
- 1macOS Monterey 12.7 (21G816) Boot ISO 原版可引导镜像
- 2干货|二十五个软件测试经典面试题,这些你都能答出来吗?
- 3ESXi 安装 OpenWRT_esxi openwrt
- 4Python封装、继承和多态_python 中是否类没有显式扩展超类,则在默认情
- 5MySQL基础练习题及答案(表的介绍、建表以及插入数据)-01_设有学生表 students(id, name),字段分别为学号、姓名; 成绩表 grades(s_
- 6用于彩票3D的一个组合算法
- 7辅助驾驶事故频发,系统感知“缺陷”怎么破?_辅助驾驶遇到的问题和瓶颈
- 8OpenAI发布了具备语言理解能力的AI视频模型Sora /腾讯发布2024年大模型安全与伦理研究报告 |魔法半周报
- 9亚信安全防毒墙网络版客户端无密码退出、卸载_亚信防火墙网络版退出密码
- 10Charles抓包App教程_charles抓取手机端的包
本地/笔记本/纯 cpu 部署、使用类 gpt 大模型_gguf模型下载
赞
踩
使用 web UI + 大模型文件,即可在笔记本上部署、使用类 gpt 大模型。
1. 安装 web UI
1.1. 下载代码库
https://github.com/oobabooga/text-generation-webui
1.2. 创建 conda 环境
conda create -n textgen python=3.11
