
- 1【三维重建】【SLAM】SplaTAM:基于3D高斯的密集RGB-D SLAM(CVPR 2024)
- 2基于YOLO V8的车牌识别_yolov8车牌识别
- 3web3描述以太坊与区块链之间的操作关系_区块链和以太坊的关系
- 4flask服务中如何request获取请求的headers信息_flask读取header
- 5作为程序员, 我如何使用ChatGPT来帮我写代码_chatgpt 辅助写代码
- 6LLMs之Llama3:Llama 3的简介、安装和使用方法、案例应用之详细攻略_meta llama 3 入门
- 7hive和hadoop版本对应关系_hadoop和hive版本
- 8gitgit did not exit cleanly (exit code 128)处理方式_git did not exit cleanly code128
- 9Hutools 常用方法--持续更新中
- 10【2024软件测试面试必会技能】adb命令操作_adb断开设备命令
【二叉树】详解 树的遍历 (前序/中序/后序/层序) (递归+迭代)_什么叫逆中序遍历
赞
踩
目录
1.1 树的深度优先遍历 (Depth-First Traversal)
1.1.1 前序遍历 (Preorder Traversal)
1.1.2 中序遍历 (Inorder Traversal)
1.1.3 后序遍历 (Postorder Traversal)
1.2 广度优先遍历 (Breadth-First Traversal)
1.2.1 树的层次遍历 (Levelorder Traversal)
1.3 迭代和递归 (Iteration and Recursion)
一、树的遍历 - 介绍 (Introduction)
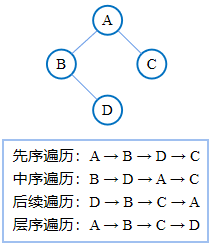
对一个数据集中的所有数据项进行访问的操作称为 遍历 (Traversal)。在 线性 数据结构中 (如 数组、链表),对其所有数据项的访问比较简单直接,按照顺序依次进行即可。而 树 作为典型的 非线性 数据结构,使得遍历操作较为复杂。以下将按照对节点访问次序的不同来区分遍历方式。
1.1 树的深度优先遍历 (Depth-First Traversal)
1.1.1 前序遍历 (Preorder Traversal)
先访问 根节点,再递归地前序访问 左子树、最后前序访问 右子树,如下所示:
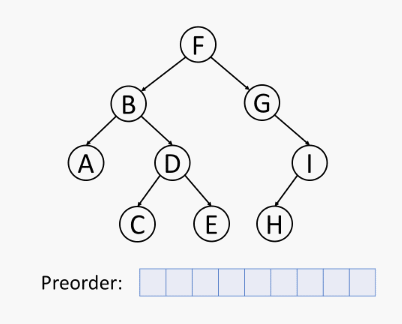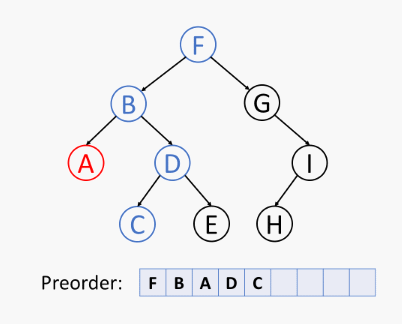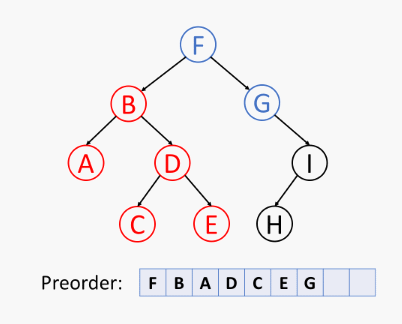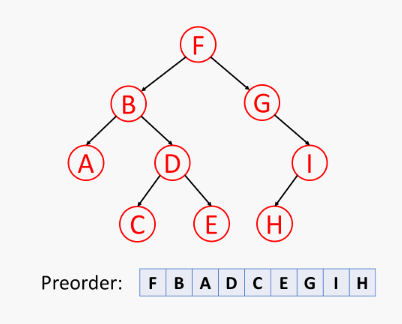
树的前序遍历伪代码 (树 T 在位置 p 的前序遍历算法):
