
- 1华为OD机试 - 分糖果(C语言)
- 2Hadoop配置文件详解(core-site.xml、hdfs-site.xm、mapred-site.xml、yarn-site.xml)_hdfs-site.xml和core-site.xml
- 3PWM输入信号转换模拟量电压电流隔离变送器1Hz~10KHz转0-10V/1-5V/4-20mA_高分辨率pwm转电压
- 4字节23届校招薪资出炉!技术岗年薪最高76万
- 5Kafka——多线程Consumer实例_spring kafka consumer 多实例
- 6大模型系列——解读RAG_大语言模型rag
- 7AutoGPT 使用教程及上手体验(一分钟配置可用)_autogpt使用
- 8打不动的蓝桥杯
- 9软考证书可以评职称吗?怎么评?_软考中级可以评高级职称吗
- 1010个顶级商业思维:如何升级思维模式突破认知,让自己快速成长_认知 商业 思维
python爬虫论坛代码_Python爬虫: 500px摄影师社区抓取摄影师数据
赞
踩
今天要抓取的网站为 https://500px.me/ ,这是一个摄影社区,在一个摄影社区里面本来应该爬取的是图片信息,可是我发现好像也没啥有意思的,忽然觉得爬取一下这个网站的摄影师更好玩一些,所以就有了这篇文章的由来。
