
- 1MySQL报错:ERROR 1064 (42000)_error 1064 (42000): you have an error in your sql
- 2RabbitMq基础概念知识复习
- 3H1 7-3可逆素数_请从小到大输出所有4位数的可逆素数。可逆素数指: 一个素数将其各位数字的顺
- 4软件设计师大纲:软件设计考试科目综合分析
- 5Flink 组件详解及任务提交流程
- 6git 拉取/推送远程分支_git 推送远程分支
- 7AI的落地场景:听AI成为现实,你也可以亲身体验!
- 8Unity射击检测(RaycastHit)图层过滤_physics.raycast(ray, out hit, mathf.infinity, wtla
- 9Could not create connection to database server.亲测有效_could not create connection to database server. at
- 10注册中心eureka的介绍及源码探索_eureka github
一文了解亚马逊云科技最新大语言模型_亚马逊大语言模型
赞
踩
大语言模型简介

大模型(LLMs)是一种人工智能模型,旨在理解和生成人类语言。它们通过在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。这些模型通常基于深度学习架构,如转换器,这使它们在各种自然语言处理任务上表现出令人印象深刻的能力。大模型领域在国内外都取得了显著的成就,各个国家和地区的企业、机构以及学术界都在积极投入资源和努力,推动大模型技术的发展。比如,在国外,OpenAI 推出的基于 GPT-3.5 的大型语言模型 ChatGPT,由于其优秀的表现,ChatGPT 及其背后的大型语言模型迅速成为人工智能领域的热门话题,吸引了广大科研人员和开发者的关注和参与。之后Google推出了LaMDA大语言模型,Meta推出了 LLaMa大语言模型。在国内,百度推出了“文心一言”、阿里推出了“通义大模型”、华为推出了“盘古大模型”等等。
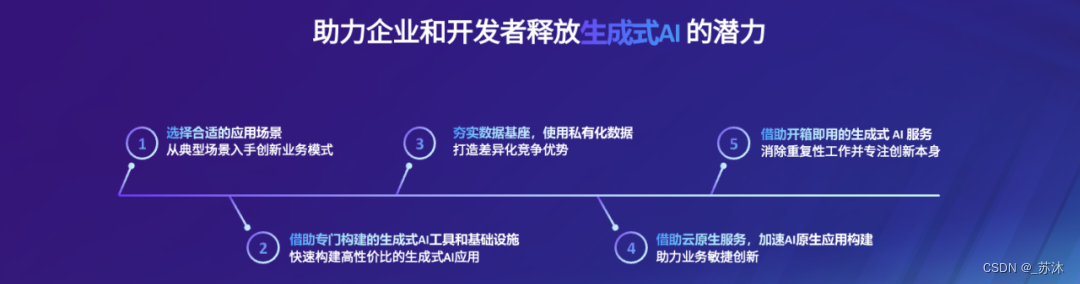
生成式AI是一类 AI 模型,专注于生成新的、具有创造性的内容,而不仅仅是根据现有数据进行分类或预测。它可以在各种领域中使用,如自然语言生成、图像生成、音乐生成等。可以说,全球范围内的大型科技公司和独角兽企业已经建立了一个多元化丰富的生成式AI生态系统,并且这一生态系统仍在不断扩展范围。近日在刚刚结束的生成式AI构建者大会上,亚马逊云科技就提出了为用户构建完整端到端生成式AI的技术堆栈。详细而言,亚马逊云科技通过以下五个方面帮助企业和开发者充分发挥生成式人工智能的潜力:
- 选择合适的应用场景,从典型场景入手创新业务模式
- 借助专门构建的生成式AI工具和基础设施,快速构建高性价比的生成式AI应用
- 夯实数据基座,使用私有化数据,打造差异化竞争优势
