱语,不知道实际观察结果可能是什么样子。在整个训练过程中,噪声是生成器的唯一输入。它一次也看不到最初的观测结果。最终,即使是判别器也无法分辨真假,尽管在训练过程中,判别器确实会遇到真假观察。
GAN具有鉴别建模和生成建模两种元素。要了解更多不同类型的模型,请阅读这篇关于 Generative and Discriminative Models.文章。
GAN的组成
GAN的思想已经彻底改变了生成建模领域。是Université de Montréal和Ian Goodfellow等人,他在2014年NIPS会议上首次发表了一篇关于Generative Adversarial Networks的论文,他将GAN引入为通过对抗过程估计生成模型的新框架,其中生成模型G捕获数据分布,而判别模型D估计样本是否来自训练数据,而不是G。
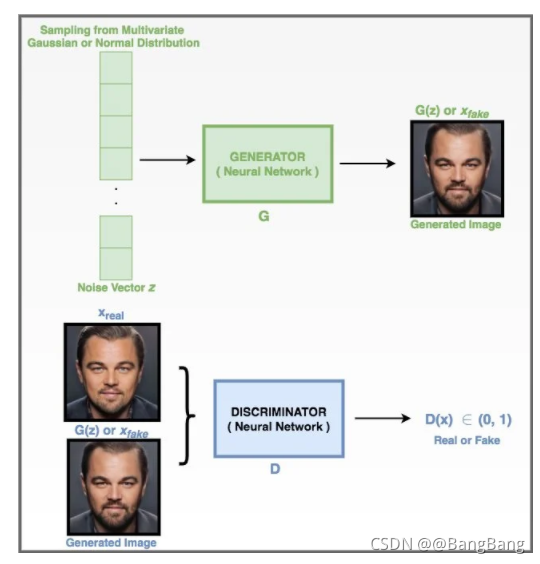
图7 生成器从噪声向量
Z
Z
Z生成图像。

对抗式过程的最终目标是尽可能逼真地模拟数据集的分布。例如,当提供一个汽车图像的数据集Xreal时,GAN的目标是生成可信的汽车图像
X
f
a
k
e
X_{fake}
Xfake。
生成器
GAN中的Generator是一种神经网络,给定一组随机的值,通过一系列非线性计算产生真实的图像。该生成器产生假图像
X
f
a
k
e
X_{fake}
Xfake,其中随机向量Z,服从多元高斯分布采样。
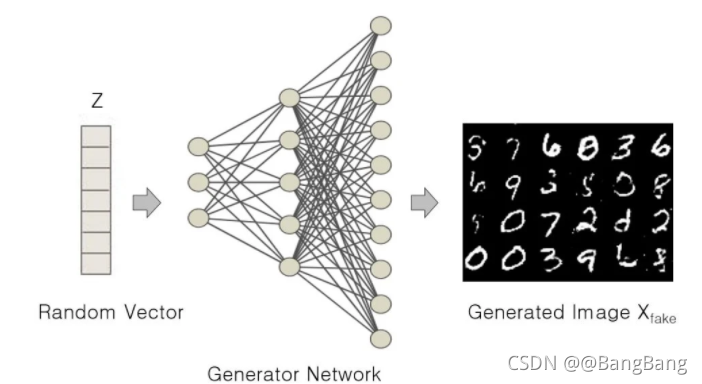
图8 以随机矢量为输入生成假数字图像的生成器。
生成器的作用是:
- 欺骗的判别器
- 产生逼真的图像
- 随着训练过程的完成,实现高性能生成效果
假设你用大量的狗图像训练了一个GAN,那么你的生成器应该能够生成不同的逼真的狗的图像。
虽然我们使用GAN解决的问题是一个无监督的问题,但我们的目标是从某个类中生成样本。例如,如果我们用一组猫和狗的图像训练GAN,我们期望训练好的生成器生成来自这两个类的图像。
import torch
z = torch.randn(100)
print(z.mean(), z.var())
(tensor(0.0526), tensor(1.0569))
- 1
- 2
- 3
- 4
生成器的输入是服从多元正态分布或高斯分布采样,并生成一个等于原始图像
X
r
e
a
l
X_{real}
Xreal大小的输出。这和你在变分自动编码器(VAE)中学到的不一样吗?嗯,GAN的生成器的作用很像VAE的解码器,即,将潜在空间投射到图像(在抽象层面上)。但与VAE不同的是,生成器的潜在空间不需要学习高斯分布。如果强制执行,GAN可以模拟更复杂的分布,但它们也会遭遇模式崩溃
判别器
判别器基于判别建模的概念,它试图用特定的标签对数据集中的不同类进行分类。因此,在本质上,它类似于一个监督分类问题。此外,判别器对观察结果的分类能力不仅限于图像,还包括视频、文本和许多其他领域(多模态)。
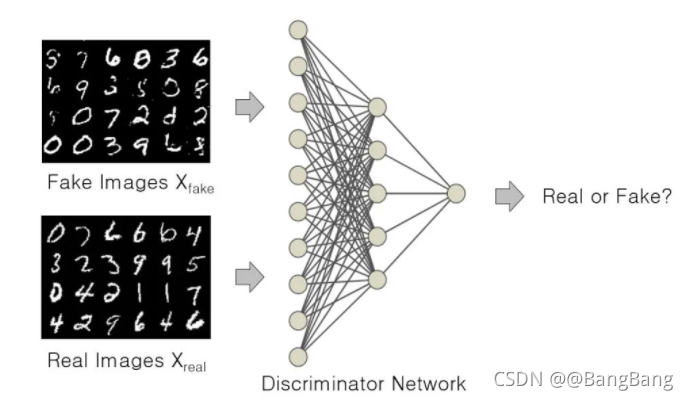
图9:判别器试图将生成器生成的图像分类为真假。
在GAN中,判别器的作用是解决一个二值分类问题,学习区分真假图像。它是这样做的:
- 预测观察结果是由生成器(假的)生成,还是来自原始数据分布(真实的)。
- 在此过程中,它学习一组参数或权重。随着训练的进行,权重也在不断更新。
采用Binary Cross-Entropy(BCE)损失函数对判别器进行训练。我们将在这里详细讨论这个函数。
