
- 1NPL预训练模型-GPT-3_npl大模型
- 2尼采:快乐的知识(上)_人言之未能言,人言之未敢言
- 38种常用的设计模式(9) —— 桥接模式bridge_桥接模式属于设计模式的哪种
- 4字符串常量池、class文件常量池和运行时常量池_类常量池、运行时常量池、字符串常量池
- 5Sarcasm detection论文解析 |利用分层融合模型在 twitter 中进行多模态讽刺检测_只涉及文本的sarcasm detection的最新论文
- 6centos7.9 安装使用kafka_centos7.9 安装kafka
- 7JDBC利用事务处理实现简单增删改查的详解及工具类的创建_如何启用事物,使用事物实现增删改查
- 8YOLOv5 分类模型的预处理(1) Resize 和 CenterCrop_yolov5 resize
- 9从外包到转岗华为正式员工月薪17K,这一百多天的心酸谁能懂.....
- 10Android Studio 实现app门户界面框架设计(移动开发技术第一次作业)_andriod studio哪个项目设计app局面
Rethinking of Pedestrian Attribute Recognition: Realistic Datasets and A Strong Baseline
赞
踩
论文:https://arxiv.org/pdf/2005.11909v2.pdf
代码:https://github.com/valencebond/Strong_Baseline_of_Pedestrian_Attribute_Recognition
1 论文
本文分析了行人重识别常用数据集PETA和RAP的缺陷,对数据集进行了修正,得到了 P E T A z s PETA_{zs} PETAzs和 R A P z s RAP_{zs} RAPzs两个数据集。并且作者提出了强的baseline模型已经具有了很好的属性定位能力,无需使用额外的注意力机制或STN进行关注区域定位。
PETA和RAP数据集的缺陷:
 PETA和RAP数据集中最大的缺陷是,训练集中和测试集中包含了同一人的图像且图像间的差异很小,如Fig. 1(a)(b)所示,这和实际的项目应用场景是不符的。这会造成各算法的测试结果优于其实际应用结果,如Fig. 2所示,作者使用PETA测试数据集中不同重叠度的数据子集进行测试,可以明确发现当训练集和测试集没有人员重复时,模型的准确率会显著下降:
PETA和RAP数据集中最大的缺陷是,训练集中和测试集中包含了同一人的图像且图像间的差异很小,如Fig. 1(a)(b)所示,这和实际的项目应用场景是不符的。这会造成各算法的测试结果优于其实际应用结果,如Fig. 2所示,作者使用PETA测试数据集中不同重叠度的数据子集进行测试,可以明确发现当训练集和测试集没有人员重复时,模型的准确率会显著下降:
 修正PETA和RAP数据集:
修正PETA和RAP数据集:
作者统计了原有PETA数据集划分方式下,训练集和测试集中来自于同一人的数据重复情况,如Fig. 3(a)所示,可以看出训练集和测试集中出现了很多的同一人的情况,具体是在训练集和测试集中,有1106个人重复出现,占测试集总人数的26.91%,重复出现的人的总图像量占总测试集的57.7%。而在实际应用中,基本上不会出现训练集和测试集是同一人的情况,Fig. 2也给出了,在PETA数据集上,如果只用不重复人的测试图像进行模型测试,精度相比使用现有的测试集会下降很多,所以非常有必要对现有的数据集进行修正。
 作者提出了下面五个原则进行数据集的修正:
作者提出了下面五个原则进行数据集的修正:

I
I
I是指Identity,指人数;N是图片数量;R是指各属性正样本的比例;T指阈值。
1,2,3是为了保证训练、验证和测试集分别包含的是不同人的图像,比例为3:1:1,且验证集中包含的人数和测试集包含的人数差异要小于 ∣ I a l l ∣ × T i d |I_{all}| \times T_{id} ∣Iall∣×Tid, T i d T_{id} Tid设置为0.01;
4,5是为了保证训练集和测试集的属性分布(不理解作者的意图), T i m g T_{img} Timg设置为300, T a t t r T_{attr} Tattr设置为0.03.
作者按照上述五条规则对PETA和RAP数据集进行了重新划分,得到了
P
E
T
A
z
s
PETA_{zs}
PETAzs和
R
A
P
z
s
RAP_{zs}
RAPzs数据集,如下表所示:
 Baseline:
Baseline:
数据集:
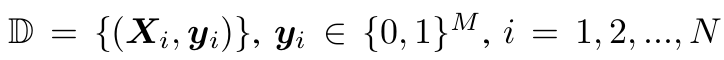
N表示图像数量,M表示属性数量,
y
i
y_i
yi表示各图像的属性label,这里是默认按照对各属性进行二分类判别的。
损失函数:
因为把行人属性识别看成了是多个二分类问题,因此采用sigmoid激活函数,损失函数表示为:
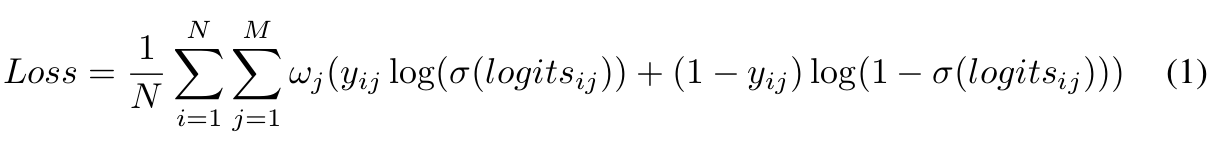 w
j
w_j
wj是为了解决属性不均衡问题引入的参数,可以表示为:
w
j
w_j
wj是为了解决属性不均衡问题引入的参数,可以表示为:
 r
j
r_j
rj表示训练集中第
j
j
j个属性为正的比例值。
r
j
r_j
rj表示训练集中第
j
j
j个属性为正的比例值。
度量标准:
采用了五个度量标准:
- 一个基于label的标准(mA),计算各属性的正样本和负样本分类的准确率的均值;
- 四个基于instance的标准,分别是Acc、P、R和F1;
- 主要使用mA和F1作为度量标准;
训练细节:
- 骨干网络:ResNet50
- 输入图像大小:256 * 192,使用随机水平镜像
- SGD,momentum=0.9,weight decay = 5e-4
- 初始学习率 0.01
- batchsize = 64
- plateau学习率衰减策略,衰减比例0.1
- 训练30个epoch
实验结果:

existing表示原有数据集;zero-shot表示处理后的数据集,也就是
P
E
T
A
z
s
PETA_{zs}
PETAzs。
 在原有数据集上的对比,也可以作为各算法的效果对比。有三点发现:
在原有数据集上的对比,也可以作为各算法的效果对比。有三点发现:
- PA100K中训练集和测试集人员重叠较少,结果更可信;
- 作者使用ResNet50比MsVAA效果更好,后者使用ResNet101,参数量更多;
- 相比于VAC,使用了更多的数据增广策略,网络上也有两个额外的分支网络,作者使用ResNet50参数量少,但效果相当;
- 将线性分类器替换为基于余弦距离的分类器,模型的效果可以小幅度提升;
- 对各属性 分类器的权重进行归一化可以使其独立于正样本,有助于提升性能。
 作者实现的baseline效果更好的原因是,一个效果更好的baseline可以进行更好地进行感兴趣区域的定位。作者用GradCAM测试了其方法定位的感兴趣区域,发现已经很准确了,所以无需使用额外的注意力机制了。
作者实现的baseline效果更好的原因是,一个效果更好的baseline可以进行更好地进行感兴趣区域的定位。作者用GradCAM测试了其方法定位的感兴趣区域,发现已经很准确了,所以无需使用额外的注意力机制了。

2 代码分析
作者使用了四个trick,分别为:
-
sample-wise loss not label-wise loss;
loss = loss.sum() / batch_size if self.size_average else loss.sum()- 1
-
big learning rate combined with clip_grad_norm;
clip_grad_norm_(model.parameters(), max_norm=10.0)- 1
-
augmentation Pad combined with RandomCrop;
train_transform = T.Compose([ T.Resize((height, width)), T.Pad(10), T.RandomCrop((height, width)), T.RandomHorizontalFlip(), T.ToTensor(), normalize, ])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
add BN after classifier layer.
self.logits = nn.Sequential( nn.Linear(2048, nattr), nn.BatchNorm1d(nattr) )- 1
- 2
- 3
- 4
其余的也就是正常的训练resnet模型。

