
- 1大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)_hadoop mysql
- 2【修改huggingface transformers默认缓存文件夹】_transformers_cache
- 3大数据在推荐系统中的作用_推荐系统与大数据安全
- 4android 检测无用资源,一个自动清理Android项目无用资源的工具类及源码
- 5【深度学习】-Imdb数据集情感分析之模型对比(4)- CNN-LSTM 集成模型_cnn-lstm做情感分析的时候需要保证cnn的输出和bilstm的输出维度一致吗
- 6Wireshark 抓包工具与长ping工具pinginfoview使用,安装包_wireshark端口抓包命令
- 7Neo4基础语法学习_neo4j语法教程
- 8注意力机制(Attention)原理详解_attention层
- 9毕业设计 基于单片机的智能盲人头盔系统 - 导盲杖 stm32
- 10基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
从零开始使用MMSegmentation训练Segformer_mmsegmentation segformer
赞
踩
从零开始使用MMSegmentation训练Segformer
写在前面:最新想要用最新的分割算法如:Segformer or SegNeXt 在自己的数据集上进行训练,但是有不是搞语义分割出身的,而且也没有系统的学过MMCV以及MMSegmentation。所以就折腾了很久,感觉利用MMSegmentation搭建框架可能比较系统,但是对于不熟悉的或者初学者非常不友好,因此记录一下自己training Segformer的心路历程。
