
- 1git+linux+最新版本,linux源码安装git最新版本
- 2刚踏入职场的程序员(2年以内初级程序员)如何快速踏实地提升自己的能力
- 3【VSCode】配置git图文_vscode git path
- 4Java基于微信小程序的房屋租赁、租房小程序,附源码_房屋出租源码
- 5Springboot计算机毕业设计基于标签电影推荐微信小程序【附源码】开题+论文+mysql+程序+部署_基于springboot影视分享
- 6C++:vector容器(memcpy浅拷贝问题、迭代器失效问题)_c++new出来对象可以memcpy吗
- 7java开发(必遇)十大常见异常报错类型(详细)_java数据库开发常见错误
- 82023-08-06 YOLOair 使用GPU训练问题_yolo arm gpu
- 9Knowledge Distillation_模型剪枝开山之作
- 10大数据技术原理与应用-林子雨版-课后习题答案_大数据技术原理与应用林子雨答案csdn
RabbitMQ 如何保证高可用的?_rabbitmq高可用方案
赞
踩
分析&回答
RabbitMQ基于主从模式实现高可用。RabbitMQ有三种模式:单机模式,普通集群模式,镜像集群模式。
普通集群模式
普通集群模式就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是创建的queue只会放在一个rabbitmq实例上面,但是其他的实例都同步了这个queue的元数据。在你消费的时候,如果连接到了另一个实例,他会从拥有queue的那个实例获取消息然后再返回给你。
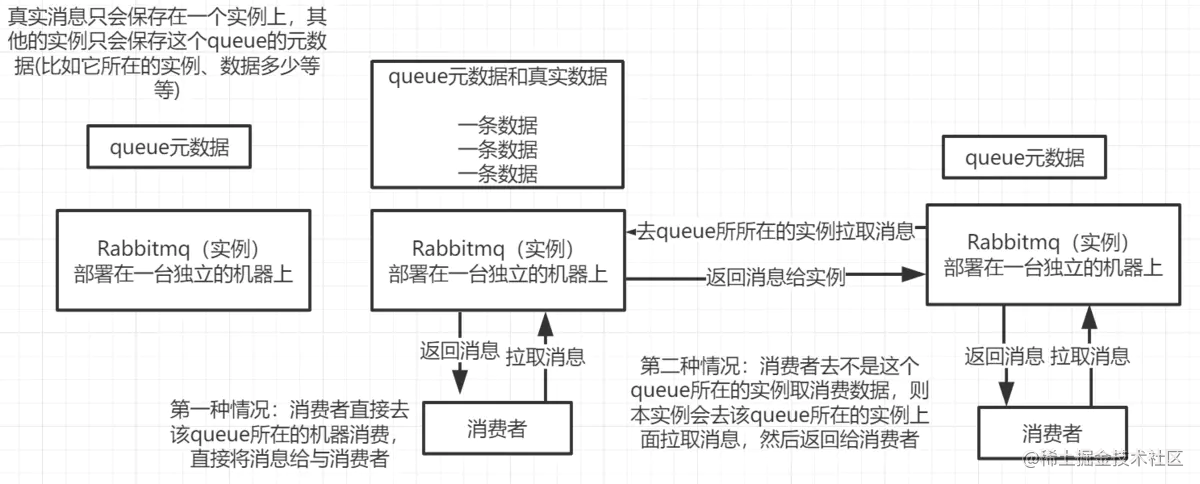
这种方式并没有做到所谓消息的高可用,就是个普通的集群,这样还会导致要么消费者每次随机连接一个实例然后拉取数据,这样的话在实例之间会产生网络传输,增加系统开销,要么固定连接那个queue所在的实例消费,这样会导致单实例的性能瓶颈。
而且如果那个方queue的实例宕机了,会导致接下来其他实例都无法拉取数据;如果没有开启消息的持久化会丢失消息;就算开启了消息的持久化,消息不一定会丢,但是也要等这个实例恢复了,才可以继续拉取数据。
所以这个并没有提供高可用,这种方案只是提高了吞吐量,也就是让集群中多个节点来服务某个queue的读写操作。
镜像集群模式
这种模式,才是rabbitmq提供是真正的高可用模式,跟普通集群不一样的是,你创建的queue,无论元数据还是queue里面是消息数据都存在多个实例当中,然后每次写消息到queue的时候,都会自动把消息到多个queue里进行消息同步。
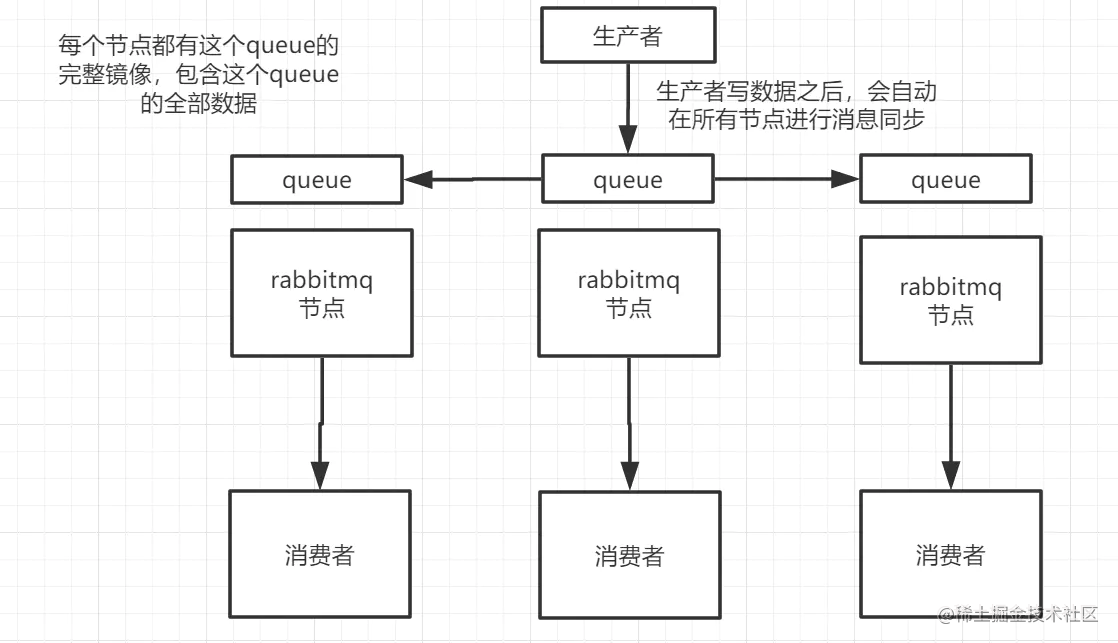
这种模式的好处在于,任何一台机器宕机了,其他的机器还可以使用。 坏处在于:
- 性能消耗太大,所有机器都要进行消息的同步,导致网络压力和消耗很大。
- 没有扩展性可言,如果有一个queue负载很重,就算加了机器,新增的机器还是包含了这个queue的所有数据,并没有办法扩展queue。
如何开启镜像集群模式:在控制台新增一个镜像集群模式的策略,指定的时候可以要求数据同步到所有节点,也可以要求同步到指定节点,然后在创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上面去了。
反思&扩展
实际上rabbitmq并不是分布式消息队列,他就是传统的消息队列,只不过提供了一些集群、HA的机制而已,因为无论如何配置,rabbitmq一个queue的数据就存放在一个节点里面,镜像集群下,也是每个节点都放这个queue的全部数据。
喵呜面试助手: 一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!