基于上面的目的,我找了了一个不错的页面 https://500px.me/community/search/user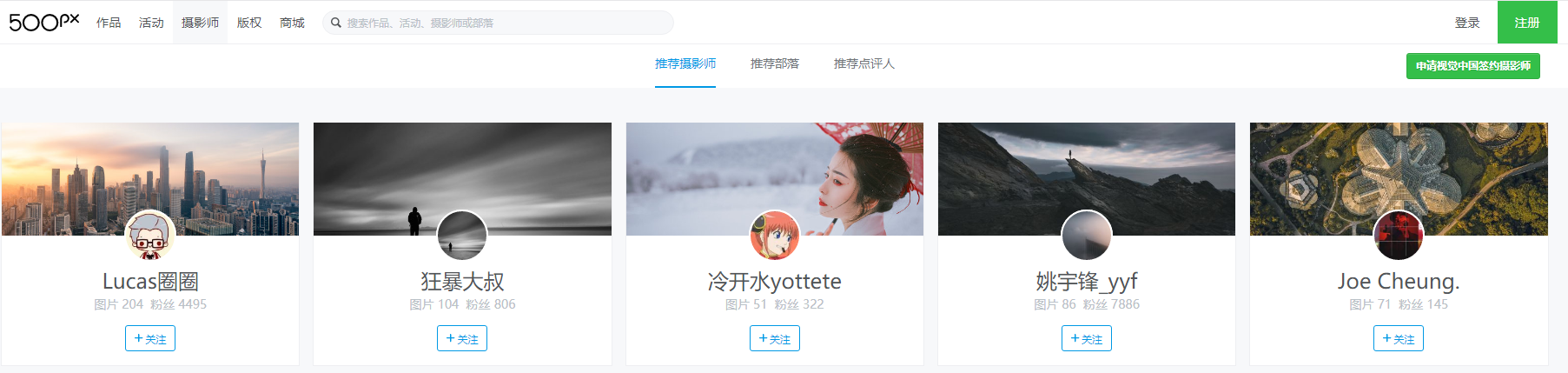
不过细细分析之后,发现这个页面并不能抓取到尽可能多的用户,因为下拉一段时间,就不能继续了,十分糟心,难道我止步于此了么,显然不可能的,一番的努力之后(大概废了1分钟吧),我找到了突破口,任意打开一个用户的个人中心页,就是点击上述链接的任意用户头像,出现如下操作。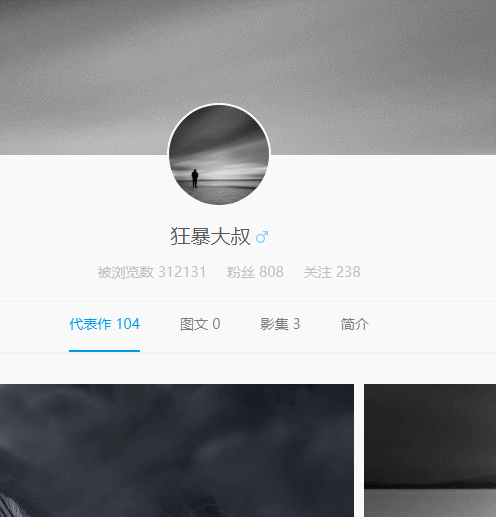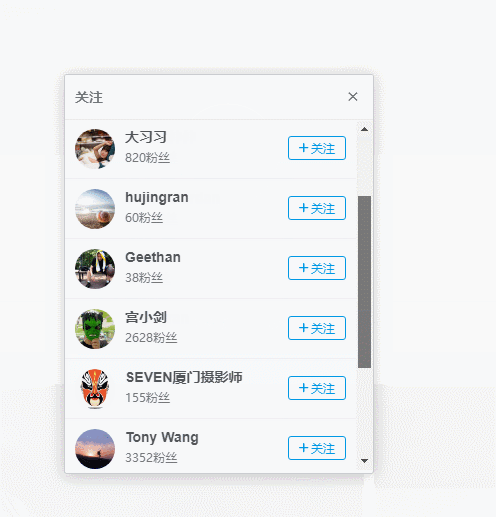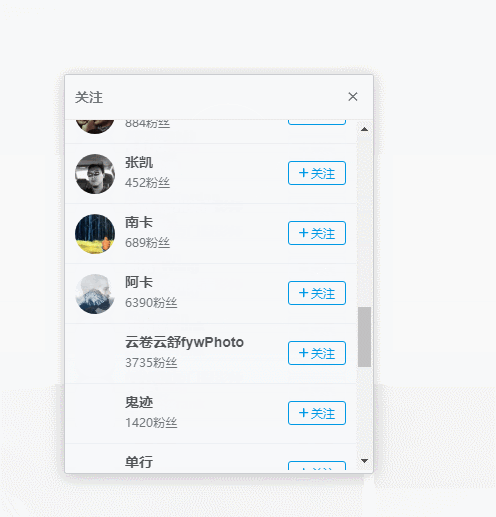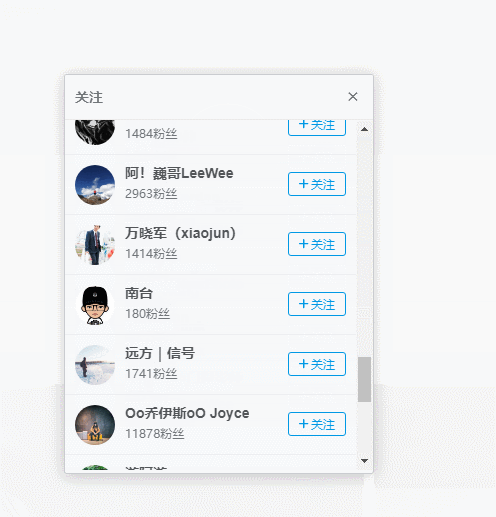
用户个人中心页面,竟然有关注列表唉~~,nice啊,这个好趴啊,F12分析一下。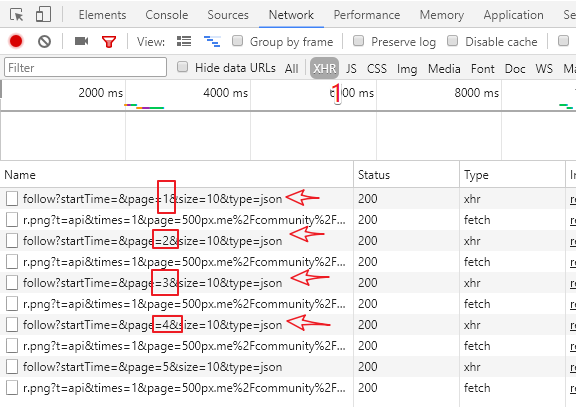
哒哒哒,数据得到了。
URL是 https://500px.me/community/res/relation/4f7fe110d4e0b8a1fae0632b2358c8898/follow?startTime=&page=1&size=10&type=json
参数分别如下,实际测试发现size可以设置为100
