
- 1马斯克大模型Grok1.5来了:推理能力大升级,支持128k上下文
- 2Python深度学习实例三--房价预测(回归问题)_python房价预测代码
- 3【前端寻宝之路】总结学习使用CSS的引入方式
- 4VGG16/VGG19 网络详解_vgg19和vgg16的区别
- 5Bert的位置编码:position_embeddings(绝对位置可学习参数式编码)
- 6虚拟机中的Linux安装VMware Tools的方法_bin doc etc files install installer lib vmware-ins
- 7Linux -- 图形界面配置Samba;system-config-samba工具
- 8计算机网络(04)
- 9MATLAB-样条插值运算_matlab b样条插补
- 10Python 面对对象(下):装饰器_python 装饰器 操作对象的值
将MNIST的手写数字识别转化为使用yolov5训练的模型_mnist数据集yolo格式
赞
踩
深度学习入门阶段,常常较为先接触的就是MNIST的手写数字识别,其网络模型如下:
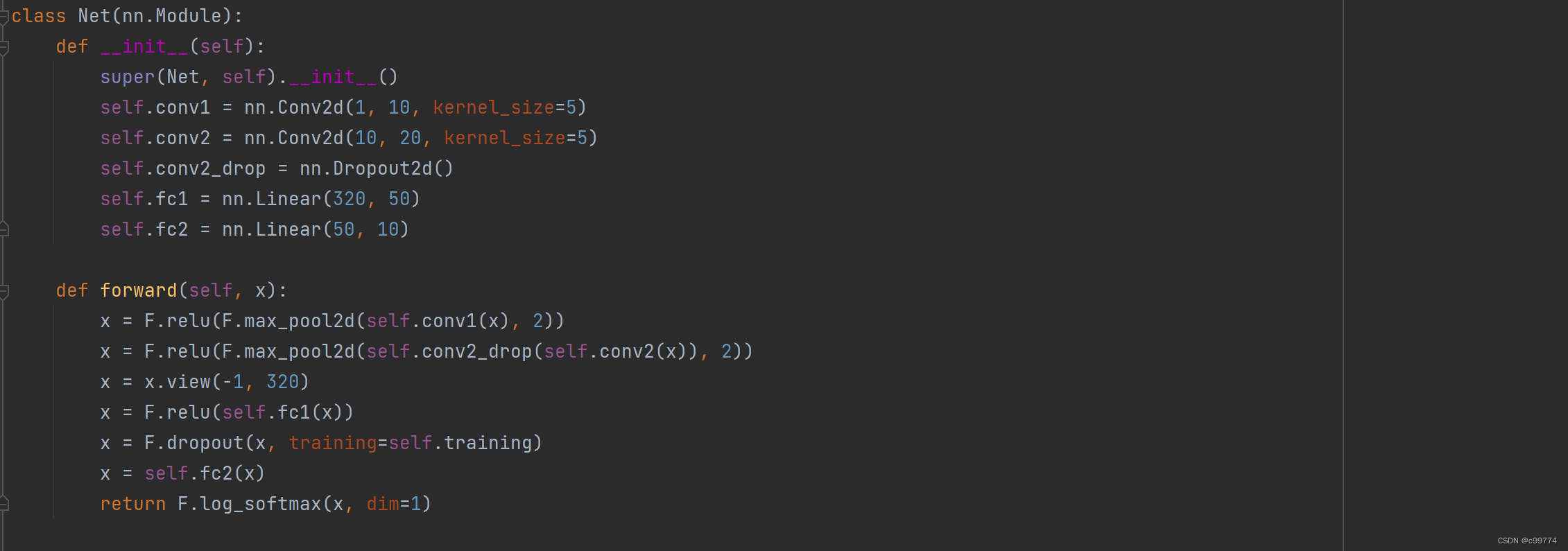 而yolov5又是当前较为流行的算法,刚好有个作业是要改进上面的模型,于是使用yolov5算法来训练手写数字识别的模型。
而yolov5又是当前较为流行的算法,刚好有个作业是要改进上面的模型,于是使用yolov5算法来训练手写数字识别的模型。
