
- 1python项目:僵尸大战僵尸(植物大战僵尸改版)_python 植物大战僵尸
- 2IDEA02:配置SQL Server2019数据库_sql server jar包
- 3Flask+MySQL+ECharts实现地名关系图谱_flask charts 关系图 边
- 4GoWeb——Go Mod使用
- 5为什么 ChatGPT 不火了?
- 6电脑手机快速互传文件7个免费工具软件_手机电脑怎么互传文字和图片
- 7蓝桥杯常用算法——数学函数_蓝桥杯常用函数
- 8关于项目管理(PMP)绝对的骗局_pmp证书大忽悠
- 9uniapp开发WebRTC语音直播间支持app(android+IOS)和H5,并记录了所有踩得坑_uniapp webrtc
- 10常用网站链接_小网站链接
【技术新趋势】合合信息:文本纠错提升OCR任务准确率的方法_大模型文本纠错准确率
赞
踩
点击领取AI产品100元体验金,助力开发者高效工作解决文档难题:
摘要:错字率是OCR任务中的重要指标,文本纠错需要机器具备人类水平相当的语言理解能力。随着人工智能应用的成熟,越来越多的纠错方法被提出。
近年来深度学习在OCR领域取得了巨大的成功,但OCR应用中识别错误时有出现。错误的识别结果不仅难以阅读和理解,同时也降低文本的信息价值。在某些领域,如医疗行业,识别错误可能带来巨大的损失。因此如何降低OCR任务的错字率受到学术界和工业界的广泛关注。合合信息通过本文来讲解文本纠错技术帮助更多人解决业务问题。通常文本纠错的流程可以分为错误文本识别、候选词生成和候选词排序三个步骤。文本纠错方法可包括基于CTC解码和使用模型两种方式,下面分别对这两种纠错方式进行介绍。
1.Beam Search
该方法是针对CTC解码时的一种优化方法,这是由于当使用贪心算法进行CTC解码时忽略了一个输出可能对应多种对齐结果,导致在实际应用中错字率会颇高,并且无法与语言模型结合。因而通过Beam Search的方法我们能够得到top最优的路径,后续也可以利用其他信息来进一步优化搜索结果。
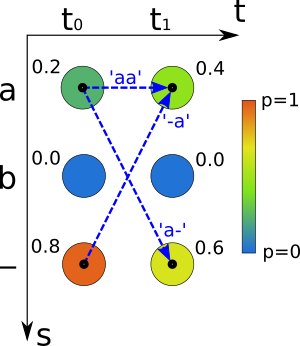
图 1: All paths corresponding to text “a”.
1.1 prefix Beam Search[1]
由于有许多不同的路径在many-to-one map的过程中是相同的,当使用Beam Search时只会选择Top N个路径,这就导致了很多有用的信息被舍弃了,如图1所示,生成“a”路径的概率为0.2·0.4+0.2·0.6+0.8·0.4=0.52,而生成blank的路径概率为0.8·0.6=0.48,当使用最佳路径的搜索方式会倾向于选择blank的路径,而不是整体概率更大的a路径。所以就有了Prefix Beam Search,其基本思想是,在每个t时刻,计算所有当前可能输出的规整字符串(即去除连续重复和blank的字符串)的概率。然后用Beam Search的方法,在每个时刻选取最好的N个路径,从而将每个时间点t上的搜索空间变为常数。在计算最优路径概率时,以t=3时刻,规整字符串为“a”为例,如图2所示。对于t+1时刻的可能情况有6种,可以看出在Prefix Beam Search中将规整后的字符串分为了以blank和非blank结尾的两种情况来计算t+1时刻的概率。通过Prefix Beam Search方法,解决了在many-to-one map过程所导致的结果相同而路径可能不同的问题,搜索结果是针对具有相同结果路径的排序,而不是单一路径的排序。

图 2: The effect of appending a character to paths ending with blank and non-blank.