Segformer paper: https://arxiv.org/abs/2105.15203>
官方实现: https://github.com/NVlabs/SegFormer>
纯Torch版Segformer: https://github.com/camlaedtke/segmentation_pytorch
方法
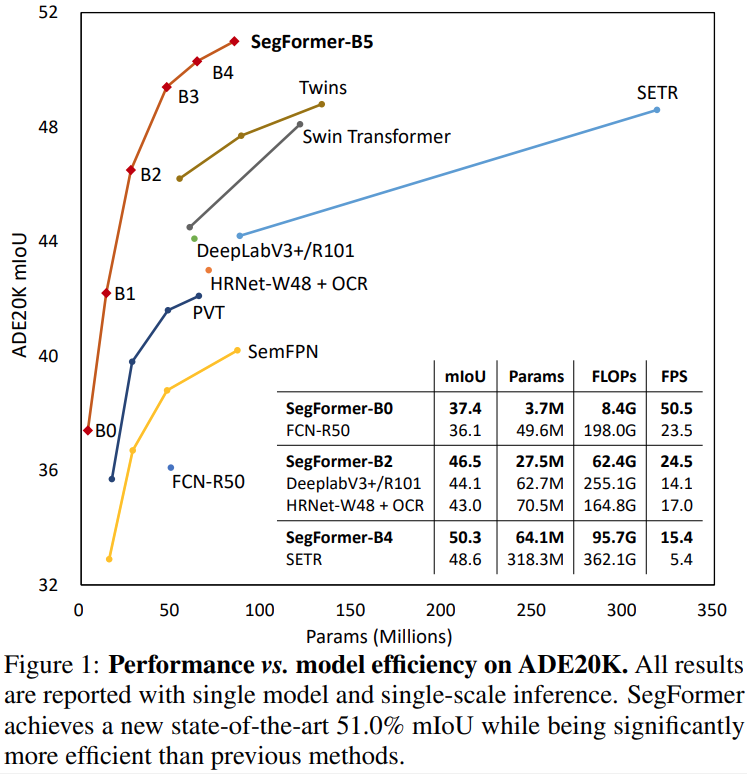
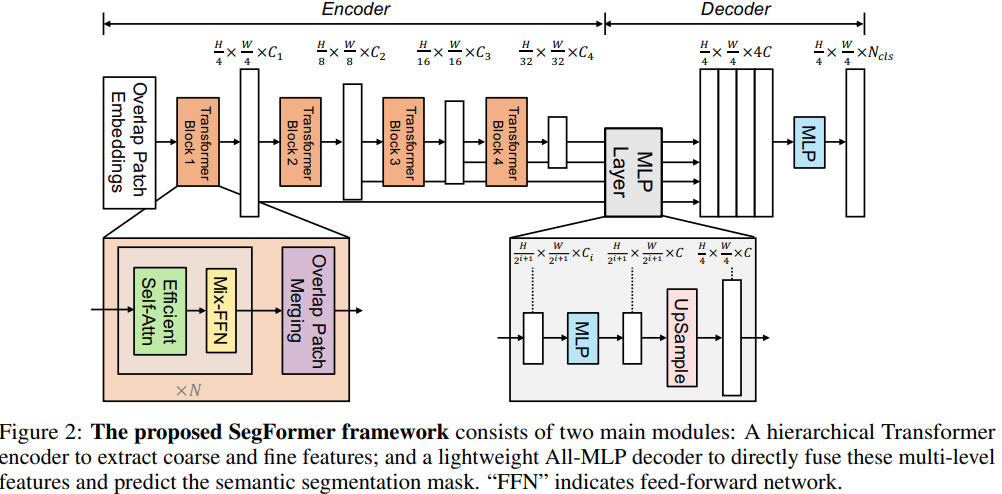
由于本人不是研究语义分割的,所以只能简要地介绍一下Segformer。
SegFormer的动机在于:
① ViT作为backbone只能输出固定分辨率的特征图,这对于密集预测任务显然不够友好;
② 由于self-attention操作的存在,transformer的运算量和参数两都非常大,不利于大尺度图像的分割。
为此作者提出了相应的创新:
① 先是对transformer进行层次化结构设计,得到多层级的特征图;
② 构造轻量级的decoder,仅使用MLP进行特征聚合。
③ 除此之外,SegFormer抛弃了位置信息编码,选择采用MixFCN来学习位置信息,这样可以很好地扩充到不同尺度的测试环境下(避免由于尺寸变化,需要对positional-encoding进行插值,从而影响性能)。最后提出的模型在ADE20k上达到了新sota,并且在速度、性能和鲁棒性上都表现很好。