但是yolov5常用的是VOC数据集,而目前只有MNIST数据集,显然第一步就是需要讲MNIST数据集转化为VOC数据集:
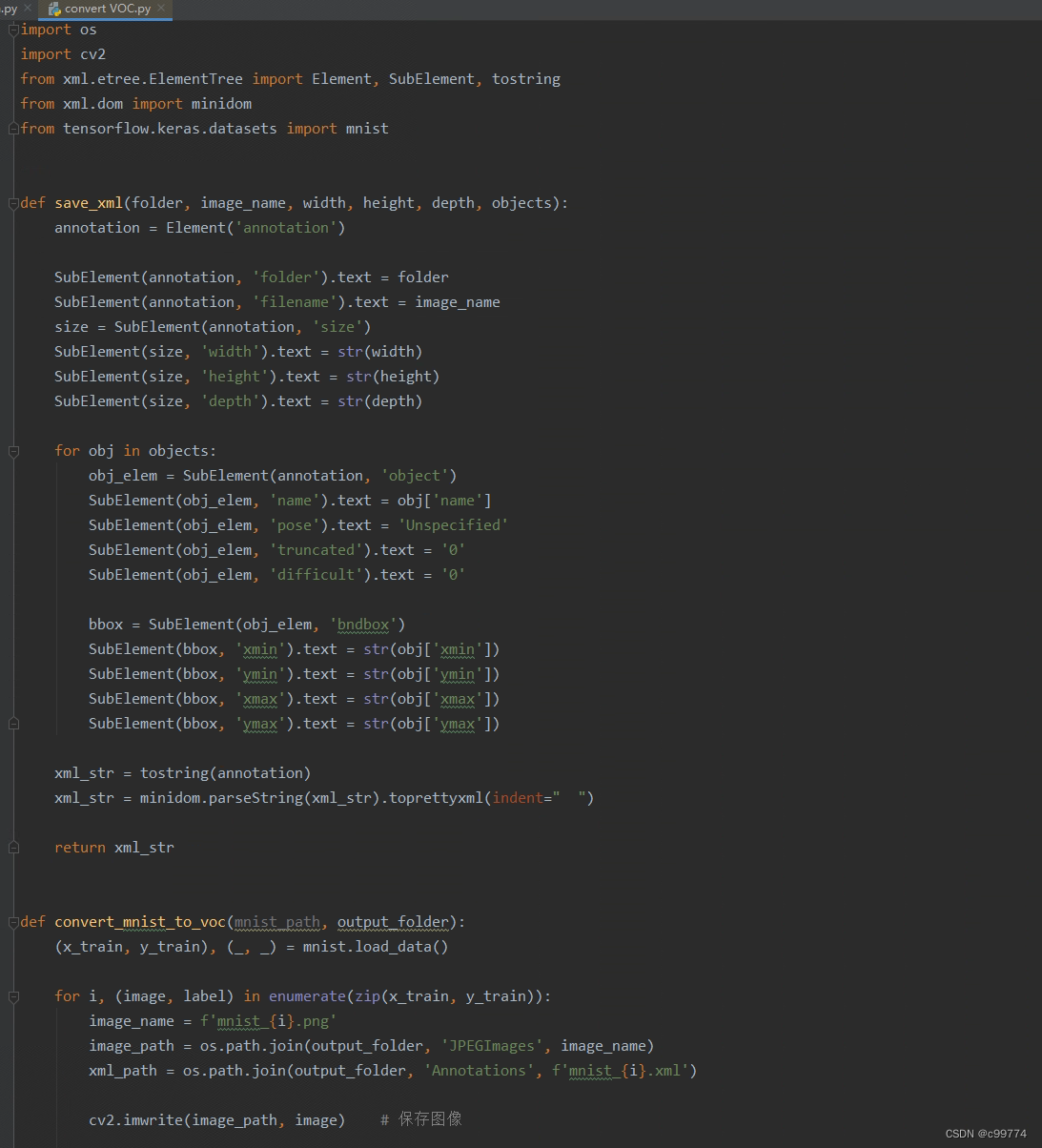
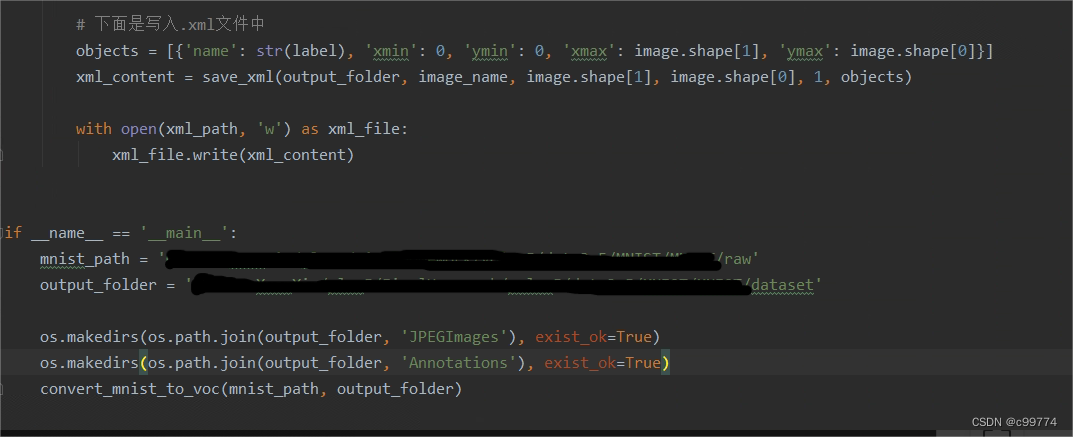
通过使用上面的代码就可以得到两个文件“JPGEImages”与“Annotations”,也就是VOC格式的数据集了

但是我自己常用的是.txt文件,不是.xml文件,于是使用下图所示代码将其转化为.txt文件
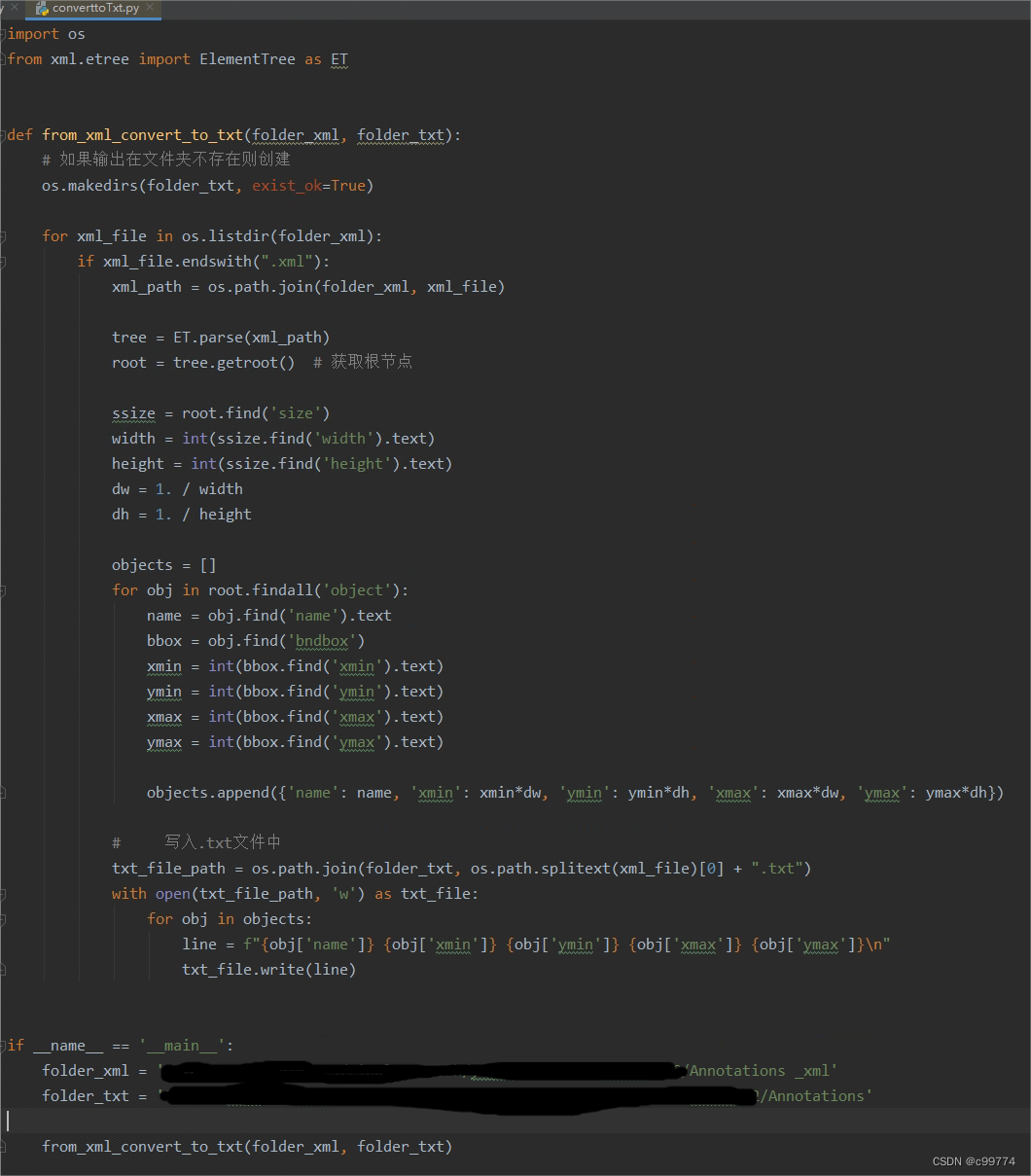
但是这只是将所有图片所对应的.xml转化为.txt文件,并没有classes.txt文件这个就需要手动创建一个文本了