- Algorithm preorder(T, p):
- perform the "visit" action for position p
- for each child c in T.children(p) do
- preorder(T, c) {recursively traverse the subtree rooted at c}
二叉树的前序遍历递归表示:
- # Python implementation
- def preorder(tree):
- if tree:
- print(tree.getRootVal()) # one of so called "visit" actions
- preorder(tree.getLeftChild())
- preorder(tree.getRightChild())
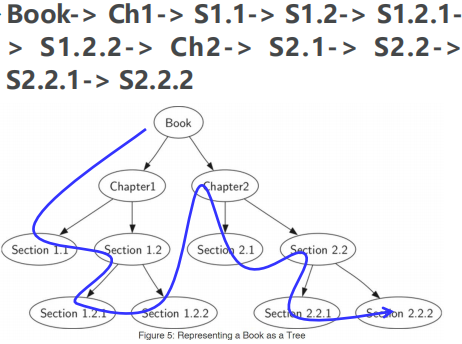
常见应用:将一本书的各章节表示为树,那么通过 前序遍历 即可表示出正确的阅读顺序。
1.1.2 中序遍历 (Inorder Traversal)
事实上,一般树的标准前序、后序和广度优先遍历都能直接应用于二叉树中,而 中序遍历算法则专门应用于二叉搜索树。
先递归地中序访问 左子树,再访问 根节点,最后中序访问 右子树,如下所示 (节点元素经过特意设计):
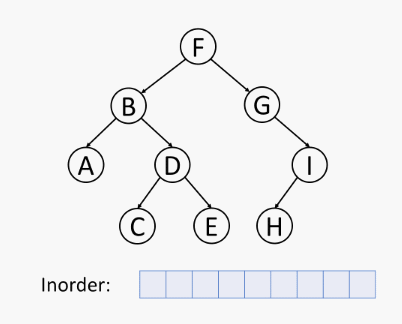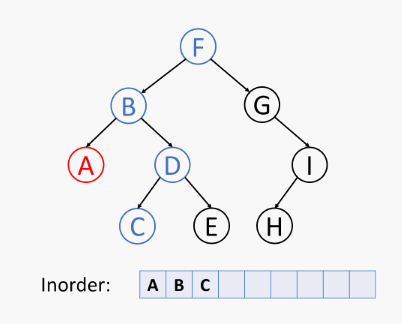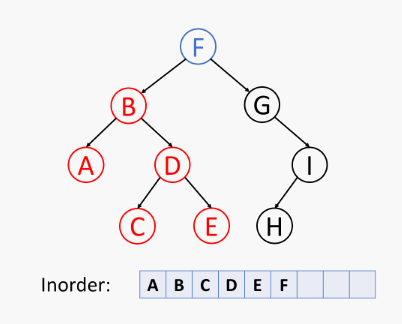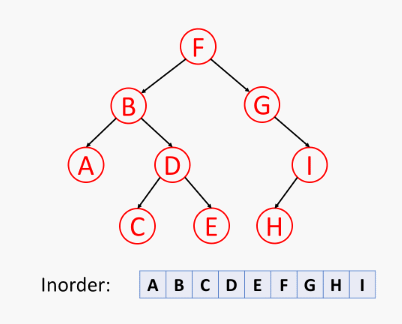
二叉树的中序遍历伪代码 (在位置 p 的中序遍历算法):
- Algorithm inorder(p):
- if p has a left child lc then
- inorder(lc) {recursively traverse the left subtree of p}
- perform the "visit" action for position p
- if p has a right child rc then
- inorder(rc) {recursively traverse the right subtree of p}
二叉树的中序遍历递归表示:
- def inorder(tree):
- if tree != None: # equals to "if tree:"
- inorder(tree.getLeftChild())
- print(tree.getRootVal()) # one of so called "visit" actions
- inorder(tree.getRightChild())
常见应用:采用中序遍历递归算法 生成全括号中缀表达式。

通常,对于 二叉搜索树,可以通过中序遍历得到一个 递增序列;反之,通过逆中序遍历将得到一个递减序列。这将在另一张卡片(数据结构介绍 – 二叉搜索树)中再次提及。
1.1.3 后序遍历 (Postorder Traversal)
先递归地后序访问 左子树,再后序访问 右子树,最后访问 根节点,如下所示:
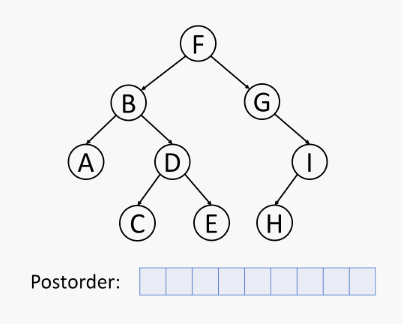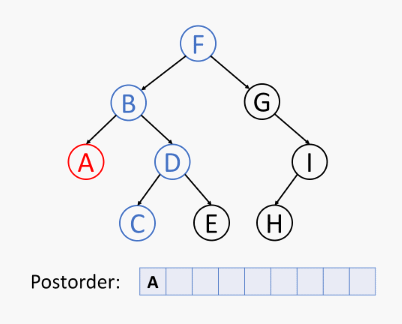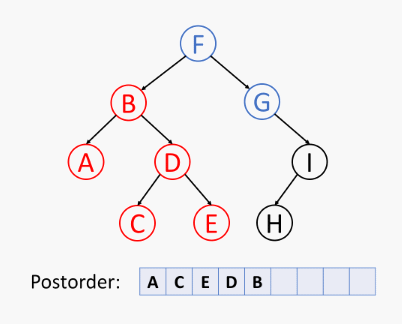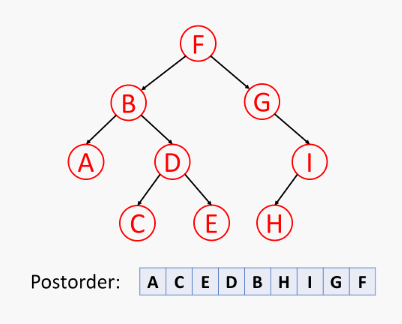
树的后序遍历伪代码 (树 T 在位置 p 的后序遍历算法):
- Algorithm postorder(T, p):
- for each child c in T.children(p) do
- postorder(T, c) {recursively traverse the subtree rooted at c}
- perform the "visit" action for position p
二叉树的后序遍历递归表示:
- # Python implementation
- def postorder(tree):
- if tree:
- preorder(tree.getLeftChild())
- preorder(tree.getRightChild())
- print(tree.getRootVal()) # one of so called "visit" actions
从某种程度上,后序遍历算法可以看做相反的前序遍历。因为它优先遍历子树的根,即先从 child 的根开始,然后访问才访问根 (因此称为后序) 。
注意,当删除树中内部节点 (非外部/叶子节点) 时,删除过程将按照后序遍历的顺序进行。换言之,删除一个节点时,将首先删除它的左、右节点,然后再删除节点自身。
另外,后序在数学表达中被广泛使用。 编写程序来解析后缀表示法更为容易 (表达式解析树求值),例如:
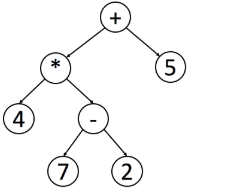
可以用中序遍历轻松找出原始表达式。 但是程序处理这个表达式时并不容易,因为必须检查操作的优先级。
如果想对该树进行后序遍历,使用栈 (stack) 来处理表达式会更容易。每遇到一个操作符,就可以从栈中弹出 (pop) 栈顶的两个元素,然后计算并将结果压入 (push) 栈中。
常见应用:采用后序遍历递归算法实现 表达式解析树求值。

1.2 广度优先遍历 (Breadth-First Traversal)
1.2.1 树的层次遍历 (Levelorder Traversal)
访问树的某位置时,前序遍历和后序遍历是常见的方法,中序遍历则是二叉树的特有方法,这些均属于 深度优先遍历。因此,相应存在 广度优先遍历 (层次遍历)。对树的广度优先遍历而言,其在访问深度 d+1 的位置之前,先访问深度 d 的位置。
广度优先遍历广泛应用于游戏软件上, 在游戏 (或计算机)中,博弈树 代表了可选择的一些动作,树根是游戏的初始配置或状态。例如,下图展示了井字棋的部分博弈树 (蓝色数字代表广度优先遍历的访问顺序):

之所以常执行这样一个博弈树的广度优先遍历,是因为计算机无法在有限的时间内去挖掘完整的博弈树。所以计算机要考虑所有动作,然后在允许的计算时间内对这些动作进行反馈。
树的广度优先遍历伪代码 (树 T 的 BFT 算法):
- Algorithm breathfirst(T):
- Initialize queue Q to contain T.root()
- while Q not empty do
- p = Q.dequeue() {p is the oldest entry in the queue}
- preform the "visit" action for position p
- for each child c in T.children(p) do
- Q.enqueue(c) {add p's children to the end of the queue for later visits}
该过程不是递归的,因为我们并非首先遍历整个子树,而是使用一个队列 (queue) 来产生 FIFO 访问节点的顺序语义。整体的运行时间为 O(n),因为对 入队 (enqueue) 和 出队 (dequeue) 操作各调用了 n 次。
1.3 迭代和递归 (Iteration and Recursion)
注意练习和理解接下来的几种遍历实现,并比较迭代和递归实现算法之间的差异。
参考文献
《Data Structures and Algorithms in Python》
https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/7/#_1
二、二叉树的前序遍历
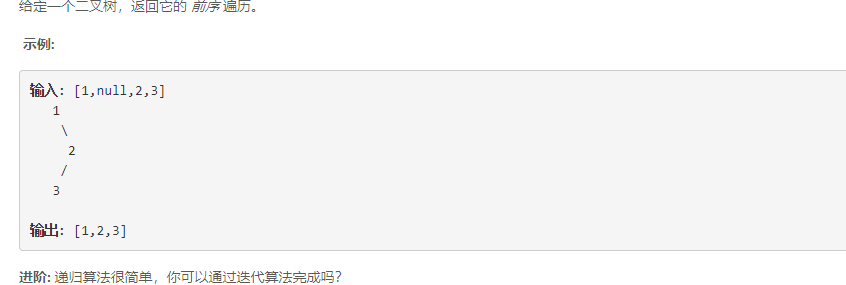
2.1 递归实现
2020/07/14 - 44.40% - 最优的方法之一,但本实现存在一些问题。
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
-
- class Solution:
- def __init__(self):
- self.result = [] # 遍历记录
-
- def preorderTraversal(self, root: TreeNode) -> List[int]:
- if root:
- self.result.append(root.val) # 先执行访问操作(此处为 list.append) —— 先序遍历的直观体现 !!!!!
- self.preorderTraversal(root.left) # 再对 left-child 递归前序遍历
- self.preorderTraversal(root.right) # 再对 right-child 递归前序遍历
- return self.result

上述方法的每次递归都返回当前的结果列表 self.resule,这其实是不必要的冗余操作,会降低算法效率。故本次将其修改,将前序遍历的递归部分封装到嵌套函数 traverse() 中,使所有操作都在本函数体 preorderTraversal() 内完成。且 每次调用都对结果列表 result 进行原地 (in-place) 增加,而无需显式返回当前结果列表或当前遍历元素等。空间复杂度 O(n),时间复杂度 O(n)。
2020/07/14 - 99.16% - 最优
- class Solution:
- def preorderTraversal(self, root: TreeNode) -> List[int]:
- def traverse(node):
- if node:
- result.append(node.val) # 先执行访问操作(此处为 list.append)
- traverse(node.left) # 再对 left-child 递归前序遍历
- traverse(node.right) # 再对 right-child 递归前序遍历
- result = [] # 遍历结果列表
- traverse(root)
- return result

2.2 迭代实现
使用栈迭代其实是模拟递归的一种形式。
2020/07/14 - 87.93% - 次优
- # 写法一
- class Solution:
- def preorderTraversal(self, root: TreeNode) -> List[int]:
- if not root:
- return []
-
- res = [] # 记录先序遍历结果
- stack = [] # 中间过程辅助栈
- node = root # 当前节点
- while stack or node: # 只要栈非空/当前节点非空, 就说明还没遍历完
- while node: # 若当前节点非空
- res.append(node.val) # 先记录(子树)根节点
- stack.append(node) # 左子树根节点入栈
- node = node.left # 再移动到左子树的根节点, 直至叶节点
- node = stack.pop() # 弹出当前节点的父节点
- node = node.right # 移到右子节点
-
- return res
- # 推荐写法 - 仿中序遍历迭代写法 - 更容易理解
- class Solution:
- def preorderTraversal(self, root: TreeNode) -> List[int]:
- preorder = []
- stack = []
- node = root
- while stack or node:
- if node:
- stack.append(node)
- preorder.append(node.val)
- node = node.left
- else:
- node = stack.pop()
- node = node.right
-
- return preorder

参考资料
https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/1/
https://leetcode-cn.com/problems/binary-tree-preorder-traversal/
三、中序遍历二叉树
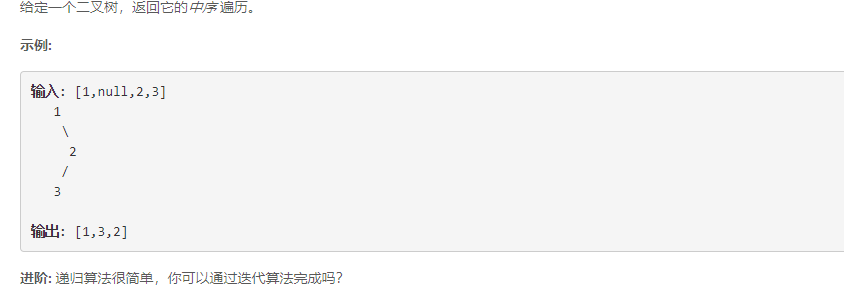
3.1 递归实现
2020/07/14 - 99.15% - 最优
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
-
- class Solution:
- def inorderTraversal(self, root: TreeNode) -> List[int]:
- def traverse(node):
- if node:
- traverse(node.left) # 先左子节点
- result.append(node.val) # 再根节点 —— 中序遍历的直观体现 !!!!!
- traverse(node.right) # 最后右子节点
- result = []
- traverse(root)
- return result

3.2 迭代实现
这很特别,迭代反而比递归实现更抽象,表明 递归/迭代 对 线性/非线性 的数据结构存在不同的适应程度。
2020/07/14 - 87.96% - 次优
- # 推荐写法
- class Solution:
- def inorderTraversal(self, root: TreeNode) -> List[int]:
- inorder = []
- stack = []
- node = root
- while stack or node:
- if node:
- stack.append(node)
- node = node.left
- else:
- node = stack.pop()
- inorder.append(node.val)
- node = node.right
-
- return inorder

参考资料
https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/2/
四、二叉树的后序遍历
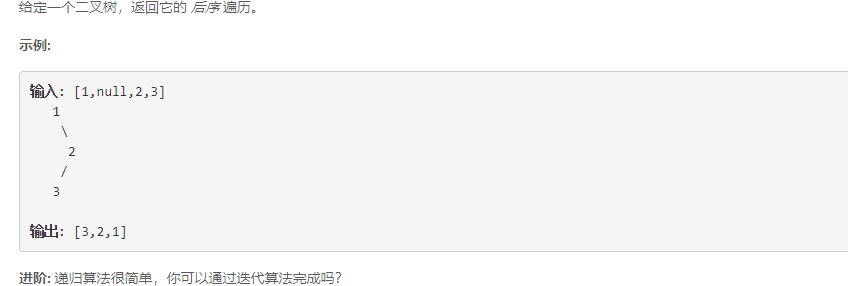
4.1 递归实现
前序、中序和后序递归都只需根据伪代码对顺序稍作调整即可,简洁高效。
2020/07/14 - 99.18% - 最优
- # Definition for a binary tree node.
- # class TreeNode:
- # def __init__(self, x):
- # self.val = x
- # self.left = None
- # self.right = None
-
- class Solution:
- def postorderTraversal(self, root: TreeNode) -> List[int]:
- def traverse(node):
- if node:
- traverse(node.left) # 先左子节点
- traverse(node.right) # 再右子节点
- result.append(node.val) # 最后根节点 —— 后序遍历的直观体现 !!!!!
- result = []
- traverse(root)
- return result

4.2 迭代实现
- # 实现 1
- class Solution:
- def postorderTraversal(self, root: TreeNode) -> List[int]:
- if not root:
- return []
-
- res = []
- node = root
- stack1 = [node]
- stack2 = []
- while stack1:
- node = stack1.pop()
- if node.left:
- stack1.append(node.left)
- if node.right:
- stack1.append(node.right)
- stack2.append(node)
- while stack2:
- res.append(stack2.pop().val)
-
- return res
- # 实现 2
- class Solution:
- def postorderTraversal(self, root: TreeNode) -> List[int]:
- if not root:
- return []
-
- res = []
- stack = []
- prev = None
-
- while root or stack:
- while root:
- stack.append(root) # (左)(子树)根节点入栈
- root = root.left # 移动到左子树
- root = stack.pop() # 出栈
- # 若 当前节点没有右子节点 或 当前节点的右子节点遍历过了
- # (因为在往右子树遍历过程中, 还需要往回遍历到父节点, 所以存在可能遍历过的情况, 所以需要加以判断)
- if (not root.right) or (root.right == prev):
- res.append(root.val) # 则记录当前节点值
- prev = root # 记录已遍历的当前节点
- root = None # 清空当前节点
- # 否则, 当前节点存在未遍历过的右子节点
- else:
- stack.append(root) # 右子树根节点入栈
- root = root.right # 移动到右子树
-
- return res
- # 推荐写法
-
- class Solution:
- def postorderTraversal(self, root: TreeNode) -> List[int]:
- postorder = []
- stack = []
- prev = None
- node = root
- while stack or node:
- if node:
- stack.append(node) # (左)(子树)根节点入栈
- node = node.left # 移动到左子树
- else:
- node = stack.pop() # 新的当前节点出栈
-
- # 1. 记录
- # 若 当前节点没有右子节点 或 当前节点的右子节点遍历过了
- # (因为在往右子树遍历过程中, 还需往回遍历到父节点, 所以存在可能遍历过的情况, 需加以判断)
- if (not node.right) or (node.right == prev):
- postorder.append(node.val)
- prev = node # 记录 当前节点 为 先前已遍历节点
- node = None # 清空 当前节点
-
- # 2. 转移
- # 否则, 当前节点存在未遍历过的右子节点
- else:
- stack.append(node) # 右子树根节点入栈
- node = node.right # 移动到右子树
-
- return postorder

参考资料
https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/3/
五、层序遍历 - 介绍

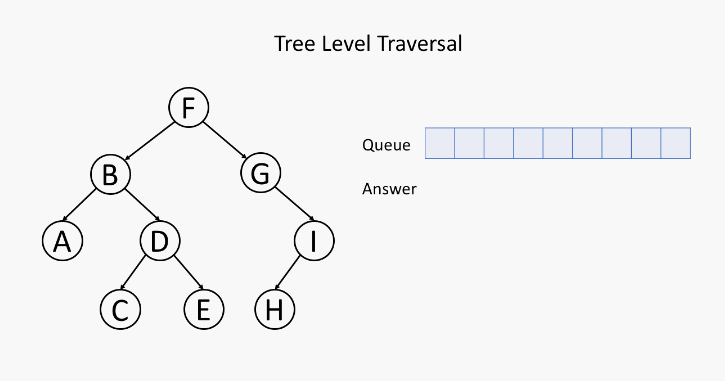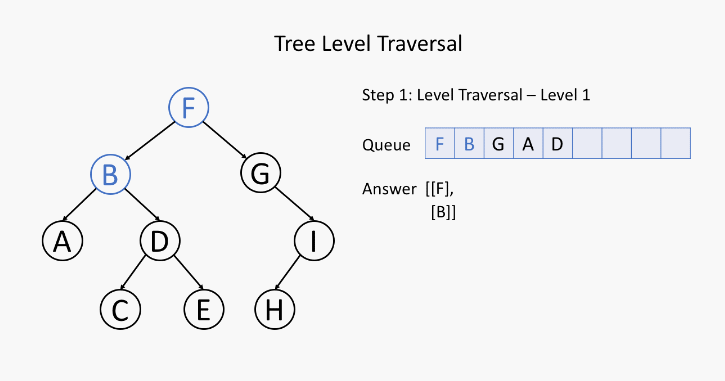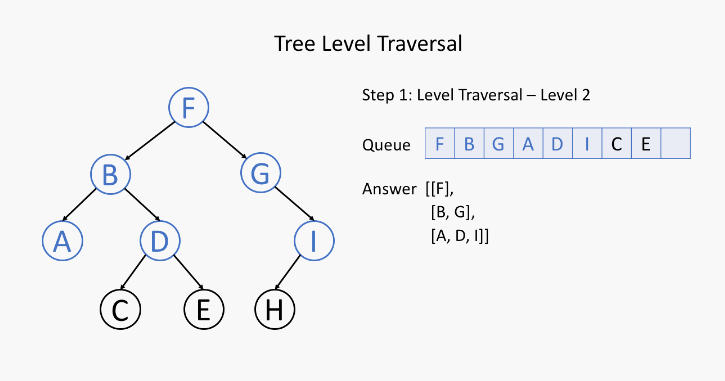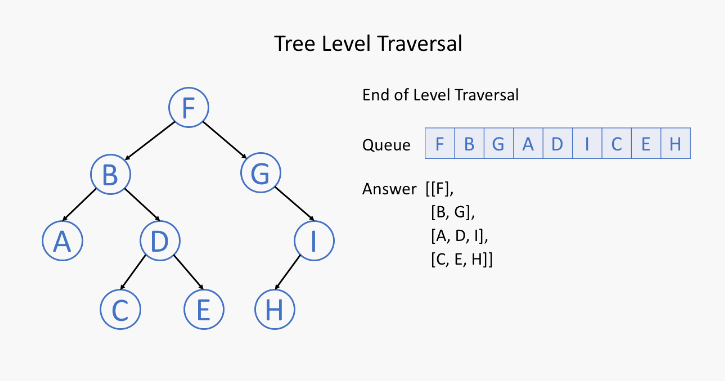
![]()
参考资料:https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/8/
六、二叉树的层序遍历
![]()

6.1 迭代实现 (计数循环)
空间复杂度 O(n),时间复杂度 O(n)
2020/07/14 - 94.51% (36ms)
- # Python - 推荐
- class Solution:
- def levelOrder(self, root: TreeNode) -> List[List[int]]:
- if not root:
- return []
-
- result = [] # 层序遍历结果列表
- Q = collections.deque() # 辅助队列
- Q.append(root) # 根节点入队
-
- while Q: # 迭代至辅助队列队空
- result.append([]) # 当前层级空列表初始化
- for _ in range(len(Q)): # 根据次序依次添加当前层级节点
- node = Q.popleft() # 当前层级第 index 个节点, 出队
- result[-1].append(node.val) # 在当前层级空列表 result[-1] 中添加值
- if node.left: # 若当前层级节点存在子节点(下一层级), 入队
- Q.append(node.left)
- if node.right:
- Q.append(node.right)
-
- return result
6.2 迭代实现 (层分隔符)
空间复杂度 O(n),时间复杂度 O(n)
2020/08/03 - 94.51% (36ms)
- # Python - 推荐
- class Solution:
- def levelOrder(self, root: TreeNode) -> List[List[int]]:
- if not root:
- return []
-
- result = []
- Q = collections.deque()
- Q.append(root)
- Q.append(None) # 层分隔符
-
- while Q[0]: # 不能用 while Q 因为当遍历完毕时 Q 中只有分隔符 None, 会无限循环
- temp = [] # 当前层层序遍历结果
- cur = Q.popleft() # 当前层节点出队
-
- while cur != None:
- temp.append(cur.val)
- if cur.left:
- Q.append(cur.left) # 下一层节点入队
- if cur.right:
- Q.append(cur.right) # 下一层节点入队
- cur = Q.popleft() # 当前层节点出队
-
- result.append(temp) # 当前层结果记录
- Q.append(None) # 层分隔符
-
- return result
6.3 递归实现 (尾递归)
空间复杂度 O(n),时间复杂度 O(n)
2020/08/03 - 82.90% (40ms)
- # 推荐记忆
- class Solution:
- def levelOrder(self, root: TreeNode) -> List[List[int]]:
-
- # 辅助尾递归函数
- def recur(root, depth, result):
- # 空节点返回
- if not root:
- return
- # 增加当前层遍历结果列表
- if depth >= len(result):