conda activate textgen
- 1
- 2
1.3. 安装 pytorch
文档:https://github.com/oobabooga/text-generation-webui#2-install-pytorch
| System | GPU | Command |
|---|---|---|
| Linux/WSL | NVIDIA | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
| Linux/WSL | CPU only | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu |
| Linux | AMD | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6 |
| MacOS + MPS | Any | pip3 install torch torchvision torchaudio |
| Windows | NVIDIA | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
| Windows | CPU only | pip3 install torch torchvision torchaudio |
如果是 nvidia 显卡,需执行以下命令:
conda install -y -c "nvidia/label/cuda-12.1.0" cuda-runtime
- 1
1.4. 安装 pip 库
文档:https://github.com/oobabooga/text-generation-webui#3-install-the-web-ui
pip install -r <requirements file according to table below>
- 1
| GPU | CPU | requirements file to use |
|---|---|---|
| NVIDIA | has AVX2 | requirements.txt |
| NVIDIA | no AVX2 | requirements_noavx2.txt |
| AMD | has AVX2 | requirements_amd.txt |
| AMD | no AVX2 | requirements_amd_noavx2.txt |
| CPU only | has AVX2 | requirements_cpu_only.txt |
| CPU only | no AVX2 | requirements_cpu_only_noavx2.txt |
| Apple | Intel | requirements_apple_intel.txt |
| Apple | Apple Silicon | requirements_apple_silicon.txt |
如果是 linux ,需按照以下步骤才可以使用 cuda 加速的 llama 后端:
# 注释 requirements.txt 中安装 llama_cpp_python_cuda 的行
pip install -r requirements.txt
export LLAMA_CUBLAS=1
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
- 1
- 2
- 3
- 4
2. 下载大模型
2.1. 搜索大模型
Models - Hugging Face:https://huggingface.co/models
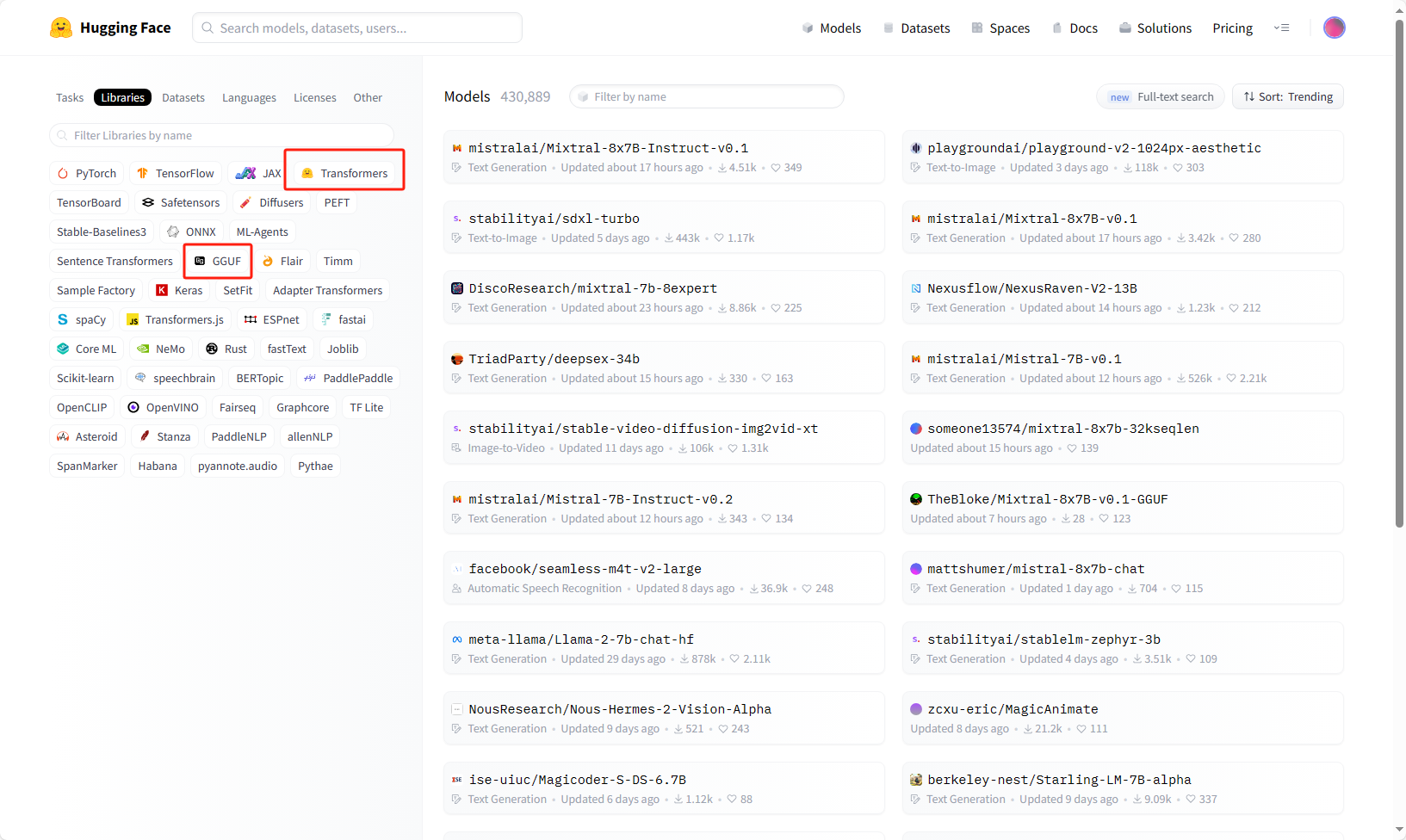
Hugging Face 是深度学习里最活跃的开源社区之一,提供了许多开源模型量化版本的下载。
量化:将模型权重中的 float 替换为 int 等数据类型,损失一小部分精度,但大量减少模型文件大小、内存占用、计算开销。
在页面搜索需要的模型,建议勾选 Libraries 选项中的 transformers 或 GGUF 后搜索,例如搜索模型名 Llama-2-7B-GGUF。
- 其中
7B代表模型的参数量 7 billion(常见参数量有 7b , 13b , 70b),参数量越大,模型精度越高,即对话质量越高。 transformers是一种大模型的格式,勾选后也会包含GPTQ量化格式的模型。GPTQ是一种量化大模型的格式,示例模型名为Llama-2-7B-GPTQGGUF是另一种量化大模型的格式,示例模型名为Llama-2-7B-GGUFGPTQ和GGUF是最常用、好用的量化模型格式
