
- 1飞桨Ai(一)基于训练后的模型进行信息提取
- 2Pytorch入门实战: 05-Pytorch实现运动鞋识别
- 3华为OD机试-考勤信息_od考勤信息 python
- 4CompletableFuture异步编程事务及多数据源配置详解(含gitee源码)_completablefuture.runasunc
- 5数字集成电路设计(六、Verilog HDL高级程序设计举例)_verilog hdl高级数字设计
- 6人工智能机器人 grok-1在github开源_grok-1 github
- 7Windows10安装多个版本的PostgreSQL数据库,但是均没有自动注册Windows服务的解决方法_win10安装两个版本的pg
- 8laravel实现AMQP(rabbitmq)生产者以及消费者_laravel amqp
- 9Personal Fedora 9 Installation Guide
- 10java.util.Concurrent包下面的常见类_concurrent包下的类
youtube DNN视频topN推荐算法原理及代码_topk ranking
赞
踩
一、前言
最近由于需要做一个topK推荐的项目,所以调研了一下,发现youtubeNet好像大家的评价不错,想实现一下,以此博客记录一下
二、YoutubeNet基本框架
Youtube是国外的大型视频网站,用户多达几亿,每秒上传的视频长度多达几个小时。对于这样一个大型视频网站,它的推荐系统面临以下几个问题:
1、体量大:包括用户和视频集都十分巨大,如何从上百亿的视频中为上亿用户推荐他们所感兴趣的视频?
2、新鲜度:youtube视频集是一个动态的视频库,每秒上传的视频多达几个小时,如何平衡好新视频(new content)和以北大家所接受的热门视频(well-established videos)之间的关系?
3、噪音:youtube用户的行为很难准确预测(由于稀疏性和外部因素的不可控性)
整个系统分成Candicate generation和Ranking,前者从上百亿的视频中选出一个百级数量的候选视频集,后者将这百级数量的视频排序,选出topK(本课题是选出50个)个用户感兴趣的视频推荐给用户。整个系统如下图所示:
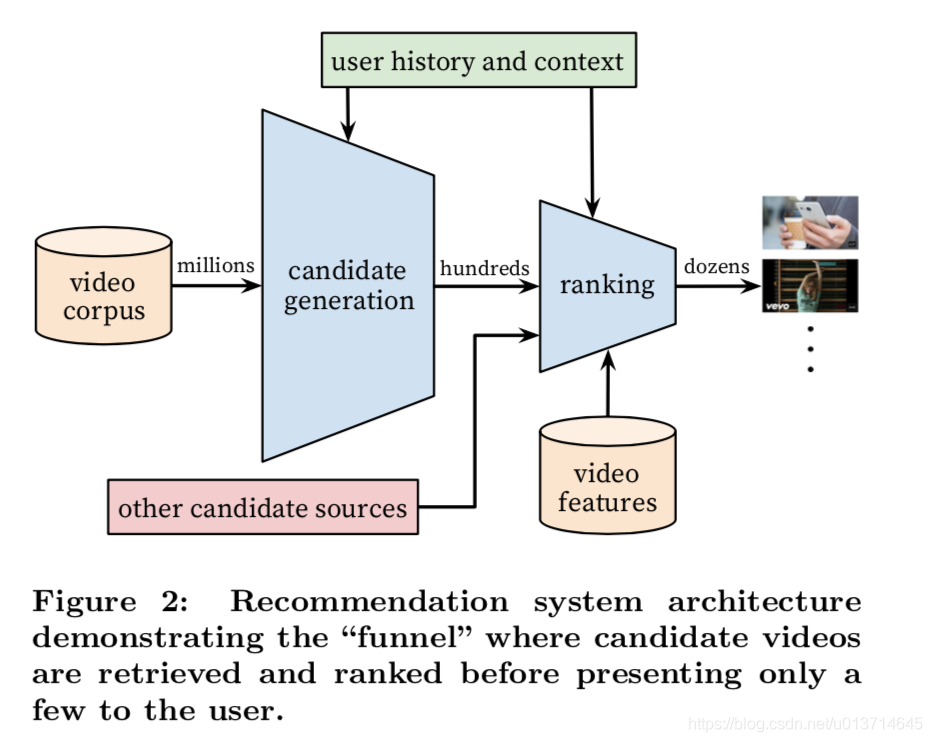
三、候选集生成(Candicate generation)
前者在这一部分是用的算法是矩阵分解(a matrix factorization approach trained under rank loss),可以将这部分的DNN模型是做一个非线性的因子分解技术(a non- linear generalization of factorization techniques)。
1、推荐看作分类(Recommendation as Classification)
作者们实际上将推荐问题看作一个多分类问题(超大规模多分类):已知视频全集V,用户U和其上下文C,预测其在t时刻的视频类别。公式如下:

如文中所说,该DNN的目的是学习user embedding向量,作为输入送到softmax classifier,用以生成初步候选集。整个候选集生成的模型如下图:
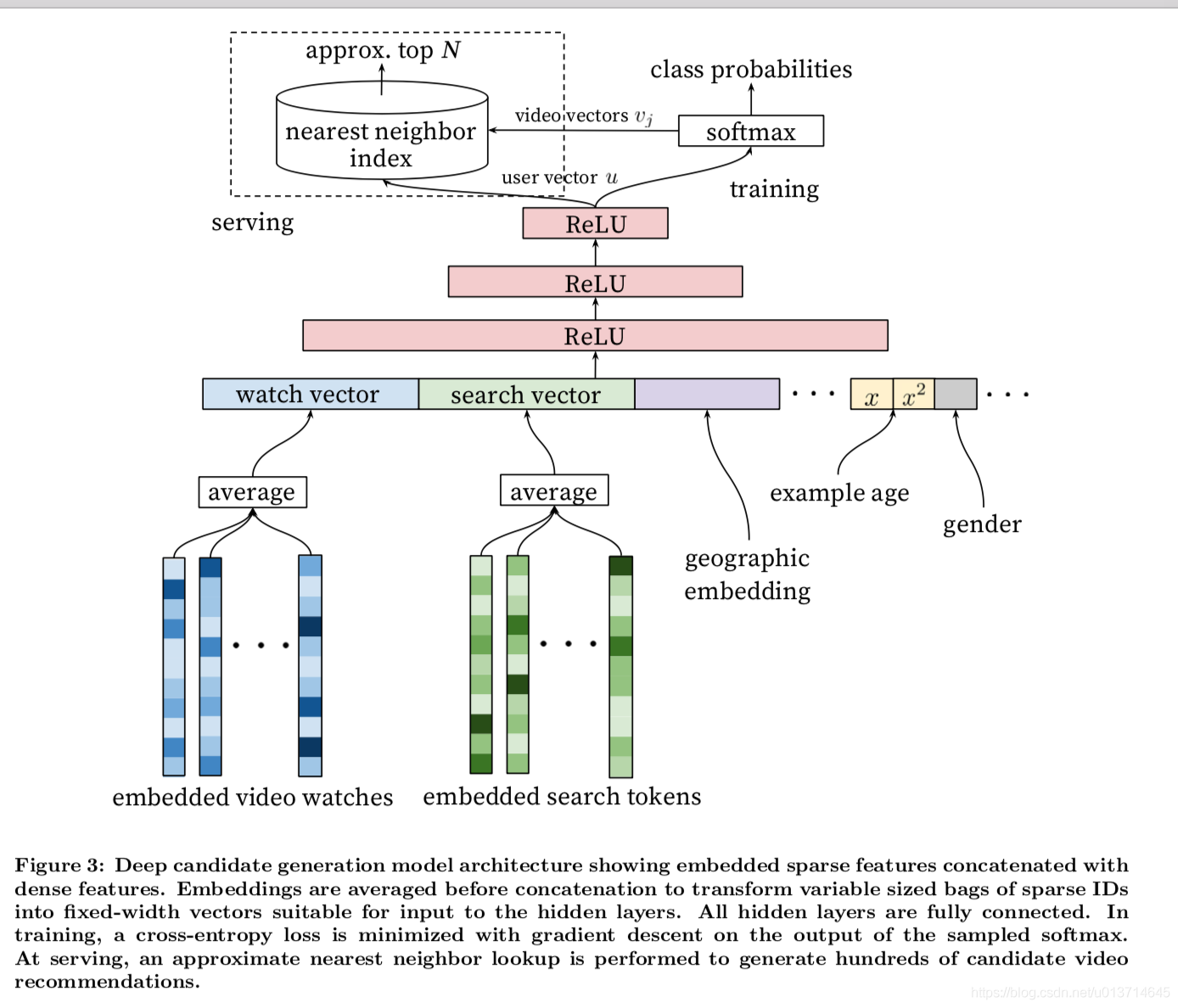
受启发于NLP中对词袋的处理。文中将用户历史观看视频ID (定长的,如历史前20次观看记录,不足补零)和用户历史搜索视频ID转化成定长的的embedding vector(可以通过求均值,补零等操作转化成定长)。使用DNN的原因之一:在DNN中连续性变量和类别型变量都很容易输入到模型中,包括一些人口统计特征(Demographic features),对最终的效果起着十分重要的作用。用户的地域,设备等都可以作为embedding向量输入到DNN中去。简单的二值化特征(如性别)和数值型特征(如年龄)可以直接输入到DNN中,数值型需要经过归一化到[0,1]再输入到模型中。
推荐中关键的一点,新颖性:
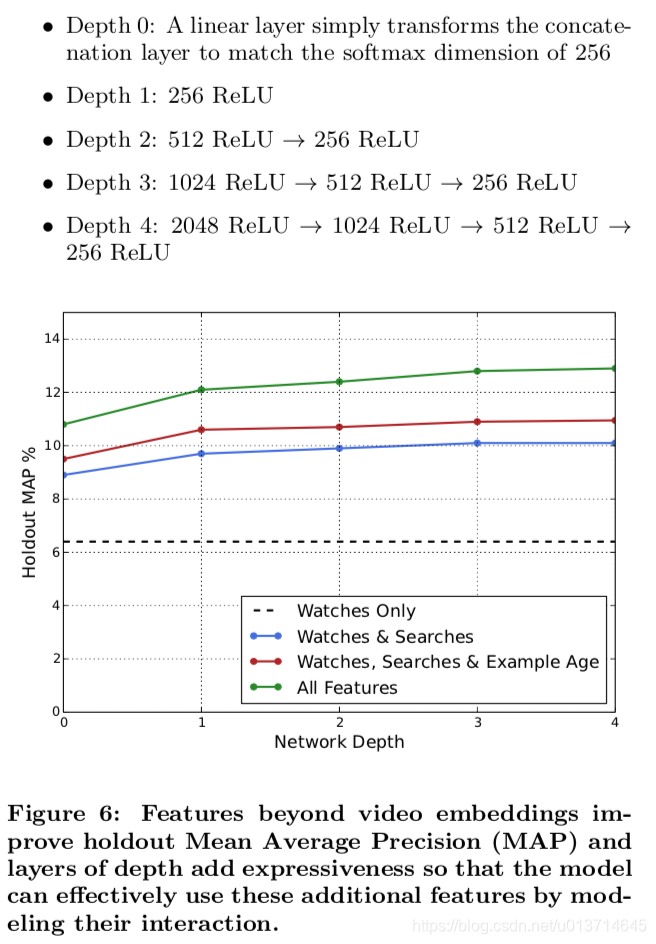
在推荐系统中很重要的一点是视频的新颖性,用户更倾向于观看新视频,但机器学习模型都是基于历史观看视频记录学习,所以在某种程度上,模型和业务是相悖的,所以文中构建了一个特征age of training example,简单的可以理解为是视频的年龄,初始值设为0,随着时间的增长,记录视频的年龄。加入之后效果十分明显,如下图:

标签和上下文的选择:

skip-gram是用的是(a)中的采样方法,这种方法实际上是使用了未来信息,在线上的时候会导致效果下降,所以文中使用的是(b)方法采样和构建标签。
在实验中,将用户的观看记录(50次)和历史搜索记录(50次) embedding成256维的向量,输入到模型中,如下图:
作者称之为tower结构,
四、排序,topK推荐生成(Ranking)

1、 特征工程:
在构建特征的过程中,作者发现一个重要的特征信号是该用户历史上与该视频或者同类视频的交互历史(pv,click等),由此启发构建特征:该用户在该频道下看过多少视频,在该频道下上一次观看视频的时间,
2、embedding类别特征:
和candidate generation类似,对每个视频ID embedding,
3、归一化连续特征:
众所周知,NN对输入特征的尺度和分布都是非常敏感的,实际上基本上除了Tree-Based的模型(比如GBDT/RF),机器学习的大多算法都如此。我们发现归一化方法对收敛很关键,推荐一种排序分位归一到[0,1]区间的方法,累计分位点:

而且,不止输入归一化之后的x,还做二次,根号变换,如x**2,x的平方根都作为输入送到模型中去,见上面ranking的DNN结构图,文中说这样能够让模型很容易学习到特征的非线性特性。加入这些连续型特征之后。大大提升了模型的线下效果。
4、建模期望观看时长

5、不同隐层的实验
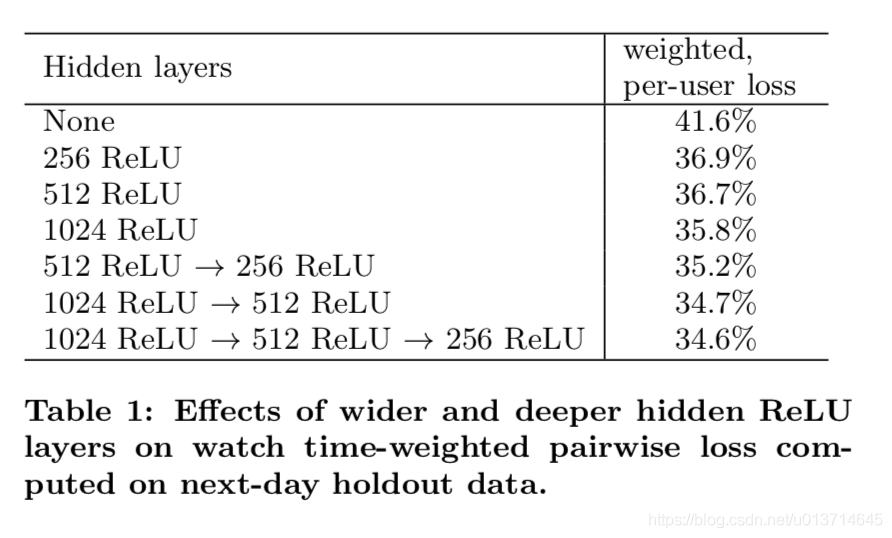
下图的table1是离线利用hold-out一天数据在不同NN网络结构下的结果。如果用户对模型预估高分的反而没有观看,我们认为是预测错误的观看时长。weighted, per-user loss就是预测错误观看时长占总观看时长的比例。
我们对网络结构中隐层的宽度和深度方面都做了测试,从下图结果看增加隐层网络宽度和深度都能提升模型效果。而对于1024-->512-->256这个网络,测试的不包含归一化后根号和方式的版本,loss增加了0.2%。而如果把weighted LR替换成LR,效果下降达到4.1%。
五、代码
代码链接:
可以用google colab直接运行,白嫖的大厂计算资源还是很好用的。
用的是浅梦大佬的开源包deepmatch,代码如下
- import pandas as pd
- from deepctr.inputs import SparseFeat, VarLenSparseFeat
- from preprocess import gen_data_set, gen_model_input
- from sklearn.preprocessing import LabelEncoder
- from tensorflow.python.keras import backend as K
- from tensorflow.python.keras.models import Model
-
- from deepmatch.models import *
- from deepmatch.utils import sampledsoftmaxloss
-
- # 以movielens数据为例,取200条样例数据进行流程演示
-
- data = pd.read_csvdata = pd.read_csv("./movielens_sample.txt")
- sparse_features = ["movie_id", "user_id",
- "gender", "age", "occupation", "zip", ]
- SEQ_LEN = 50
- negsample = 0
-
- # 1. 首先对于数据中的特征进行ID化编码,然后使用 `gen_date_set` and `gen_model_input`来生成带有用户历史行为序列的特征数据
-
- features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip']
- feature_max_idx = {}
- for feature in features:
- lbe = LabelEncoder()
- data[feature] = lbe.fit_transform(data[feature]) + 1
- feature_max_idx[feature] = data[feature].max() + 1
-
- user_profile = data[["user_id", "gender", "age", "occupation", "zip"]].drop_duplicates('user_id')
-
- item_profile = data[["movie_id"]].drop_duplicates('movie_id')
-
- user_profile.set_index("user_id", inplace=True)
-
- user_item_list = data.groupby("user_id")['movie_id'].apply(list)
-
- train_set, test_set = gen_data_set(data, negsample)
-
- train_model_input, train_label = gen_model_input(train_set, user_profile, SEQ_LEN)
- test_model_input, test_label = gen_model_input(test_set, user_profile, SEQ_LEN)
-
- # 2. 配置一下模型定义需要的特征列,主要是特征名和embedding词表的大小
-
- embedding_dim = 16
-
- user_feature_columns = [SparseFeat('user_id', feature_max_idx['user_id'], embedding_dim),
- SparseFeat("gender", feature_max_idx['gender'], embedding_dim),
- SparseFeat("age", feature_max_idx['age'], embedding_dim),
- SparseFeat("occupation", feature_max_idx['occupation'], embedding_dim),
- SparseFeat("zip", feature_max_idx['zip'], embedding_dim),
- VarLenSparseFeat(SparseFeat('hist_movie_id', feature_max_idx['movie_id'], embedding_dim,
- embedding_name="movie_id"), SEQ_LEN, 'mean', 'hist_len'),
- ]
-
- item_feature_columns = [SparseFeat('movie_id', feature_max_idx['movie_id'], embedding_dim)]
-
- # 3. 定义一个YoutubeDNN模型,分别传入用户侧特征列表`user_feature_columns`和物品侧特征列表`item_feature_columns`。然后配置优化器和损失函数,开始进行训练。
-
- K.set_learning_phase(True)
-
- model = YoutubeDNN(user_feature_columns, item_feature_columns, num_sampled=5, user_dnn_hidden_units=(64, 16))
- # model = MIND(user_feature_columns,item_feature_columns,dynamic_k=True,p=1,k_max=2,num_sampled=5,user_dnn_hidden_units=(64,16),init_std=0.001)
-
- model.compile(optimizer="adagrad", loss=sampledsoftmaxloss) # "binary_crossentropy")
-
- history = model.fit(train_model_input, train_label, # train_label,
- batch_size=256, epochs=1, verbose=1, validation_split=0.0, )
-
- # 4. 训练完整后,由于在实际使用时,我们需要根据当前的用户特征实时产生用户侧向量,并对物品侧向量构建索引进行近似最近邻查找。这里由于是离线模拟,所以我们导出所有待测试用户的表示向量,和所有物品的表示向量。
-
- test_user_model_input = test_model_input
- all_item_model_input = {"movie_id": item_profile['movie_id'].values, "movie_idx": item_profile['movie_id'].values}
-
- # 以下两行是deepmatch中的通用使用方法,分别获得用户向量模型和物品向量模型
- user_embedding_model = Model(inputs=model.user_input, outputs=model.user_embedding)
- item_embedding_model = Model(inputs=model.item_input, outputs=model.item_embedding)
- # 输入对应的数据拿到对应的向量
- user_embs = user_embedding_model.predict(test_user_model_input, batch_size=2 ** 12)
- # user_embs = user_embs[:, i, :] i in [0,k_max) if MIND
- item_embs = item_embedding_model.predict(all_item_model_input, batch_size=2 ** 12)
-
- print(user_embs.shape)
- print(item_embs.shape)
-
- # 5. [可选的]如果有安装faiss库的同学,可以体验以下将上一步导出的物品向量构建索引,然后用用户向量来进行ANN查找并评估效果
-
- test_true_label = {line[0]:[line[2]] for line in test_set}
- import numpy as np
- import faiss
- from tqdm import tqdm
- from deepmatch.utils import recall_N
- index = faiss.IndexFlatIP(embedding_dim)
- # faiss.normalize_L2(item_embs)
- index.add(item_embs)
- # faiss.normalize_L2(user_embs)
- D, I = index.search(user_embs, 50)
- s = []
- hit = 0
- for i, uid in tqdm(enumerate(test_user_model_input['user_id'])):
- try:
- pred = [item_profile['movie_id'].values[x] for x in I[i]]
- filter_item = None
- recall_score = recall_N(test_true_label[uid], pred, N=50)
- s.append(recall_score)
- if test_true_label[uid] in pred:
- hit += 1
- except:
- print(i)
- print("recall", np.mean(s))
- print("hr", hit / len(test_user_model_input['user_id']))