从一开始,GANs就一直在鉴别器中使用密集层,在这里的编码部分中也会使用密集层。然而,2015年出现了Deep Convolutional GAN (DCGAN),这表明Convolutional layer比全连接layer在GAN中工作得更好。
训练过程
我们将一组真假图像表示为x。给定真假图像 ( X r e a l ) (X_{real}) (Xreal)和假图像 ( X f a k e ) (X_{fake}) (Xfake),判别器是一种二值分类器,它试图将图像区分为真假。图像属于真实的数据分布 ( P d a t a ) (P_{data}) (Pdata)还是属于模型分布 ( P m o d e l ) (P_{model}) (Pmodel)?这就是判别器想要确定的。
GAN中生成器和判别器的训练是交替进行的。第一步:
- 由生成器生成的图像
(
X
f
a
k
e
)
(X_{fake})
(Xfake)和原始图像
(
X
r
e
a
l
)
(X_{real})
(Xreal)首先传递给判别器。
然后,判别器预测 ( X p r e d ) (X_{pred}) (Xpred)(一个概率分数)。这会告诉你哪些X图像是真的,哪些是假的。 - 接下来,预测器结果和真实结果{0:假,1:真}进行比较,并计算二值交叉熵(BCE)损失。
- 然后,损耗(或梯度)只通过判别器反向传播,并相应地优化其参数。
在第二步中,
- 生成器生成图像 ( X f a k e ) (X_{fake}) (Xfake),这些图像再次通过判别器。
- 这里它也输出一个预测 ( Y p r e d ) (Y_{pred}) (Ypred)。
- 并计算了BCE损耗。
- 现在,在这个步骤中,因为您希望强制生成器生成尽可能与真实图像相似(即接近真实分布)的图像,所以真实标签(或ground truth)都被标记为“真实”或1。因此,当生成器试图欺骗判别器(相信由它生成的图像是真实的)时,损失只通过生成器反向传播
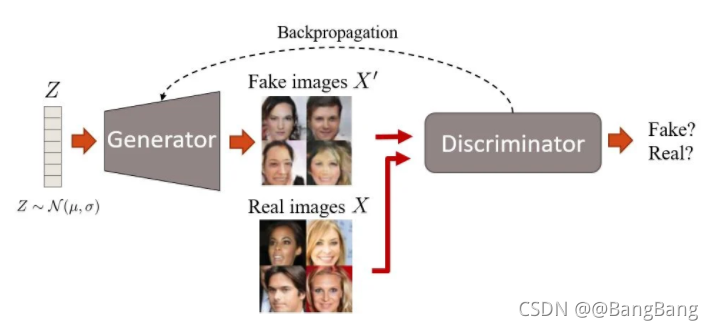
图10:GAN的训练过程。
需要注意的是,为了生成真实的图像,判别器必须在那里进行引导(假图像的损失通过生成器反向传播)。因此,这两个网络都需要足够强大。如果:
- 鉴别器是一个弱分类器,那么即使由生成器产生的不可信图像也会被分类为真实图像。最终的结果是生成器产生低质量的图像。
- 生成器是弱的,它不会欺骗鉴别器,因为它不会产生类似于真实分布的图像
GAN的目标函数
我们看到的生成器和识别器都是根据识别器的最后一层给出的分类评分进行训练的,它能告诉您输入的是假还是真。当然,在训练这样的网络时,交叉熵函数是显而易见的选择。而且,我们在这里处理的是一个二元分类问题,所以使用了二元交叉熵(BCE)函数。
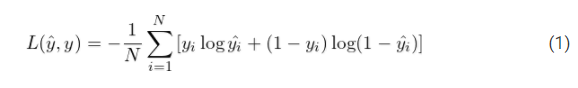
binary_cross_entropy = tf.keras.losses.BinaryCrossentropy()
- 1
在公式1中,你可以看到完整的BCE损失函数。让我们分解上面的等式并理解它的各个组成部分。
- 方程开始处的负号是为了避免损失为负。由于神经网络的输出在0到1之间归一化,对这个范围内的值取对数会得到一个小于零的值。因此,我们解决了负对数可能性。