1.2 Vanilla Beam Search[2]
对于输出是一个大小为 T × (C + 1) 的矩阵,进行解码时在每个时间步t,每个beam-labeling都会被t+1时刻的所有可能的字符扩展,同时未被扩展前的beam-labeling也会被保留下来,这一搜索过程可以表示为如图 3 所示的树状结构。为避免搜索路径的指数增长,在每个时间步仅保留N个最佳的beam-labeling。如果在t时刻两个beam-labeling相等,则会把二者的概率进行求和,然后删除其中一个来合并二者的路径。在这一过程中可以使用character-level LM的先验信息对beam-labeling可能的扩展进行打分。也可以引入一个词典,当出现词汇表外的单词(OOV)时,就可以删除相关的beam,来保证解码后始终能够得到有意义的结果。

图 3: Iteratively extending beam-labelings (from top to bottom) forms this tree. Only the two best-scoring beams are kept per time-step (i.e. N = 2), all others are removed (red). Equal labelings get merged (blue).
1.3 Word Beam Search[3]
VBS工作在字符级别,不会从语义级别去判断解码的内容是否符合规则,而WBS方法可以综合前后几个字符的信息来获得当前字符的准确信息,在能够将解码后的单词限制在词典里的同时,还允许单词之间拥有任意数量的非单词字符,并且在解码中还可以使用word-level LM的先验信息,来提升对CTC解码的准确性。
在进行解码时,当beam-labeling被标记为单词状态时,使用根据词典预先构成的prefix-tree,如图4所示,来约束解码的结果始终在词典中,当beam-labeling转换为非单词状态时,则不必受prefix-tree的约束进而能够实现非单词字符的解码,beam-labeling状态的转换受将要扩展字符的影响,如果字符为词典字符(对英文来说词典字符可以定义为英文字母)则其状态为单词状态,字符为非词典字符则为非词典状态。通过WBS方法可以进一步降低解码时的错字率。
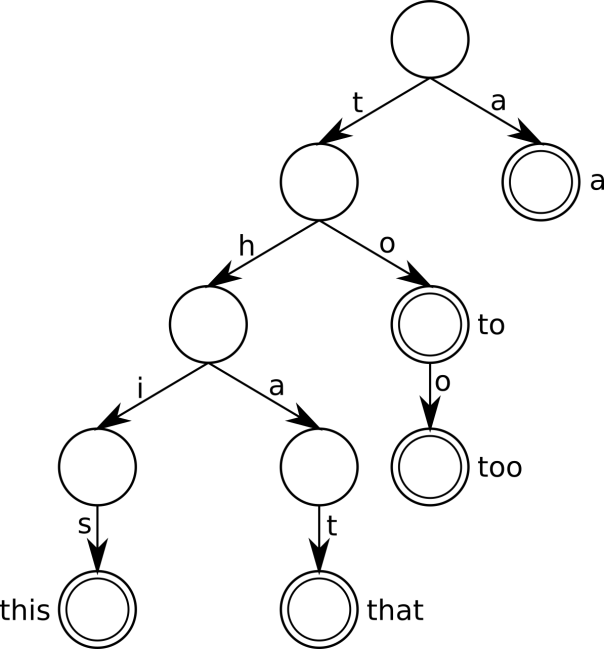
图 4: Prefix tree containing the words “a”, “to”, “too”, “this” and “that”.Double circles indicate that the word-flag is set.
