- 1Android Studio 之aar_androidstudio aar
- 2Ubuntu | 查看资源使用率(CPU/GPU)| glances介绍_gpu glance
- 3Appium运行时日志解析(内附Demo)_waiting up to 30000ms for uiautomator2 to be onlin
- 4高校课程知识库系统|基于Springboot+vue实现高校课程知识库在线学校平台_使用spring boot技术,使用spring框架和mybatis框架技术实现对高校基本信息、高校
- 5HarmonyOS@Prop装饰器:父子单向同步_harmony 如何实现父子组件间的数据同步
- 6RAM、ROM、FLASH的存储原理及区别
- 7【毕业设计】基于Android系统的校园图书共享APP的设计实现_共享图书app分析与设计软件工程
- 8ubuntu查看内存cpu占用情况_ubuntu查看cpu占用率
- 9appium iOS 真机之坑_encountered internal error running command: error:
- 10uiautomator2设置不重复安装io.appium.uiautomator2.server和io.appium.uiautomator2.server.test
机器学习之随机森林(Random forest)
赞
踩
1 什么是随机森林
随机森林是一种监督式算法,使用由众多决策树组成的一种集成学习方法,输出是对问题最佳答案的共识。随机森林可用于分类或回归,是一种主流的集成学习算法。
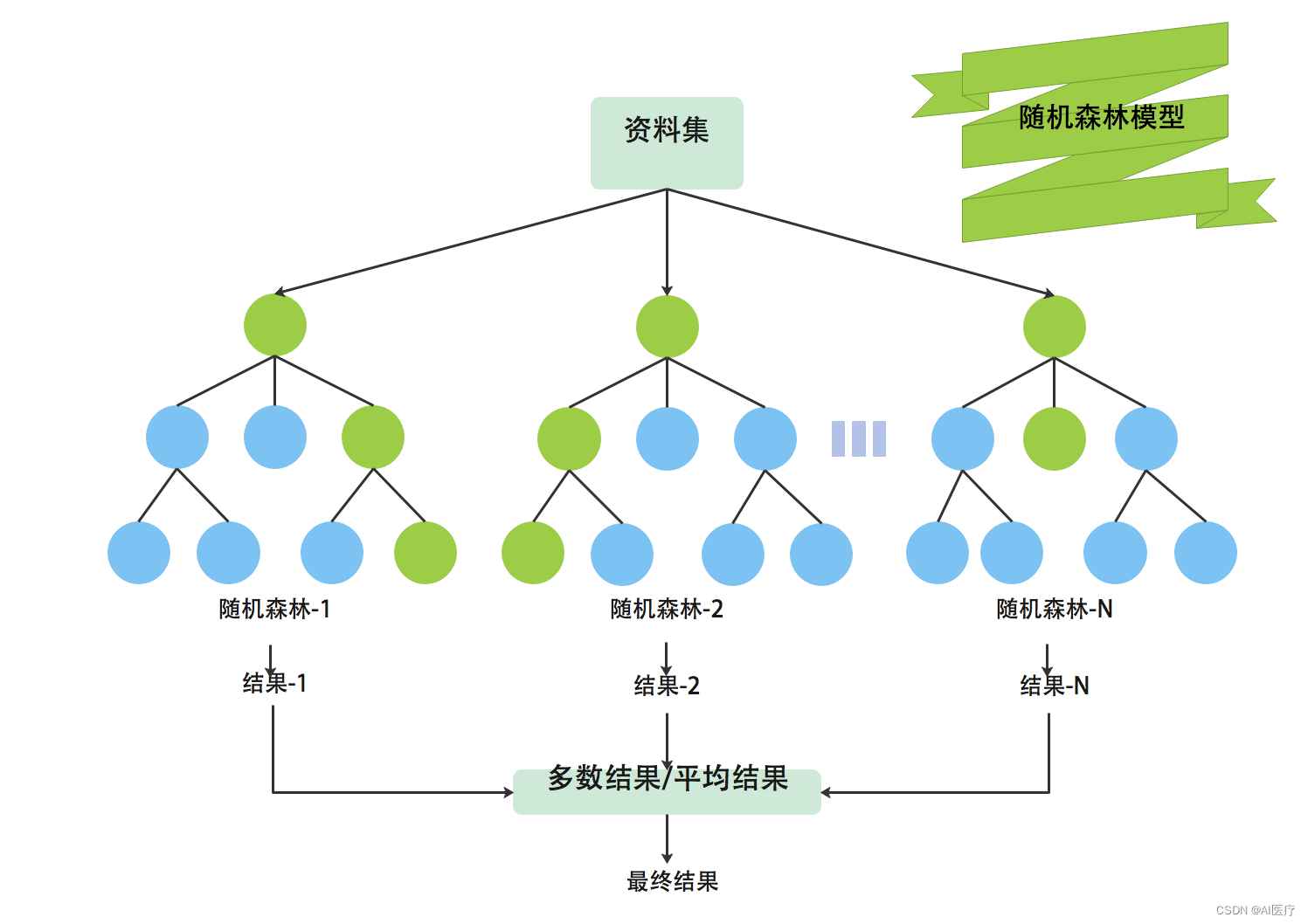
1.1 随机森林算法原理
随机森林中有许多的分类树。我们要将一个输入样本进行分类,我们需要将输入样本输入到每棵树中进行分类。打个形象的比喻:森林中召开会议,讨论某个动物到底是老鼠还是松鼠,每棵树都要独立地发表自己对这个问题的看法,也就是每棵树都要投票。该动物到底是老鼠还是松鼠,要依据投票情况来确定,获得票数最多的类别就是森林的分类结果。
1.1.1 核心思想
将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想(关于bagging的一个有必要提及的问题:bagging的代价是不用单棵决策树来做预测,具体哪个变量起到重要作用变得未知,所以bagging改进了预测准确率但损失了解释性)。
1.1.2 森林中的每棵树怎么生成
每棵树的按照如下规则生成:
(1)如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集;
从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本。
-
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要;