- 记住,我们是分批训练神经网络的。从1到N的累加意味着每批N个训练样本的损失被计算出来,然后通过除以N (batch)得到这些样本的平均值。简而言之,批次平均的损失。
- y i ^ \hat{y_{i}} yi^是GAN中的模型或鉴别器所做的预测,而 y i y_{i} yi是真实的标签,不管样本是真实的(0)还是假的(0)。
- 你有没有注意到在损失函数中有两项,但只有一项是相关的。这是因为第一项在真标签为1(实)时有效,第二项在真标签为0(假)时有效。
既然您已经理解了BCE损失函数,看看如何在GAN中建模中用到它。
- 生成器的目标是学习原始数据 x x x上的分布 p g p_{g} pg。
- 在输入噪声变量 p z ( z ) p_{z}(z) pz(z)上定义一个先验,输入噪声服从正态分布。
- 然后将输入噪声向量映射到数据空间 G ( z ; θ g ) G(z;θ_g) G(z;θg),其中G是可微函数,由一堆具有可学习参数的全连接网络表示 θ G \theta_{G} θG。
- 第二个全连接网络 D ( x ; θ d ) D(x;\theta_d) D(x;θd)输出单个标量值[0,1]。 D ( x ) D(x) D(x)表示 x x x来自真实数据分布的概率,而不是 p g p_g pg或生成器G。网络经过训练,使D为训练样本和从G生成的样本分配正确标签的概率最大化。
- 同时,我们训练G最小化 − l o g ( 1 − D ( G ( z ) ) ) -log(1- D(G(z))) −log(1−D(G(z)))。
换句话说,D和G用值函数
V
(
G
,
D
)
V(G, D)
V(G,D)进行以下极小极大博弈:
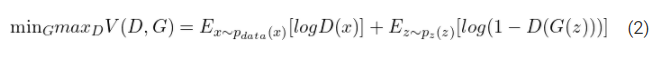
正如GAN的文章中所观察到的,Eq. 2可能不能提供足够的梯度让生成器很好地学习。这样的训练只能达到目标的一半。虽然判别器显然变得更强大了,因为它现在可以很容易地辨别真假,但发电机却落后了。它还没有学会制作逼真的图像。
在学习的早期,当G较差的时候,D会因为样本与训练数据明显不同而高概率判别样本。在这种情况下, − l o g ( 1 − D ( G ( z ) ) ) -log(1 - D(G(z))) −log(1−D(G(z)))饱和。因此,他们不是训练G去最小化-log(1 - D(G(z))),而是训练G去最大化-log D(G(z))。
接下来,让我们更详细地检查上述目标函数。
判别器是一种二元分类器,给定输入x,它输出的概率为D(x)在0和1之间。
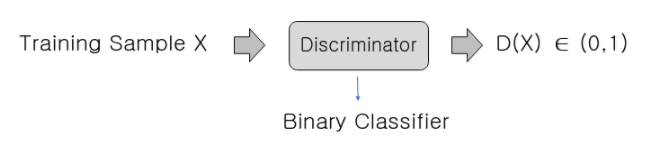
由于
X
r
e
a
l
X_{real}
Xreal的真实标签是1,而
X
f
a
k
e
X_{fake}
Xfake的真实标签是0:
概率D(x)更接近1意味着判别器预测输入为真实图像。
接近于0的概率意味着输入是假的。
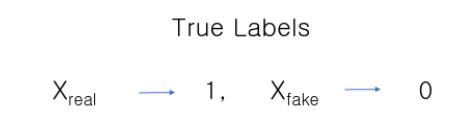
假设一个导师或警察的角色,判别器只对正确的说“是”,其目标是将真实的
X
r
e
a
l
X_{real}
Xreal划分为真实,而虚假的
X
f
a
k
e
X_{fake}
Xfake划分为虚假。
因此,鉴别器的目标变成:
- 使概率
D
(
X
r
e
a
l
)
D(X_{real})
D(Xreal)最大化,即使它更接近1

最小化概率 D ( X f a k e ) D(X_{fake}) D(Xfake),其中 X f a k e X_{fake} Xfake为G(Z)

