
热门标签
热门文章
- 1Hive运行机制与原理_hive 的运行机制
- 2C6031,C4996关于scanf函数报错怎么处理?_c4996怎么解决scanf
- 3Dify学习笔记-基础介绍(一)
- 4digital envelope routines::unsupported_:digital envelope routines::unsupported
- 5【Kafka】Windows下安装Kafka(图文记录详细步骤)_windows 安装kafka
- 6[502]牛巴巴解析VIP电影
- 7【Flutter】Flutter 使用 location 获取定位_flutter 获取当前位置
- 8【Pytorch教程】迅速入门Pytorch深度学习框架_pytorch symint
- 9五款优秀的端口扫描工具_开启服务扫描器
- 10MAC 启动nacos、elasticsearch、sentinel、seata、redis指令合集(持续更新中)_mac启动nacos
当前位置: article > 正文
语音情感分析(MLP)
作者:笔触狂放9 | 2024-04-09 05:18:14
赞
踩
语音情感分析
一、简单介绍
这是一个练手的小项目,内容很简单,可以帮助熟悉一下流程。主要工作是通过对公开数据集RAVDESS进行模型训练,并通过在测试集上的实验验证了我们的模型在语音情感分类中的性能。
二、数据集
Ryerson Audio-Visual Database of Emotional Speech and Song(RAVDESS)数据集是一个情感语音数据集,其中包含了24名专业演员的语音信号和歌曲,每个演员的语音信号都包括了情感标签。该数据集主要使用 Res Vectors (RDE)、aligned ace Database (ADPB)、Fake 2014 ITEYE 数据集中的部分材料,以及通过除理人为增加的部分演员的数据。该数据集包含了若干个不同的情感标签,包括 “happy”、“sad”、“angry”、“calm”、“fearful”、“disgust” 和 “surprised”。该数据集的目的是为了研究情感语音识别、情感语音合成、以及情感语音对话系统等相关问题。
原数据集过大,不太适合做小项目,这里做了一下精简,提供链接:
链接:https://pan.baidu.com/s/1WMD5VTJe52_2FQ6ItfPm0Q?pwd=0806
提取码:0806
三、特征提取
这里主要提取语音的三种特征:
- mfcc:表示声音的短期功率谱
- chroma: 色度,与12个不同的音高类别有关
- mel:mel谱图频率
特征提取代码如下:
import librosa import soundfile import os, glob, pickle import numpy as np from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier from sklearn.metrics import accuracy_score def extract_feature(file_name, mfcc, chroma, mel): with soundfile.SoundFile(file_name) as sound_file: # 读取文件后关闭 X = sound_file.read(dtype="float32") sample_rate=sound_file.samplerate if chroma: stft=np.abs(librosa.stft(X)) result=np.array([]) if mfcc: mfccs=np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0) result=np.hstack((result, mfccs)) if chroma: chroma=np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0) result=np.hstack((result, chroma)) if mel: #mel=np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0) mel=np.mean(librosa.feature.melspectrogram(y=X, sr=sample_rate).T,axis=0) result=np.hstack((result, mel)) return result # 定义一个字典,用数字表示RAVDESS数据集中的情绪 emotions={ '01':'neutral', '02':'calm', '03':'happy', '04':'sad', '05':'angry', '06':'fearful', '07':'disgust', '08':'surprised' } # 观察情绪 observed_emotions=['calm', 'happy', 'fearful', 'disgust'] #加载数据并提取每个声音文件的特征 def load_data(test_size=0.2): x,y=[],[] for file in glob.glob("C:\\数据集\\语音情感识别数据集\\speech-emotion-recognition-ravdess-data\\Actor_*\\*.wav"): file_name=os.path.basename(file) emotion=emotions[file_name.split("-")[2]] if emotion not in observed_emotions: continue feature=extract_feature(file, mfcc=True, chroma=True, mel=True) x.append(feature) y.append(emotion) return train_test_split(np.array(x), y, test_size=test_size, random_state=9)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
四、模型训练
#将数据集分为训练集和测试集(3:1) x_train,x_test,y_train,y_test=load_data(test_size=0.25) # 训练集和测试集的形状 print((x_train.shape[0], x_test.shape[0])) # 提取的特征个数 print(f'Features extracted: {x_train.shape[1]}') # 初始化MLP model=MLPClassifier(alpha=0.01, batch_size=256, epsilon=1e-08, hidden_layer_sizes=(300,), learning_rate='adaptive', max_iter=500) # 模型训练 model.fit(x_train,y_train) # 模型保存 model.save("C:\\数据集\\语音情感识别数据集\\model.h5") # 测试集验证 y_pred=model.predict(x_test) # 计算模型精度 accuracy=accuracy_score(y_true=y_test, y_pred=y_pred) print("Accuracy: {:.2f}%".format(accuracy*100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
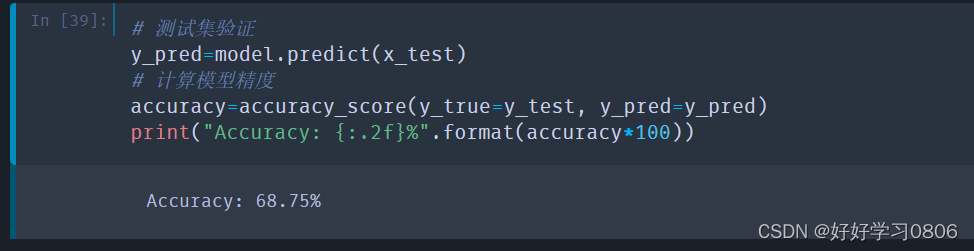
结果如下:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/390562
推荐阅读
相关标签

