
要点:
- Scrapy-Redis不是框架,也不是一套可以单独运行的东西
- Scrapy-Redis是一套基于Scrapy框架的组件,它提供了一堆可以支持分布式的组件,用来替换Scrapy原本的一些东西,然后让Scrapy具有分布式的功能。
- 安装scrapy-redis=======>直接:pip install scrapy-redis
一、Scrapy-Redis构架
1、Scrapy和Scrapy-Redis的区别
- Scrapy是一个通用的爬虫框架,但是不支持分布式
- Scrapy-Redis是为了更方便的实现Scrapy分布式爬虫,而不是提供一些以redis为基础的组件(仅有组件)
- pip install scrapy-redis
- Scrapy-Redis提供了四种组件:Scheduler;Duplication Filter;Item Pipeline;Base Spider
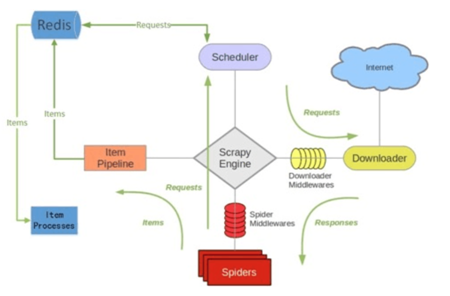
2、Scrapy和Scrapy-Redis构架图
 =构架=>
=构架=>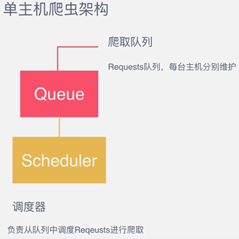
 =构架=>
=构架=>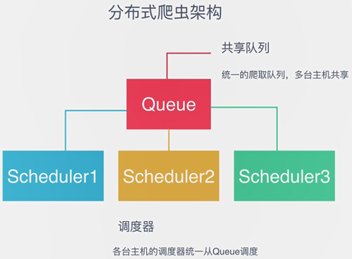
如上图所示,Scrapy-Redis在scrapy的构架上增加了Redis,基于Redis的特性扩展了如下组件:scheduler;Duplication Filter;Item Pipeline;Base Spider。
(1)Scheduler
Scrapy改造了python本来的collection.deque(双向队列)形成自己的Scrapy queue,但是Scrapy多个spider不能共享爬虫队列Scrapy queue,即Scrapy本身并不支持爬虫分布式。
Scrapy-Redis的解决是:把这个scrapy queue换成redis数据库(也指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
(2)Item Pipeline
引擎(Engine)将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的Item存入redis的items pipeline。
修改过的Item Pipeline可以很方便的根据key从items queue提取item,从而实现items process集群。
(3)Duplication Filter
scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放到一个集合中,把下一个request的指纹拿到集合中对比,如果该指纹存在于集合中,就说明这个request发送过了,如果没有则继续操作。
scrapy-redis中的核心判重功能根据如下实现:
def request_seen(self,request): #核心判重功能
fp=self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp+os.linesep)
在Scrapy-Redis中去重是由Duplication Filter组件来实现,它通过redis的set不重复的特性
Scrapy-Redis调度器从引擎Engine接收request,将request的指纹存入redis的set检查是否重复,并将不重复的request push 写入到redis的request queue。
(4)Base Spider (爬虫的基类)
Scrapy-Redis不使用scrapy原有的spider类,重写的Redis Spider继承了Spider和RedisMixin这两个类,RedisMixin用来从redis读取url的类。
当生存一个Spider继承RedisSpider时,调用setup-redis函数,这个函数会去链接redis数据库,然后设置signals(信号):
- 一个是当spider空闲时的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一个活着的状态,并且抛出DontCloseSpider异常
- 一个是当抓住item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request
注:Scrapy中有两大基类:Spider和CrawlSpider
==>相应的Redis-Scrapy中的两个基类为:Redis-Spider和Redis-CrawlSpider
二、Scrapy-Redis分布式策略
1、分布式策略
假设有4台电脑:Windows10、Max OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为Master端或Slaver端,如(1)和(2):
(1)Master端(核心服务器):使用Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据存储
(2)Slaver端(爬虫程序执行端):使用Max OS X、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
只能有一个Master端 可以有多个Slaver端
流程: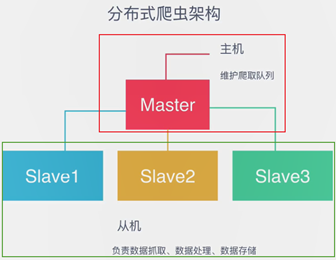
步骤:
- (1)首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
- (2)Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
总结:Scrapy-Redis默认使用的就是这种策略,实现起来很简单,因为任务调度等工作Scrapy-Redis都已经做好了,则只需要继承RedisSpider、指定redis_key就行了。
缺点:Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
2、Scrapy-Redis前期准备
(1)安装Redis
将Redis-x64-3.0.504.zip安装包中的文件解压到D:\redis\文件夹下,并将“D:\redis\”添加到系统变量中。
在cmd中输入:C:\Users\Administrator>redis-server
(若该cmd窗口左侧出现一个类似于“正方体(3面)”,则安装成功!)