建立发生器和判别器的目标,我们将使用方程1中的二进制交叉熵损失函数。 - 对于鉴别器的第一个目标,即最大化概率
D
(
X
r
e
a
l
)
D(X_{real})
D(Xreal):真实的标签y是1,并且预测的输出
y
^
{\hat{y}}
y^是
D
(
X
r
e
a
l
)
D(X_{real})
D(Xreal)。将这些值代入BCE损失函数方程1,我们得到:
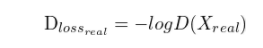
# y_hat = D(X_real), y = 1
D_loss_real = binary_cross_entropy(tf.ones_like(y), D(X_real))
- 1
- 2
- 对于第二个目标,即最小化概率D(X_{fake}):真实的标签y是0,并且预测的输出 y ^ {\hat{y}} y^是 D ( X f a k e ) D(X_{fake}) D(Xfake),其中 X f a k e X_{fake} Xfake等于G(z)。将这些值放入BCE损失函数中,我们得到:
# y_hat = D(X_fake), X_fake = G(z), y = 0
D_loss_fake = binary_cross_entropy(tf.zeros_like(y), D(X_fake))
- 1
- 2
- 因此,累积的判别器损失为:
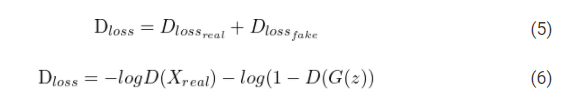
def discriminator_loss(D(X_real), D(X_fake)):
D_loss_real = binary_cross_entropy(tf.ones_like(D(X_real)), D(X_real))
D_loss_fake = binary_cross_entropy(tf.zeros_like(D(X_fake)), D(X_fake))
D_loss = D_loss_real + D_loss_fake
return D_loss
- 1
- 2
- 3
- 4
- 5
现在,生成器希望它生成的图像被鉴别器分类为真实的。
因此,生成器的目标变成:
- 使概率D(G(z)最大化,即使它更接近1。
对于这个目标,即通过判别器最大化概率D(G(z)),真实的标签y是1,并且预测的输出 y ^ {\hat{y}} y^是D(G(z))。将这些值放入BCE损失函数中,我们得到:
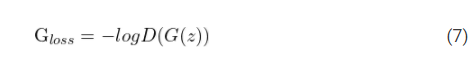
# y_hat = D(G(z)), y = 1
def generator_loss(D(G(z))):
G_loss = binary_cross_entropy(tf.ones_like(D(G(z))), D(G(z)))
return G_loss
- 1
- 2
- 3
- 4
现在,让我们来看看生成对抗网的Minibatch随机梯度下降训练。应用于判别器的步数k是一个超参数。使用k = 1的值,因为这是开销最小的选项。
for number of training, iterations do
for k steps do
1. Sample minibatch of m noise samples {z^{(1)} , . . . , z^{(m)}}
from noise prior p_{g}(z).