- 为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是"有偏的",都是绝对"片面的"(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是"求同",因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的,这样无异于是"盲人摸象"。
(2)如果每个样本的特征维度为M,指定一个常数m<<M,随机地从M个特征中选取m个特征子集,每次树进行分裂时,从这m个特征中选择最优的;
(3)每棵树都尽最大程度的生长,并且没有剪枝过程。
一开始我们提到的随机森林中的“随机”就是指的这里的两个随机性。两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力(比如:对缺省值不敏感)。
1.1.3 随机森林分类影响因素
随机森林分类效果(错误率)与两个因素有关:
- 森林中任意两棵树的相关性:相关性越大,错误率越大;
- 森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
1.1.4 误分率(oob error)
构建随机森林的关键问题就是如何选择最优的m,要解决这个问题主要依据计算误分率oob error。随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。而这样的采样特点就允许我们进行oob估计,它的计算方式如下:(以样本为单位)
- 对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树);
- 然后以简单多数投票作为该样本的分类结果;
- 最后用误分个数占样本总数的比率作为随机森林的oob误分率。
1.2 集成学习
集成学习算法是一种通过结合多个基本模型来构建一个更强大的模型的机器学习方法。它通过将多个基本模型的预测结果进行综合,从而提高整体预测的准确性和鲁棒性。此类学习方法基于这样一种概念:一群对问题领域知之有限的人集思广益,可以获得比一个知识丰富的人更好的解决方案。
在集成学习中,基本模型也被称为弱学习器或基分类器。这些基本模型可以是不同的算法(如决策树、支持向量机、神经网络等)的组合,也可以是同一算法在不同子样本上训练得到的模型。
Bagging(装袋法)、Boosting(提升法)和Stacking(堆叠法)是三种常见的集成学习方法,它们都通过结合多个基本模型来提高整体模型的性能。
1.2.1 Bagging(装袋法)
Bagging是一种基于自助采样的集成学习方法。它通过有放回地随机抽样生成多个独立的子训练集,然后在每个子训练集上训练一个基本模型。最终的预测结果通过对各个基本模型的预测结果进行投票或平均得到。Bagging的一个典型应用是随机森林(Random Forest)算法,其中每棵决策树都是基于不同的随机样本和随机特征子集构建的。
1.2.2 Boosting(提升法)