https://500px.me/community/res/relation/{用户ID}/follow?startTime=&page={页码}&size={每页数据}&type=json
那么我们只需要这么做就可以了获取关注总数
关注总数除以100,循环得到所有的关注者(这个地方为什么用关注,不用粉丝,是因为被关注的人更加有价值)
明确我们的目标之后,就可以开始写代码了。
撸代码
基本操作,获取网络请求,之后解析页面,取得关注总数。
用户的起始,我选择的id是5769e51a04209a9b9b6a8c1e656ff9566,你可以随机选择一个,只要他有关注名单,就可以。
导入模块,这篇博客,用到了redis和mongo,所以相关的基础知识,我建议你提前准备一下,否则看起来吃力。
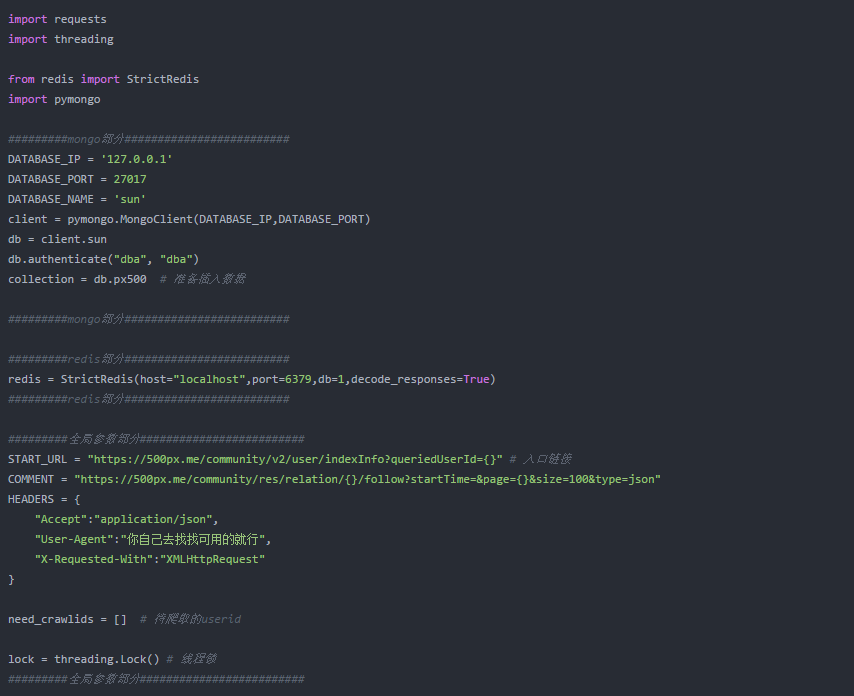
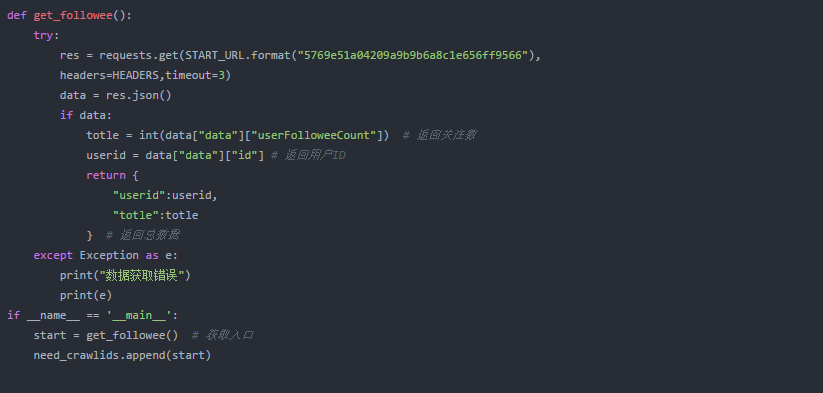
上面代码中有一个非常重要的逻辑,就是为什么要先匹配种子地址的【关注数】和【用户ID】,这两个值是为了拼接下面的URL
https://500px.me/community/res/relation/{}/follow?startTime=&page={}&size=100&type=json
经过分析,你已经知道,这个地方第一个参数是用户id,第二个参数是页码page,page需要通过关注总数除以100得到。不会算的,好好在纸上写写吧~