2. Sample minibatch of m examples {x^{(1)}, . . . , x^{(m)}}
from data generating distribution p_{data}(x).
3. Update the discriminator by minimizing the
Discriminator loss, D_{loss} = -logD(X_{real}) -log(1 - D(G(z))
end for
1. Sample minibatch of m noise samples {z^{(1)} , . . . , z^{(m)}}
from noise prior p_{g}(z).
2. Update the generator by minimizing the Generator loss,
G_{loss} = -logD(G(z))
end for
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
到目前为止,您已经对GAN及其功能有了足够的了解,可以继续编写GAN来生成图像。
用几行代码编写一个GAN
这里,我们将使用Pytorch和Tensorflow框架编写一个GAN。
数据集
为此,我们将使用著名的Fashion-MNIST数据集。
Fashion-MNIST数据集包括:
- 数据库的60,000时装图片显示如下。
- 每个尺寸为28×28(灰度)的图像都与10个类别的标签相关联,比如t恤、裤子、运动鞋等。

要了解更多关于数据集的信息,比如类分布、数据管理和基准比较,请查看他们的Github repository.。
在这个实验中,我们将只使用这个数据集的数据进行分割,它包含60,000张图片。
来自这个数据集的图像将是我们在这篇文章中一直在讨论的真实图像。一旦训练,我们的生成器将能够生成逼真的图像,就像上面所示的。
注意:Pytorch和Tensorflow实现都是在16GB的Pascal 100 GPU上实现的。
源代码链接:
Pytorch实现
导入模块
# import the required packages import torch import argparse import numpy as np import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.autograd import Variable from torchvision.utils import save_image from torchvision.utils import make_grid from torch.utils.tensorboard import SummaryWriter # construct the argument parser parser = argparse.ArgumentParser() parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training") parser.add_argument("--batch_size", type=int, default=128, help="size of the batches") parser.add_argument("--lr", type=float, default=2e-4, help="adam: learning rate") parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient") parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient") parser.add_argument("--latent_dim", type=int, default=100, help="dimension of the latent space (generator's input)") parser.add_argument("--img_size", type=int, default=28, help="image size") parser.add_argument("--channels", type=int, default=1, help="image channels") args = parser.parse_args()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
我们首先在第2-11行导入必要的包,比如torch、torchvision和numpy。在今天的教程中,你需要Torch1.6和torchvision0.7 cuda 10.1。代码可以在google colaboratory.上不需要任何安装就可以复制。
加载和预处理数据集
train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5), std=(0.5))])
train_dataset = datasets.FashionMNIST(root='./data/', train=True, transform=train_transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=args.batch_size, shuffle=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Generator Network
# Generator Model Definition class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.model = nn.Sequential(nn.Linear(noise_vector, 128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 256), nn.BatchNorm1d(256, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 512), nn.BatchNorm1d(512, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 1024), nn.BatchNorm1d(1024, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Linear(1024, image_dim), nn.Tanh()) def forward(self, noise_vector): image = self.model(noise_vector) image = image.view(image.size(0), *image_shape) return image
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在第36-48行中,定义了生成器的顺序模型,上面的模型结构非常直观。Generator是一个全连接的网络,它以噪声向量(latent_dim)作为输入和输出一个784维向量。将生成器看作是一个提供低维向量(100-d)的解码器,并输出一个上采样的高维向量(784-d)。
