
ELK+Kafka+Beats实现海量日志收集平台(一)_packetbeat收集入方向流量
赞
踩
ELK+Kafka+Beats实现海量日志收集平台(一)
目录
一、应用场景
利用ELK+Kafka+Beats来实现一个统一日志平台,它是一款针对大规模分布式系统日志的统一采集、存储、分析的APM 工具。在分布式系统中,有大量的服务部署在不通的服务器上,客服端的一个请求查询,就可能会调用后端多个服务,每个服务之间可能会相互调用或一个服务又会调用其它服务,最终才将请求的结果返回,汇总展现到前端页面上。假若这其中的某个环节发生异常,开发运维人员很难准确定位这个问题到底是由哪个服务调用造成的, 统一日志平台的作用就是追踪每个请求的完整调用链路,收集调用链路上每个服务的性能、日志数据,方便开发运维人员能够快速发现问题,定位问题。
统一日志平台通过采集模块、传输模块、存储模块、分析模块实现日志数据的统一采集、存储和分析,结构图如下:
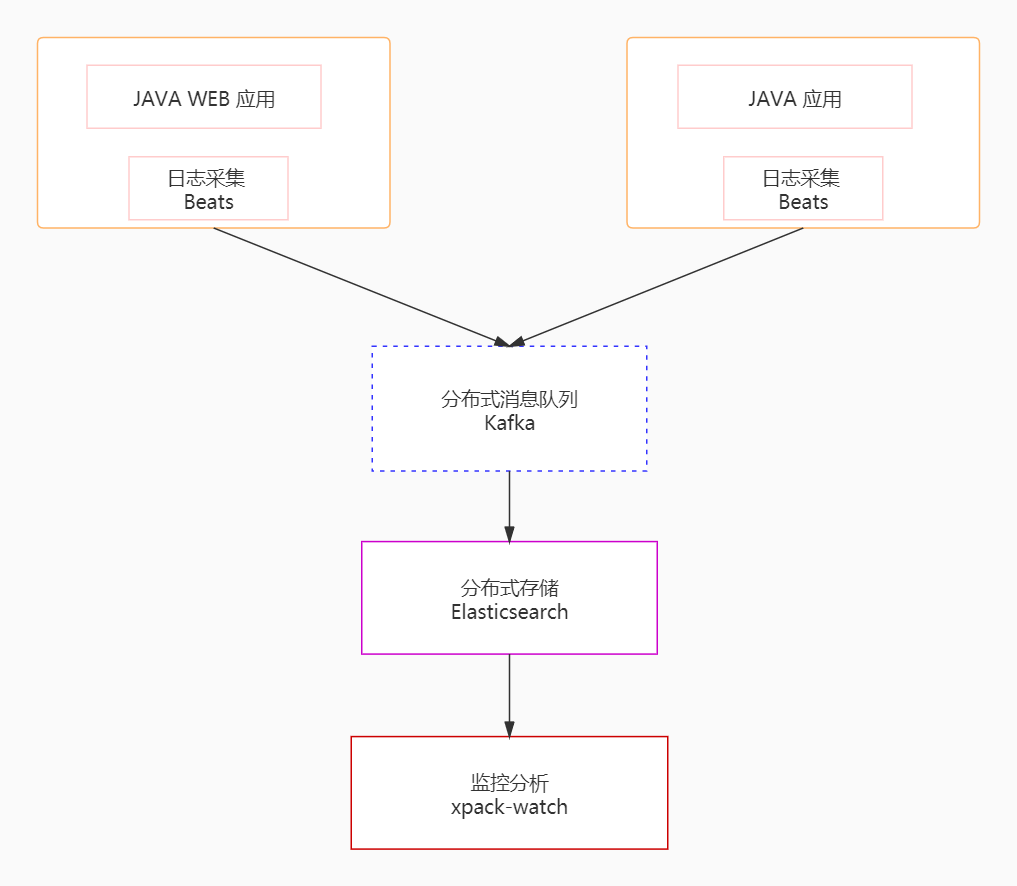
二、实现原理
“ ELK”是三个开源项目的缩写:Elasticsearch,Logstash和Kibana。也称ELK Stack,能够可靠,安全地从任何来源以任何格式获取数据,然后进行实时搜索,分析和可视化。Elasticsearch是搜索和分析引擎,开源的,分布式,RESTful,基于JSON的搜索引擎。它易于使用,可扩展且灵活。Logstash是服务器端的数据处理管道,它同时从多个源中提取数据,进行转换,然后将其发送到类似Elasticsearch的“存储”中。Kibana允许用户在Elasticsearch中使用图表将数据可视化。
Beats 是一个免费且开放的平台,集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。Beats可以将数据直接发送到Elasticsearch或通过 Logstash 发送,然后在Logstash中可以进一步处理和过滤数据,然后再在Kibana中进行可视化 。
Beats架构图如下:

要实现海量日志数据收集分析,首先要解决的问题就是如何处理海量的数据信息,本案例中利用Kafka结合Beats、Logstash来实现分布式消息队列平台,其中采用Beats来采集日志数据,也就相当于是Kafka消息队列中的Producer来生产消息,然后将消息发送到Kafka(相当于消息队列的Broker),然后将日志数据发送到Logstash(扮演消费者-Consumer)进行分析过滤等处理。再把从Logstash中处理之后的数据存储到Elasticsearch中,最终通过Kibana来可视化日志数据。
该过程架构图如下:
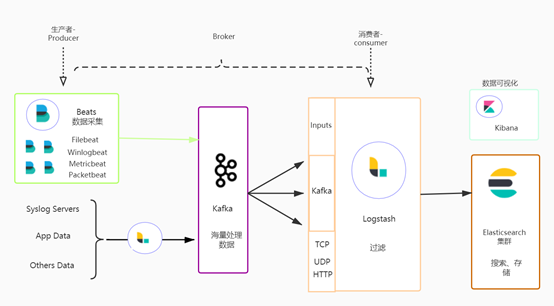
其中Beats主要有以下几种:
Filebeat : 用于收集日志文件
Winlogbeat : 用于收集Windows事件日志
Metricbeat : 用于指标
Packetbeat : 用于收集网络流量数据
由于我们要采集日志来进行分析管理,所以我们使用Beats中的filebeat来进行日志采集
通过上面的架构思路,大致清楚了日志收集分析显示到底要干什么事儿?接下来再通过下图进一步将
该流程具体梳理下
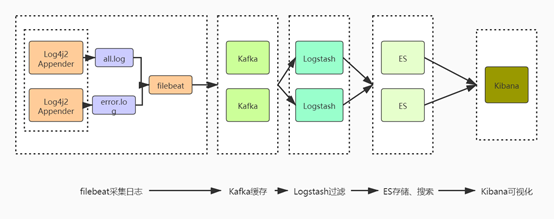
本案例通过编写一个简单的SpringBoot工程来生产日志数据,也就是图中的Log4j2 Appender来作为filebeats的数据源(filebeats要从哪儿获取日志文件),使用Log4j2来进行日志记录而不是Spring自带的Slf4j记录是因为Log4j2的性能要优于Slf4j。图中把生成的日志分为了all.log、error.log 两类日志,all.log用于记录应用服务产生的所有日志记录,error.log主要用于记录warn、error两类的错误日志。error.log日志只有当应用服务报错的时候才进行记录,这样以便日后进行分析告警。
ELK官方参考文档
ElasticSearch官网文档 Elasticsearch:官方分布式搜索和分析引擎 | Elastic
Logstash官网文档 Logstash:收集、解析和转换日志 | Elastic
Kibana 官网文档 Kibana:数据的探索、可视化和分析 | Elastic
Beats 官网文档 Beats:Elasticsearch 的数据采集器 | Elastic

