
- 1输入参数的数目不足 matlab_干货|利用MATLAB实现FMCW MIMO雷达的超分辨测角
- 2CROSSFORMER: A VERSATILE VISION TRANSFORMER BASED ON CROSS-SCALE ATTENTION 论文阅读笔记
- 3Javascript-力扣-hot100-49. 字母异位词分组
- 4AI/DM相关conference ddl(更新中)_iclr2024
- 5[深度学习][转载]Msnhnet一款优秀轻量的用于推理pytorch模型的框架
- 6我给Chat GPT写了个记忆系统_chat gpt 会话长记忆
- 7企业如何设计和实施有效的网络安全演练?
- 8重磅!459页《用Python进行深度学习》电子书及源码下载!_《使用 python 进行深度学习》pdf 百度云
- 9python&anconda系列:【ChatGLM2-6B】运行问题、【ChatGLM2-6B】环境部署_chatglm2运行时没有回复
- 10SINE: 一种基于扩散模型的单图像编辑解决方案_微调文本到图像扩散模型过拟合的问题
C#学习笔记之正则表达式_:~itjpt'y- u m\ y+re c\x= ckpg-
赞
踩
正则表达式 是一种匹配输入文本的模式。
.Net 框架提供了允许这种匹配的正则表达式引擎。
模式由一个或多个字符、运算符和结构组成。
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式是繁琐的,但它是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。只要认真阅读本教程,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
许多程序设计语言都支持利用正则表达式进行字符串操作。
正则表达式的使用,可以通过简单的办法来实现强大的功能。下面先给出一个简单的示例:
-
^ 为匹配输入字符串的开始位置。
-
[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
-
abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。

匹配以数字开头,并以 abc 结尾的字符串
- var str = "123abc";
- var patt1 = /^[0-9]+abc$/;
- document.write(str.match(patt1));
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
-
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)。
-
runoo*b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)。
-
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)。
| 字符 | 描述 |
|---|---|
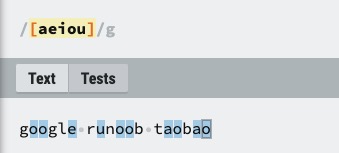
| [ABC] | 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。
|
| [^ABC] | 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。 
|
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。 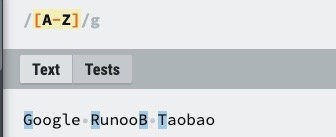
|
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
|
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 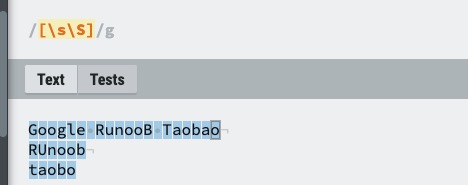
|
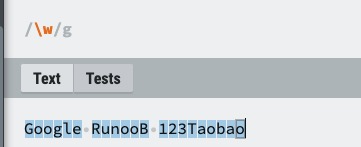
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
|

非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。要匹配 $ 字符本身,请使用 \$。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 |
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 \. 。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\\' 匹配 "\",而 '\(' 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 \^。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 \|。 |
限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
定位符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式。
若要匹配一行文本开始处的文本,请在正则表达式的开始使用 ^ 字符。不要将 ^ 的这种用法与中括号表达式内的用法混淆。
若要匹配一行文本的结束处的文本,请在正则表达式的结束处使用 $ 字符。
修饰符
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配 | 查找所有的匹配项。 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
元字符
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\\' 匹配 "\" 而 "\(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ' |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |

运算符优先级
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作 字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
匹配规则
[a-z] // 匹配所有的小写字母 [A-Z] // 匹配所有的大写字母 [a-zA-Z] // 匹配所有的字母 [0-9] // 匹配所有的数字 [0-9\.\-] // 匹配所有的数字,句号和减号 [ \f\r\t\n] // 匹配所有的白字符
[^a-z] //除了小写字母以外的所有字符
[^\\\/\^] //除了(\)(/)(^)之外的所有字符
[^\"\'] //除了双引号(")和单引号(')之外的所有字符
| 字符簇 | 描述 |
|---|---|
| [[:alpha:]] | 任何字母 |
| [[:digit:]] | 任何数字 |
| [[:alnum:]] | 任何字母和数字 |
| [[:space:]] | 任何空白字符 |
| [[:upper:]] | 任何大写字母 |
| [[:lower:]] | 任何小写字母 |
| [[:punct:]] | 任何标点符号 |
| [[:xdigit:]] | 任何16进制的数字,相当于[0-9a-fA-F] |
| 字符簇 | 描述 |
|---|---|
| ^[a-zA-Z_]$ | 所有的字母和下划线 |
| ^[[:alpha:]]{3}$ | 所有的3个字母的单词 |
| ^a$ | 字母a |
| ^a{4}$ | aaaa |
| ^a{2,4}$ | aa,aaa或aaaa |
| ^a{1,3}$ | a,aa或aaa |
| ^a{2,}$ | 包含多于两个a的字符串 |
| ^a{2,} | 如:aardvark和aaab,但apple不行 |
| a{2,} | 如:baad和aaa,但Nantucket不行 |
| \t{2} | 两个制表符 |
| .{2} | 所有的两个字符 |
字符转义
| 转义字符 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| \a | 与报警 (bell) 符 \u0007 匹配。 | \a | "Warning!" + '\u0007' 中的 "\u0007" |
| \b | 在字符类中,与退格键 \u0008 匹配。 | [\b]{3,} | "\b\b\b\b" 中的 "\b\b\b\b" |
| \t | 与制表符 \u0009 匹配。 | (\w+)\t | "Name\tAddr\t" 中的 "Name\t" 和 "Addr\t" |
| \r | 与回车符 \u000D 匹配。(\r 与换行符 \n 不是等效的。) | \r\n(\w+) | "\r\nHello\nWorld." 中的 "\r\nHello" |
| \v | 与垂直制表符 \u000B 匹配。 | [\v]{2,} | "\v\v\v" 中的 "\v\v\v" |
| \f | 与换页符 \u000C 匹配。 | [\f]{2,} | "\f\f\f" 中的 "\f\f\f" |
| \n | 与换行符 \u000A 匹配。 | \r\n(\w+) | "\r\nHello\nWorld." 中的 "\r\nHello" |
| \e | 与转义符 \u001B 匹配。 | \e | "\x001B" 中的 "\x001B" |
| \ nnn | 使用八进制表示形式指定一个字符(nnn 由二到三位数字组成)。 | \w\040\w | "a bc d" 中的 "a b" 和 "c d" |
| \x nn | 使用十六进制表示形式指定字符(nn 恰好由两位数字组成)。 | \w\x20\w | "a bc d" 中的 "a b" 和 "c d" |
| \c X \c x | 匹配 X 或 x 指定的 ASCII 控件字符,其中 X 或 x 是控件字符的字母。 | \cC | "\x0003" 中的 "\x0003" (Ctrl-C) |
| \u nnnn | 使用十六进制表示形式匹配一个 Unicode 字符(由 nnnn 表示的四位数)。 | \w\u0020\w | "a bc d" 中的 "a b" 和 "c d" |
| \ | 在后面带有不识别的转义字符时,与该字符匹配。 | \d+[\+-x\*]\d+\d+[\+-x\*\d+ | "(2+2) * 3*9" 中的 "2+2" 和 "3*9" |
字符类
| 字符类 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| [character_group] | 匹配 character_group 中的任何单个字符。 默认情况下,匹配区分大小写。 | [mn] | "mat" 中的 "m","moon" 中的 "m" 和 "n" |
| [^character_group] | 非:与不在 character_group 中的任何单个字符匹配。 默认情况下,character_group 中的字符区分大小写。 | [^aei] | "avail" 中的 "v" 和 "l" |
| [ first - last ] | 字符范围:与从 first 到 last 的范围中的任何单个字符匹配。 | [b-d] | [b-d]irds 可以匹配 Birds、 Cirds、 Dirds |
| . | 通配符:与除 \n 之外的任何单个字符匹配。 若要匹配原意句点字符(. 或 \u002E),您必须在该字符前面加上转义符 (\.)。 | a.e | "have" 中的 "ave", "mate" 中的 "ate" |
| \p{ name } | 与 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配。 | \p{Lu} | "City Lights" 中的 "C" 和 "L" |
| \P{ name } | 与不在 name 指定的 Unicode 通用类别或命名块中的任何单个字符匹配。 | \P{Lu} | "City" 中的 "i"、 "t" 和 "y" |
| \w | 与任何单词字符匹配。 | \w | "Room#1" 中的 "R"、 "o"、 "m" 和 "1" |