- 借助云原生服务,加速AI原生应用构建,助力业务敏捷创新
- 借助开箱即用的生成式AI服务,消除重复性工作并专注创新本身
亚马逊 Amazon Bedrock
在今年9月,亚马逊云科技正式发布Amazon Bedrock,这是一套生成式AI全托管服务,包含业界领先的基础模型和构建生成式AI应用程序所需的一系列功能。
Amazon Bedrock 汇聚了业内几乎所有领先的基础大语言模型,面对不同应用场景,它可以让人们只需通过单一 API 就能用上来自 AI21 Labs、Anthropic、Cohere、Meta Llama2、Stability AI 等公司的先进大语言模型来构建自己的应用。
在Amazon Bedrock的基础之上,企业可以更方便、快速地尝试各种领先的基础模型,进行提示工程,完成微调和检索增强生成(RAG)等动作,使用自身专有数据定制模型。
生成式AI,可以用一个公式呈现,即提示词+上下文+大模型=输出结果。

举个栗子,当一位客户想要更换球鞋的颜色,他会提出「我买的鞋子可以换成棕色的吗?」,提出问题便是提示词。
那么上下文是指,之前购买的历史对话信息,以及客户订单记录等数据。然后需要寻求大模型,检索退换货相关策略,然后根据以往的售后处理案例,再给出结果。这样,一个生成式AI应用真正的价值就体现了。但我们要清楚的是,这其中的基础模型,并不是生成式AI的全部。若说,在这些华丽的应用背后,有着一个非常关键要素——数据相比于传统的应用,生成式AI在数据的利用上,有一套特有的流程。其所需的能力涉及到从数据/语料加工、基础模型训练/调优,到数据治理、知识召回、提示工程等一系列模块。
向量数据库
大模型在给我们带来无限震撼,同时一些缺陷和限制也让大模型的开发者头痛不已。比较常见的问题如:大模型输入端上下文(tokens)的大小存在限制,开发者们不得不寻找其他的解决方案。向量数据库就是解决方案之一。
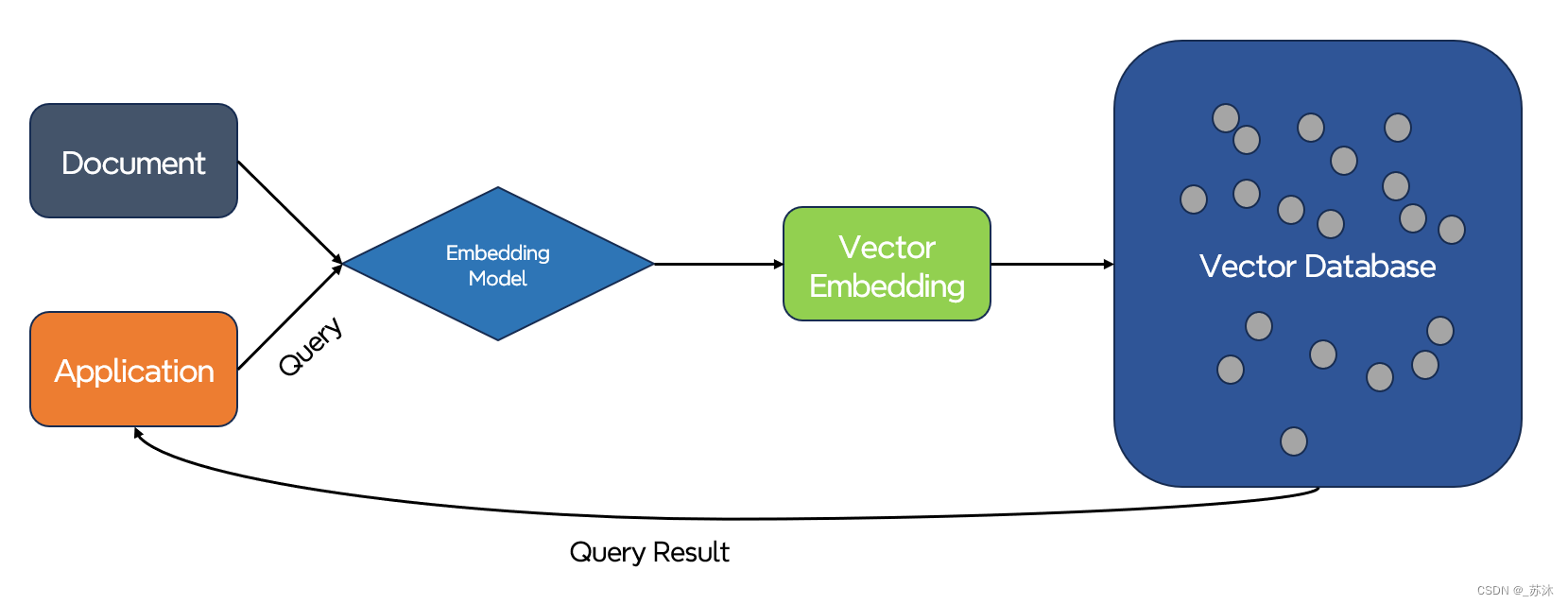
如下图所示,向量数据库的核心思想是将文本转换成向量,然后将向量存储在数据库中,当用户输入问题时将问题转换成向量,然后在数据库中搜索最相似的向量和上下文,最后将文本返回给用户。
当我们有一份文档需要大模型处理时,例如这份文档是客服培训资料或者操作手册,我们可以先将这份文档的所有内容转化成向量(这个过程称之为 Vector Embedding),然后当用户提出相关问题时,我们将用户的搜索内容转换成向量,然后在数据库中搜索最相似的向量,匹配最相似的几个上下文,最后将上下文返回给模型。这样不仅可以大大减少 模型 的计算量,从而提高响应速度,更重要的是降低成本,并绕过 模型 的 tokens 限制。
向量数据库,它可以可加速AI应用程序的开发,并简化由AI驱动的应用程序工作负载的运作。然而,作为一项相对较新的技术,目前能够做出高质量向量数据库的企业并不多。