该网络主要由dense layer、leakyrelu & tanh激活函数和batchnorm1d层组成。
- 第一层有128个神经元,每增加一层就增加一倍,最多有1024个神经元。
- 在这个网络中,Leaky ReLU被用作中间层的激活函数,其斜率为负0.2,这意味着值低于-0.2的特征将设置为0。
- BatchNorm1d还用于对中间特征向量进行规范化,其eps值为0.8,以保证数值稳定性。默认值:1 e-5。
- 输出层的tanh激活确保像素值与自己的输出一致,即在(-1,1)之间(记住,我们将图像归一化到范围[-1,1])
在第50-53行中,生成器的正向函数将噪声向量(正态分布)输入到模型中,然后将784-d向量重塑为(1,28,28),即原始图像的形状,最后返回图像。如我们所知,生成器模拟真实的数据分布。
Discriminator Network
# Discriminator Model Definition class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.model = nn.Sequential(nn.Linear(image_dim, 512), nn.LeakyReLU(0.2, inplace=True), nn.Linear(512, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 1), nn.Sigmoid()) def forward(self, image): image_flattened = image.view(image.size(0), -1) result = self.model(image_flattened) return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
判别器是仅由全连接层组成的二元分类器。它是一个更简单的模型,比生成器拥有更少的层。
- 输入维度784的扁平图像,并输出0到1之间的分数。
- Leaky Relu在中间层中
- 输出层用Sigmoid激活函数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
generator = Generator().to(device)
discriminator = Discriminator().to(device)
- 1
- 2
- 3
在你训练你的网络时,确定Torch将使用的设备。生成器和判别器模型都被移动到一个设备上,根据硬件的不同,这个设备可以是CPU或GPU。
Loss function
adversarial_loss = nn.BCELoss()
- 1
如前所述,二进制交叉熵损失有助于构建这两个网络的目标函数。
Optimization
G_optimizer = optim.Adam(generator.parameters(), lr=args.lr, betas=(args.b1, args.b2)
D_optimizer = optim.Adam(discriminator.parameters(), lr=args.lr, betas=(args.b1, args.b2)
- 1
- 2
用Adam优化器优化了生成器和判别器。
生成器和判别器都用Adam优化器优化。传递给优化器的参数有三个:
- 生成器和判别器参数,或要优化的权重
-学习速率 - 贝塔系数b1和b2计算平均梯度在反向传播过程中
训练网络
判别器
判别器同时训练真假图像。
for epoch in range(1, args.n_epochs+1): D_loss_list, G_loss_list = [], [] for index, (real_images, _) in enumerate(train_loader): D_optimizer.zero_grad() # zero-out the old gradients real_images = real_images.to(device) real_target = Variable(torch.ones(real_images.size(0), 1).to(device)) fake_target= Variable(torch.zeros(real_images.size(0), 1).to(device)) # Training Discriminator on Real Data D_real_loss = adversarial_loss(discriminator(real_images), real_target) # noise vector sampled from a normal distribution noise_vector = Variable(torch.randn(real_images.size(0), args.latent_dim).to(device)) noise_vector = noise_vector.to(device) generated_image = generator(noise_vector) # Training Discriminator on Fake Data D_fake_loss = adversarial_loss(discriminator(generated_image), fake_target) D_total_loss = D_real_loss + D_fake_loss D_loss_list.append(D_total_loss) D_total_loss.backward() D_optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
判别器的训练分为两部分:真实图像和假图像(由生成器产生)。当我们处理批量数据集时,判别器将图像分类为真实的或假的。它有两种损失:真正的损失和虚假损失。加起来,他们给出了合并损失(你甚至可以取两个损失的平均值),这被用来优化判别器的权重。
生成器
生成器用来自判别器的反馈进行训练。
# Train G on D's output
G_optimizer.zero_grad() # zero out the old gradients
generated_image = generator(noise_vector)
G_loss =
adversarial_loss(discriminator(generated_image),
real_target) # G tries to dupe the discriminator
G_loss_list.append(G_loss)
G_loss.backward()
G_optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 将噪声向量输入生成器,生成器生成伪generated_image。
- 接下来,将generated_image传递给识别器进行分类。
注意:adversarial_loss是在标签为real_target(1)的情况下计算的,因为您希望生成器欺骗判别器并生成真实的图像。