把MNIST数据集转化为VOC数据集基本上大功就快告成了,后面就是划分数据集、修改数据集路径使用train.py训练模型、使用测试数据通过运行detect.py来测试训练好的模型。
测试数据转化为.jpg格式的图片,可以使用下面的代码:

通过测试后的图片可以看到其实效果还是不错的
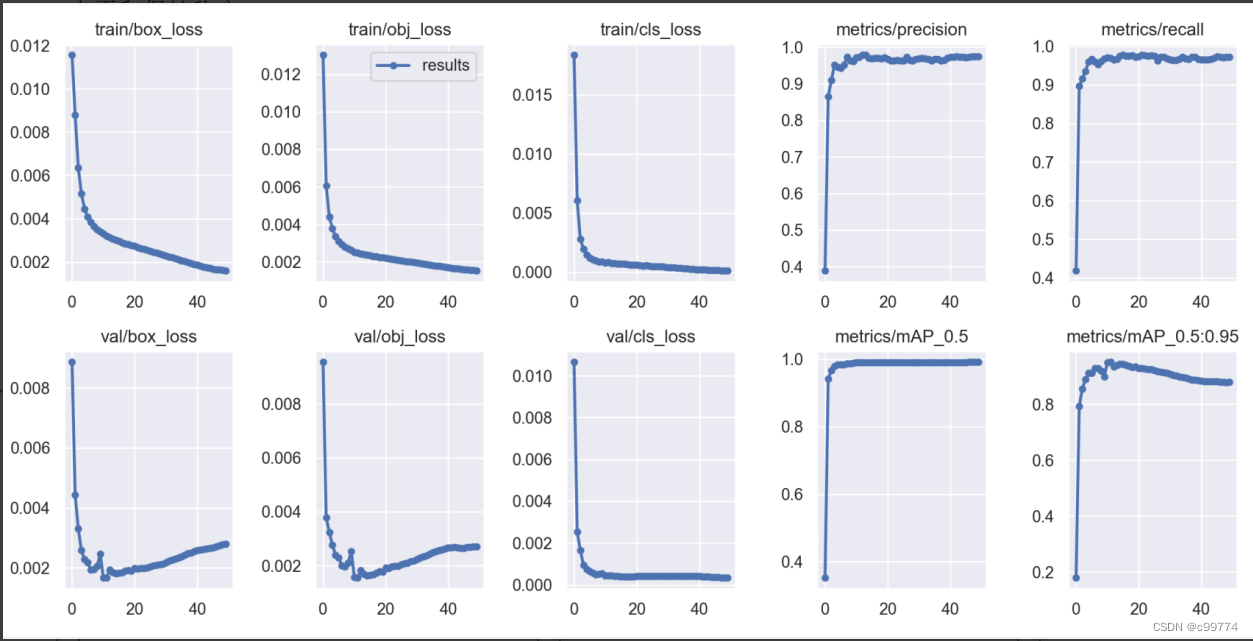
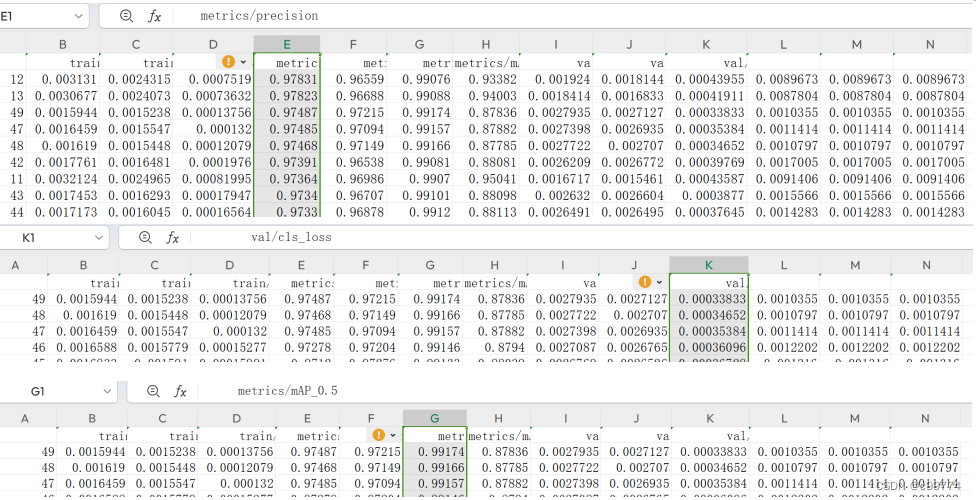
对于训练出来的模型,通过观察数据可以看到模型算法性能较好,其mAp(平均精度)高达99.1%,并且精确率可达到97.8%,分类损失值低至0.00033,该模型的分类能力也是较强的:
