
热门标签
热门文章
- 1华为机考入门python3--(15)牛客15-求int型正整数在内存中存储时1的个数
- 2Gerrit或Git中使用git clone/git pull/git cherry-pick使用时如何不输入密码_git cherry-pick每次都要输入密码
- 3移植speexdsp到OpenHarmony标准系统⑤
- 4js的国密sm3加密sm4加解密base64加解密javascript_sm679
- 5C# 上位机之海康相机开发(SDK)_c#海康sdk
- 6docker运行 elasticsearch 出错NoNodeAvailableException[None of the configured nodes are available_fluent no nodes are available
- 7不需要在 HTML 中添加任何额外的标签,就能实现复杂的设计效果。
- 8mac安装MINIO服务器
- 9001 计算机系统概论【计组】_电子管时代的外存
- 105.1 标准IO介绍及缓冲区_i/o流和缓冲区
当前位置: article > 正文
动手学深度学习(十二)——心跳信号分类预测(天池学习赛)简略
作者:笔触狂放9 | 2024-04-19 04:14:42
赞
踩
心跳信号分类预测
天池比赛: 零基础入门数据挖掘-心跳信号分类预测
主要介绍建模的步骤和思路(借鉴了B榜第一、第七以及各位大佬的部分内容,关于模型融合的部分将在之后的博客继续推出),采用CNN卷积神经网络对提供的一维数据进行训练。
一、认识数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
- 1
- 2
- 3
1.1 加载原始数据
原始数据下载:https://tianchi.aliyun.com/competition/entrance/531883/information
# 加载原始数据
df_train = pd.read_csv('./initial_data/train.csv')
df_testA = pd.read_csv('./initial_data/testA.csv')
- 1
- 2
- 3
1.2 查看原始数据相关信息
# 查看训练和测试数据的前五条
print(df_train.head())
print('\n')
print(df_testA.head())
# 检查数据是否有NAN数据
print(df_train.isna().sum(),df_testA.isna().sum())
# 确认标签的类别及数量
print(df_train['label'].value_counts())
# 查看训练数据集特征
print(df_train.describe())
# 查看数据集信息
print(df_train.info())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

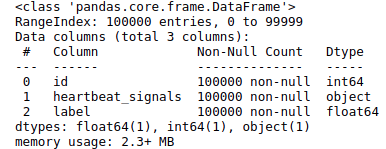
1.3 查看心跳信号波形
# 绘制每种类别的折线图
ids = []
for id, row in df_train.groupby('label').apply(lambda x: x.iloc[2]).iterrows():
ids.append(int(id))
signals = list(map(float, row['heartbeat_signals'].split(',')))
sns.lineplot(data=signals)
plt.legend(ids)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