Boosting是一种迭代的集成学习方法,它通过顺序训练多个基本模型来逐步提升整体模型的性能。在每次迭代中,Boosting会调整样本的权重,使得之前模型预测错误的样本在后续迭代中得到更多的关注。常见的Boosting算法包括AdaBoost和梯度提升树(Gradient Boosting Tree)。最终的预测结果是通过对所有基本模型的加权组合得到,权重通常与基本模型的性能相关。
1.2.3 Stacking(堆叠法)
Stacking是一种基于模型集成的元学习方法。它通过在训练数据上训练多个不同的基本模型,然后将这些基本模型的预测结果作为输入,再通过另一个模型(称为元模型或组合模型)进行集成学习。元模型可以是简单的线性模型,也可以是更复杂的机器学习算法。Stacking的关键是使用基本模型的预测结果作为新的特征,以提供更多的信息给元模型,从而提高整体模型的性能。
这三种集成学习方法各自具有特点。Bagging通过并行训练独立的基本模型来减少方差,提高模型的稳定性。Boosting通过迭代训练调整样本权重,聚焦于难以分类的样本,提高模型的准确性。Stacking通过组合多个基本模型和一个元模型来利用它们的优势,提供更强的预测能力。
这些方法在实际应用中并不是互斥的,可以结合使用或根据具体问题选择最适合的方法。它们都是为了通过整合多个模型的预测结果来提高整体模型的性能。
2 随机森林算法优缺点
2.1 算法优点
(1)高准确性:随机森林通过组合多个决策树的预测结果,可以得到较高的准确性。由于每个决策树都是基于不同的随机样本和随机特征子集构建的,随机森林可以减少过拟合的风险,提高模型的泛化能力。
(2)可处理大规模数据集:随机森林能够有效处理包含大量样本和特征的数据集,而且在处理高维数据时也具有较好的表现。
(3)无需特征归一化和处理缺失值:随机森林算法对原始数据的处理要求相对较低,可以直接处理不需要进行特征归一化和处理缺失值。
(4)能够评估特征的重要性:随机森林可以通过测量特征在决策树中的贡献度来评估特征的重要性,这有助于特征选择和数据理解。
2.2 算法缺点
(1)训练时间较长:相比于单个决策树,随机森林的训练时间通常较长,特别是当包含大量决策树和复杂特征时。因为每棵树都是独立构建的,需要进行并行计算。
(2)占用更多内存:随机森林由多个决策树组成,需要存储每棵树的信息,因此相对于单个决策树,它需要更多的内存空间。
(3)预测过程较慢:当需要对新样本进行预测时,随机森林需要将样本在每棵树上进行遍历,并将各个决策树的结果进行综合,因此相对于单个决策树,预测过程稍慢。
随机森林是一种强大的机器学习算法,适用于各种预测和分类任务。它的准确性高,能够处理大规模数据集,不需要对数据进行过多的预处理,同时能够评估特征的重要性。然而,由于其训练时间较长,占用较多内存,并且在预测过程中稍慢,因此在某些场景下可能需要权衡其优缺点来选择合适的算法。
3 随机森林应用场景
随机森林算法由于其良好的性能和可解释性,适用于许多不同的应用场景。以下是一些常见的随机森林算法应用场景:
(1)分类问题:随机森林可用于二分类和多分类问题。它可以应用于各种领域,如医疗诊断、金融欺诈检测、文本分类等。
(2)回归问题:随机森林也可以用于解决回归问题。例如,预测房价、销售量、股票价格等连续型变量的问题。