- result.append([])
- # 添加当前深度的层遍历结果
- result[depth].append(root.val)
- # 左子树
- if root.left:
- recur(root.left, depth+1, result)
- # 右子树
- if root.right:
- recur(root.right, depth+1, result)
-
- result = []
- recur(root, 0, result) # 注意 result 是可变对象, 此处传引用调用
-
- return result
官方实现与说明



- // C++ implementation
- class Solution {
- public:
- vector<vector<int>> levelOrder(TreeNode* root) {
- vector <vector <int>> ret;
- if (!root) return ret;
-
- queue <TreeNode*> q;
- q.push(root);
- while (!q.empty()) {
- int currentLevelSize = q.size();
- ret.push_back(vector <int> ());
- for (int i = 1; i <= currentLevelSize; ++i) {
- auto node = q.front(); q.pop();
- ret.back().push_back(node->val);
- if (node->left) q.push(node->left);
- if (node->right) q.push(node->right);
- }
- }
- return ret;
- }
- };
其他 Python 实现 1 (使用了更多的辅助标志和队列):
- # Python implementation
- class Solution:
- def levelOrder(self, root: TreeNode) -> List[List[int]]:
- if not root:
- return []
-
- result, level_temp = [], [] # 遍历结果列表 + 临时层级列表
- nodes = [root, "level"]
- while nodes:
- temp = nodes.pop(0)
- if temp == "level": # 继续搜索标志
- result.append(level_temp)
- level_temp = []
- if nodes:
- nodes.append("level")
- continue
- else:
- break
- if temp.val:
- level_temp.append(temp.val)
- if temp.left:
- nodes.append(temp.left)
- if temp.right:
- nodes.append(temp.right)
- return result
其他 Python 实现 2 (使用了更多的辅助标志和队列):
- # Python implementation
- class Solution:
- def levelOrder(self, root: TreeNode) -> List[List[int]]:
- if not root: return []
- queue = [[root]]
- res = []
- while queue:
- layer = queue.pop(0)
- temp_queue = []
- temp_res = []
- for node in layer:
- if not node:
- continue
- temp_res.append(node.val)
- temp_queue += [node.left, node.right]
- if not temp_queue:
- break
- res.append(temp_res)
- queue.append(temp_queue)
- return res

参考资料
https://leetcode-cn.com/explore/learn/card/data-structure-binary-tree/2/traverse-a-tree/9/