最后,G_loss.backward()计算梯度,G_optimizer.step()优化生成器的参数。
判别器和生成器损失图
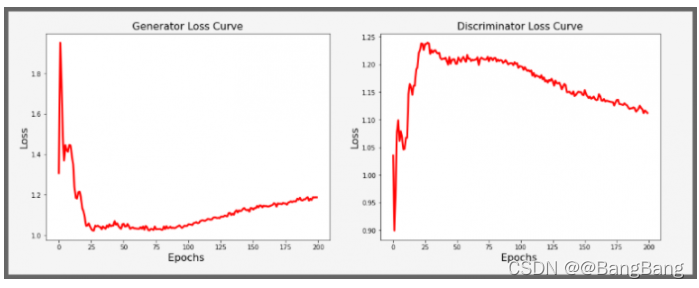
16 训练后的生成器和判别器损失曲线。
从以上的损耗曲线可以明显看出,判别器的损失最初很低,而生成器的损耗很高。然而,随着训练的进行,我们看到生成器的损失在减少,这意味着它能产生更好的图像,并能骗过判别器。因此,鉴别器的损失增加。当然,你不能期望一个平滑的图形。在80epoch前后,生成器的损耗再次上升,这可能是由于各种因素造成的。一个原因是,当判别器经过训练时,它改变了生成器的损失情况。它也可能标志着训练在这里结束,在这个~80 epoch,生成器已经无法再继续优化了。
结果
看看下面的三张图片。生成器在三个不同的训练阶段产生了它们。您可以清楚地看到,最初,生成器产生的是噪声图像。但随着训练的进行,它开始生成看起来更真实的逼真的图像。

图17 图像生成器在三个不同的训练阶段生成。
Tensorflow实现
让我们在Tensorflow中重现GAN的Pytorch实现。对于这个实现,我们将使用Tensorflow v2.3.0和Keras v2.4.3。
导入包
#import the required packages import os import time import tensorflow as tf from tensorflow.keras import layers from IPython import display import matplotlib.pyplot as plt %matplotlib inline # construct the argument parser parser = argparse.ArgumentParser() parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training") parser.add_argument("--batch_size", type=int, default=128, help="size of the batches") parser.add_argument("--lr", type=float, default=2e-4, help="adam: learning rate") parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient") parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient") parser.add_argument("--latent_dim", type=int, default=100, help="dimension of the latent space (generator's input)") parser.add_argument("--img_size", type=int, default=28, help="image size") parser.add_argument("--channels", type=int, default=1, help="image channels") args = parser.parse_args()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
数据加载和预处理
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_train = (x_train - 127.5) / 127.5 # Normalize the images to [-1, 1]
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(x_train).\
shuffle(60000).batch(args.batch_size)
- 1
- 2
- 3
- 4
- 5
- 6
定义生成器网络
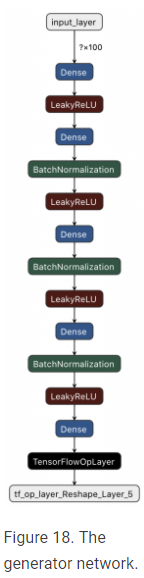
def generator(image_dim): inputs = layers.Input(shape=(100,)) x = layers.Dense(128, kernel_initializer=tf.keras.initializers.he_uniform)(inputs) print(x.dtype) x = layers.LeakyReLU(0.2)(x) x = layers.Dense(256, kernel_initializer=tf.keras.initializers.he_uniform)(x) x = layers.BatchNormalization(momentum=0.1, epsilon=0.8)(x) x = layers.LeakyReLU(0.2)(x) x = layers.Dense(512, kernel_initializer=tf.keras.initializers.he_uniform)(x) x = layers.BatchNormalization(momentum=0.1, epsilon=0.8)(x) x = layers.LeakyReLU(0.2)(x) x = layers.Dense(1024, kernel_initializer=tf.keras.initializers.he_uniform)(x) x = layers.BatchNormalization(momentum=0.1, epsilon=0.8)(x) x = layers.LeakyReLU(0.2)(x) x = layers.Dense(image_dim, activation='tanh', kernel_initializer=tf.keras.initializers.he_uniform)(x) outputs = tf.reshape(x, [-1, args.img_size, args.img_size, args.channels], name=None) model = tf.keras.Model(inputs, outputs, name="Generator") return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
无论是TensorFlow还是PyTorch,生成器的架构仍然和上面一样。你确实需要修改生成器函数。
生成器被输入一个100 d的噪声矢量,从一个正态分布采样。
我们定义输入层,形状为(100,)。
PyTorch的线性层被Tensorflow的密集层所取代。
在PyTorch中,线性层的默认权重初始化器是kaiming_uniform。TensorFlow使用he_uniform,这与he_uniform非常相似。
批量规范层的动量值更改为0.1(默认为0.99)。
我们使用tf将784-d张量重塑为(Batch Size, 28, 28, 1)。重塑,第一个参数是输入张量,第二个参数是张量的新形状。最后,我们通过传递生成器函数的输入和输出层来创建模型
判别函数