(3)特征选择:由于随机森林可以评估特征的重要性,它可以用于特征选择。通过排名特征的重要性,可以筛选出对目标变量有较大影响的特征,以提高模型的效果和解释能力。
(4)异常检测:随机森林在检测异常和离群点方面也具有一定的应用潜力。通过将异常样本与正常样本进行区分,可以帮助发现异常情况,如网络入侵、信用卡欺诈等。
(5)缺失值处理:随机森林能够处理包含缺失值的数据集。它可以利用其他特征的信息来填补缺失值,并进行准确的预测。
(6)推荐系统:随机森林可以应用于推荐系统中,通过分析用户行为和特征,预测用户对商品或服务的喜好,为用户提供个性化的推荐。
随机森林并非适用于所有问题,对于某些特定的领域和任务,可能存在其他更合适的机器学习算法。因此,在选择算法时,需要综合考虑问题的特点、数据规模、计算资源等因素。
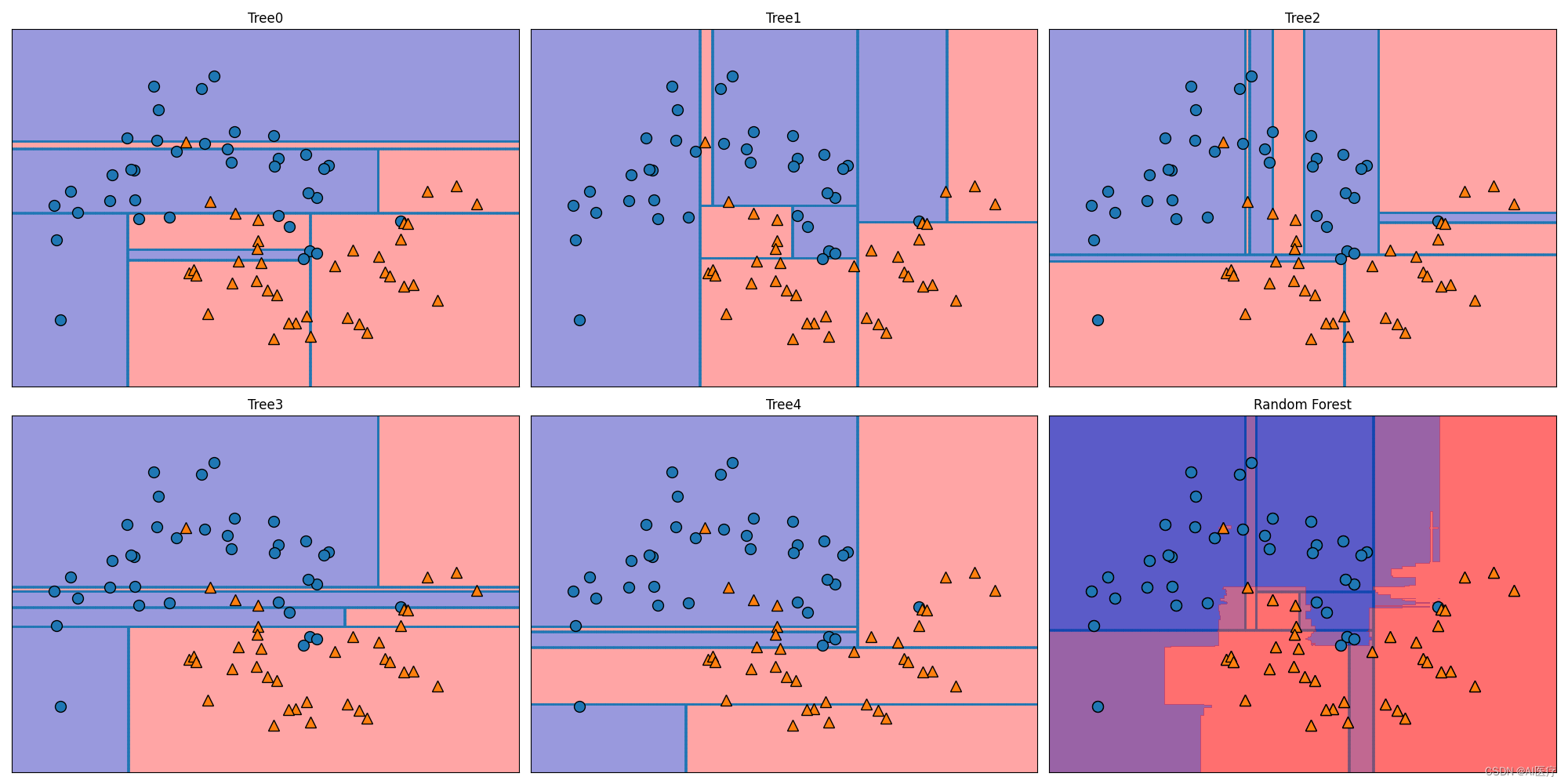
4 基于随机森林算法实现双月数据集的分类
实现代码如下:
- import matplotlib.pyplot as plt
- import mglearn
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.datasets import make_moons
- from sklearn.model_selection import train_test_split
-
-
- # 在two_moon数据集上构造5棵树组成的随机森林
- X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
- X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
- RFC = RandomForestClassifier(n_estimators=100, random_state=2).fit(X_train, y_train)
-
- # 将每棵树及总预测可视化
- fig, axes = plt.subplots(2, 3, figsize=(20, 10))
-
- for i, (ax, tree) in enumerate(zip(axes.ravel(), RFC.estimators_)):
- ax.set_title('Tree{}'.format(i))
- mglearn.plots.plot_tree_partition(X_train, y_train, tree, ax=ax)
-
- mglearn.plots.plot_2d_separator(RFC, X_train, fill=True, ax=axes[-1, -1], alpha=.4)
- axes[-1, -1].set_title('Random Forest')
- mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
- plt.show()

运行效果如下: