- 1OceanBase4.1社区版(单节点集群)安装_oceanbase社区版安装
- 2PostgreSql的聚合函数--string_agg_postgres聚合字段
- 3《数据挖掘与数据化运营实战》(第10章)_过拟合在数据挖掘第几章
- 4什么是实例分割,与语义分割和目标检测有何不同?_实例分割和目标检测区别
- 5Java并发:线程安全与锁优化_并发的安全问题 java 锁
- 6面试题汇总 --js 进阶_js进阶面试题
- 7【银行测试】金融项目+测试方法范围分析,功能/接口/性能/安全...
- 8Hadoop伪分布式的安装配置步骤_hadoop伪分布式安装步骤
- 9github copilot学生认证(手把手一小时成功)
- 10STM32智能定位称重垃圾箱设计_stm32智能垃圾桶word
CES 2024的亮点仅仅聚焦AI深度赋能和产业创新吗?| DALL-E 3、Stable Diffusion等20+ 图像生成模型综述_ces2024大会
赞
踩
随着科技飞速发展,CES(国际消费电子展)已然成为全球科技产业的风向标,每年的CES大会都是业界瞩目的盛事。回顾2024年CES大会,不难发现其亮点纷呈,其中以人工智能的深度赋能为最引人注目之处。AI技术的深入应用成为CES大会上的一大亮点,各大厂商纷纷展示了在AI领域的最新成果。
关键词:CES;AI;VR;消费电子;生成式AI;NVIDIA;Copilot;Rabbit R1;Vision Pro;Micro LED;GeForce RTX 40 SUPER
AI深度赋能产业创新纷呈
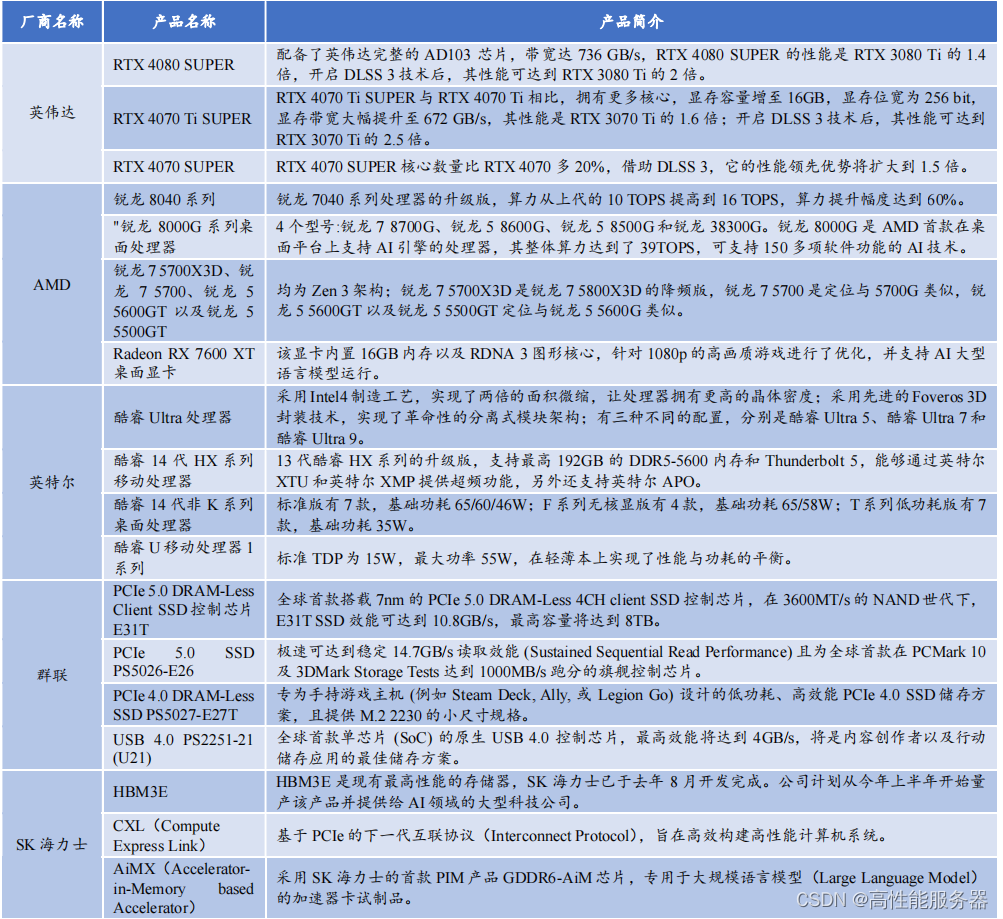
各大芯片公司围绕生成式AI展开激烈竞争。英伟达RTX 40 SUPER系列表现优秀,不仅提高性能还节约成本;AMD锐龙8000G系列突出AI能力;英特尔已经开始与OEM企业合作,率先构建AI PC生态系统。这些的芯片制造商通过不懈努力,有望加速AI及AI PC在不同行业中的应用,并推动AI技术为各行各业注入新活力。
一、英伟达
1、芯片
在本届CES大会上,英伟达发布基于Ada Lovelace架构的GeForce RTX 40 SUPER系列显卡,型号涵盖RTX 4080 SUPER、RTX 4070 Ti SUPER和 RTX 4070 SUPER三款产品(均可应用于笔记本电脑)。RTX 4080 SUPER凭借AD103芯片和强大的CUDA核心数,736 GB/s的内存带宽,可轻松应对4K全景光线追踪游戏。在游戏图形高性能需求情况下,RTX 4080 SUPER速度是RTX 3080 Ti的1.4倍。此外,借助836 TOPS AI算力和DLSS帧生成功能,RTX 4080 SUPER的性能可达到RTX 3080 Ti的2倍。
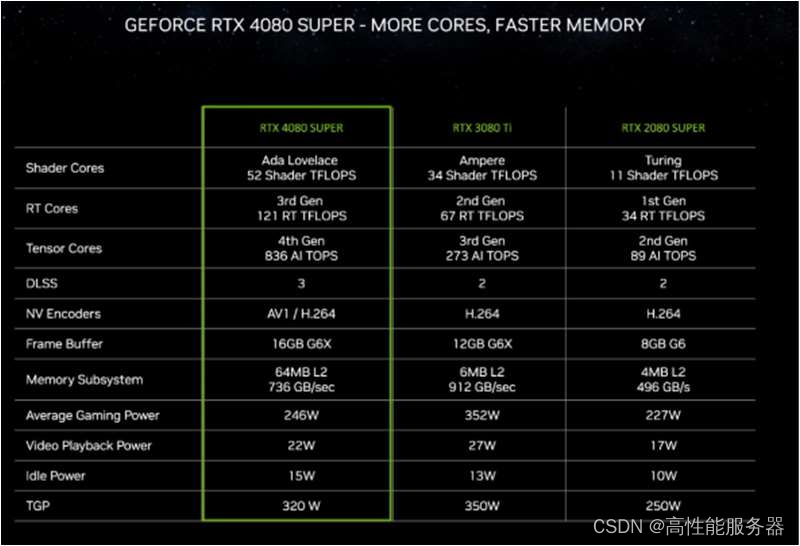
英伟达 RTX 4080 SUPER 性能对比
英伟达RTX 4070 Ti SUPER在核心数量和显存容量上优于RTX 4070 Ti,显存容量提升至16GB,显存位宽为256 bit,带宽增加至672 GB/s。相较于上代RTX 3070 Ti,其性能提升1.6倍,在开启DLSS 3技术后,性能可提升至RTX 3070 Ti的2.5倍。
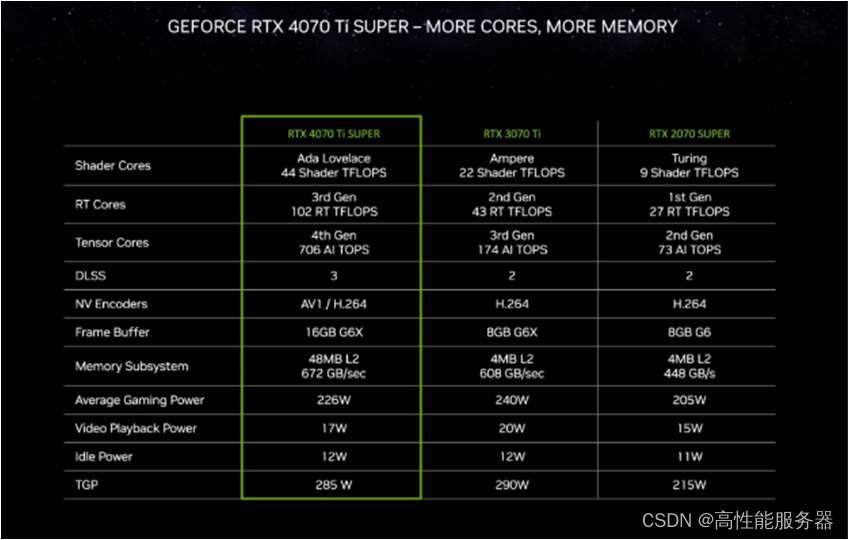
英伟达 RTX 4070 Ti SUPER 性能对比
RTX 4070 SUPER的核心数量比RTX 4070高出20%,并且仅用RTX 3090部分功耗情况下,就已经超越RTX 3090性能表现。当使用DLSS 3时,其性能优势可扩大到1.5倍。
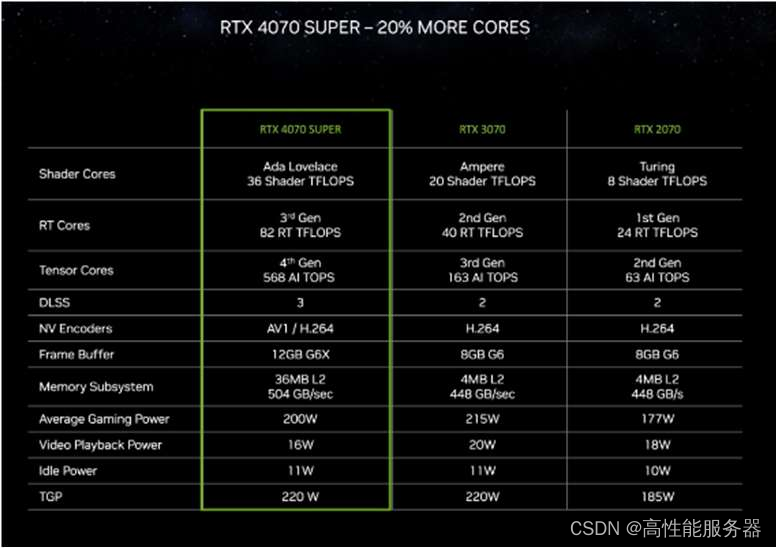
英伟达 RTX 4070 SUPER 性能对比
2、AI软件服务
英伟达首次将AI应用到游戏虚拟人物生成上,该服务包括NVIDIA Audio2 Face(A2F)和NVIDIA Riva 自动语音识别(ASR)。前者依据声音来源制作富有表情的面部动画,后者能为虚拟数字人物开发多语言语音和翻译应用。

3、智能驾驶领域
在CES 2024展会上,梅赛德斯-奔驰发布一系列软件驱动功能以及基于NVIDIA DRIVE Orin芯片的CLA级智能驾驶辅助系统。
英伟达近日宣布,理想汽车等一系列厂商选择使用NVIDIA DRIVE Thor集中式车载计算平台。此外,电动汽车制造商如长城汽车、极氪和小米汽车已决定在其新一代自动驾驶系统中采用NVIDIA DRIVE Orin平台。

NVIDIA DRIVE Thor™集中式车载计算平台
二、AMD
AMD引入基于Zen 3架构的四款新品,包括锐龙7 5700X3D、锐龙7 5700、锐龙5 5600GT和锐龙5 5500GT:
- 锐龙7 5700X3D具有8核16线程设计,最大加速频率为4.1GHz,并支持3D V-CACHE技术,游戏性能十分突出;
- 锐龙7 5700是8核16线程,最大加速频率4.6GHz,无核显;
- 锐龙5 5600GT和锐龙5 5500GT都是6核12线程,最大加速频率分别为4.6GHz和4.4GHz,并带有Radeon核显。
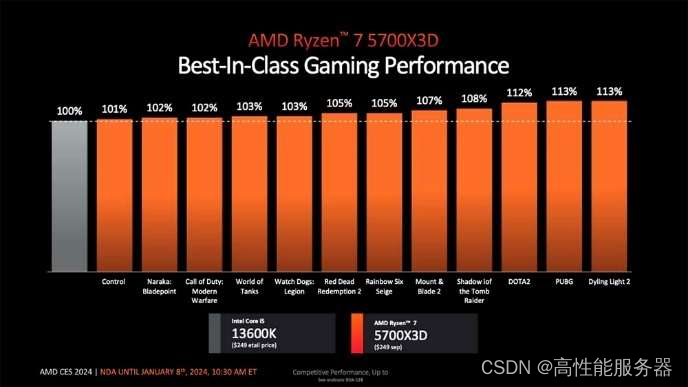
锐龙 7 5700X3D 游戏性能优秀
AMD发布新显卡Radeon RX 7600 XT,配备RDNA 3图形核心和16GB内存,专门优化1080p高画质游戏,并可以处理一些1440p游戏。该显卡支持HYPR-RX、Ray Tracing、AV1、FSR3等软件,提供更顺畅的游戏体验。此外,16GB内存使Radeon RX 7600 XT能够支持AI大语言模型,显著提高处理和创作速度。

Radeon RX 7600 XT 16GB 显卡的游戏性能得到较大提升
三、 英特尔
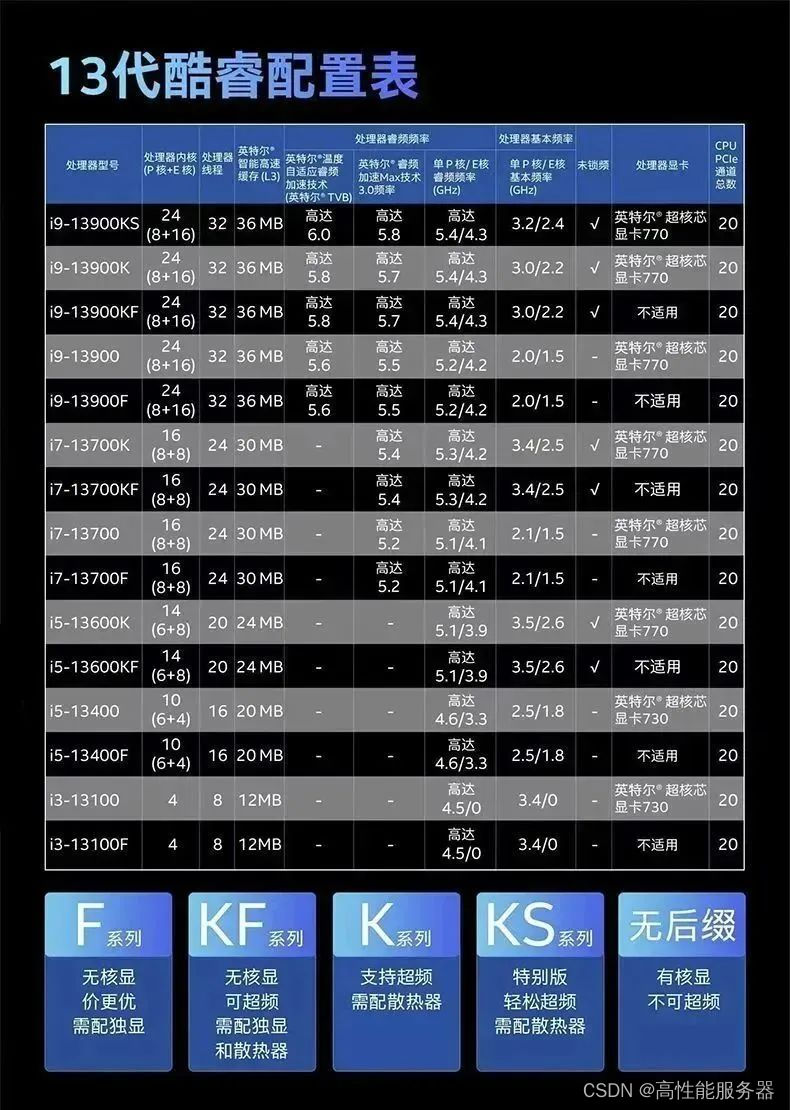
英特尔推出14代酷睿移动和台式机处理器系列,包括升级版的HX系列移动处理器,以及适用于移动平台的低压酷睿移动处理器系列。14代酷睿HX系列提升游戏和多任务创作性能,支持最高192GB DDR5-5600内存和Thunderbolt 5,并配备超频功能以及增强的联网能力。酷睿i9-14900HX是14代移动处理器家族的顶级产品,拥有24核心32线程,最高频率为5.8 GHz。

英特尔 14 代酷睿 HX 系列移动处理器
四、群联
群联电子推出全球首款7纳米制程的PCIe 5.0 DRAM-Less 4CH client SSD控制芯片E31T,标志着其在PC OEM和主流SSD市场开展业务。这颗新芯片在现有的3600MT/s NAND时代下,SSD效能可达到10.8GB/s,最高容量可达8TB。未来4800MT/s NAND发布后,其速度可能提升至14GB/s。此外,群联还展示其他新产品,如PCIe 5.0 SSD PS5026-E26、PCIe 4.0 DRAM-Less SSD PS5027-E27T和USB 4.0 PS2251-21 (U21)。

全球首款 PCIe 5.0 DRAM-Less Client SSD 控制芯片 E31T
CES 2024大会亮点
CES作为颇具影响力的科技展览,展示芯片硬件到终端应用的全方位科技成果,涉及AI、VR、消费电子、汽车电子和智能家居等领域,标志着未来科技的方向。
一、AI PC
AI PC作为本次盛会主角,集结全链条科技力量,包括芯片、系统和终端,预示着AI PC元年来临。戴尔、惠普、华硕、三星等知名厂商的AI PC产品势如破竹,在硬件提升、AI助手整合和性能优化方面展示出其领先地位。特别是大多数AI PC都增加AI专用启动键。英伟达、AMD、英特尔等核心元件制造商的最新AI PC芯片部署,使整体计算能力有了显著的提升。在CES 2024引领下,全球PC产业正在以更快的速度进入AI时代。
二、生成式AI与笔记本电脑完美结合:开启智能办公新时代
2023年,生成式AI成为科技领域的大热话题。因此在CES展上,生成式AI大放光彩。
戴尔Windows 11笔记本将配备微软自然语言AI助手,即通过Windows for Copilot按钮实现更智能操作。NVIDIA首次推出Chat with RTX展示应用程序,可以在Windows RTX个人电脑或工作站上搜索包括聊天、文档和视频在内的各种内容。
在零售商业领域,生成型AI也在2024年的CES展上大放异彩。如沃尔玛首次亮相Shop With Friends社交商务平台。大众汽车正在尝试将ChatGPT技术融入到汽车产品中。目前不能确定这些功能是否会像语言AI助手一样受欢迎,从长远角度来看,都是值得密切关注的重要发展趋势。
三、生产力小工具强调速度和易用性
在2024年CES展览会上Rabbit R1是另外一个令人瞩目的焦点,这是一款基于生成式AI的手持设备。其可以改变人们与应用程序的互动方式,甚至可以取代智能手机。例如,通过用户简单口头指令,Rabbit R1能完成如“预订航班”等任务。
![]()

此外,屏幕显示技术也取得重大突破。如联想ThinkVision 27 3D显示器能快速将2D图像转换为3D内容,满足用户多样化的需求。
值得一提的是,Wi-Fi 7认证推出意味着更多设备将具备更高的数据处理能力,为虚拟现实等应用领域带来无限可能。在展会上,众多制造商如TP-Link、UniFi、MSI和Acer都发布适配Wi-Fi 7的路由器产品。
四、多合一笔记本电脑为专业人士提供选择
在CES 2024上,能够轻松转换为平板电脑的笔记本成为焦点,其中惠普Spectre x360和戴尔新款XPS系列备受瞩目。华硕的Zenbook DUO(2024)UX8406更是独树一帜,凭借其独特的双屏设计和灵活的变形模式,为用户提供丰富的功能。
![]()

华硕 Zenbook DUO 双屏共享模式
五、高通、汽车制造商和其他公司推广虚拟现实和混合现实产品
预计一月底,三星将推出一款搭载高通骁龙XR2+ Gen 2芯片的虚拟混合现实耳机,与苹果的Vision Pro展开竞争。在CES展览会上,除三星和宝马之外,混合现实和虚拟现实还在其他领域得到展示。
六、曲面透明的电视屏幕引人注目
在家庭办公环境中,透明电视屏幕已从单纯的电视设备转变为令人惊叹的艺术品。三星透明Micro LED和LG Signature OLED T就是杰出代表。此外,许多大型曲面显示器也在展现游戏市场的吸引力。不仅提升电视的观感体验,也进一步拓宽显示技术的应用领域。
![]()

LG Signature OLED T 透明电视
DALL-E、Stable Diffusion等 20+ 图像生成模型综述
近两年图像生成模型如Stable Diffusion和DALL-E系列模型的不断发展引起广大关注。为深入理解 Stable Diffusion 和 DALL-E 3 等最新图像生成模型,从头开始探索这些模型的演变过程就显得至关重要。下面主要通过任务场景、评估指标、模型类型、效率优化、局限性等11个方面为大家进行讲解。
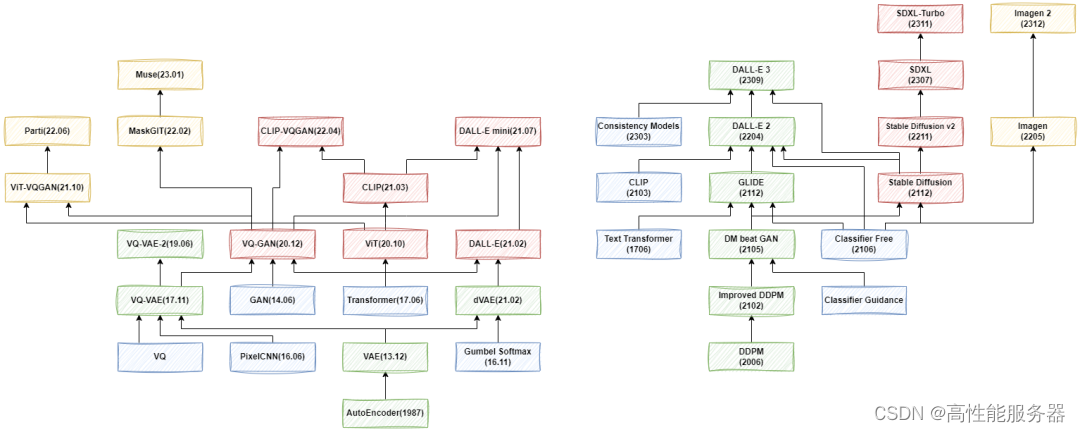
一、任务场景
1、无条件生成
无条件生成是一种生成模型不受任何额外条件影响,只根据训练数据分布生成图像。其适用于不需要额外信息或上下文的场景,如根据随机噪声生成逼真的人脸图像。举列来说:CelebA-HQ和FFHQ是高质量的人脸数据集,分别包含30,000和70,000张1024x1024分辨率的人脸图像。而LSUN是一款场景类别数据集,包括卧室、厨房、教堂等类别,每个图像的大小为256x256分辨率,每个类别包含12万到300万张图像。这些都是常用的无条件评估任务。

基于以上数据集训练之后(4 个模型)生成的图像
2、有条件生成
有条件生成是一种生成模型,在形成图像时会受到额外条件或上下文的影响,如类别标签、文本描述或特定属性等。广泛应用于需要按特定条件生成结果的任务。如根据给定的文本描述生成相应的图像或在生成特定类别图像时提供相应类别标签。
1)类别条件生成
类别条件生成常用于图像生成领域,ImageNet 是其常见的实例,主要用于图像分类任务,拥有1000个类别标签。在生成图像时,可以指定对应的类别标签,让模型按照类别进行图像生成。

2)文本条件生成
文本条件生成是目前最流行的图像生成方法,其模型可根据输入的自然语言描述来生成相应的图像。
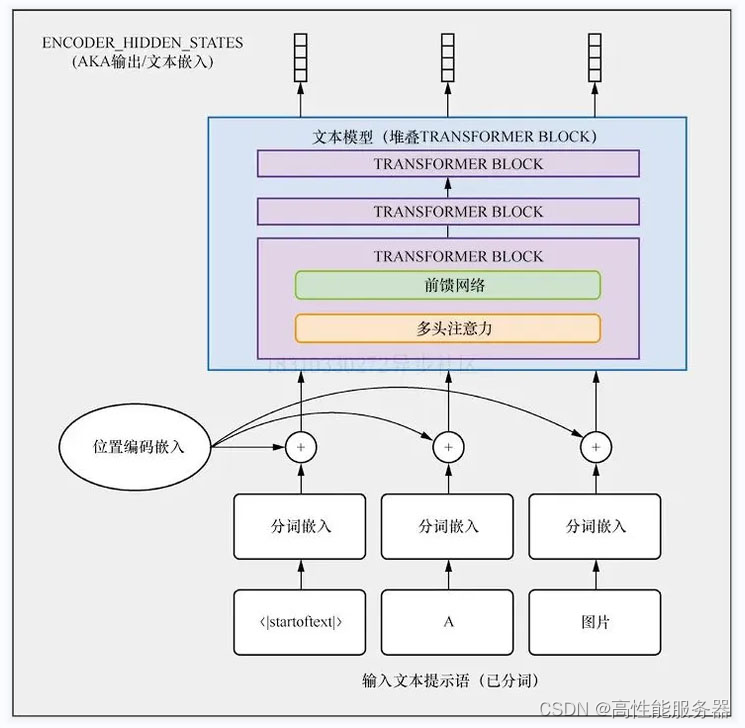
3)位置条件
当对图像的物体布局或主体位置有特定需求时,可以结合使用类别条件和文本条件指导模型生成过程。

左侧图中指定图片中物体的位置关系(以边界框坐标表示),最终模型按要求生成对应的图像
4)图像扩充
图像条件经常被用于按需处理图像,如图像扩充(Outpainting)。

5)图像内编辑
图像内编辑(Inpainting)是另一个以图像为条件的常见生成方式,结合文本输入进行操作。
6)图像内文字生成
需要图片中包含特定文本内容,也可以条件形式输入。

7)多种条件生成
有些场景会包含多种条件,如给定图像、文本等,模型要综合考量这些条件才能生成满足要求的图像。
三、评估指标
1、IS
IS(Inception Score)一个评估生成图像质量和多样性的标准,主要考虑生成图像的真实性与多样性。其计算过程通过分类模型确定各类别的概率分布,再计算概率分布的KL散度,最后以指数平均值形式表达。
2、FID
FID(Frechet Inception Distance)即衡量生成图片与真实图片距离指标,其值越小代表越优秀。计算方法包括提取真实图像和生成图像的特征向量,并计算二者的Frechet距离。在实践中通常利用IS评估真实性,而FID则用来评估多样性。
3、CLIP Score
OpenAI发布的CLIP模型包含图像和文本编码器,主要目的是实现图文特征的匹配。其工作方式是分别提取文本和图片的嵌入值计算相似性,距离大则说明相似性低,图片和文本不相关。
4、DrawBench
在 Imagen 中,Google 提出 DrawBench,是一个全面且具有挑战性的文本生成图片模型评测基准。

DrawBench 基准包含 11 个类别的 200 个文本提示
针对各类别进行独立人工评估,评估员对两组模型A和B生成的图像进行评分。每组有8个随机生成结果。评分员需要回答:哪组图像质量更高,以及哪组图像与文本描述更匹配。每个问题都有三个选项:更喜欢A,无法确定,更喜欢B。

Figure 2 所示为评估的示例
四、常用模型
1、模型结构
图像生成任务通常由多个子模型组成,包括常见的 CNN、AutoEncoder、U-Net、Transformer等。其中,AutoEncoder 和 U-Net等模型相似,都是各种模型的主要组成部分。主要的差别在于AutoEncoder由编码器和解码器组成,可以单独使用,编码器压缩输入,比如把图像映射到隐空间,解码器用编码重构输入,即从隐空间恢复图像。而U-Net模型在编码器和解码器之间添加Skip Connection,使得解码器不仅依赖隐空间编码,还依赖输入,因此不能单独使用。

2、预训练模型
1)CLIP 模型
OpenAI的CLIP是一个强大的图文对齐模型,利用对比学习在海量图文数据对(4亿)上进行预训练。在训练过程中,将配对的图文特征视为正面,将图片特征与其他文本特征视为负面。由于其强大的表征能力,CLIP的文本和图像编码器常常被其他模型用于图像或文本编码。
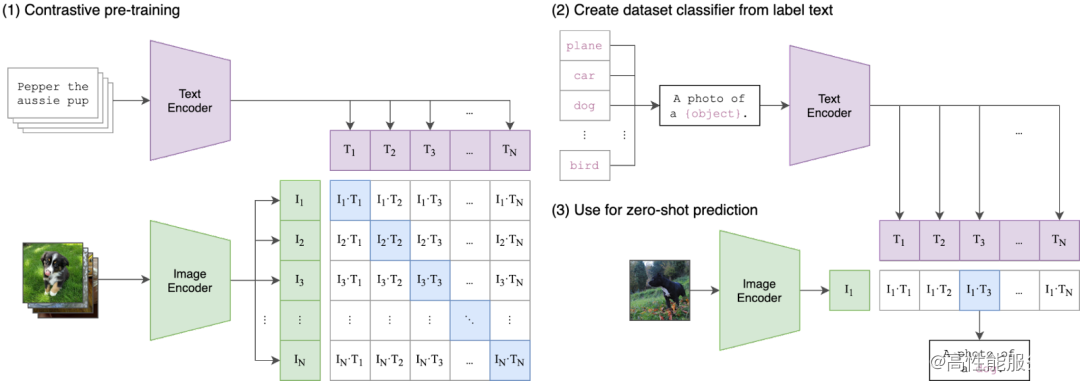
2)CoCa 模型
CoCa模型在CLIP模型基础上,增加多模态文本解码器。训练过程中,除使用原来CLIP模型对比损失,增加描述损失。

五、模型类型
1、VAE 系列
VAE系列模型发展从最初自编码器(AE)发展到变分自编码器(VAE),然后出现向量量化VAE(VQ-VAE)、VQ-VAE-2以及VQ-GAN、ViT-VQGAN和MaskGIT等。但这些通常只用于无条件生成或简单类别和图像条件,对文本输入支持能力不足。