| \W | 与任何非单词字符匹配。 | \W | "Room#1" 中的 "#" |
| \s | 与任何空白字符匹配。 | \w\s | "ID A1.3" 中的 "D " |
| \S | 与任何非空白字符匹配。 | \s\S | "int __ctr" 中的 " _" |
| \d | 与任何十进制数字匹配。 | \d | "4 = IV" 中的 "4" |
| \D | 匹配不是十进制数的任意字符。 | \D | "4 = IV" 中的 " "、 "="、 " "、 "I" 和 "V"
|
定位点
| 断言 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| ^ | 匹配必须从字符串或一行的开头开始。 | ^\d{3} | "567-777-" 中的 "567" |
| $ | 匹配必须出现在字符串的末尾或出现在行或字符串末尾的 \n 之前。 | -\d{4}$ | "8-12-2012" 中的 "-2012" |
| \A | 匹配必须出现在字符串的开头。 | \A\w{4} | "Code-007-" 中的 "Code" |
| \Z | 匹配必须出现在字符串的末尾或出现在字符串末尾的 \n 之前。 | -\d{3}\Z | "Bond-901-007" 中的 "-007" |
| \z | 匹配必须出现在字符串的末尾。 | -\d{3}\z | "-901-333" 中的 "-333" |
| \G | 匹配必须出现在上一个匹配结束的地方。 | \G | "(1)(3)(5)[7](9)" 中的 "(1)"、 "(3)" 和 "(5)" |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。 | er\b | 匹配"never"中的"er",但不能匹配"verb"中的"er"。 |
| \B | 匹配非单词边界。 | er\B | 匹配"verb"中的"er",但不能匹配"never"中的"er"。 |
分组构造
| 分组构造 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| ( subexpression ) | 捕获匹配的子表达式并将其分配到一个从零开始的序号中。 | (\w)\1 | "deep" 中的 "ee" |
| (?< name >subexpression) | 将匹配的子表达式捕获到一个命名组中。 | (?< double>\w)\k< double> | "deep" 中的 "ee" |
| (?< name1 -name2 >subexpression) | 定义平衡组定义。 | (((?'Open' | "3+2^((1-3)*(3-1))" 中的 "((1-3)*(3-1))" |
| (?: subexpression) | 定义非捕获组。 | Write(?:Line)? | "Console.WriteLine()" 中的 "WriteLine" |
| (?imnsx-imnsx:subexpression) | 应用或禁用 subexpression 中指定的选项。 | A\d{2}(?i:\w+)\b | "A12xl A12XL a12xl" 中的 "A12xl" 和 "A12XL" |
| (?= subexpression) | 零宽度正预测先行断言。 | \w+(?=\.) | "He is. The dog ran. The sun is out." 中的 "is"、 "ran" 和 "out" |
| (?! subexpression) | 零宽度负预测先行断言。 | \b(?!un)\w+\b | "unsure sure unity used" 中的 "sure" 和 "used" |
| (?<=subexpression) | 零宽度正回顾后发断言。 | (?<=19)\d{2}\b | "1851 1999 1950 1905 2003" 中的 "99"、"50"和 "05" |
| (?<! subexpression) | 零宽度负回顾后发断言。 | (?<!wo)man\b | "Hi woman Hi man" 中的 "man" |
| (?> subexpression) | 非回溯(也称为"贪婪")子表达式。 | [13579](?>A+B+) | "1ABB 3ABBC 5AB 5AC" 中的 "1ABB"、 "3ABB" 和 "5AB" |
限定符
| 限定符 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| * | 匹配上一个元素零次或多次。 | \d*\.\d | ".0"、 "19.9"、 "219.9" |
| + | 匹配上一个元素一次或多次。 | "be+" | "been" 中的 "bee", "bent" 中的 "be" |
| ? | 匹配上一个元素零次或一次。 | "rai?n" | "ran"、 "rain" |
| { n } | 匹配上一个元素恰好 n 次。 | ",\d{3}" | "1,043.6" 中的 ",043", "9,876,543,210" 中的 ",876"、 ",543" 和 ",210" |
| { n ,} | 匹配上一个元素至少 n 次。 | "\d{2,}" | "166"、 "29"、 "1930" |
| { n , m } | 匹配上一个元素至少 n 次,但不多于 m 次。 | "\d{3,5}" | "166", "17668", "193024" 中的 "19302" |
| *? | 匹配上一个元素零次或多次,但次数尽可能少。 | \d*?\.\d | ".0"、 "19.9"、 "219.9" |
| +? | 匹配上一个元素一次或多次,但次数尽可能少。 | "be+?" | "been" 中的 "be", "bent" 中的 "be" |
| ?? | 匹配上一个元素零次或一次,但次数尽可能少。 | "rai??n" | "ran"、 "rain" |
| { n }? | 匹配前导元素恰好 n 次。 | ",\d{3}?" | "1,043.6" 中的 ",043", "9,876,543,210" 中的 ",876"、 ",543" 和 ",210" |
| { n ,}? | 匹配上一个元素至少 n 次,但次数尽可能少。 | "\d{2,}?" | "166"、 "29" 和 "1930" |