我们可以通过一个方法,获取到了种子用户的关注列表,以此继续爬取下去,完善生产者代码。关键代码都进行了注释标注。
思路如下:死循环不断获取need_crawlids 变量中的用户,然后获取该用户的关注者列表。
爬取到的信息,写入redis方便验证重复,快速存储。
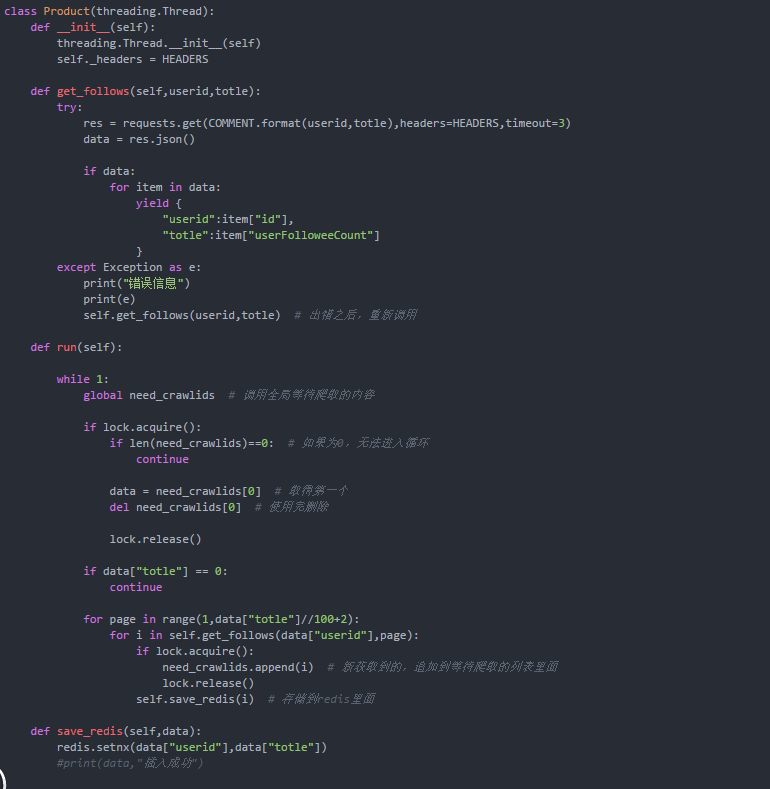
由于500px无反爬虫,所以运行起来速度也是飞快了,一会就爬取了大量的数据,目测大概40000多人,由于咱是写教程的,我停止了爬取。

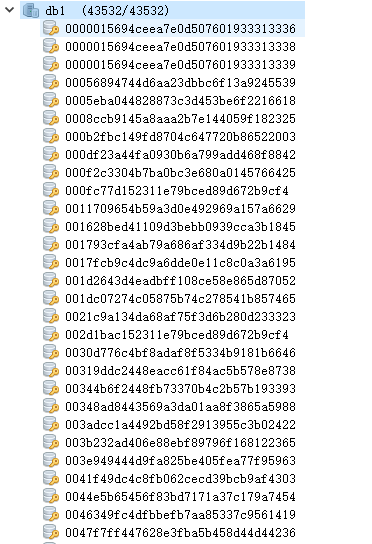
这些数据不能就在redis里面趴着,我们要用它获取用户的所有信息,那么先找到用户信息接口,其实在上面已经使用了一次
https://500px.me/community/v2/user/indexInfo?queriedUserId={} 后面的queriedUserId对应的是用户id,只需要从刚才的数据里面获取redis的key就可以了,开始编写消费者代码吧,我开启了5个线程抓取。
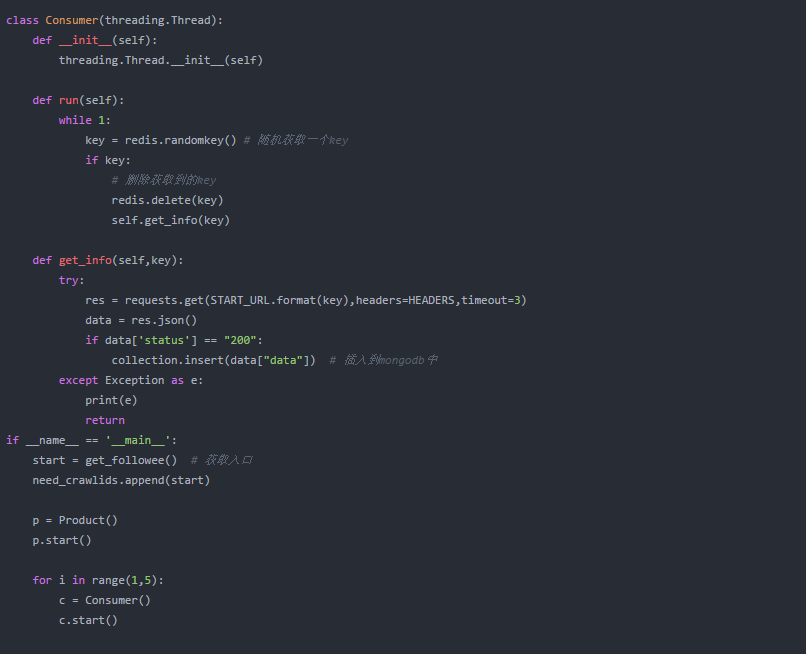
代码没有特别需要注意的,可以说非常简单了,关于redis使用也不多。

(⊙o⊙)…经过几分钟的等待之后,大量的用户信息就来到了我的本地。


