
热门标签
热门文章
- 1[AIGC] Spring 获取前端请求参数的全面指南
- 2带扰动观测器的全驱动船舶轨迹跟踪自适应动态面滑模控制Matlab仿真_船舶轨迹跟踪matlab仿真
- 3通过房价预测简要介绍十种线性回归算法及python实现_基于决策树的房价预测
- 4 t检验与F检验 /统计常识 / 统计学笔记(2)--随机抽样与统计推断的逻辑_抽样分布与统计推断的逻辑关系
- 5Django报错 HINT: Add or change a related_name argument to the definition for 'GodownentryReturn.suppl
- 6探索PyTorch的情感分析和文本处理技术
- 7搜索之道:信息素养与终身学习的新引擎
- 8Android Studio自带模拟器启动无响应_android emulator closed unexpec、
- 9linux的进程pcd,Linux下 PCL源码安装
- 10LeetCode66.加一
当前位置: article > 正文
Qwen-VL 技术报告总结
作者:笔触狂放9 | 2024-03-31 04:09:49
赞
踩
qwen-vl
感谢如此优秀的开源工作,仓库链接 Qwen-VL
权重分为 Qwen-VL && Qwen-VL-Chat,区别文档稍后介绍
训练过程
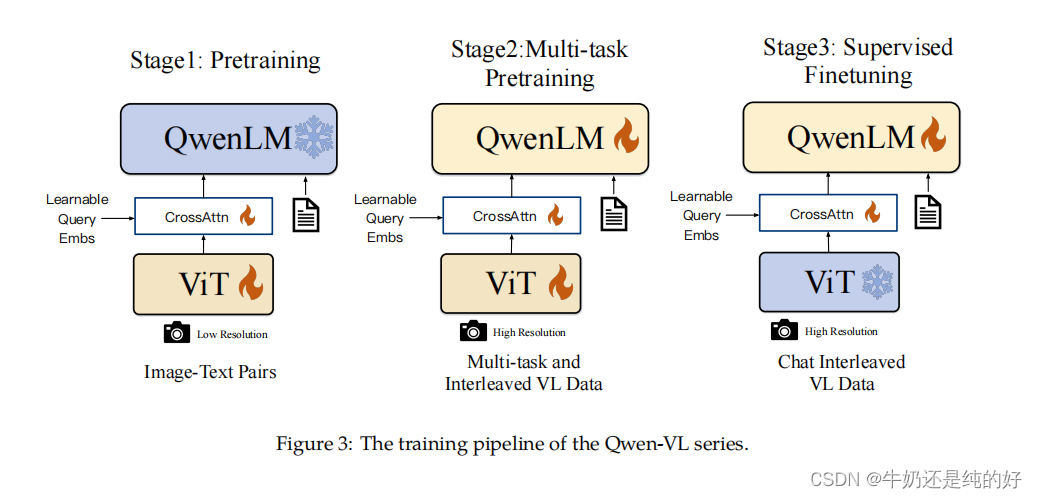
- 在第一阶段中主要使用224X224分辨率训练,训练数据主要来源是公开数据集,经过清洗,数据总量大约是1.4B(中英混合)。训练目标是视觉语言和文本语言对齐。loss函数是交叉熵;训练过程:给定一个输入(例如图像or文本),预测整个词表中作为next token的概率(The language model, given an input (such as an image and some initial text), predicts the probability of each token in the vocabulary being the next token in the sequence.),实际标签转换为one-hot, 然后使用交叉熵损失函数计算两个的差(The actual distribution is represented by the true next token in the training data. In practice, this is often converted into a one-hot encoded vector, where the actual next token has a probability of 1, and all
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/343059
推荐阅读
相关标签