但是由于是直接从MNIST数据集转化为VOC数据集的,图片都是没有画框的,而且在这些图片的对应的.txt文件中xy的中心点都是0,框的长度也都是1,这很明显是会出现下面的结果


解决这个问题就需要将转化为.jpg格式的图片通过使用labelimg或者其他什么软件对图片中的数字画框;
另外,当使用自己写的手写数字来测试模型,显然结果很糟糕
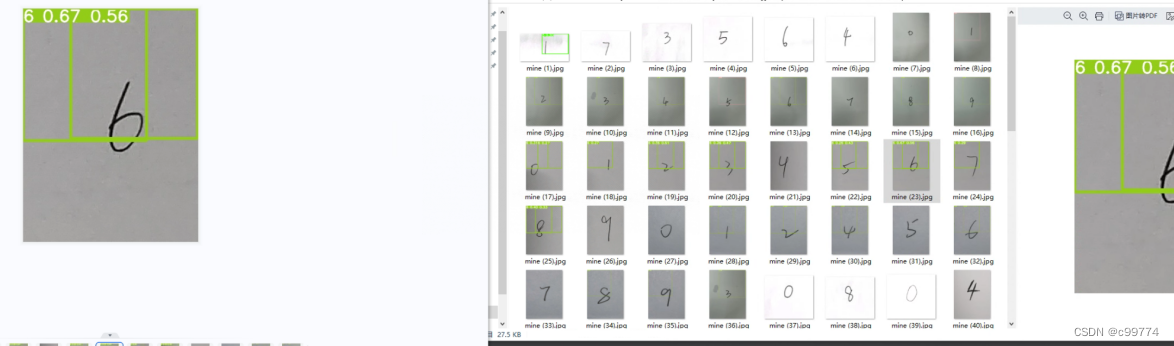
当将图片处理成黑白的28*28像素后,效果有所提高,但仍不是很理想:
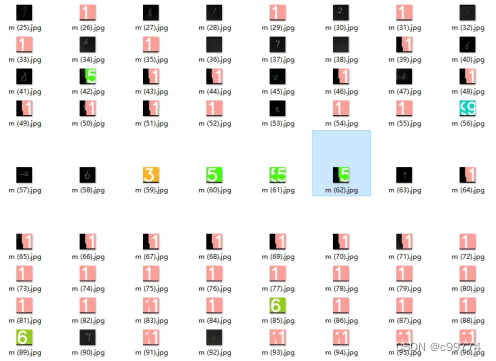
这也说明了模型的鲁棒性不够强。对此,可以通过添加一些日常拍摄的手写数字图片来扩展训练数据集从而提高模型的鲁棒性
以上都是自己尝试得出的,如有错误之处,还请大佬指点一下。