2.基于深度模型的文本纠错
针对文本纠错,除了在解码时引入Beam Search和LM先验知识来降低错字率外,还可以通过深度学习的方法,使用经过训练的纠错模型来识别和纠正文本中出现的错误。
2.1 基于Seq2Seq 模型的纠错
在Confusionset-guided Pointer Networks for Chinese Spelling Check[4]文中,提出了使用混淆集和门控机制相结合的中文纠错模型,如图5所示。纠错模型使用的时Encoder-Decoder模式,编码器使用的是BiLSTM,对中文文本按字符级别进行编码,解码器使用的是LSTM,在解码器进行解码时,不仅接收上一个token的embedding的特征向量,还接受通过注意力机制将编码器的文本特征聚合成一个包含上下文信息的特征向量,从而达到基于语义信息的文本纠错。在解码器的每个时间t所生成的特征向量,一方面通过线性变换投影到vocabulary的向量空间用于生成候选字符,另一方面也会通过一个Softmax层构成的门控机制,用于决定当前时刻解码器的输出结果是否直接复制原始的文本字符。此外当门控机制不选择直接复制时,并且当要预测的字符出现在预先设定好的混淆集中的时候,解码器则会在混淆集中选择候选的字符,而不是在整个词典向量空间中选择。

图 5: Structure of Confusionset-guided Pointer Network with for Chinese Spelling Check.
2.2 FASPell[5]
虽然通过加入注意力机制Seq2Seq模型也能实现基于上下文信息的文本纠错,但是基于混淆集进行候选词的构造,很容易在少量数据上过拟合,而且只利用混淆集的方法也不够灵活,由于这一阈值是固定的导致字符之间的相似性没有被充分利用。
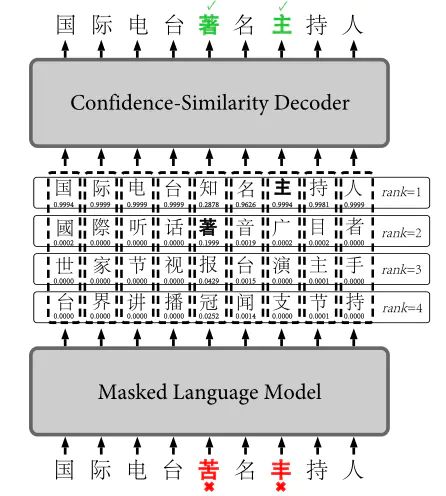
图 6: A real example of how an erroneous sentence
因而FASPell模型提出了基于预训练模型作为候选词生成器,并使用了置信度和相似度相结合的解码器实现不依赖混淆集的中文纠错,模型结构如图6所示。首先是在Bert模型上进行训练(也就是文中说的自降噪编码器DAE),训练时将错误的token用mask代替,为了防止过拟合也会随机对正确的token使用mask。通过训练编码器生成的候选词后经过一个Confidence-Similarity Decoder,简单来说就是利用字符的字形和拼音相似度,再结合训练集上给出的置信度分布找出基于二者之间正确和错误字符的分界线。在测试时不再仅仅根据Bert模型所给出的置信度来挑选候选词,而是加上候选字符与原始字符的相似度信息共同决定最终的结果。
FASPell虽然说该方法比RNN结构的纠错网络能够更快、更好的适用性、更加简单和更强大,少了混淆集但同时引入了字形相似度和拼音相似度,并且在解码时,决策边界的选择也需要根据训练集进行调整,当训练集分布与实际使用时数据的分布不同时决策边界有可能也需要调整,才能取得较为理想的结果。
2.3 基于注意力机制的Seq2Seq纠错模型
针对英文的纠错在Denoising Sequence-to-Sequence Modeling for Removing Spelling Mistakes[6]一文中使用Bert 的注意力机制代替了RNN结构,模型结构如图7所示。其中编码器使用了6层多头注意力结构,解码器与编码器结构相同,与Seq2Seq解码方式一样,按时间顺序生成纠错后的文本,为了实现这一过程,在解码时使用了mask机制,使得解码器在t时刻的只能看到t时刻之前的信息。
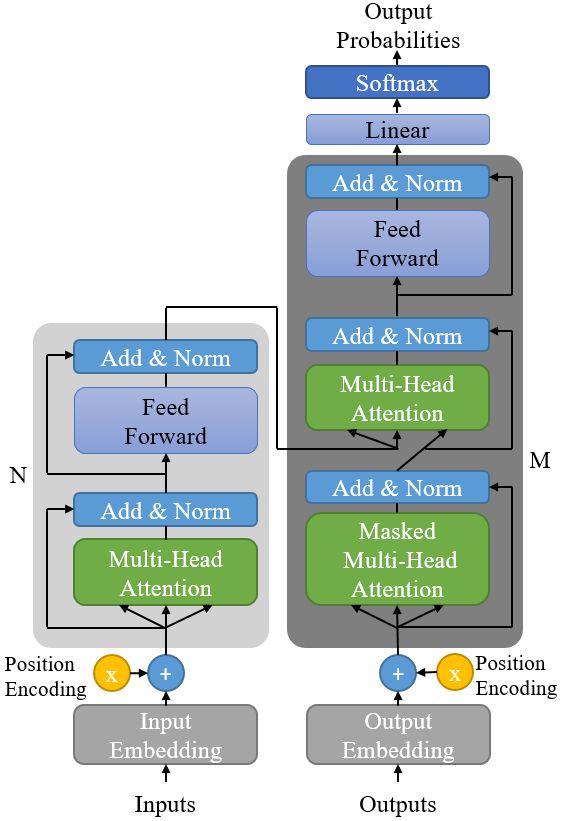
图 7: full model architecture
相比RNN结构的降噪模型,模型性能有所提升,由于没有使用预训练模型需要较大的训练集进行训练,而且在文中并没有提及具体的实验细节,编码器的特征是怎样送入解码器中的,文中也没有具体提及。
2.4 Soft-Masked BERT[7]
文中指出由于Bert是基于mask进行训练的一种无监督模型,导致其只能拟合被mask部分的token分布,并不能识别文本中的错误,因而在纠错算法中一般需要额外的模块指出文本中的错误,再将错误的文本mask掉再送入Bert模型进而得到正确的文本。而本文提出了一种soft-masked机制,送入Bert的文本不再被强制mask掉而是文本token的embedding和MASK token特征的加权和,如图8所示。具体做法是,使用一个BiLSTM模型用来判别文本中字符错误的概率,记为p,在将文本送入Bert中时会对没给token的特征表示e i与MASK token的特征e mask 按照概率p进行加权,公式如下:
e i’ = p · e mask + (1 − p) · e i
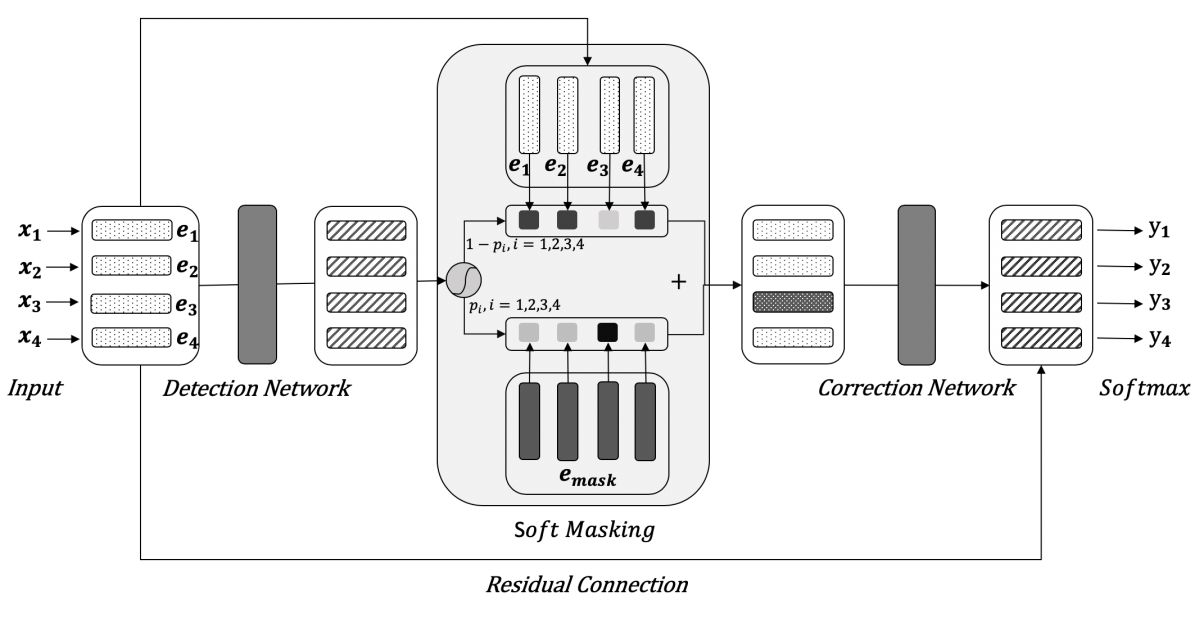
图 8: Architecture of Soft-Masked BERT
在训练时将文本错误检测模块和纠错模块放在一起训练,并通过超参数λ来平衡两个任务的损失,通过实验验证,λ=0.8时整个文本纠错模型达到最优,说明文本错误检测任务比纠正任务要容易。使用soft-masked机制,通过错误概率p控制文本token进入纠错模型中的信息量的方式,避免了文本错误检测时阈值的设计,缺点是该方法没有使用生成式的方案不太容易处理字符缺失的问题。
2.5 Chunk-Based[8]
鉴于大多数中文纠错模型都是针对具有相似字符形状或发音的文本纠错,对于没有字形相似和语音相似的错别字更正效果则一般,另一方面大部分纠错模型都是以pipeline的形式来实现的导致模型难以优化。针对以上缺点在Chunk-based Chinese Spelling Check with Global Optimization文中对纠错任务提出了改进,纠错流程如图9所示。
本文主要的贡献是扩展了混淆集,以前的混淆集主要是字形或发音相似的字符组成,而本中使用的混淆集中也包含了语义相近的词组。另一方面是关于模型的优化方法,是基于句子级别的优化,以往模型只是针对个别字符输出结果的优化,很少考虑整个语义上的最优结果。模型中的候选词是根据字形、语音和语义相似度生成的,其中语义相似度是由 FASPell模型得到。具体做法是将文中定义的编辑距离、字形相似度、语音相似度、语义级别错字率等特征通过加权求和的方式来生成候选词的top K。在选择候选词时,结合Beam Search方法考虑了句子级别整体最优解的情况。在进行模型优化时使用了Minimum Error Rate Training (MERT)[9]方法,从而实现了文中所说的针对多特征组合排序的联合优化。
Chunk-based方法虽然能提升纠错模型的表现,但似乎看起来又回到了基于规则进行文本纠错的方向(添加了人为定义的编辑距离,使用语义相近的词组对混淆集进行了扩展),只不过以往基于规则的纠错方法都不可微,各个特征之间的权重设计往往需要根据经验设计,本文则通过一个线性层将这些特征进行了加权,而不需要人为设计最佳的权重参数。
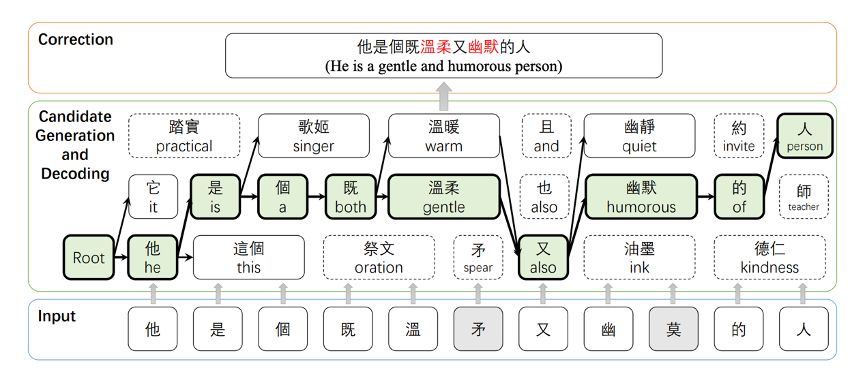
图 9: The workflow of the proposed chunk-based decoding method during the inference time. The chunk-based candidate generation and decoding are used to disambiguate and correct the input sentence gradually.
小结
本文针对OCR的文本纠错任务进行了简单介绍,分为对针对CTC解码时的纠错和使用纠错模型两种方式。前者一般是使用Beam Search来搜索最优的解码路径,并在搜索过程中引入LM,使用相关语言的先验信息来进一步降低解码时的错字率,这样做的好处是相比于使用纠错模型的方法,不必引入额外的训练参数,实现起来较为简单,只是受OCR模型的限制,存在着性能提升的上限。后者则是针对解码后的文本进行纠错,经历了从基于Seq2Seq模型使用生成方式进行文本纠错,到使用预训练模型进行文本纠错的转变,纠错能力也有了很大的提升,显示了出巨大的发展潜力。
方案选择
对于文本纠错,合合信息的理解是:严格来说Beam Search只是对CTC解码的优化,存在着优化上限(Beam长度为文本长度,找到全局最优解),只有当与基于统计LM(n-gram)相结合时才有着一定的纠错能力,但往往是基于统计信息针对字词的纠错,对于语法和语义的纠错则能力有限。然而Beam Search作为一种优化算法,在OCR模型部署时并不会引入额外的参数,计算也不复杂,可以说是针对CTC解码优化的必备算法。针对中文和英文的不同特点,中文任务选择VBS而英文任务选择WBS较好。至于要不要引入LM的先验信息,可以视具体OCR任务决定。
当有必要使用纠错模型对OCR任务进行优化时,最为简单实现方式是Soft-Masked BERT,不需要额外定义例如字形相似度、语音相似度等参数,并且对中英文都适用。但和Chunk-Based模型、FASPell模型一样模型主体使用的预训练模型(Bert),纠错方式并不是生成式,模型一个输入token对应着一个输出token,因此难以处理文本缺字和多字的问题。如果OCR结果缺字或多字的问题比较严重,优化方案可以将Bert模型改成与翻译模型类似的,基于注意力机制的Seq2Seq纠错模型。如果想进一步提升模型的纠错能力,Chunk-Based模型是种不错的选择,混淆集的使用可以避免大部分常见的字形相似、拼音相似的错误,只是混淆集需要人工制作,编辑距离也需要人为定义,算是一种基于规则和深度学习相结合的纠错方式。
更多体验::TextIn - API中心![]() https://www.textin.com/document/index
https://www.textin.com/document/index
参考文献:
[1] Hannun A Y , Maas A L , Jurafsky D , et al. First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs[J]. computer science, 2014.
[2] Hwang K , Sung W . Character-Level Incremental Speech Recognition with Recurrent Neural Networks[C]// IEEE. IEEE, 2016.
[3] Scheidl H , Fiel S , Sablatnig R . Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm[C]// 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR). 2018.
[4] Wang D , Yi T , Zhong L . Confusionset-guided Pointer Networks for Chinese Spelling Check[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[5] Hong Y , Yu X , He N , et al. FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm[C]// Proceedings of the 5th Workshop on Noisy User-generated Text (W-NUT 2019). 2019.
[6] Roy S . Denoising Sequence-to-Sequence Modeling for Removing Spelling Mistakes[C]// 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT). 2019.
[7] Zhang S , Huang H , Liu J , et al. Spelling Error Correction with Soft-Masked BERT[J]. 2020.
[8] Bao Z , Li C , Wang R . Chunk-based Chinese Spelling Check with Global Optimization[C]// Findings of the Association for Computational Linguistics: EMNLP 2020. 2020.
[9] Franz Josef Och. Minimum error rate training in statistical machine translation. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics, pages 160–167, Sapporo, Japan. Association for Computational Linguistics.2003.