通用大模型存在着幻觉、信息时效性差,以及包括token长度限制等各种问题。尤其是对于企业内部的信息来说,如果让LLM自由发挥,很容易就给出了错误答案。但如果能有私有知识的加持,LLM就可以给出更为精准有效的回答。为了利用这些私域知识,我们可以通过Embedding模型把它们变成向量,并存放在向量数据库里。当有查询到来时,通过同样的Embedding模型生成新的向量,和向量数据库里的数据做相似度计算,返回最相近的结果。可以说,如果把LLM比作是容易失忆的大脑,那么向量数据库就是这个大脑的海马体。对此,亚马逊云科技有AmazonOpenSearch、Amazon PostgreSQL和Amazon RDS for PostgreSQL等方案。Amazon Aurora/Amazon RDS PostgreSQL,能够兼容开源PostgreSQL,易于学习。Amanzon OpenSearch具备向量和倒排召回能力,可利用现有集群,同时能提供日志检索能力。Amazon Kendra是基于机器学习的端到端智能检索服务,能够帮助用户使用自然语言搜索非结构化文本。
亚马逊大模型的应用
今年 4 月WPS首次公布旗下具备大语言模型能力的人工智能应用WPS AI,可以为每一位用户提供AIGC(内容创作)、Copilot(智慧助理)和Insight(知识洞察)三方面全新的产品体验。为了给更多海外客户提供稳定且优质的办公服务,金山办公通过携手亚马逊云科技,从AI创新等多个方面入手,开展持续深入合作,不断推动产品创新的同时,加速海外业务拓展。如今,金山办公已经将AI能力深度融合到WPS产品中:在AIGC(内容创作)方面,针对内容生成、创作以及排版美化等领域,涵盖文字、智能文档、演示等模块;在Copilot(智慧助理)方面通过AI能力提高用户的使用效率,降低用户操作门槛;在Insight(知识洞察)方面让用户快速对文件进行内容识别和文意理解。
Amazon Bedrock轻松地帮WPS解决了许多问题问题,很大程度上提升了研发效率。
比如,Amazon Bedrock支持来自AI21 Labs、Anthropic、Cohere、Meta、Stability AI 和Amazon等领先人工智能公司的高性能基础模型,并可以轻松安全地进行自定义模型训练;金山办公可以在轻松使用这些高性能基础模型的同时,也能够使用自己的数据构建差异化的应用程序。
不仅如此,由于Amazon Bedrock已支持PCI-DSS、HIPAA和GDPR,金山办公也可以利用它有效提升安全合规工作的效率,并确保客户数据的安全性。
与此同时,金山办公通过使用机器学习平台Amazon SageMaker,正在帮助算法科学家快速进行场景实验和算法迭代。Amazon SageMaker不仅可以避免算法科学家从头搭建模型,还可以通过Amazon SageMaker JumpStart功能帮助客户快速构建和部署模型,从而尝试多种开源模型。
在亚马逊云科技的助力之下,各大企业的生成式AI技术一定会继续蓬勃发展,发生更多革命性变化。生成式AI带来的生产力提高和新用例,会给全球经济带来巨大影响。肉眼可见的是,这个时间点正在加速到来。