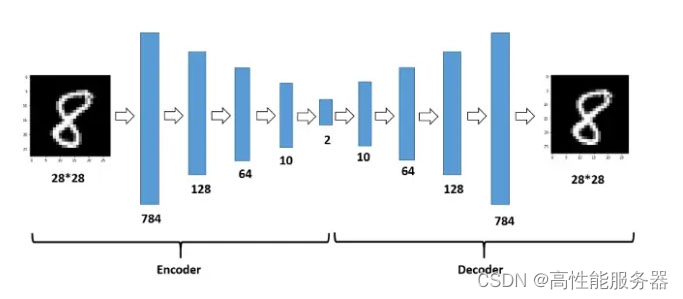
1)AE
自编码器(AE)是一种人工神经网络技术,用于实现无标签数据的有效编码学习。该过程涉及将高维度数据做低维度表示,进而实现数据压缩,因此主要应用于降维任务。AE主要由两部分组成:编码器(负责将输入数据编码,即压缩)和解码器(负责使用这些编码重构输入,即解压)。
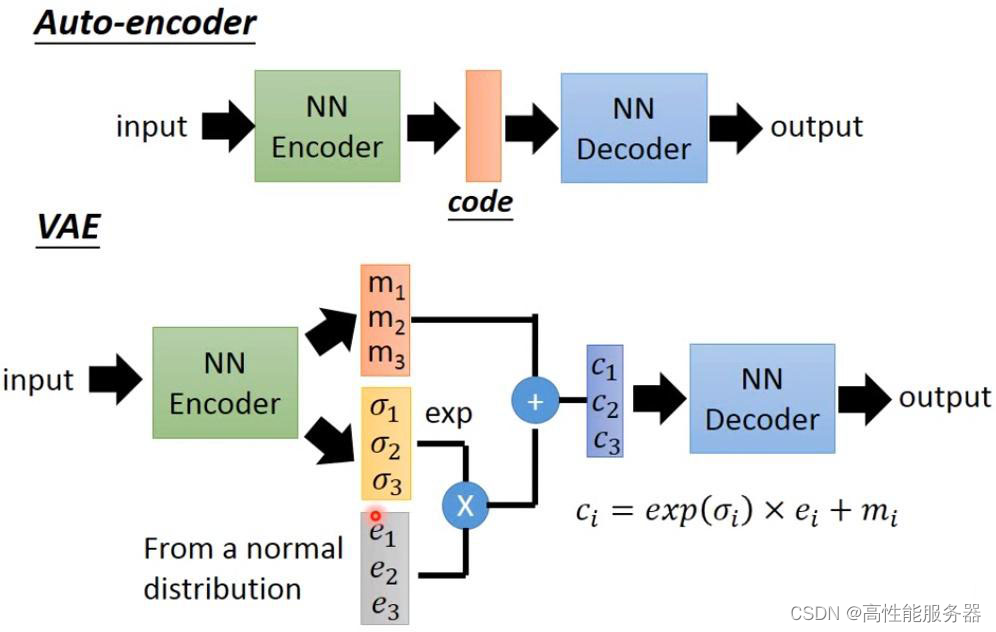
2)VAE
变分自编码器(VAE)在自编码器(AE)的基础上,引入概率生成模型思想,通过设置隐空间概率分布,生成多样样本,同时更好地理解数据的分布性质。
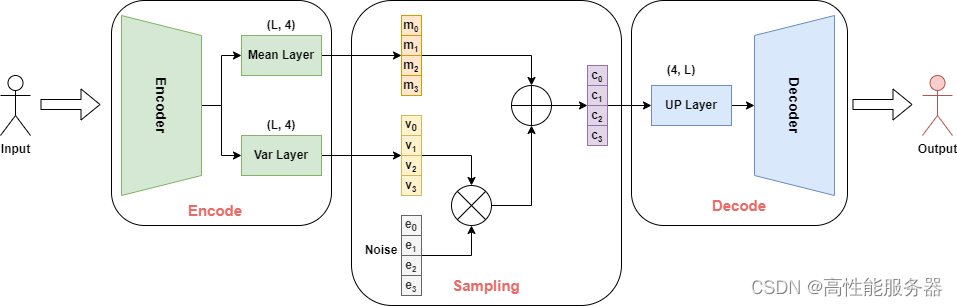
3)VQ-VAE
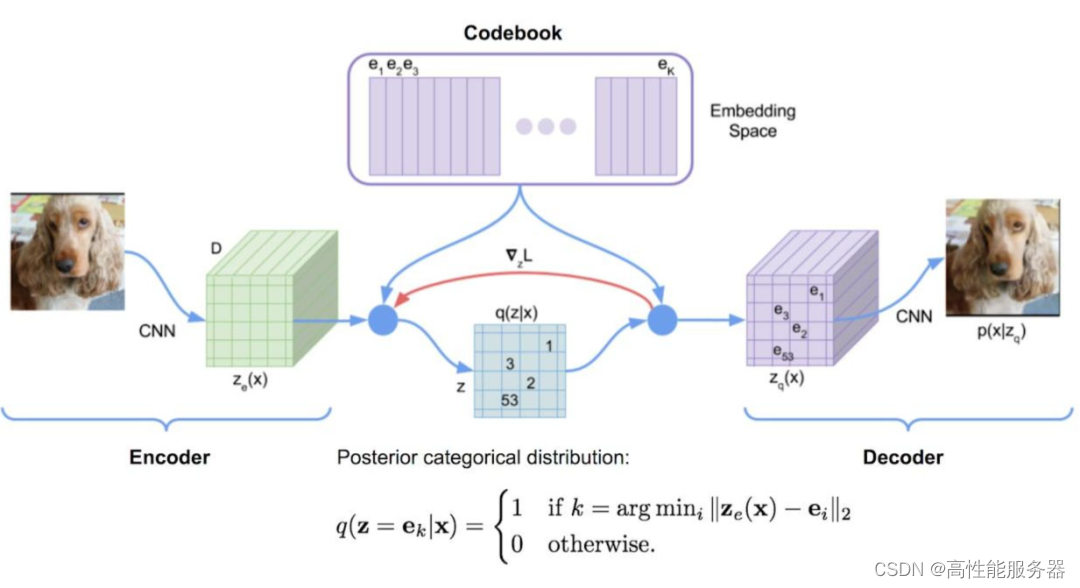
向量量化变分自编码器(VQ-VAE)在变分自编码器(VAE)基础上加入离散、可度量的隐空间表示形式,有利于模型理解数据中的离散结构和语义信息,同时可以避免过拟合。VQ-VAE与VAE的工作原理相通,只是在中间步骤中,没有学习概率分布,而是利用向量量化(VQ)学习代码书(Codebook)。
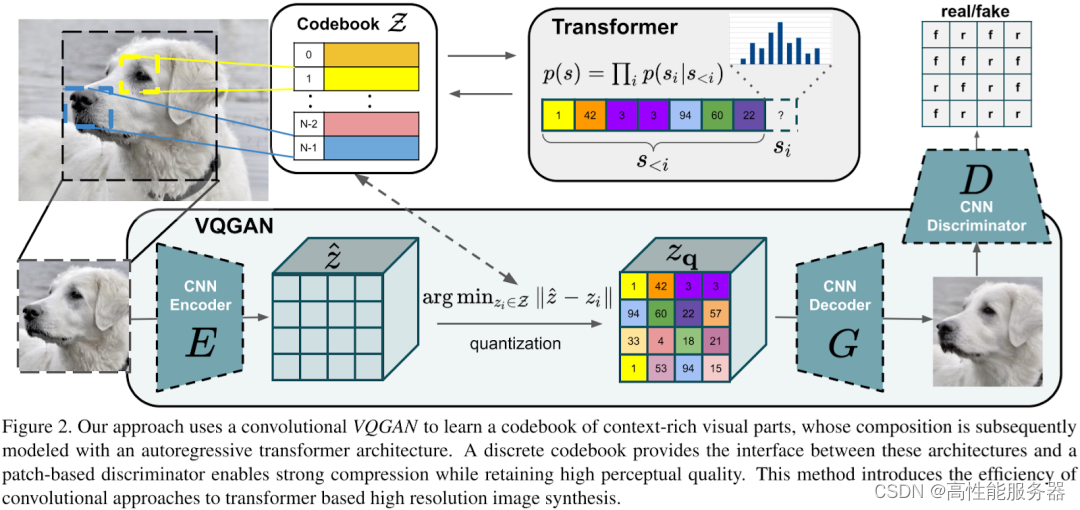
4)VQ-GAN
向量量化生成对抗网络(VQ-GAN)的主要改进是使用生成对抗网络(GAN)策略,将变分自编码器(VAE)作为生成器,并配合一个判别器对生成图像进行质量评估。该模型引入感知重建损失方案,不仅关注像素差异,同时也关注特征图差异,以此来生成更高保真度的图片,从而使学习的代码书更加丰富。
5) ViT-VQGAN
图像转换器 VQ-GAN (ViT-VQGAN)的模型结构保持VQGAN的基础结构,关键差异在于将编解码器的CNN框架切换为ViT模型。首先,编码器对每8x8像素块进行独立编码,从而产生1024个 token 序列。再者通过量化过程,这1024个token序列被映射到大小为8192的codebook空间。然后,解码器从1024个离散的潜在编码中复原原始图像。最后,自回归转换器被应用于生成离散潜在编码。训练期间,可以直接使用由编码器生成的离线潜在编码作为目标,计算交叉熵损失。

6)Parti
相较于VQ-GAN或ViT-VQGAN仅使用解码器(Decoder Only)形式的Transformer来生成离散的潜在编码,Parti的作者采取编码器+解码器(Encoder + Decoder)的模式。这样做的好处就在于可以使用编码器对文本进行编码,生成文本嵌入(Text Embedding),再将这个文本嵌入作为条件引入解码器中,通过交叉注意力机制(Cross Attention)与视觉Token产生交互。
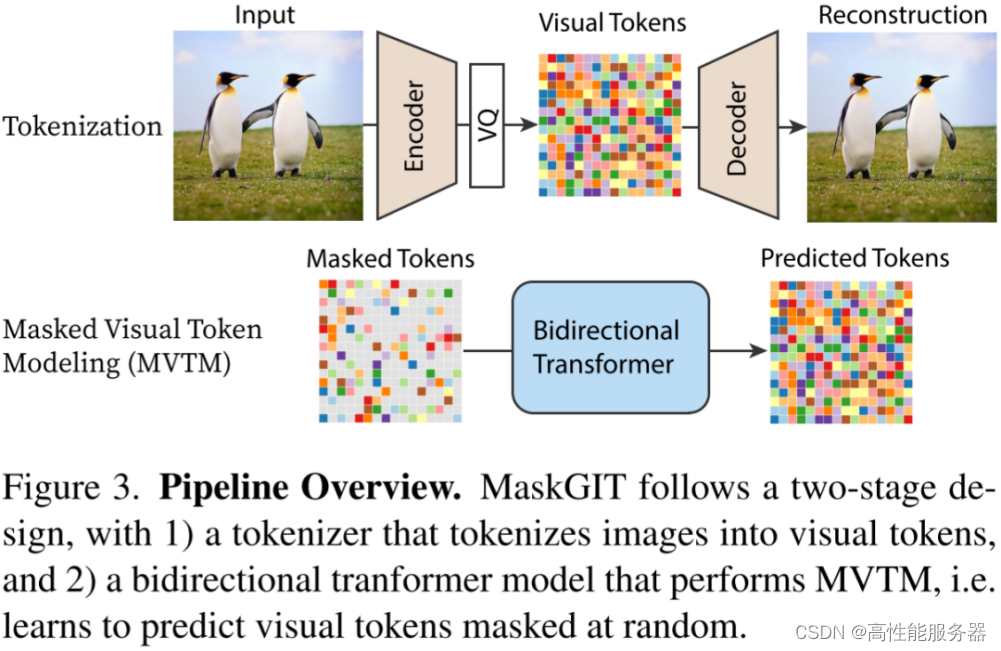
7)MaskGIT
MaskGIT模型采用VQGAN范式,但在实现上有所不同。VQGAN中的Transformer通过序列生成方式预测图像Token,一次只预测一个,效率不高。相比之下,MaskGIT采用蒙面视觉Token建模法(Masked Visual Token Modeling)进行训练,这种方法使用类似BERT的双向Transformer模型,训练时会随机遮挡部分图像Token,目标就是预测这些被遮挡的Token。

8)DALL-E
DALL-E训练过程和VQ-GAN相似,但DALL-E并未使用VQ-VAE,而是选择Discrete VAE(dVAE),其的总体概念相似。dVAE的主要不同之处在于引入Gumbel Softmax进行训练,有效避免VQ-VAE训练中由于ArgMin操作不能求导而产生的问题。

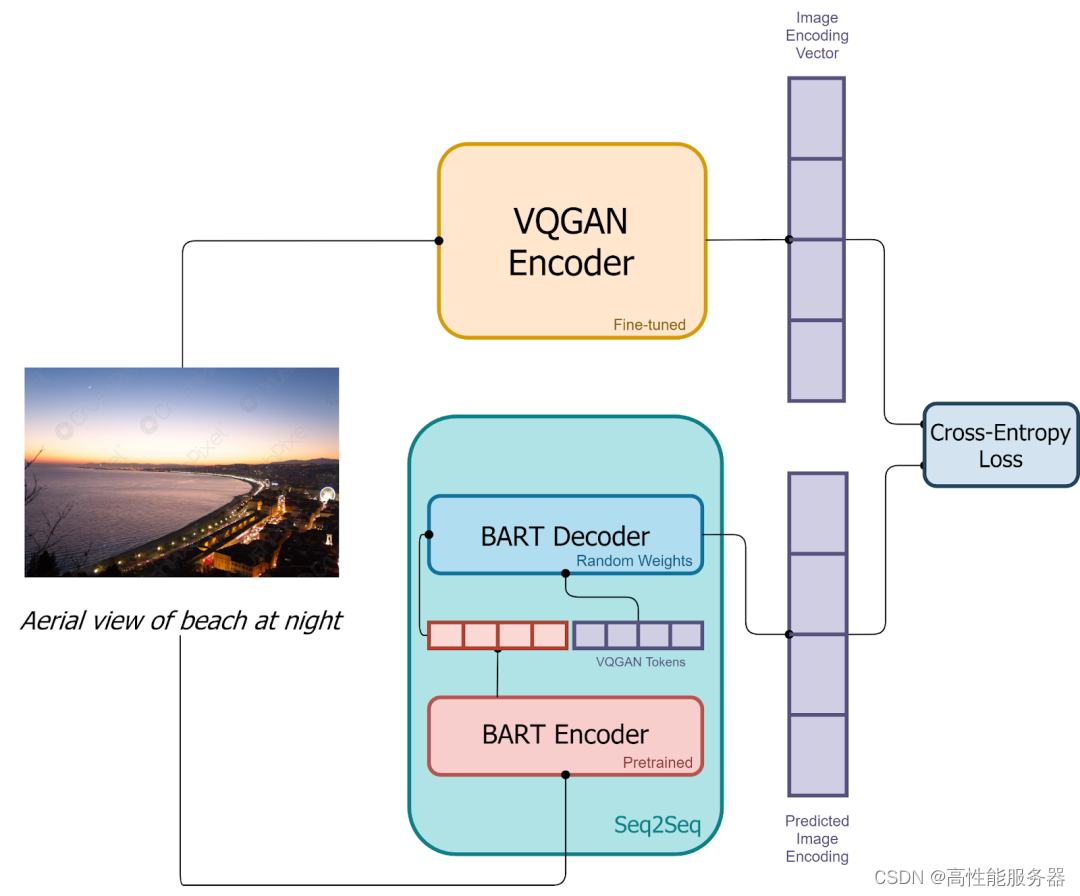
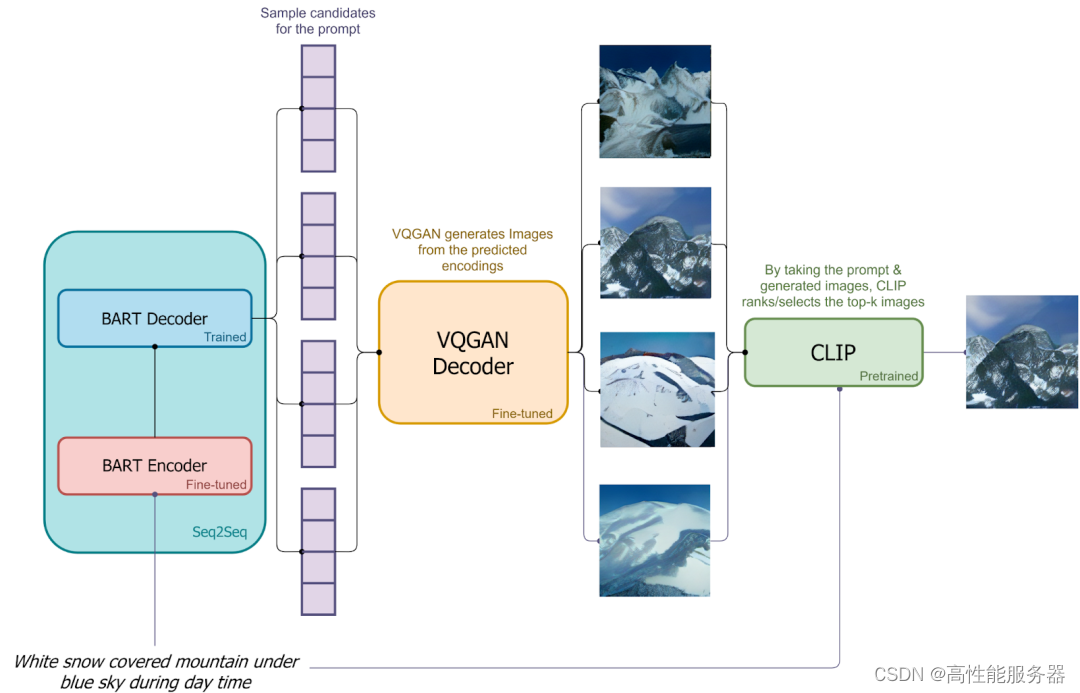
9)DALL-E mini
DALL-E mini是社区对DALL-E的开源复现。其使用VQ-GAN替代dVAE,用具有编码器和解码器的BART替代DALL-E中仅解码器的Transformer。此外,会用VQ-GAN的解码器生成多张候选图像,利用CLIP提取这些图像和文本嵌入,进行比较排序,以挑选出最匹配的生成结果。
10)VQGAN-CLIP
VQGAN-CLIP的实现思路直接明了,通过VQ-GAN将初始图像转化成一幅新图像,然后使用CLIP对这个生成图像以及目标文本提取embedding,计算它们之间的相似性,并将误差反馈到隐空间的Z-vector上进行迭代更新。

2、Diffusion 系列
Diffusion模型虽在2015年首次被提出,但因效果不佳未受到广泛关注。直到2020年06月OpenAI发布DDPM后,该模型才逐渐为人所知。Diffusion模型的发展路径主要包括OpenAI系列模型,Stable Diffusion系列模型,以及Google的Imagen和Imagen 2。
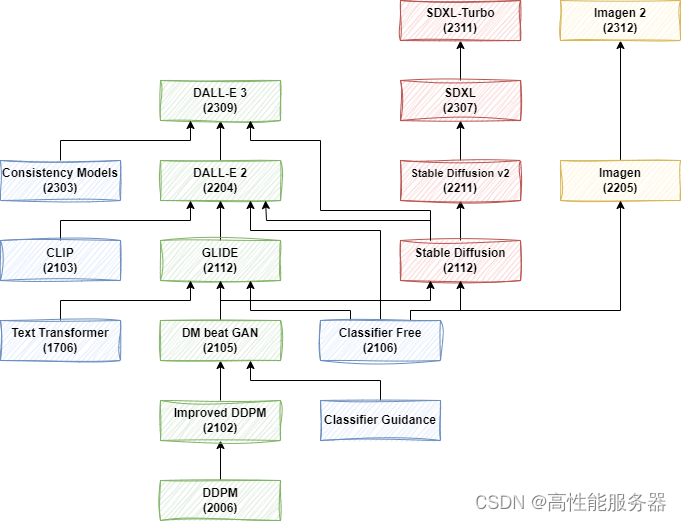
1)DDPM
在扩散模型中存在两个关键步骤:前向过程(或称为扩散过程)以及逆向过程。简单来说前向过程的要点在于不断向图片添加高斯噪声,而逆向过程的主旨则在于通过逐步去除高斯噪声以重建图像。

2)Diffusion Model Beat GANs
主要有两个亮点:首先对无条件图像生成中不同模型结构对生成效果的影响进行大量的消融实验验证。其次引入分类器引导以提升生成质量。
模型结构主要变动包括在保持模型大小不变的前提下增加深度、减小宽度,以及增加Attention头的数量,并扩大Attention的应用范围至16x16、32x32和8x8的分辨率上。结果表明,更多和更广泛的Attention应用范围以及采用BigGAN的residual block都可以帮助提升模型表现。这些工作不仅创建了一种新的模型--ADM(Ablate Diffusion Model), 为OpenAI后续的生成模型打下坚实基础,同时也为Stable Diffusion的模型开发提供参考。
3)GLIDE
在GLIDE模型中,将Diffusion模型应用于文本条件图像生成,主要包含两个子模型:
- 文本条件的扩散模型
由一个文本编码的变压器(1.2B,24个残差块,宽度2048)以及一个在Diffusion Model Beat GANs中的ADM(Ablated Diffusion Model)的扩散模型组成,后者的分辨率为64x64,参数为2.3B,宽度扩展至512通道,并在该基础上扩展文本条件信息。
- 文本条件+上采样模型
包括类似于前述文本变压器模型,但是宽度减少到1024,还有一种同样源自ADM-U的上采样模型,分辨率从64x64扩展到256x256,通道数从192扩展到384。
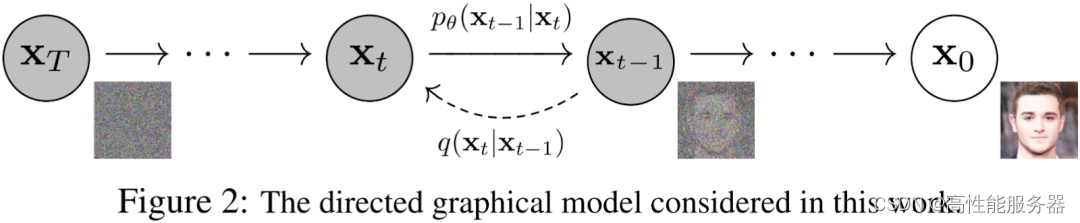
4)DALL-E 2
GLIDE模型对文本引导图像生成进行全新的尝试,并取得优秀成果。在这项工作中,利用强大的CLIP模型,构建一个两阶段图像生成模型,该模型主要由四个部分构成。
- 一个对应CLIP模型的图像编码器,其生成的图像嵌入在训练阶段被用做prior目标,要求prior生成嵌入尽可能与其相似。
- 一个在训练和生成阶段对文本编码的文本编码器,生成的嵌入作为prior的输入。
- prior根据这个嵌入生成图像嵌入。
- 根据图像嵌入生成最终图像解码器,其可以选择是否考虑文本条件。
在训练阶段,图像编码器和文本编码器保持不变,而在生成阶段则不再需要图像编码器。
5)DALL-E 3
OpenAI的DALL-E 3是一款先进的文生图模型,针对传统模型在遵循详细图像描述方面的不足进行优化。由于传统模型常常会忽略或混淆语义提示,为解决该问题,需要先训练一个图像描述器,并生成一组高度描述性的图像描述,用于训练文生图模型,从而显著提高模型的指令跟随能力。
DALL-E 3的图像解码器借鉴稳定扩散的实现,采用一个三阶段的隐扩散模型。其VAE和稳定扩散相同,都采用8倍的下采样,训练的图像分辨率为256x256,并生成32x32的隐向量。为处理时间步长条件,模型采用GroupNorm并学规模和偏差。对文本条件的处理,则是使用T5 XXL作为文本编码器,然后将输出的embedding和xfnet进行交叉注意。
6)Stable Diffusion(LDM)
LDM模型与其他扩散生成模型类似,主要由三个部分组成:
-自动编码器
包括编码器和解码器两部分。编码器主要用于生成目标z,而解码器则用于从潜在编码中恢复图像。
-调节部分
用于对各种条件信息进行编码,其生成的嵌入将在扩散模型U-Net中使用。不同的条件需利用不同的编码器模型以及使用方法。
-去噪U-Net
该部分主要用于从随机噪声zT生成潜在编码,然后利用解码器恢复图像。各种条件信息会通过交叉注意机制进行融合。

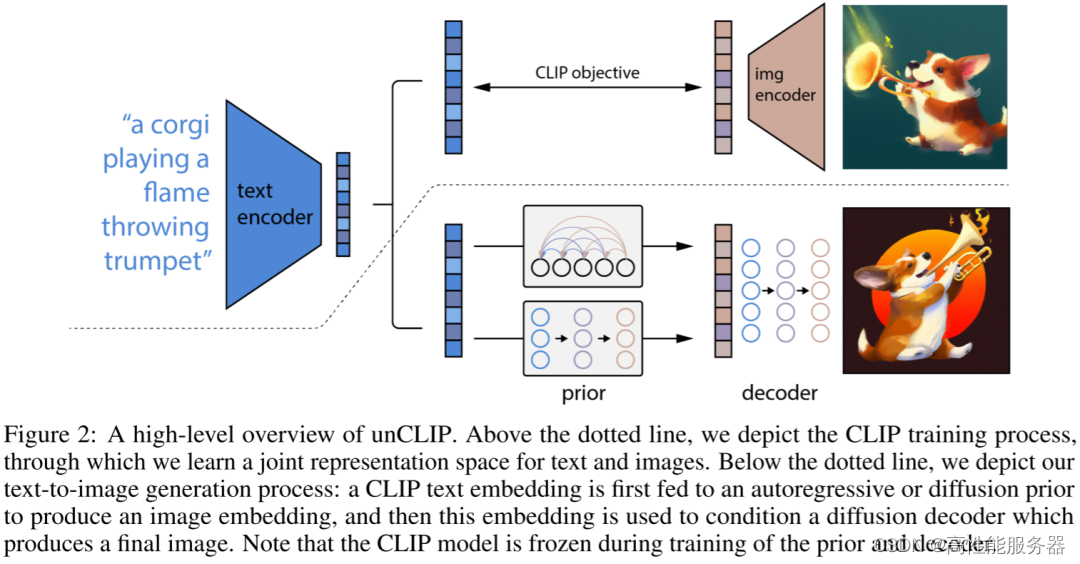
7)SDXL
SDXL模型针对SD模型作出一些关键的改进(总参数量为26亿,其中文本编码器有8.17亿的参数):
- 增加一个Refiner模型,用于进一步精细化图像。
- 使用两个文本编码器,即CLIP ViT-L和OpenCLIP ViT-bigG。
- 基于OpenCLIP的文本嵌入中添加一个汇集文本嵌入。

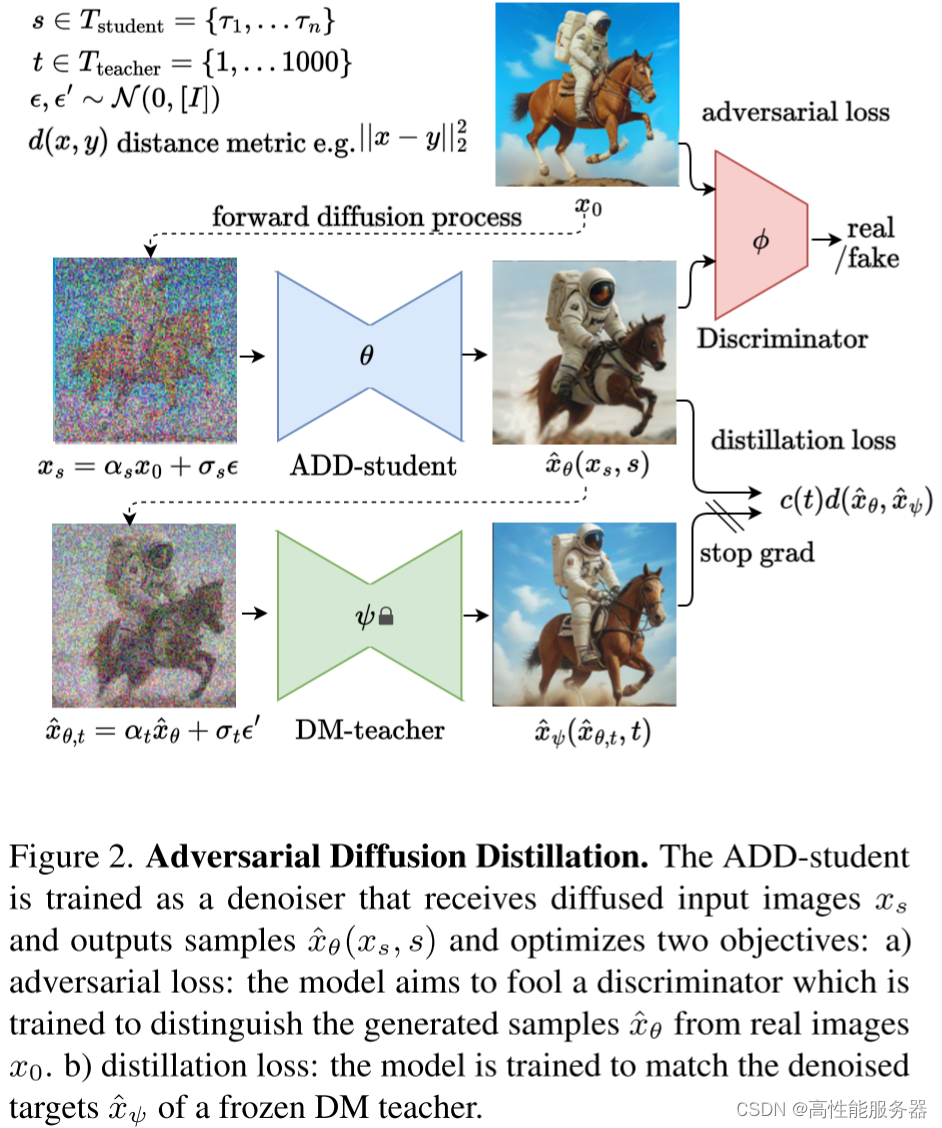
8)SDXL-Turbo
SDXL-Turbo模型的主要改进在于引入蒸馏技术减少生成步数并提升生成速度。其主要流程包括:
- 从Tstudent模型中选择步长s进行前向扩散,生成加噪图像。
- 使用学生模型对加噪图像进行去噪,得到去噪后的图像。
- 基于原始图像和去噪后的图像计算对抗损失。
- 从Tteacher模型中选择步长t对去噪后的图像进行前向扩散,生成新图像。
- 使用教师模型对新生成的图像进行去噪,得到新的去噪图像。
- 基于学生模型和教师模型的去噪图像计算蒸馏损失。
- 根据损失进行反向传播,注意教师模型不会进行更新。
9)Imagen
Google推出的Imagen模型是一个复杂且强大的基于扩散模型的文生图模型,能生成极其逼真的图像并深度理解语言。该模型主要由四个部分组成:
- Frozen Text Encoder
将文本进行编码得到嵌入,经过比较后,选择T5-XXL模型。
- Text-to-Image Diffusion Model
该模块使用U-Net结构的扩散模型,把步数t和前一步的文本嵌入作为条件,总共有20亿参数。
- 第一Super-Resolution Diffusion Model
采用优化过的高效U-Net,把64x64的图像超分为256x256的图像,用文本嵌入作为条件,总共有6亿参数。
- 第二Super-Resolution Diffusion Model
利用优化过的高效U-Net,将256x256的图像超分为1024x1024的图像,以文本嵌入作为条件,总共有4亿参数。
六、Guidance
1、Class Guidance
在Diffusion Model Beat GANs中,采用额外训练分类器的Classifier Guidance方式会增加复杂性和成本。这种方法有以下几个主要问题:
- 需要增训一个分类器,使生成模型训练流程变得更复杂。
- 必须在噪声数据上进行分类器的训练,无法使用已经预训练好的分类器。
- 在采样过程中,需要进行分数估计值和分类器梯度的混合,虚假地提高了基于分类器的指标,如FID和IS。
2、Class Free Guidance
Classifier Free Guidance的主要理念是不再采用图像分类器的梯度方向进行采样,而是同时训练有条件和无条件的扩散模型,并将他们的分数估计混合。通过调整混合权重,实现Classifier Guidance类似的FID和IS平衡。

在生成过程中,模型同时使用有条件和无条件生成,并通过权重w来调节二者的影响:
- 如果w值较大,那么有条件生成的作用就更大,因此生成的图像看起来更为逼真(IS分数更高)。
- 如果w值较小,那么无条件生成的作用就更为明显,从而生成的图像具有更好的多样性(FID分数更低)。

七、VQ-VAE 不可导
1、梯度拷贝
VQ-VAE和VAE结构相似,只是VQ-VAE在中间部分使用VQ(矢量量化)来学习码本,而非学习概率分布。然而,在VQ中为获取距离最小值,使用非微分的Argmin操作,就造成无法联合训练解码器和编码器的问题。为解决这个问题,可以采取直接将量化后的表示梯度复制到量化前表示,使其可以持续进行微分。
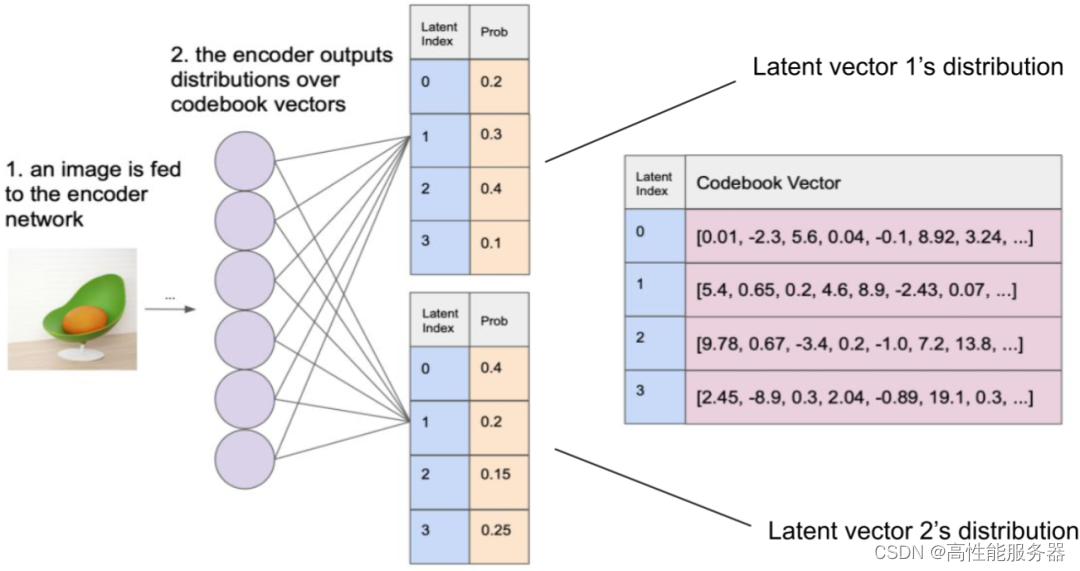
2、Gumbel Softmax
Gumbel Softmax是一种将离散采样问题转化为可微分操作的技巧,广泛应用于深度学习中的生成模型,如VAE和GAN等。Gumbel Softmax运用Gumbel分布来模拟离散分布的采样,具体来说,它生成一组噪声样本,然后用Softmax函数将这些样本映射为类别分布。
表现在图像中,一个图像经过编码器编码后会生成32x32个嵌入向量,与码本(8192个)进行内积,再经过Softmax函数处理,就落实每个码本向量的概率。
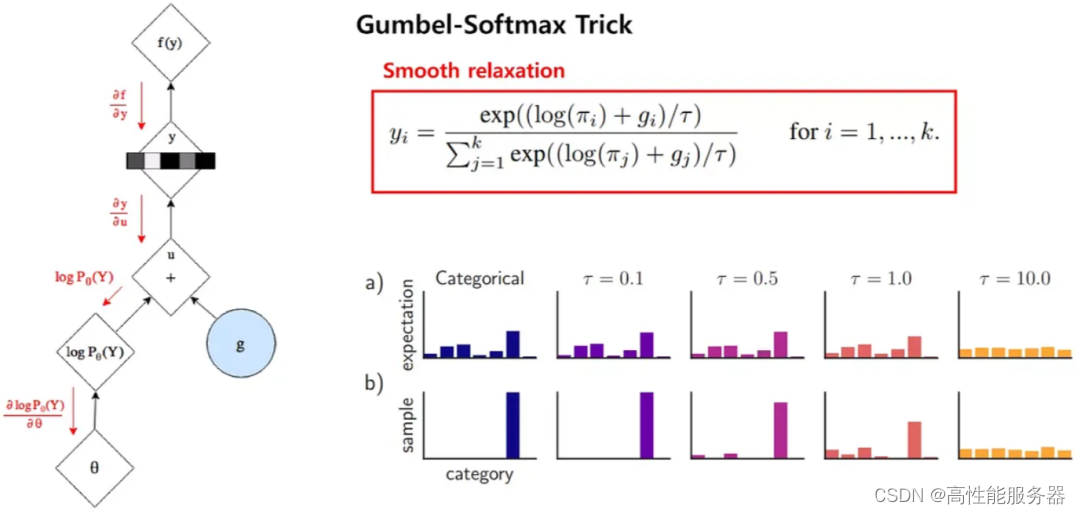
通过应用Gumbel Softmax采样,得到新的概率分布。再以此作为权重,累加对应的码本向量,获得潜在向量。然后,解码器基于潜在向量来重建输出图像。

上述过程中,使用Gumbel噪声实现离散采样,能够近似选择概率最大的类别,为处理离散采样问题提供一种可微分的解决方案。其中,gi是从Gumbel(0, 1)分布中得到的噪声,τ是温度系数。τ小的时候,Softmax函数更接近ArgMax,而τ大时,更接近于均匀分布。

八、扩大分辨率
1、图像超分
图像超分是提高图像分辨率的有效手段,被很多热门的图像生成模型,像Imagen、Parti、Stable Diffusion、DALL-E等所采用。就像图Figure A.4所展示,Imagen使用两个图像超分模型,将分辨率从64x64提升到256x256,然后再进一步提升到1024x1024。

2、多级 Latent code
在VQ-VAE-2模型中,采用多级潜在编码方案。以256x256的图像为例,在训练阶段,图像首先被编码压缩到64x64大小的底层,然后进一步压缩到32x32大小的顶层。重建阶段,32x32的表征通过VQ量化转换为潜在编码,然后通过解码器重建为64x64的压缩图像,再进一步通过VQ和解码器重建为256x256大小的图像。而在推理阶段,首先使用PixelCNN生成顶层的离散潜在编码,然后作为输入条件生成更高分辨率的底层离散潜在编码。

3、多级 Latent code + 图像超分
在Muse模型中,直接预测512x512分辨率的图像可能会过度关注低级细节,而采用级联模型更有效。模型首先生成16x16的潜在地图(对应256x256分辨率的图像),然后基于这个潜在地图使用超分模型采样到64x64的潜在地图(对应512x512分辨率的图像)。
训练分为两阶段,首先训练Base模型生成16x16的潜在地图;然后基于此训练超分模型,用于生成64x64的潜在地图和最终的512x512图像。

九、指令遵循
1、更大的 Text Encoder
在Imagen模型中,扩大语言模型的规模比增大图像扩散模型的规模更能提高生成样本的逼真度和图像-文本的对齐效果。

2、多个 Text Encoder
在SDXL模型中,为增强文本编码能力,采用两个文本编码器,具体来说,同时使用CLIP ViT-L和OpenCLIP ViT-bigG中的文本编码器。
3、数据增强
OpenAI的新模型DALL-E 3是一款文本生成图像模型,解决传统模型不能精准遵循图像描述和忽视或混淆语义提示的问题。

十、效率优化
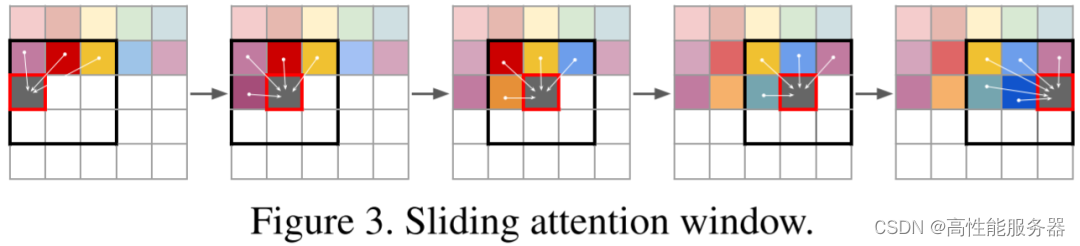
1、滑动窗口 Attention
在VQ-GAN模型中,自回归Transformer模型用于预测离散的latent code,然后通过解码器使用latent code恢复图像。通常离散latent code相比原始图像有16x16或8x8的压缩率。例如要生成一个分辨率为1024x1024的图像,相应的离散latent code为64x64。但是,由于Transformer模型的推理计算量与序列长度成二次方关系,计算量较大。具体来说,预测每个位置的code时只考虑局部code,而不是全局code,例如使用16x16的窗口,计算量将降低到原来的1/16。对于边界区域,将窗口向图像中心偏移,以保持窗口大小。
2、Sparse Transformer
在DALL-E中,采用参数量达到12B的Sparse Transformer,利用三种不同的注意力遮罩来加速推理过程。这些注意力遮罩保证所有的图像令牌都可以观察到所有的文本令牌,但只能观察到部分图像令牌。具体来说,行注意力用于(i-2)%4不等于0的层,如第2层和第6层,列注意力用于(i-2)%4等于0的层,如第1层和第3层,而卷积性注意力则仅在最后一层使用。
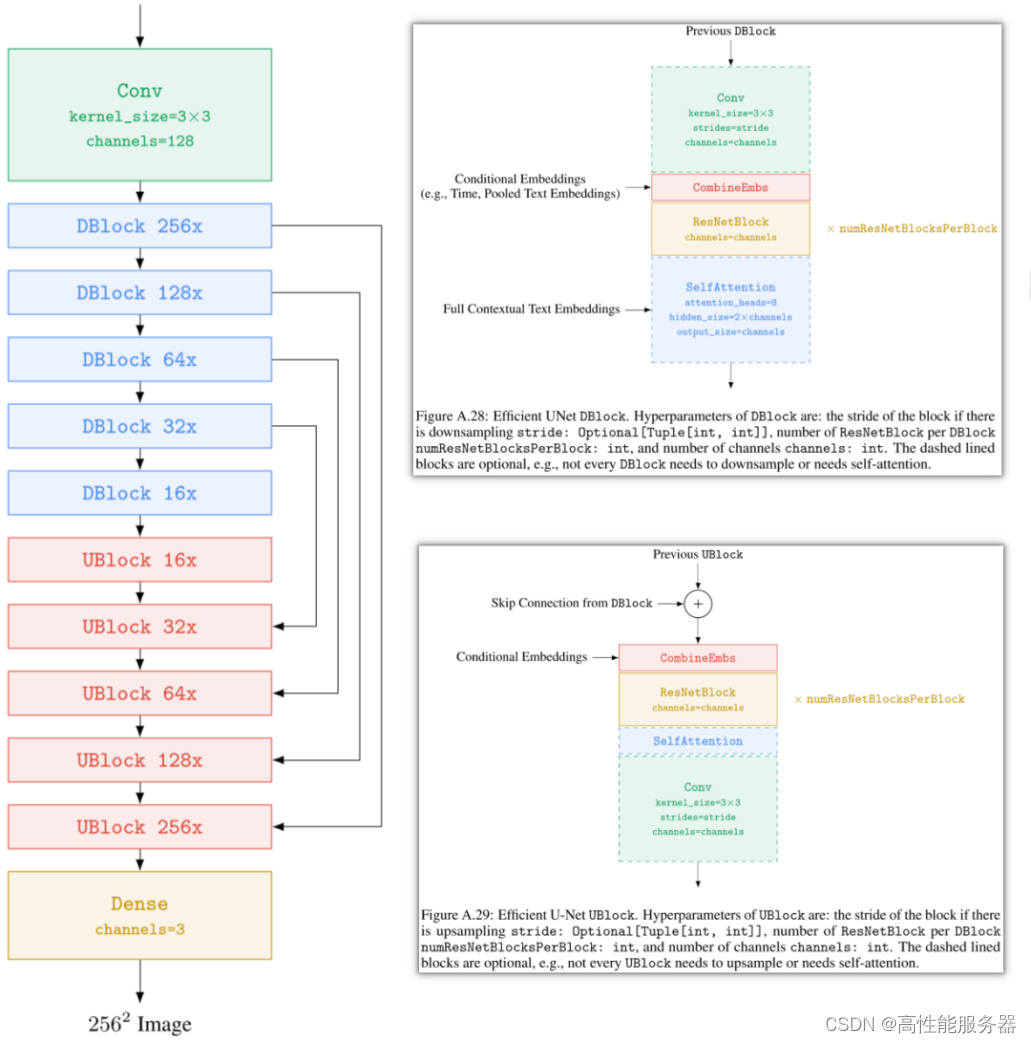
3、Efficient U-Net
在Imagen中,在两个超分辨模型中使用高效的U-Net。具体调整包括:在低分辨率添加更多残差块,将高分辨率的模型参数转移到低分辨率,从而增加模型容量,但无需更多计算和内存;使用大量低分辨率残差块时,将Skip connection缩放到1/sqrt(2),以提升收敛速度;将下采样和上采样块的顺序交换,以提高前向传播速度,且不降低性能。同时,在256x256至1024x1024的超分模型中,删除自注意力模块,仅保留交叉注意力模块。

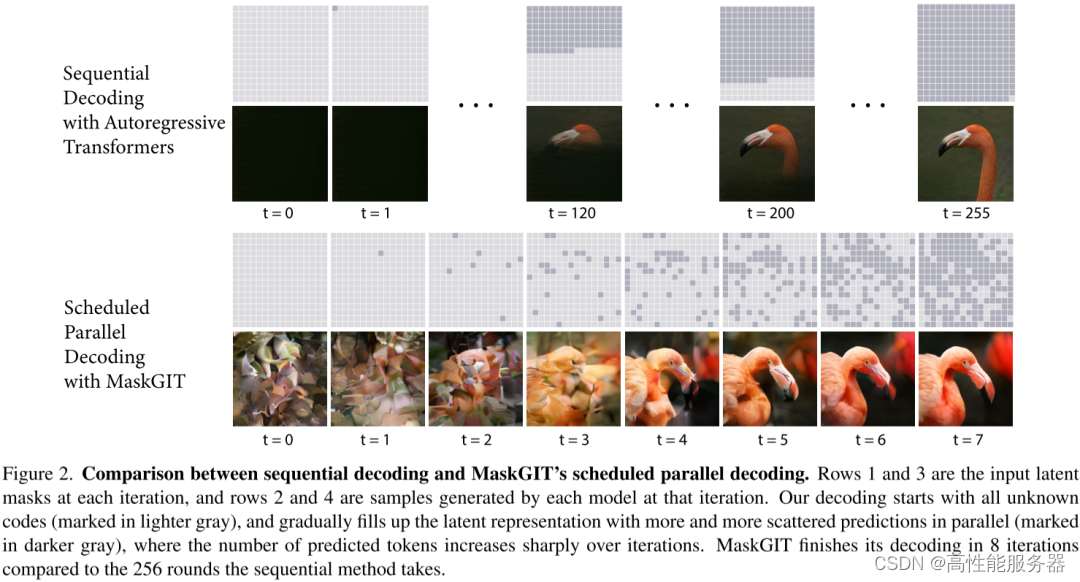
4、并行解码-推理效率
Google在图像生成模型MaskGIT和Muse中采用并行解码的策略,与VQGAN中使用的序列解码方式不同,该并行解码方案只需要8个解码步骤就能生成16x16=256个图像token,相比之下,VQGAN需要256次解码才能生成同样数量的token。

并行解码过程主要包括四个步骤:
- Predict
给定一个遮罩的token序列(已确定的token未被遮罩,待生成的token被遮罩)的情况下,预测每个token位置可能的token概率。
- Sample
在每个遮罩的token位置执行采样,采样后的概率直接作为token的置信度,而已生成的token的置信度则为1。
- Mask Schedule
根据遮罩调度函数、当前步数、总步数以及总token数,计算当前需要采纳的token数。
- Mask
根据Sample步骤获得的置信度以及Mask Schedule步骤得到的待采纳的token数,对置信度进行排序,并采纳置信度最高的token。
5、子图训练-训练效率
当前图像生成模型处理的图像越来越大,计算量因此呈指数级增长,同时需要在大型数据集上进行训练,进一步增大成本。因此一些优化方案应运而生。例如,在LDM中利用全卷积网络支持可变分辨率的特性,选择在较小分辨率上训练,但在推理时应用在较大分辨率。此外,如Imagen和DALL-E 2等后续工作也采用相似策略,主要应用在超分辨模型。以Imagen为例,在训练超分辨模型时,移除自注意力功能,仅在文本嵌入融合时使用交叉注意力;同时,从高分辨率图像中裁剪出低分辨率的子图进行训练,从而大大提高效率。
6、Denoising蒸馏-推理效率
由于扩散模型需要大量迭代来生成满意结果,对资源消耗极大,因此有研究者试图减少生成步骤以提高生成速度。例如,DPM Solver通过大幅降低迭代步数,实现4到16倍的加速。OpenAI的Consistency Models进一步将迭代步数降至1到4步,其后的LCM和LCM-LoRA(Latent Consistency Models)也沿用这一策略。在SDXL-Turbo中,将迭代步数进一步减至1到4步甚至只需要1步,也可以得到优秀的生成结果。在与各种蒸馏方案的比较中,作者的方法在只需一步的情况下就能获得最优的FID和CLIP得分。

十一、局限性
1、场景内文本
DALL-E 2的作者发现模型在图像生成正确文本方面存在问题,可能是由于BPE文本编码的问题。然而,Google的Parti和Imagen 2已经比较有效地解决了这个问题。

2、细节、空间位置、属性关联
模型在处理物体的细节和空间关系时,往往出现错误且容易混淆不同物体。例如,处理手指细节时常有错误;在设计lion和giraffe在电视里的任务时,位置未能准确控制;在请求将长凳设置为白色时,钢琴也被误设为白色;要求车门为白色时,错误地在引擎盖等位置生成白色。

在DALL-E 2中,如图Figure 15所示,模型可能会混淆不同物体的颜色,如在“创建一个红色的方块在蓝色的方块之上”的任务上,无法完成颜色属性的准确赋予。另外,模型可能在重建对象的相对大小关系上存在问题,这可能是由于使用CLIP模型的影响。
十二、其他
1、BSR 退化
许多模型在超分模型训练中采用BSR退化技术,如Stable Diffusion和DALL-E 2等模型。BSR退化流程包括JPEG压缩噪声、相机传感器噪声,下采样的不同图像插值方法,以及高斯模糊核和高斯噪声,这些处理按随即顺序对图像进行应用。具体的退化方式和顺序可以在提供的代码链接中找到。
2、采样+排序
模型在生成图像的过程中都有一定随机性,因此每次采样生成的图像可能不一样,因此就有工作尝试每次多生成几个图像,然后挑选和文本最匹配的输出,比如 DALL-E mini,每次都生成多个图像,然后通过 CLIP Score 获得最匹配的一个。
在 DALL-E 2 中,为提升采样阶段的生成质量,会同时生成两个图像 embedding zi,然后选择一个与文本 embedding zt 内积更大的(相似性更高)使用。
3、多分辨率训练
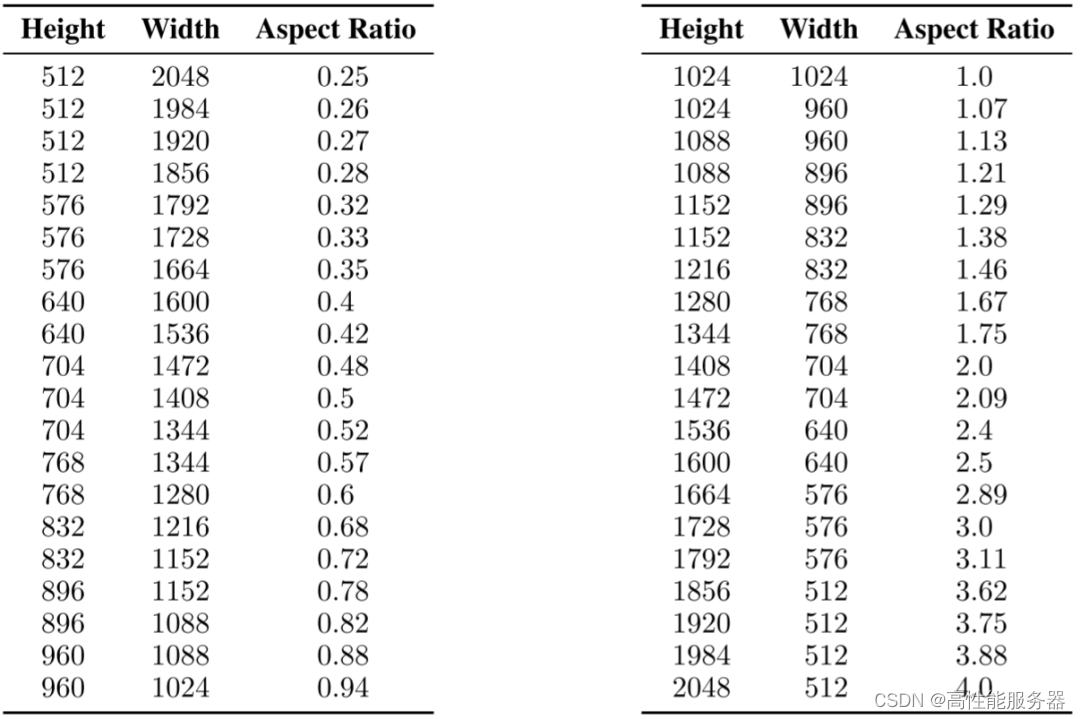
在SDXL中,对模型进行微调,以适应不同的长宽比,应对真实世界图像的多样性。首先将数据划分为不同长宽比的桶,保证总像素接近1024x1024,同时高宽需是64的整数倍。在训练时,每次从相同类型的桶里选择一个批次,并在不同的桶中轮流进行。还将桶的高度和宽度(h, w)作为条件,通过傅立叶编码后,添加到时间步骤嵌入中。
蓝海大脑集成Stable Diffusion PC集群解决方案
AIGC和ChatGPT4技术的爆燃和狂飙,让文字生成、音频生成、图像生成、视频生成、策略生成、GAMEAI、虚拟人等生成领域得到了极大的提升。不仅可以提高创作质量,还能降低成本,增加效率。同时,对GPU和算力的需求也越来越高,因此GPU服务器厂商开始涌向该赛道,为这一领域提供更好的支持。在许多领域,如科学计算、金融分析、天气预报、深度学习、高性能计算、大模型构建等领域,需要大量的计算资源来支持。为了满足这些需求,蓝海大脑PC集群解决方案应运而生。
PC集群是一种由多台计算机组成的系统,这些计算机通过网络连接在一起,共同完成计算任务。PC集群解决方案是指在PC集群上运行的软件和硬件系统,用于管理和优化计算资源,提高计算效率和可靠性。
蓝海大脑PC集群解决方案提供高密度部署的服务器和PC节点,采用机架式设计,融合PC高主频和高性价比以及服务器稳定性的设计,实现远程集中化部署和便捷运维管理。采用模块化可插拔设计,简化维护和升级的流程。有效降低网络延迟,提高游戏的流畅性。GPU图像渲染加速,减少画面卡顿和延迟。同时动态调度算法,实现负载均衡;大幅降低运营成本。高品质的游戏体验增加用户的粘度,大大提升游戏运营商收益。
同时,集成Stable Diffusion AI模型,可以轻松地安装和使用,无需进行任何额外的配置或设置。与传统的人工创作方式相比,Stable Diffusion Al模型可以更快地生成高品质的创作内容。通过集成这个模型,可以使创作者利用人工智能技术来优化创作流程。另外,蓝海大脑PC集群解决方案还具有开箱即用的特点,不仅易于安装和使用,而且能够快速适应各种创作工作流程。这意味着用户可以在短时间内开始创作,并且在整个创作过程中得到更好的体验。

一、客户收益
Stable Diffusion技术对游戏产业带来了极大的影响和改变。它提升了游戏图像的质量和真实感、增强了游戏体验和沉浸感、优化了游戏制作流程、扩展了游戏应用领域,并推动了游戏产业的发展和创新。这些都表明,Stable Diffusion技术在游戏产业中的应用前景十分广阔,有助于进一步推动游戏行业的发展,提高用户体验和娱乐价值。
1、提升游戏图像质量和真实感
Stable Diffusion可以在保证渲染速度的前提下,提高游戏图像的细节和真实感。传统的光线追踪方法需要检查和模拟每条光线,这样会消耗大量计算资源,并放缓渲染速度。而Stable Diffusion则利用深度学习技术对光线的扩散过程进行建模,使得处理数百万条光线所需的计算时间更短,同时还能够生成更为精准的光线路径。这意味着,Stable Diffusion可以让计算机产生更加逼真的景观、人物、物品等元素,在视觉效果上得到质的飞跃。
2、增强游戏体验和沉浸感
游戏是一个交互式体验,它的目标是尽可能地让玩家沉浸到虚构的世界中。Stable Diffusion可以使游戏环境变得更加真实,并增添一些更具有交互性和观赏性的场景。例如,利用Stable Diffusion技术,游戏可以在水面上添加波纹、落叶,或者使摇曳的草丛更逼真。这些改善能够让玩家更好地感受游戏中所处的环境,增强沉浸感。
3、优化游戏制作流程
Stable Diffusion的应用可以提高游戏开发的效率和质量,减少手动制作和修改的工作量。渲染过程的快速执行还可以加速开发周期,甚至使一些在过去被看做是计算机图形学难题的事情变得可能。例如,在模拟复杂的自然现象或在大范围内生成游戏元素时,使用Stable Diffusion可有效降低游戏开发的成本和时间,让开发者有更多的精力关注其他方面的设计和创意。
4、扩展游戏的应用领域
Stable Diffusion的应用使得游戏在更多的领域得到应用。例如,在心理治疗、教育、文化传播等领域中,人工智能游戏可以根据用户的情绪和行为变化来调整游戏内容和策略,为用户提供更符合需求和娱乐性的游戏体验。此外,利用Stable Diffusion技术,游戏可以生成不同类型的场景,包括虚拟现实和增强现实等体验,开发出更丰富更多变的游戏内容。
5、推动游戏产业的发展和创新
Stable Diffusion作为先进的计算机图形学技术之一,进一步推动了游戏产业的发展和创新。利用人工智能技术渲染的游戏将会产生更高品质、更广泛的游戏类别,从而吸引更多领域的玩家参与,并且会推动相关行业的发展,如文化传媒行业、数字娱乐业等。同时,稳定性更好、性能更高的Stable Diffusion技术还具有在未来制造更复杂的虚拟世界的潜力,例如更多样化、更逼真、更具交互性的虚拟现实环境和游戏。
二、PC集群解决方案的优势
1、高性能
PC集群解决方案可将多台计算机的计算能力整合起来,形成一个高性能的计算系统。可支持在短时间内完成大量的计算任务,提高计算效率。
2、可扩展性
可以根据需要进行扩展,增加计算节点,提高计算能力。这种扩展可以是硬件的,也可以是软件的,非常灵活。
3、可靠性
PC集群可以通过冗余设计和备份策略来提高系统的可靠性。当某个节点出现故障时,其他节点可以接管其任务,保证计算任务的顺利进行。
4、低成本
相比于传统的超级计算机,PC集群的成本更低。这是因为PC集群采用的是普通的PC硬件,而不是专门的高性能计算硬件。
三、PC集群解决方案的应用领域有哪些?
PC集群是指将多台个人电脑连接在一起,通过网络协同工作,实现高性能计算的一种方式。它的应用领域非常广泛,以下是一些常见的应用领域:
1、科学计算
PC集群可以用于各种科学计算,如天文学、生物学、物理学、化学等领域的计算模拟和数据分析。
2、工程计算
PC集群可以用于工程领域的计算,如飞机设计、汽车设计、建筑结构分析等。
3、金融计算
PC集群可以用于金融领域的计算,如股票交易、风险评估、投资组合优化等。
4、大数据处理
PC集群可以用于大数据处理,如数据挖掘、机器学习、人工智能等领域的数据处理和分析。
5、图像处理
PC集群可以用于图像处理,如视频编码、图像识别、虚拟现实等领域的图像处理和渲染。
四、常用配置推荐
1、处理器CPU:
i9-13900 24C/32T/2.00GHz/32MB/65W
i7-13700 16C/24T/2.10GHz/30MB/65W
i5 13400 10C/16T/1.80GHz/20MB/65W
i3 13100 4C/8T/3.40GHz/12MB/60W
G6900 2C/2T/3.40GHz/4MB/46W
G7400 2C/4T/3.70GHz/6MB/46W
i3 12100 4C/8T/3.30GHz/12MB/60W
i5 12400 6C/12T/2.50GHz/18MB/65W
i7 12700 12C/20T/2.10GHz/25MB/65W
i9 12900 16C/24T/2.40GHz/30MB/65W
2、显卡GPU:
NVIDIA RTX GeForce 3070 8GB
NVIDIA RTX GeForce 3080 10GB
NVIDIA RTX GeForce 4070 12GB
NVIDIA RTX GeForce 4060Ti 8GB or 16GB
3、内存:
32GB×2
4、系统盘:
M.2 500GB
5、数据盘:
500GB 7200K