程序复现
在重新训练过程中主要参考了:手把手教你使用Segformer训练自己的数据
作者给的教程比较详细, 但是有几处修改并不合适,导致我复现出来的结果没啥效果,因此记录一下自己的采坑记录。
自己的主要配置为:
CUDA 10.1
Pytorch 1.10.0, torchvision 0.11.1
MMCV-full 1.3.0
其中在安装MMCV-full过程中还遇到了很多问题,主要是版本不适配的原因导致的。
在安装好环境后,首先从Github下载SegFormer的项目工程: https://github.com/NVlabs/SegFormer
然后进去SegFormer目录:
pip install -r requirements.txt
pip install -e . --user
安装需要的依赖。
数据集准备
代码默认用的是ADE20K数据集进行训练
ADE20K数据集 格式如下,按照要求放就完了
├── data
│ ├── ade
│ │ ├── ADEChallengeData2016
│ │ │ ├── annotations
│ │ │ │ ├── training
│ │ │ │ ├── validation
│ │ │ ├── images
│ │ │ │ ├── training
│ │ │ │ ├── validation
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
但是@中科哥哥使用的是VOC的数据格式,因此就使用了VOC的数据格式
├── VOCdevkit
│ ├── VOC2012
│ │ ├── ImageSets
│ │ │ ├── Segmentation
│ │ │ │ ├── train.txt
│ │ │ │ ├── val.txt
│ │ │ │ ├── trainval.txt
│ │ │ ├── JPEGImages
│ │ │ │ ├── *.jpg #所有图片
│ │ │ ├── SegmentationClass
│ │ │ │ ├── *.jpg #所有标签图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在这里可以根据自己的需要修改
下面是我自己的数据格式:
├── VOCdevkit
│ ├── VOC2012
│ │ ├── ImageSets
│ │ │ ├── Segmentation
│ │ │ │ ├── train.txt
│ │ │ │ ├── val.txt
│ │ │ │ ├── test.txt
│ │ │ ├── JPEGImages
│ │ │ │ ├── *.png#所有图片
│ │ │ ├── SegmentationClass
│ │ │ │ ├── *.png #所有标签图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
其实完全可以简洁一点:
├── MFNet
│ ├── Segmentation
│ │ ├── train.txt
│ │ ├── val.txt
│ │ ├── test.txt
│ ├── Images
│ │ ├── *.png#所有图片
│ ├── Label