2.2. 下载模型文件
2.2.1. 下载 GGUF 模型文件
在具体模型页面的 Provided files 部分(以 https://huggingface.co/TheBloke/Llama-2-7B-GGUF#provided-files 为例)可以看到该模型的不同量化版本、文件大小、预计内存占用、推荐与否。点击具体量化版本的模型即可下载。
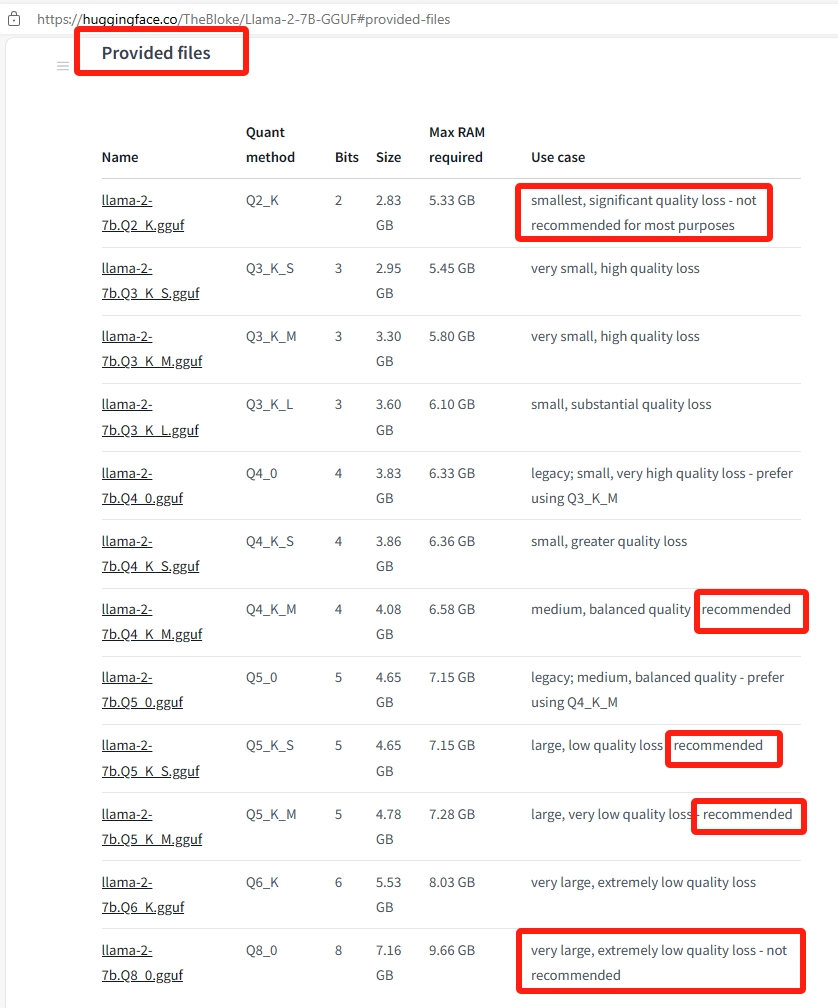
最后将下载的模型文件保存在本地 text-generation-webui 的 models 文件夹里即可。
2.2.2. 下载 GPTQ 模型文件
在具体模型页面的 Files and versions 页面(以 https://huggingface.co/TheBloke/Llama-2-13B-GPTQ/tree/main 为例),点击 clone repository 即可看到下载命令如下:
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/TheBloke/Llama-2-13B-GPTQ
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
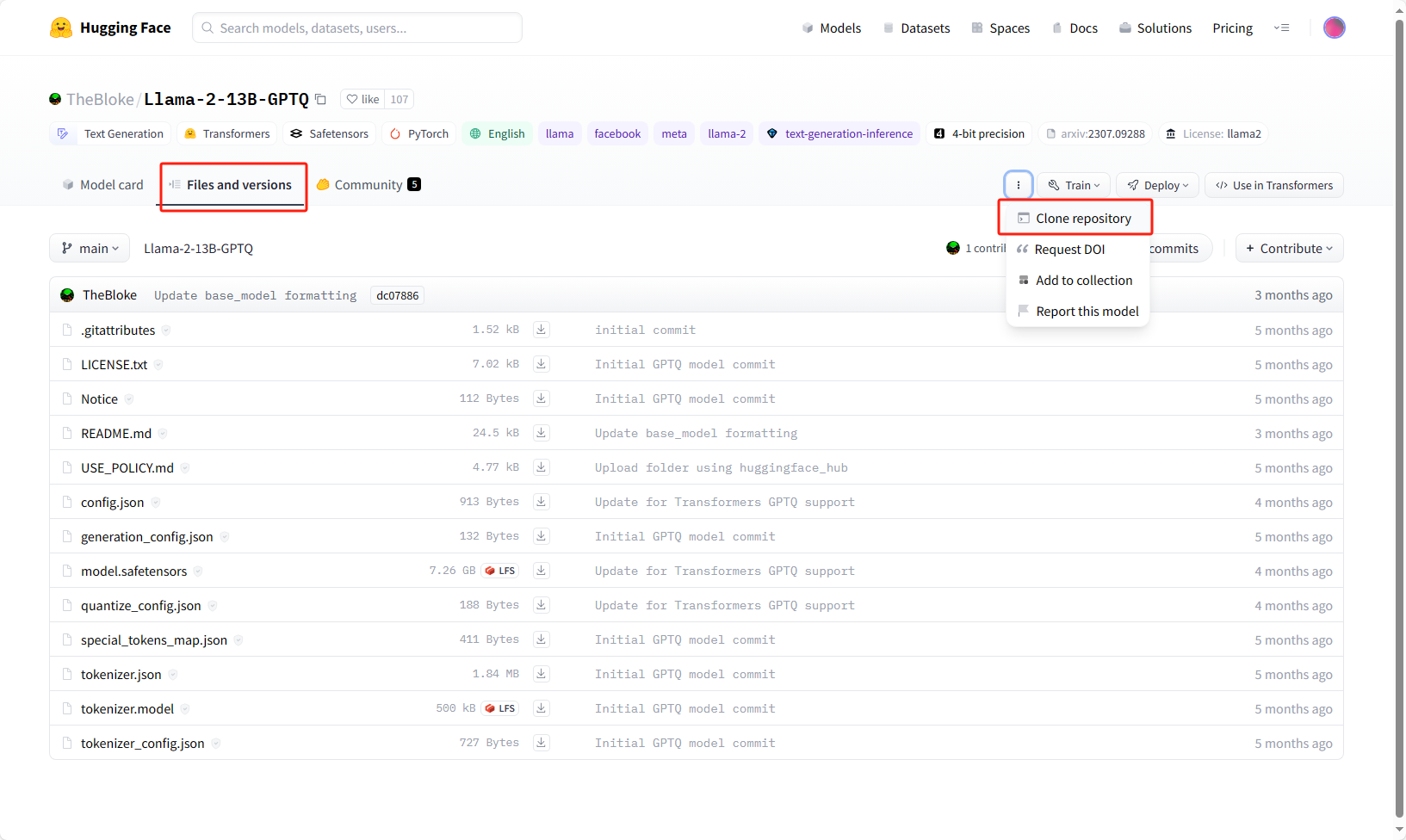