| { n , m }? | 匹配上一个元素的次数介于 n 和 m 之间,但次数尽可能少。 | "\d{3,5}?" | "166", "17668", "193024" 中的 "193" 和 "024" |
反向引用构造
| 反向引用构造 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| \ number | 反向引用。 匹配编号子表达式的值。 | (\w)\1 | "seek" 中的 "ee" |
| \k< name > | 命名反向引用。 匹配命名表达式的值。 | (?< char>\w)\k< char> | "seek" 中的 "ee" |
备用构造
| 备用构造 | 描述 | 模式 | 匹配 |
|---|---|---|---|
| | | 匹配以竖线 (|) 字符分隔的任何一个元素。 | th(e|is|at) | "this is the day. " 中的 "the" 和 "this" |
| (?( expression )yes | no ) | 如果正则表达式模式由 expression 匹配指定,则匹配 yes;否则匹配可选的 no 部分。 expression 被解释为零宽度断言。 | (?(A)A\d{2}\b|\b\d{3}\b) | "A10 C103 910" 中的 "A10" 和 "910" |
| (?( name )yes | no ) | 如果 name 或已命名或已编号的捕获组具有匹配,则匹配 yes;否则匹配可选的 no。 | (?< quoted>")?(?(quoted).+?"|\S+\s) | "Dogs.jpg "Yiska playing.jpg"" 中的 Dogs.jpg 和 "Yiska playing.jpg" |
替换
| 字符 | 描述 | 模式 | 替换模式 | 输入字符串 | 结果字符串 |
|---|---|---|---|---|---|
| $number | 替换按组 number 匹配的子字符串。 | \b(\w+)(\s)(\w+)\b | $3$2$1 | "one two" | "two one" |
| ${name} | 替换按命名组 name 匹配的子字符串。 | \b(?< word1>\w+)(\s)(?< word2>\w+)\b | ${word2} ${word1} | "one two" | "two one" |
| $$ | 替换字符"$"。 | \b(\d+)\s?USD | $$$1 | "103 USD" | "$103" |
| $& | 替换整个匹配项的一个副本。 | (\$*(\d*(\.+\d+)?){1}) | **$& | "$1.30" | "**$1.30**" |
| $` | 替换匹配前的输入字符串的所有文本。 | B+ | $` | "AABBCC" | "AAAACC" |
| $' | 替换匹配后的输入字符串的所有文本。 | B+ | $' | "AABBCC" | "AACCCC" |
| $+ | 替换最后捕获的组。 | B+(C+) | $+ | "AABBCCDD" | AACCDD |
| $_ | 替换整个输入字符串。 | B+ | $_ | "AABBCC" | "AAAABBCCCC" |
杂项构造
| 构造 | 描述 | 实例 |
|---|---|---|
| (?imnsx-imnsx) | 在模式中间对诸如不区分大小写这样的选项进行设置或禁用。 | \bA(?i)b\w+\b 匹配 "ABA Able Act" 中的 "ABA" 和 "Able" |
| (?#注释) | 内联注释。该注释在第一个右括号处终止。 | \bA(?#匹配以A开头的单词)\w+\b |
| # [行尾] | 该注释以非转义的 # 开头,并继续到行的结尾。 | (?x)\bA\w+\b#匹配以 A 开头的单词 |
Regex 类
| 序号 | 方法 & 描述 |
|---|---|
| 1 | public bool IsMatch( string input ) 指示 Regex 构造函数中指定的正则表达式是否在指定的输入字符串中找到匹配项。 |
| 2 | public bool IsMatch( string input, int startat ) 指示 Regex 构造函数中指定的正则表达式是否在指定的输入字符串中找到匹配项,从字符串中指定的开始位置开始。 |
| 3 | public static bool IsMatch( string input, string pattern ) 指示指定的正则表达式是否在指定的输入字符串中找到匹配项。 |
| 4 | public MatchCollection Matches( string input ) 在指定的输入字符串中搜索正则表达式的所有匹配项。 |
| 5 | public string Replace( string input, string replacement ) 在指定的输入字符串中,把所有匹配正则表达式模式的所有匹配的字符串替换为指定的替换字符串。 |
| 6 | public string[] Split( string input ) 把输入字符串分割为子字符串数组,根据在 Regex 构造函数中指定的正则表达式模式定义的位置进行分割。 |
- class Program
- {
- private static void showMatch(string text, string expr)
- {
- Console.WriteLine("The Expression: " + expr);
- MatchCollection mc = Regex.Matches(text, expr);
- foreach (Match m in mc)
- {
- Console.WriteLine(m);
- }
- }
- static void Main(string[] args)
- {
- string str = "A Thousand Splendid Suns";
-
- Console.WriteLine("Matching words that start with 'S': ");
- showMatch(str, @"\bS\S*");
- Console.ReadKey();
- }
- }