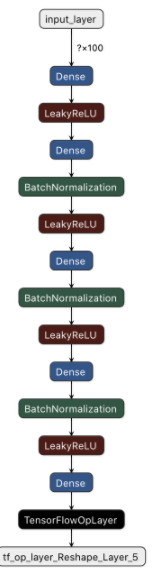
def discriminator():
inputs = layers.Input(shape=(args.img_size, args.img_size, args.channel))
reshape = tf.reshape(inputs, [-1, 784], name=None)
x = layers.Dense(512, kernel_initializer=tf.keras.initializers.he_uniform)(reshape)
x = layers.LeakyReLU(0.2)(x)
x = layers.Dense(256, kernel_initializer=tf.keras.initializers.he_uniform)(x)
x = layers.LeakyReLU(0.2)(x)
outputs = layers.Dense(1, activation='sigmoid', kernel_initializer=tf.keras.initializers.he_uniform)(x)
model = tf.keras.Model(inputs, outputs, name="Discriminator")
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
请记住,判别器是一个二元分类器,仅由完全连接的层组成。因此,判别器期望一个形状张量(Batch Size, 28, 28, 1)。但是判别器函数只由dense layers组成。因此,需要将张量重塑为形状向量(Batch Size, 784)。
最后一层是sigmoid激活函数,它将输出值压缩在0(假)和1(真)之间。
下图表示判别器网络结构。查看它以获得更多关于网络布局的见解。
损失函数
adversarial_loss = tf.keras.losses.BinaryCrossentropy()
- 1
定义二元交叉熵损失来模拟两个网络的目标。
生成器 Loss
def generator_loss(fake_output):
gen_loss = adversarial_loss(tf.ones_like(fake_output), fake_output)
#print(gen_loss)
return gen_loss
- 1
- 2
- 3
- 4
注意:计算generator_loss时,标签为real_target(1),因为您希望生成器欺骗判别器并生成真实的图像
生判别器 Loss
def discriminator_loss(real_output, fake_output):
real_loss = adversarial_loss(tf.ones_like(real_output), real_output)
fake_loss = adversarial_loss(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
#print(total_loss)
return total_loss
- 1
- 2
- 3
- 4
- 5
- 6
判别器损失是真假损失的总和,它的工作是区分真图像和由生成器产生的图像。不像生成器损失,这里:
真实的(原始图像)输出预测标签是1虚假的输出预测标签是0
Optimizer
generator_optimizer = tf.keras.optimizers.Adam(lr = args.lr, beta_1 = args.b1, beta_2 = args.b2 )
discriminator_optimizer = tf.keras.optimizers.Adam(lr = args.lr, beta_1 = args.b1, beta_2 = args.b2 )
- 1
- 2
训练判别器和生成器
@tf.function def train_step(images): noise = tf.random.normal([args.batch_size, args.latent_dim]) with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape: generated_images = generator(noise, training=True) real_output = discriminator(images, training=True) fake_output = discriminator(generated_images, training=True) gen_loss = generator_loss(fake_output) disc_loss = discriminator_loss(real_output, fake_output) gradients_of_gen = gen_tape.gradient(gen_loss, generator.trainable_variables) # computing the gradients gradients_of_disc = disc_tape.gradient(disc_loss, discriminator.trainable_variables) # computing the gradients generator_optimizer.apply_gradients(zip(gradients_of_gen, generator.trainable_variables))#updating generator parameter discriminator_optimizer.apply_gradients(zip( gradients_of_disc,discriminator.trainable_variables))#updating discriminator parameter
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
train_step函数是整个GAN训练的核心。因为这是您组合上面定义的所有训练函数的地方。注意@@tf.function ,它将train_step函数编译为一个可调用的TensorFlow图。同时,加快训练时间
在训练过程中,
- 首先,我们采用服从正态分布的噪声并输入生成器中。
- 然后生成器模型生成一幅图像。
- 我们首先向判别器模型输入真实图像。然后输入由生成器模型产生的图像,这些图像分为真实图像(来自于训练集)和假图像(由生成器产生)。
- 计算这些模型中的每个模型的损失:gen_loss和disc_loss。
- 在计算梯度后,生成器和判别器参数更新,使用Adam优化器。
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
train(train_dataset, args.epoch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果
看看下面的三个图像网格。每个网格由16张图像组成,由生成器在训练的三个不同阶段生成。与在Pytorch实现中一样,您可以看到,最初,生成器会生成噪声图像。但随着训练的进展,生成器开始生产更逼真的图像。