LFS:git clone 命令很可能无法成功下载模型库中的 LF(large file),可以在 clone 了其他文件后,单独下载标有LFS的文件。
最后同样将下载的模型库保存在本地 text-generation-webui 的 models 文件夹里即可。
补充参考文章——git lfs使用(huggingface下载大模型文件):
https://blog.csdn.net/flyingluohaipeng/article/details/130788293
2.3 额外推荐
Hugging Face 用户 TheBloke: https://huggingface.co/TheBloke
TheBloke 是 hugging face 社区的一个用户, ta 提供了许多预量化大模型的下载。
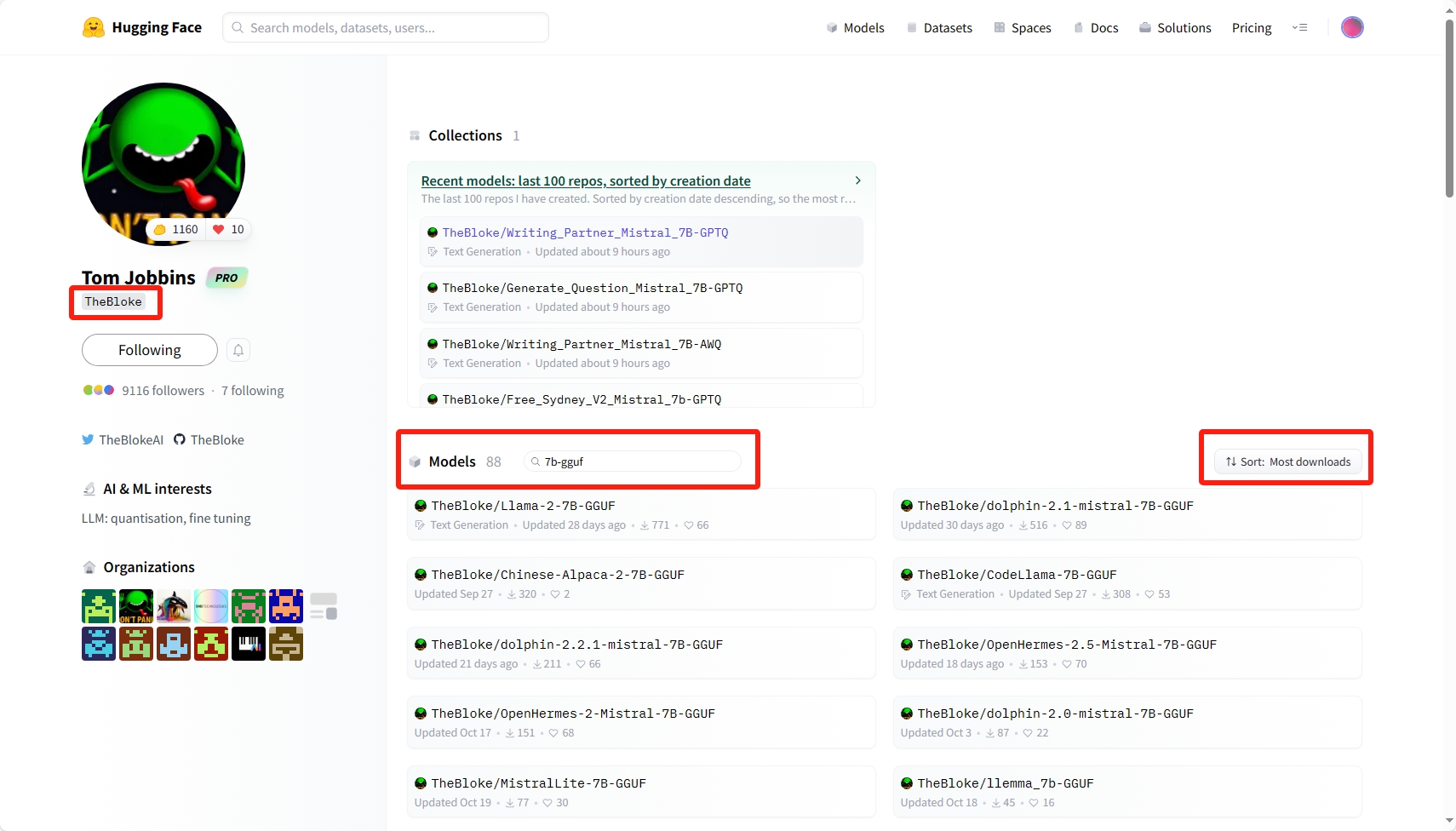
3. 使用 web UI
3.1. 运行 UI 界面
打开 conda 命令行窗口,运行以下命令,并保持窗口开启:
conda activate textgen
cd text-generation-webui
python server.py --trust-remote-code --listen
- 1
- 2
- 3
--trust-remote-code:部分 GPTQ 模型的加载需要启用该选项--listen:监听局域网访问,即使得其他设备可以通过 ip 访问网页 ui,未开启时只能本机通过127.0.0.1:7860访问