│ │ ├── *.png #所有标签图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其中: train.txt; val.txt; test.txt; 只要图片名,不需要后缀和路径 如下
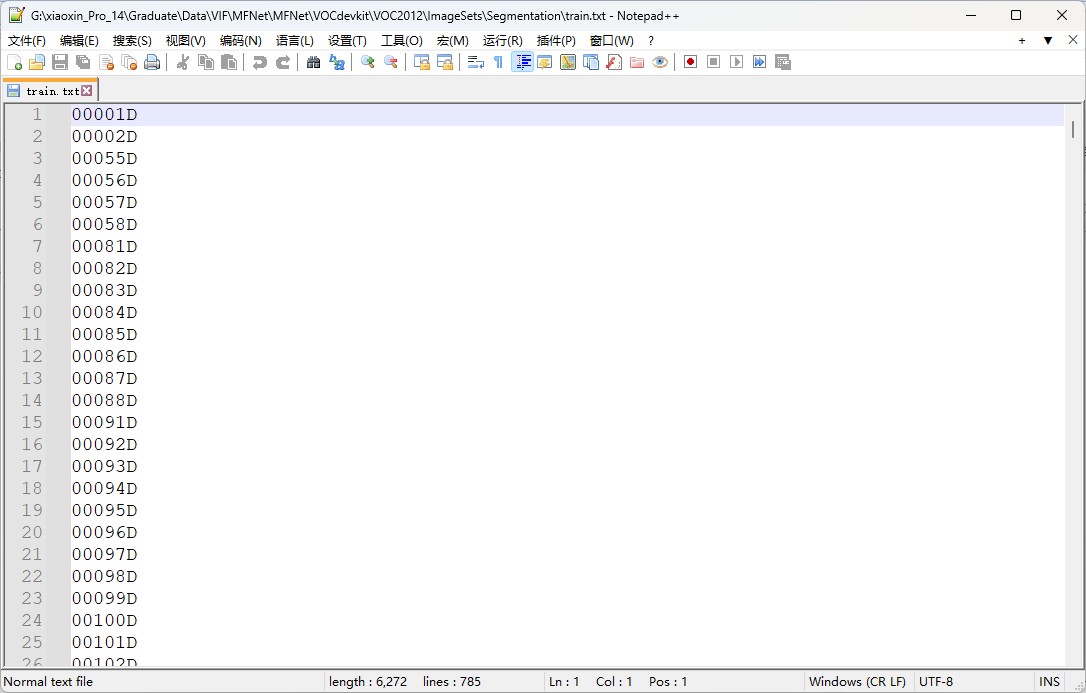
后面的程序修改都基于复杂的版本进行介绍(自己在程序复现时使用的复杂的目录,因为是按照的教程来的)
数据准备好 之后可以在SegFormer目录先新建一个/datasets/ 目录来存放自己的数据集
程序修改
-
在 mmseg/datasets/voc.py修改自己数据集的类别即修改CLASSES 和 PALETTE在我自己的数据集中一共由于9个类别,所以修改如下:

-
在 mmseg/models/decode_heads/segformer_head.py 中BatchNorm 方式(如果使用单卡训练的话就修改,多卡训练的话就不用修改)。 将第59行的SyncBN 修改为 BN
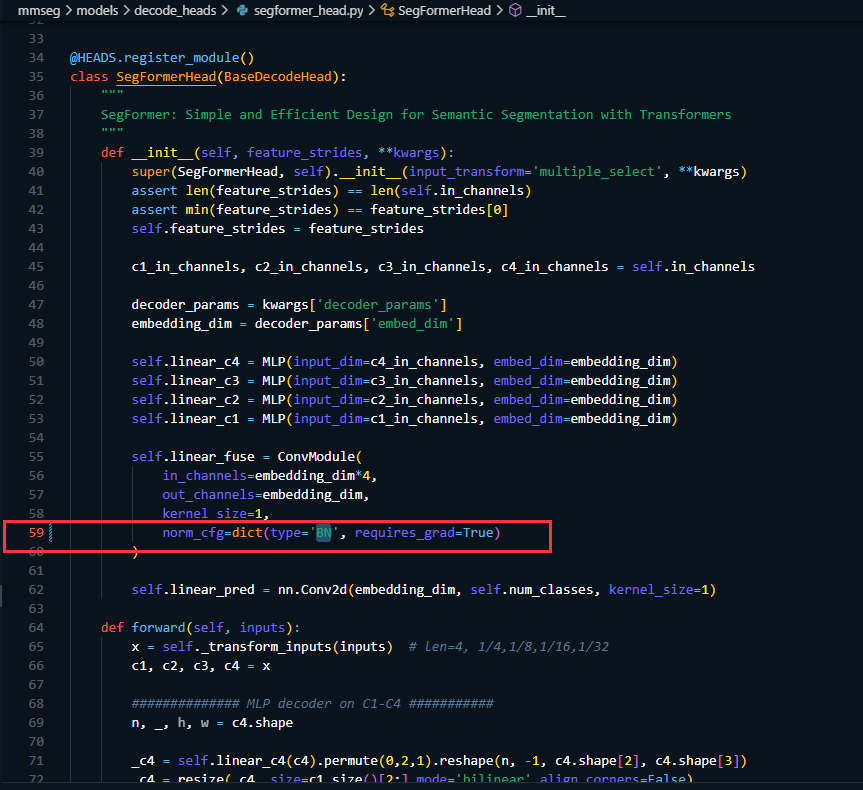
-
修改 local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py 的配置文件(这里我们使用的是B5模型,需要使用哪个模型就修改对应的配置文件即可,配置文件都位于:**local_configs/segformer/**下 );主要修改
__base__=[]中的数据集文件路径(也就是下图中的第二行)
指定dataset_type的类型,此处
dataset_type = 'PascalVOCDataset'