原始数据信息整理
- 主要特征数据为1维信号振幅,总长度为205。(已经归一化到0~1了)
- 除波形数据外无其他辅助和先验信息
- 波形数据为float64格式
- 没有缺失值,无需填充。(未采集到的数据默认为0,故无缺失数据)
- 非表格数据更适合用神经网络处理
二、构建pytorch数据集
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.utils.data as Data
import torch.optim as optim
import torch
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
说明:关于数据加载我的思路是:(1)原始数据->(2)提取原始数据中的训练数据和标签数据-> (3)将训练数据和对应标签放入到pytorch的Dataset重构的类中构建新的pytorch数据集->(4)最后使用pytorch的DataLoaser打乱数据集构建批次数据集方便后面训练
# 加载原始数据
class MyData(Data.Dataset):
def __init__(self, feature, label):
self.feature = feature # 特征
self.label = label # 标签
def __len__(self):
return len(self.feature)
def __getitem__(self, idx):
return self.feature[idx], self.label[idx]
def load_data(batch_size):
# 加载原始数据
df_train = pd.read_csv('./initial_data/train.csv')
# 拆解heartbeat_signals
train_signals = np.array(df_train['heartbeat_signals'].apply(lambda x: np.array(list(map(float, x.split(','))),dtype=np.float32)))
train_labels = np.array(df_train['label'].apply(lambda x:float(x)),dtype=np.float32)
# 构建pytorch数据类
train_data = MyData(train_signals,train_labels)
# 构建pytorch数据集Dataloader
train_loader = Data.DataLoader(dataset = train_data,batch_size=batch_size,shuffle=True)
return train_loader
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、构建神经网络
说明:
网络主要包括了两个大的部分:(1)一维卷积神经网络(2)线性全连接层。
对于一维卷积神经网络其中的一些参数我作以下说明,pytorch不太方便的一点在于你需要自己计算一下其输出的结果大小,从而设置合适的padding进行填充(网上随便就可以找到计算方法):
nn.Conv1D(in_channels=1,out_channels=32,kernel_size=11,stride=1,padding=5)
in_channels:输入通道数,对于本波形数据就是1,对于彩色图片就是RGB这三个通道3;
out_channels:输出通道数,根据卷积核计算得到的输出结果的特征图的数量;
kernel_size: 一维卷积核的数量,对于conv1D卷积而言,沿着横向进行一维单方向卷积,所以卷积核的大小为(kernel_size,in_channels):
stride:卷积步长;
padding: 对输入的每一条边的填充。
- 1
- 2
- 3
- 4
- 5
- 6
class model_CNN_1(nn.Module):
def __init__(self):
super(model_CNN_1,self).__init__()
self.conv_unit = nn.Sequential(
nn.BatchNorm1d(1),
nn.Conv1d(in_channels=1,out_channels=32,kernel_size=11,stride=1,padding=5),
nn.LeakyReLU(),
nn.BatchNorm1d(32),
nn.Conv1d(in_channels=32,out_channels=64,kernel_size=11,stride=1,padding=5),
nn.LeakyReLU(),
nn.BatchNorm1d(64),
nn.MaxPool1d(4),
nn.Conv1d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.BatchNorm1d(128),
nn.Conv1d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(),
nn.MaxPool1d(4),
nn.Dropout(0.1),
)
self.dense_unit = nn.Sequential(
nn.Linear(3072,1024),
nn.LeakyReLU(),
nn.Linear(1024,128),
nn.LeakyReLU(),
nn.Linear(128,4),
nn.Softmax(dim=1)
)
def forward(self,inputs):
inputs = inputs.view(inputs.size()[0],1,inputs.size()[1])
inputs = self.conv_unit(inputs)
inputs = inputs.view(inputs.size()[0],-1)
inputs = self.dense_unit(inputs)
return inputs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
四、训练模型
def train_model(model,train_loader):
model.train()
running_loss = 0.0
running_acc = 0.0
for i,data in enumerate(train_loader):
inputs,labels = data
predictions = model(inputs)
loss = criterion(predictions,labels.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()*labels.size()[0]
_,pred = torch.max(predictions,1)
num_correct = (pred==labels).sum()
running_acc += num_correct.item()
return running_loss,running_acc
def loss_curve(list_loss,list_acc):
epochs = np.arange(1,len(list_loss)+1)
fig,ax = plt.subplots()
ax.plot(epochs,list_loss,label='loss')
ax.plot(epochs,list_acc,label='accuracy')
ax.set_xlabel('epoch')
ax.set_ylabel('%')
ax.set_title('loss & accuray ')
ax.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
# 调用定义的加载函数进行数据加载
batch_size = 64
train_data,train_loader = load_data(batch_size)
# 定义模型、loss function
model = model_CNN_1()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=0.0001)
# 循环20个epoch进行数据训练
list_loss,list_acc = [],[]
for epoch in range(20):
running_loss,running_acc=train_model(model,train_loader)
list_loss.append(running_loss/train_data.__len__())
list_acc.append(running_acc/train_data.__len__())
print('Train {} epoch, Loss: {:.6f}, Acc:{:.6f}'.format(epoch+1,running_loss/train_data.__len__(),running_acc/train_data.__len__()))
# 绘图查看loss 和 accuracy曲线
loss_curve(list_loss,list_acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
训练精度及误差:


五、模型测试:
由于模型测试其实是需要将结果放入到天池比赛官方才能看到的,所以我只能知道自己最后的一个分数。这个模型是为了练习CNN做的,单模型的分数也不高,有很多地方也需要优化。所以模型测试和修改部分将在后面更改完善后上传。
六、后期优化方向
- CNN网络优化:包括网络的层数、输出的通道数量、池化层的位置和方法等等
- 多模型优化和模型融合:建立多个模型进行加权投票,这样可以在一定程度上提高模型的泛化性和精度,同时降低了loss。这里模型的选择不仅仅包括CNN,LSTM等。
- 模型更新参数调整方法:可以采用自动学习率降低方法来动态调整学习率,减小模型过拟合的风险,同时加快训练的效率。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/449890
推荐阅读

相关标签