(2)修改配置文件redis.windows.conf
![]() 为了支持分布式,注释掉该句子【PS:默认这一句就是注释掉的……】
为了支持分布式,注释掉该句子【PS:默认这一句就是注释掉的……】
bind 127.0.0.1表示数据库只支持本地去读取,将其注释掉表示不再绑定本地,则任何的IP都可以访问我的redis数据库,这样salve端才能远程连接到Master 端的Redis数据库。
【注:以下的操作均为:我的电脑为master端,师弟的电脑为salver端】
(3)测试slave端远程连接到master端
(3-1)在master端(我的电脑)的数据库中设置一个key1为“hello”,如下:

若salve端的机器也想从master端的数据库的数据库拿取数据,需要先将绑定到同一个局域网!!!!!
(3-2)找到master端(我的电脑)的IP地址:
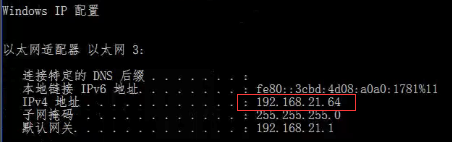 ;
;
(3-3)Salver端(师弟的电脑)在redis数据库中想拿到master端(我的电脑)中的数据,只需要输入:
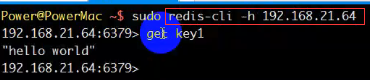 【sudo是mac下编译器自带的,windows则没有,所以不需要考虑】
【sudo是mac下编译器自带的,windows则没有,所以不需要考虑】
注:在salve端通过ip拿去master端的数据时,master端的redis数据库必须要工作,即redis-server即可,如图:

(3-4)Redis数据库桌面管理工具: Redis Desktop Manager
1)在redis数据库中的操作:
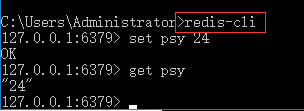
2)在redis desktop Manager中的操作:
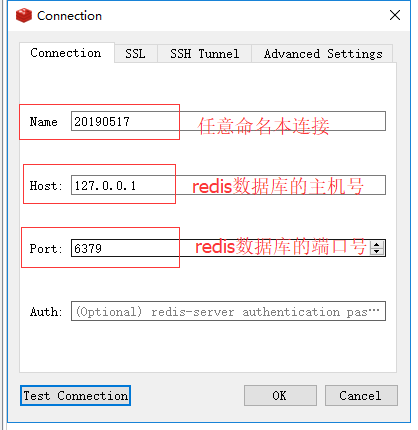
则可查看到:
三、Scrapy-Redis问题汇总
1、队列用什么维护?
通常采用“Redis队列”,因为:
- Redis为非关系型数据库,Key-Value形式存储,结构灵活
- Redis是内存中的数据结构存储系统,处理速度非常快,性能好
- Redis提供队列、集合等多种存储结构,方便队列维护
2、怎样去重?【因为多台slave端的主机进行爬取数据,存储到master端的redis数据库中,怎么去重呢?】
通常采用“Redis队列”,因为:Redis提供集合数据结构,在Redis集合中存储每个Request的指纹。
在向Request队列中加入Request前首先先验证这个Request指纹是否已经加入集合中。
- 如果已存在,则不添加Request到队列;
- 如果不存在,则将Request添加入队列并将指纹加入集合。
3、怎样防止中断? 【因为多台slave端的主机进行爬取数据,可能会突然死机,连不上网等…,怎样防止中断?】
通常采用“启动判断”,因为:在每台从机Scrapy启动时都会先判断当前Redis Request队列是否为空。
- 如果不为空,则从队列中取得下一个Request执行爬虫;
- 如果为空,则重新开始爬取,第一台从机执行爬取向队列中添加Request。
4:怎样实现该架构? 【该架构需要:维护Request队列、多台slave从机调用master端的Request队列、去重的机制】
采用“Scrapy-Redis库”,它为我们实现了:爬取的Request队列、多台调度器、去重、连接Redis的基本接口等等,改写scrapy的调度器、队列等组件。