data_root = '/data1/timer/Segmentation/SegFormer/datasets/VOC2012' 也可以给相对路径。
然后根据自己的数据需要修改文件中的crop_size, train_pipline中的img_scale,以及test_pipline中的img_scale
- 1
- 2
- 3
- 4
- 5
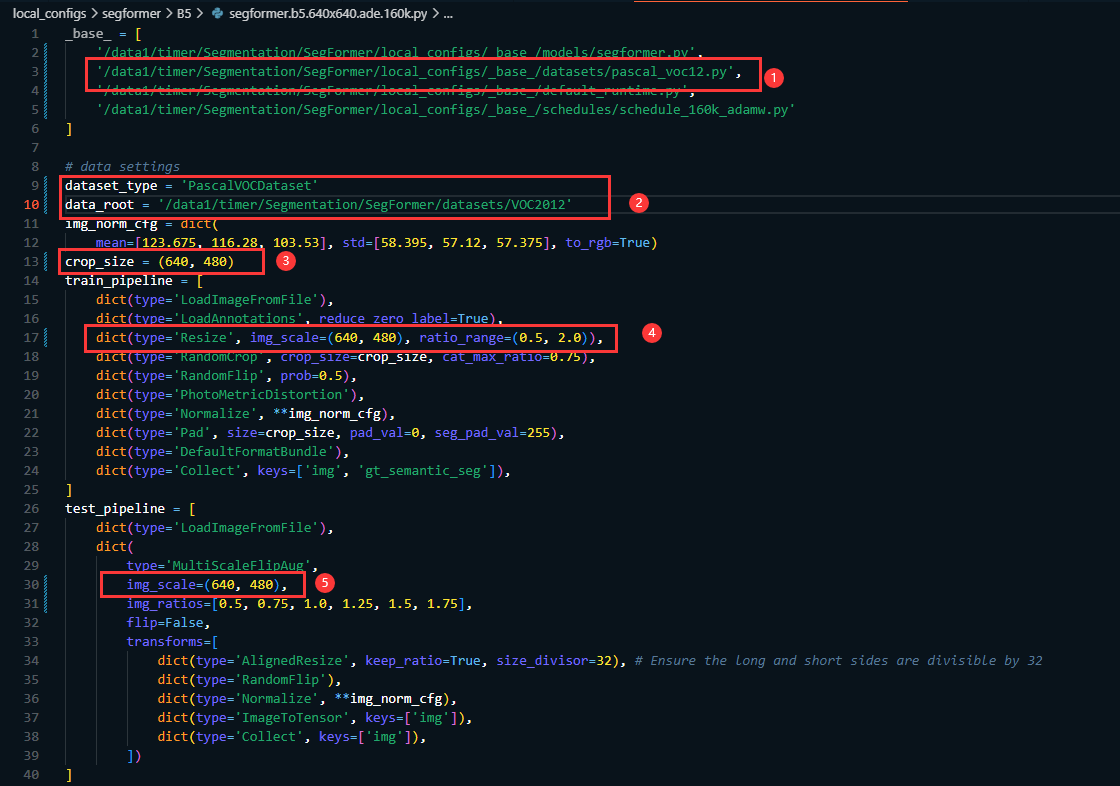
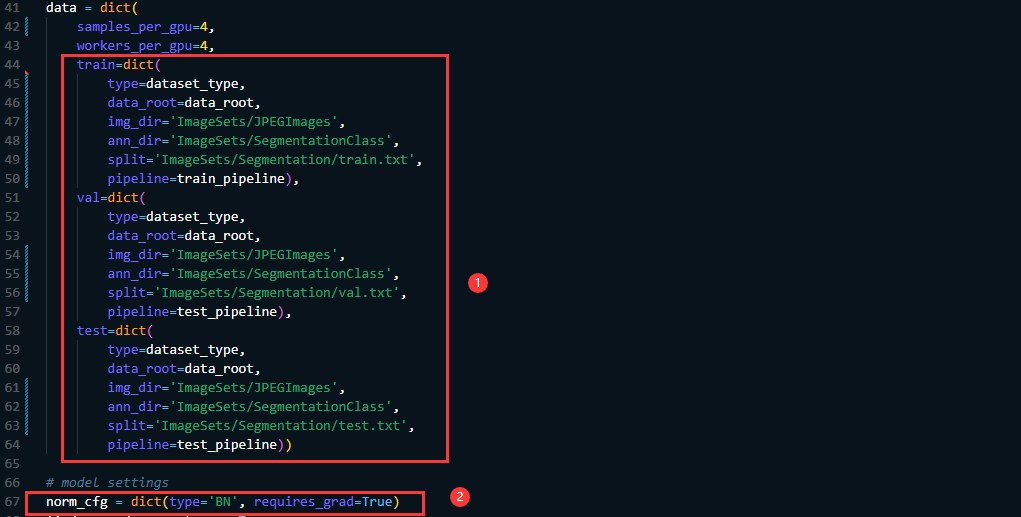
同时还需要在data字典中指定 img_dir, ann_dir, 以及split的路径,如果是单卡训练的话需要将norm_cfg 的type由的SyncBN 修改为 BN
接下来继续修改模型相关的文件,主要是给定预训练权重的位置即修改:pretrained 以及backbone[‘type’],这里的type因为使用的是B5的结构所以type就指定为mit_b5,然后预训练权重需要从项目中给定的链接下载。值得注意的是还需要指定decode_head[‘num_classes’] (这个需要根据你的数据集来指定,因为我的数据集中包含9类,所以这里就设置为9了)
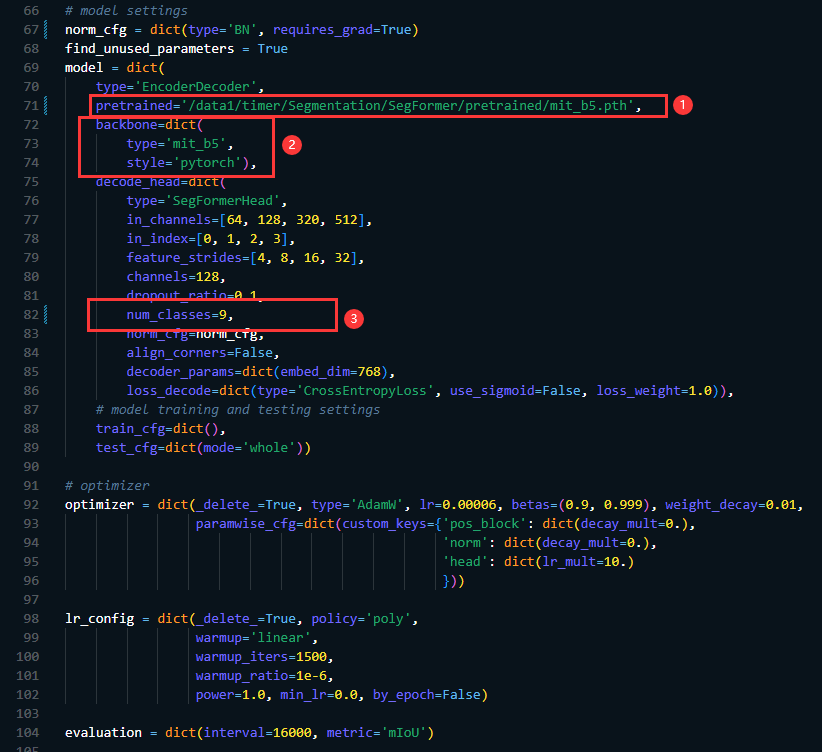
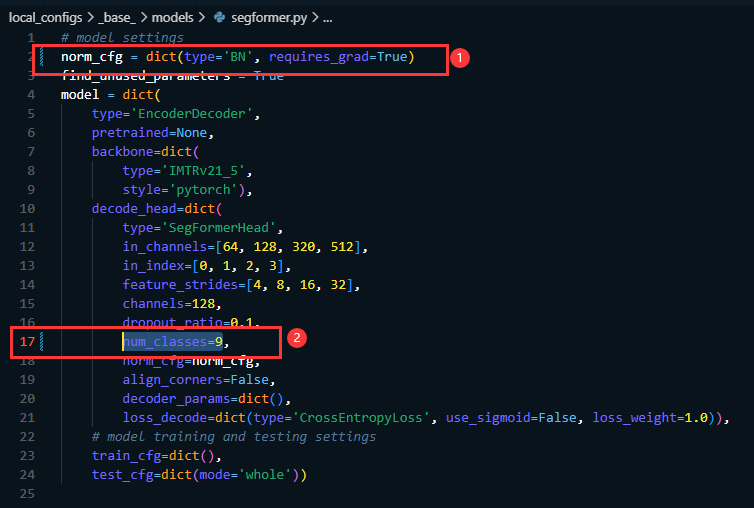
- 在 local_configs/base/models/segformer.py 修改
norm_cfg[‘type’]=‘BN’
num_classes=9 (这里修改成你数据集对应的类别的数量)
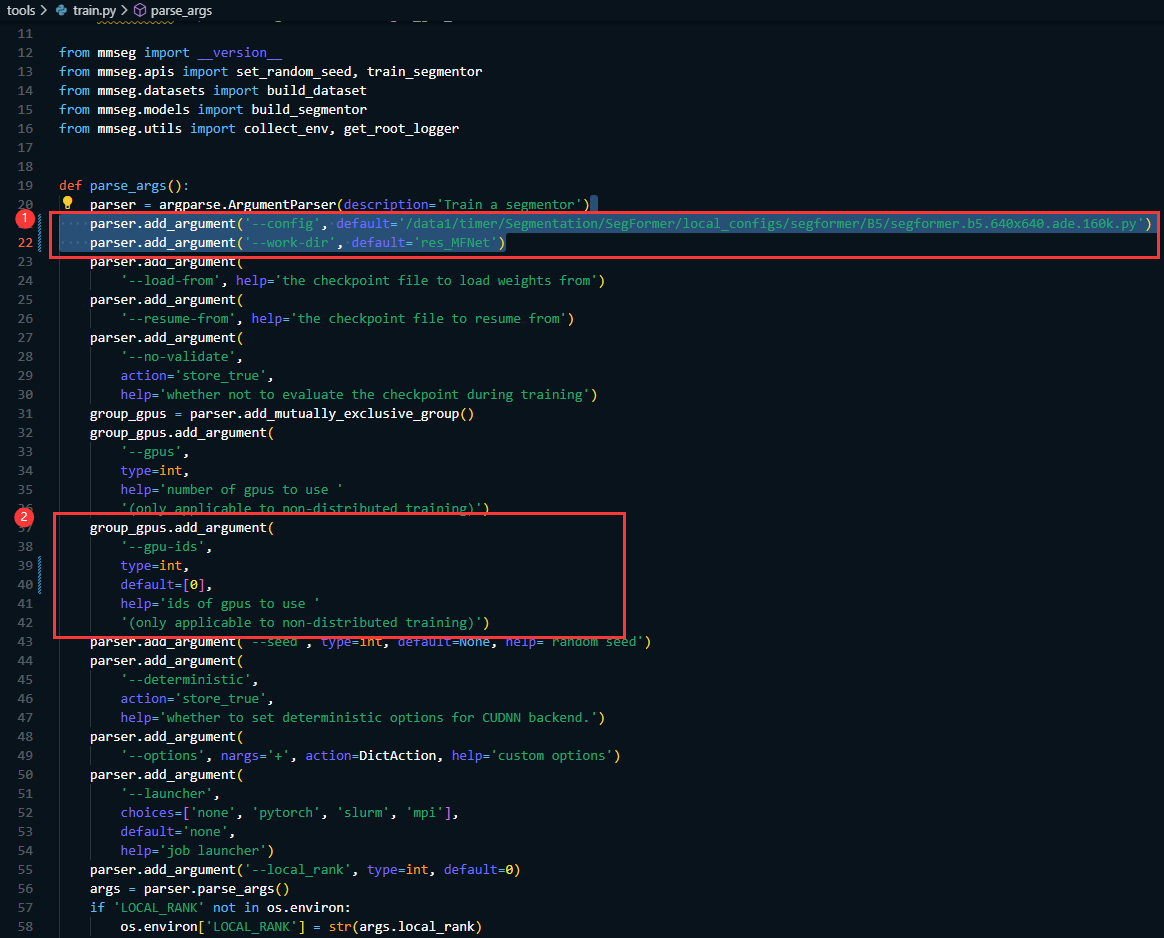
5. 在 tools/train.py中修改
parser.add_argument('--config', default='/data1/timer/Segmentation/SegFormer/local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py')
parser.add_argument('--work-dir', default='res_MFNet')
- 1
- 2
其中 /data1/timer/Segmentation/SegFormer/local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py 是配置文件的路径
res_MFNet是训练日志和模型保存的路径
同时指定GPU的卡号
group_gpus.add_argument(
'--gpu-ids',
type=int,
default=[0],
help='ids of gpus to use '
'(only applicable to non-distributed training)')
- 1
- 2
- 3
- 4
- 5
- 6
 6. 进入tools目录下运行
6. 进入tools目录下运行
python train.py
- 1
即可开始训练模型。
由于本人也在摸索阶段,有不当之处,恳请各位不吝赐教。也欢迎大家交流:2458707789@qq.com