3.2. 加载 GPTQ 模型

打开 127.0.0.1:7860 网页链接,model 页面,按上图进行模型加载即可(大概需要几十秒),随后即可进行对话。
GPTQ 模型加载具体文档:https://github.com/oobabooga/text-generation-webui/wiki/04-‐-Model-Tab#transformers
3.3. 加载 GGUF 模型
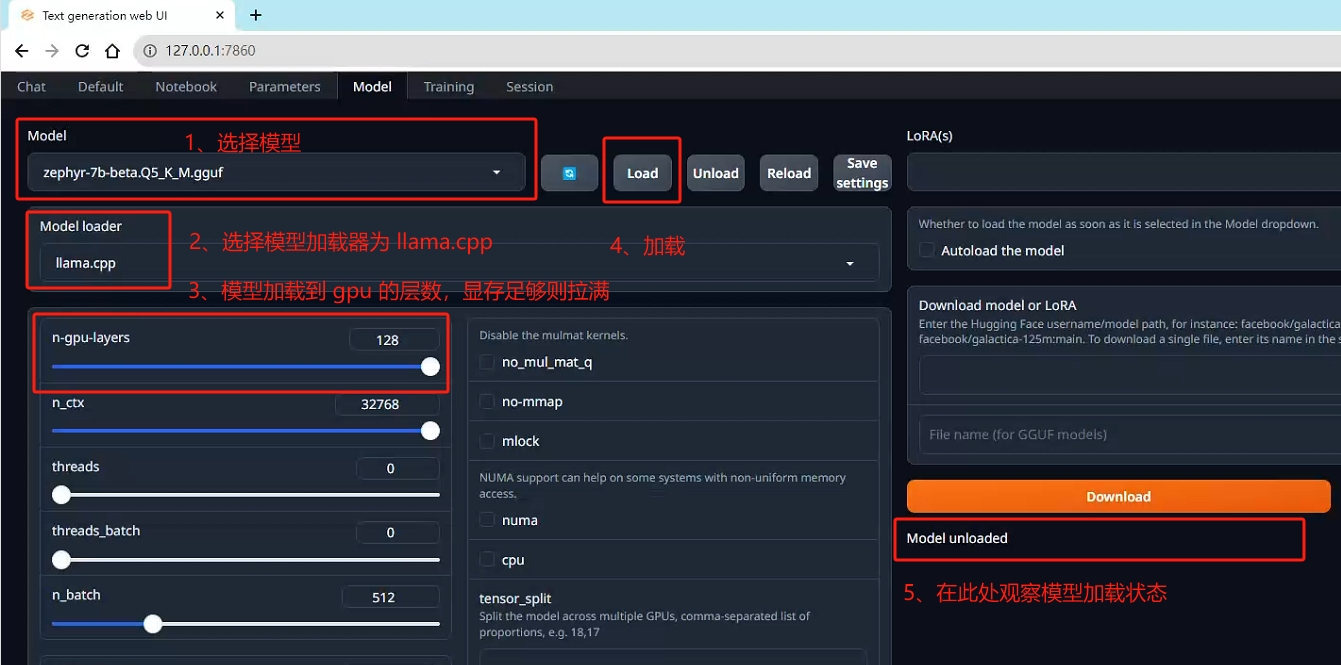
打开 127.0.0.1:7860 网页链接,model 页面,按上图进行模型加载即可(大概需要几十秒),随后即可进行对话。
GGUF 模型加载具体文档:https://github.com/oobabooga/text-generation-webui/wiki/04-‐-Model-Tab#llamacpp
3.3. 进行对话
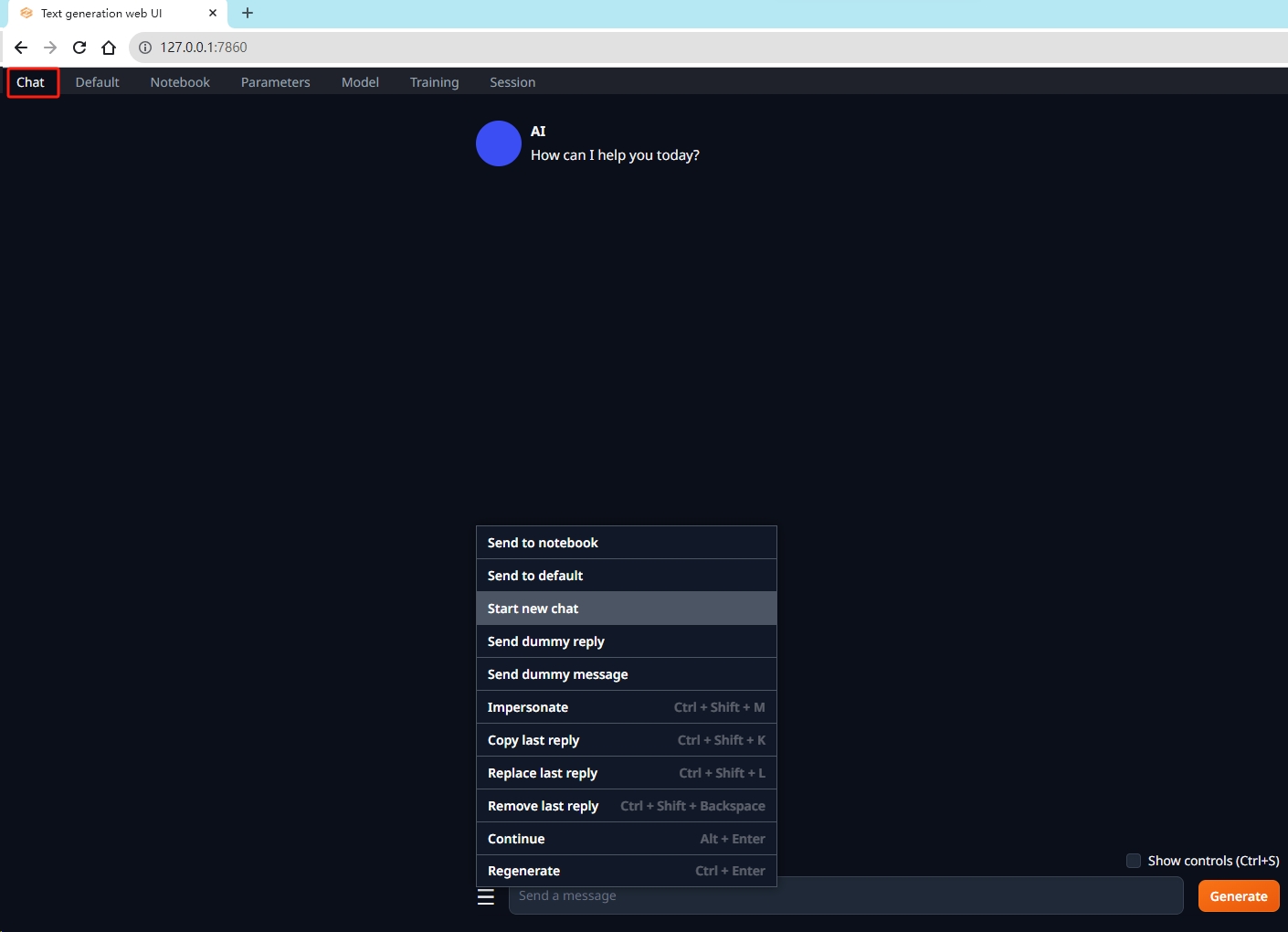
打开 chat 页面,即可进行对话。
- 在对话框左侧菜单中有 “开始新对话” 等操作
- 需注意,大部分模型默认语言为英文,不支持中文对话(可在模型页面查看详情)
- 需注意,本地模型无法像 chat-gpt 一样联网访问信息
4. 探索更多
- 中文
Awesome-LLM:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM

