
热门标签
热门文章
- 1DataLoader详解_dataloader函数
- 2北京/上海内推 | 字节跳动AI Lab招聘NLP算法模型优化方向实习生
- 3【工具】1664- Codeium:强大且免费的AI智能编程助手
- 4.net core使用filter过滤器处理拦截webapi接口_asp.net core 过滤器 拦截所有接口
- 5网络端口及对应服务_常用端口号与对应的服务
- 6Bag of Tricks for Efficient Text Classification (fastText) 学习笔记_fasttext model 镜像网站
- 7Android手机 通过NFC读取二代证信息_安卓 解析 nfc 身份证
- 8ubuntu查看内存cpu占用情况_ubuntu查看cpu占用率
- 9Bugku之Flask_FileUpload
- 10YOLOv8及其改进(三) 本文(5000字) | 解读modules.py划分成子文件 | 标签透明化与文字大小调节 | 框粗细调节 |
当前位置: article > 正文
YOLOv8添加注意力机制后可以从预训练模型开始训练_改进yolov8,在训练时候还用原来的模型吗
作者:笔触狂放9 | 2024-04-02 11:02:54
赞
踩
改进yolov8,在训练时候还用原来的模型吗
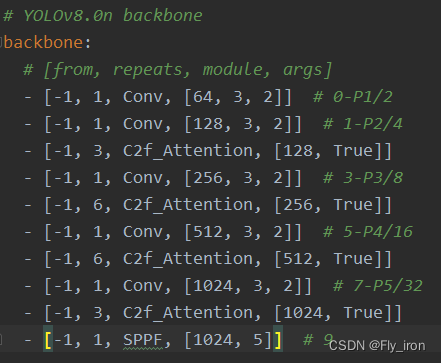
本人在YOLOv8中添加注意力机制发现新的模型,例如将yolov8s.yaml文件更改成为yolov8s-Attention.yaml文件,也就是在C2f里添加了注意力机制。
原文件:

更改后:
训练的py文件就可以写成:
- model = YOLO("yolov8s.pt")
-
- # 使用模型
- model.train(model="yolov8s-Attention.yaml",
- data="VOC2028.yaml",
- epochs=300,
- project='runs/VOC2028/train',
- name='exp-SE',
- resume=False,
- lr0=0.0001,
- lrf=0.001)
但是我们会发现在运行的界面当中并没有添加注意力机制,如图所示:
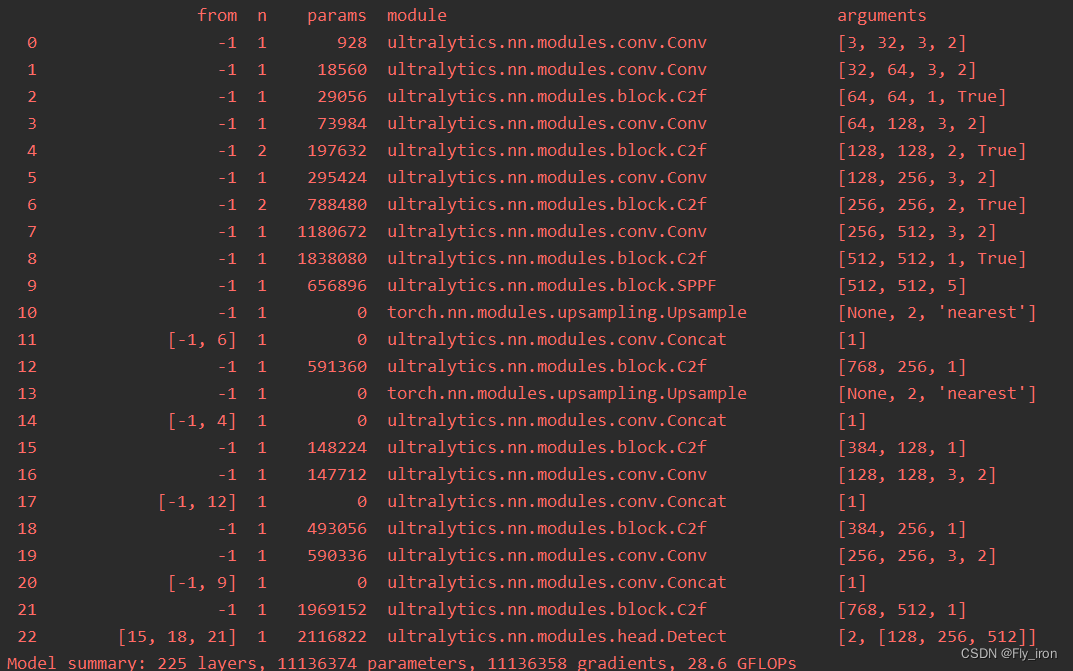 所以我们需要在源文件中更改,打开ultralytics/engine/model.py,找到train方法,找到如下图这一行:
所以我们需要在源文件中更改,打开ultralytics/engine/model.py,找到train方法,找到如下图这一行:
 将这一行画圈的代码改成:
将这一行画圈的代码改成:
self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.trainer.model)然后我们再来测试一下:
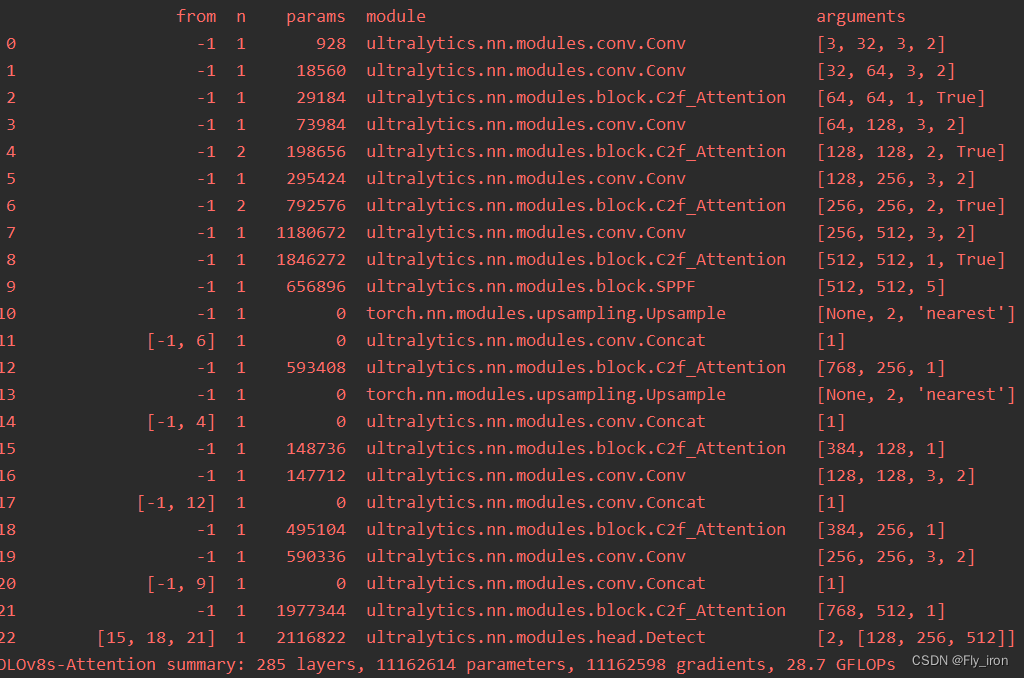 发现注意力机制添加成功!!!
发现注意力机制添加成功!!!
所以我们需要进一步看看是否真的添加成功,就需要看看重新开始训练的第一轮能得到什么样的结果:

这里我们发现第一轮的训练结果为0,说明是从头开始训练。

再看看更改后的代码,发现第一轮的训练结果为0.832,说明预训练加载到模型当中了。
yolov8模型以此完成了添加注意力机制并且完成了预训练的加载,谢谢!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/352015
推荐阅读
相关标签

