
- 1大学生如何选择人生第一份工作_大学生职业选择的策略
- 2RabbitMQ快速上手(包含秒杀案例)_spring.rabbitmq.listener.simple.acknowledge-mode=m
- 3使用postman时,报错SSL Error: Unable to verify the first certificate
- 4hive数据仓库的应用_hive数据仓库应用
- 5基于STM32的语音识别系统
- 6CSDN获取积分方案_csdn积分如何购买
- 7对一个给定的列表进行增、删、改等操作,并输出变化后的最终列表_本关任务:对一个给定的列表进行增、删、改等操作,并输出变化后的最终列表。 列表
- 8小鱼深度产品测评之:阿里云低代码开发平台魔笔,一站式的应用全生命周期管理,高效解决应用研发、迭代、运维的问题。_阿里云魔笔
- 9使用Burp Suite进行Web应用渗透测试_burpsuite怎么web扫描
- 10RedisTemplate实现令牌桶限流
hadoop组件---spark----全面了解spark以及与hadoop的区别_hadoop组件spark基本概述
赞
踩
Spark是什么
Spark (全称 Apache Spark™) 是一个专门处理大数据量分析任务的通用数据分析引擎。
Spark核心代码是用scala语言开发的,不过支持使用多种语言进行开发调用比如scala,java,python。
Spark目前有比较完整的数据处理生态组件,可以部署在多种系统环境中,同时支持处理多种数据源。
Spark发展历史
2009年,Spark诞生于伯克利大学AMPLab,属于伯克利大学的研究性项目;
2010年,通过BSD 许可协议正式对外开源发布;
2012年,Spark第一篇论文发布,第一个正式版(Spark 0.6.0)发布;
2013年,成为了Aparch基金项目,进入高速发展期。第三方开发者贡献了大量的代码,活跃度非常高;发布Spark Streaming、Spark Mllib(机器学习)、Shark(Spark on Hadoop);
2014 年,Spark 成为 Apache 的顶级项目; 5 月底 Spark1.0.0 发布;发布 Spark Graphx(图计算)、Spark SQL代替Shark;
2015年,推出DataFrame(大数据分析);2015年至今,Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架;
2016年,Spark 2.0.0版本发布,推出dataset(更强的数据分析手段);
2017年,structured streaming 发布;
2018年,Spark2.4.0发布,成为全球最大的开源项目。
截至 2020年1月15号 目前最稳定的最后发布版本为 Spark 2.4.4。
还有一个 新值得期待的 预发布版本 Spark 3.0 主要 是增加了 与k8s等云结合使用的特性。
特点
1、速度快,适合实时分析场景
Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle),在运算方面是hadoop运算速度的一百多倍。
2、容易上手开发
Spark的基于RDD的计算模型,比Hadoop的基于Map-Reduce的计算模型要更加易于理解,更加易于上手开发,实现各种复杂功能,比如二次排序、topN等复杂操作时,更加便捷。
3、支持多种语言
Spark提供Java,Scala,Python和R中的高级API .Spark代码可以用任何这些语言编写。 它在Scala和Python中提供了一个shell。 可以通过./bin/spark-shell和Python shell通过./bin/pyspark从已安装的目录访问Scala shell。
4、支持多种格式的数据来源
Spark支持多种数据源,如Parquet,JSON,HDFS、Hbase、Hive和Cassandra,Alluxio,CSV和RDBMS表,还包括通常的格式,如文本文件、CSV和RDBMS表,甚至一些云存储比如S3等。 Data Source API提供了一种可插拔的机制,用于通过Spark SQL获取结构化数据。
5、超强的通用性
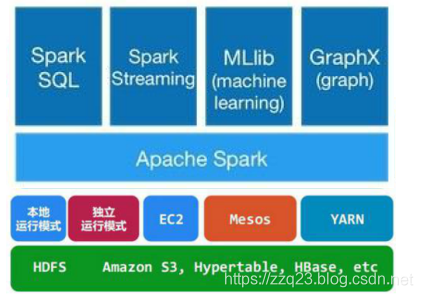
Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。
6、集成Hadoop
Spark并不是要成为一个大数据领域的“独裁者”,一个人霸占大数据领域所有的“地盘”,而是与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark负责大数据计算。实际上,Hadoop+Spark的组合,是一种“double win”的组合。
7、可以在任何环境下搭建
spark框架可以运行在各种操作系统上。
最初Spark作为hadoop的一个计算框架组件而发布,现在慢慢长大,可以独立运行了。意味着 我们不搭建Hadoop集群也能 独立的安装运行Spark。
除了运行在Hadoop集群中,
目前Spark支持
(一)local本地模式
只需要一台机器,运行该模式非常简单,只需要把Spark的安装包解压后,默认也不需修改任何配置文件,取默认值。不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS)。
运行客户端程序(可以是spark自带的命令行程序,如spark-shell,也可以是程序员利用spark api编写的程序),就可以完成相应的运行。相当于这一个客户端进程,充当了所有的角色。
这种模式,只适合开发阶段使用,我们可以在该模式下开发和测试代码,使的代码的逻辑没问题,后面再提交到集群上去运行和测试。
如果是学习或者做测试,为了搭建环境的简化,可以搭建本地模式。
在实际生产环境,spark会采用集群模式来运行,即分布式式运行,spark可以使用多种集群资源管理器来管理自己的集群。
(二)独立的Spark集群standalone模式
Standalone模式,即独立模式,自带完整的服务,使用spark自带的集群资源管理功能。可单独部署到一个集群中,无需依赖任何其他资源管理系统。即每台机器上只需部署下载的Spark版本即可。
这种模式需要提前启动spark的master和Worker守护进程,才能运行spark客户端程序。
因为Standalone模式不需要依赖任何第三方组件,如果数据量比较小,且不需要hadoop(如不需要访问hdfs服务),则使用Standalone模式是一种可选的简单方便的方案。
(三)在aws的ec2中安装
这种模式类似于Standalone模式,不过部署的集群是aws的ec2服务器,需要有一些 权限方面的配置,在GitHub中有专门针对 ec2中部署spark的脚本项目, 可以直接根据其中的步骤进行部署。
(四)使用yarn进行管理
该模式,使用hadoop的YARN作为集群资源管理器。这种模式下因为使用yarn的服务进行资源管理,所以不需要启动Spark的Master、Worker守护进程。
如果你的应用不仅使用spark,还用到hadoop生态圈的其它服务,从兼容性上考虑,使用Yarn作为统一的资源管理是更好的选择,这样选择这种模式就比较适合。
目前spark on yarn的部署方式 最为常用。
(五)使用mesos进行管理
该模式,使用Mesos作为集群资源管理器。如果你的应用还使用了docker,则选择此模式更加通用。
(六)使用k8s进行管理
Spark本身的设计更偏向使用静态的资源管理,虽然Spark也支持了类似Yarn等动态的资源管理器,但是这些资源管理并不是面向动态的云基础设施而设计的,在速度、成本、效率等领域缺乏解决方案。
随着Kubernetes的快速发展,数据科学家们开始考虑是否可以用Kubernetes的弹性与面向云原生等特点与Spark进行结合。
在Spark 2.3中,Resource Manager中添加了Kubernetes原生的支持。
意味着 我们可以使用k8s对Spark进行管理了,而且能运用云的特性,很好的进行集群伸缩,降低我们的成本以及当运算资源不足时快速增加节点。
(七) 伪分布集群模式
即在一台机器上模拟集群下的分布式场景,会启动多个进程。上述的集群模式都可以启动伪分布式集群模式,当然要求机器的配置满足要求。
这种模式主要是开发阶段和学习使用。
8、极高的社区活跃度
Spark目前是Apache基金会的顶级项目,全世界有大量的优秀工程师是Spark的committer。并且世界上很多顶级的IT公司都在大规模地使用Spark。
spark的使用场景
物联网领域: 通过物联网的设备收集到海量的数据,比如环境监控,海洋监控,地震预测等,需要及时的处理反馈。
大健康领域: 用户健康生活与遗传信息基因等数据的分析,反馈健康方面的信息给用户
医疗保健:医疗保健领域使用实时分析来持续检查关键患者的医疗状况。寻找血液和器官移植的医院需要在紧急情况下保持实时联系。及时就医是患者生死攸关的问题。
政府:政府机构主要在国家安全领域进行实时分析。各国需要不断跟踪警察和安全机构对于威胁的更新。
电信:以电话,视频聊天和流媒体实时分析等形式围绕服务的公司,以减少客户流失并保持领先竞争优势。他们还提取移动网络的测量结果。
银行业务:银行业务几乎涉及全球所有资金。确保整个系统的容错事务变得非常重要。通过银行业务的实时分析,可以实现欺诈检测。
股票市场:股票经纪人使用实时分析来预测股票投资组合的变动。公司通过使用实时分析来推销其品牌的市场需求,从而重新思考其业务模式。
使用spark的公司和项目也非常多,可以参考官网列表
Project and Product names using
hadoop和spark的关系与区别
Spark作为Hadoop生态中重要的一员,其发展速度堪称恐怖,不过其作为一个完整的技术栈,在技术和环境的双重刺激下,得到如此多的关注也是有依据的。
Spark核心在于内存计算模型代替Hadoop生态的MapReduce离线计算模型,用更加丰富Transformation和Action算子来替代map,reduce两种算子。
计算流程的区别
Hadoop这项大数据处理技术大概已有十年历史,而且被看做是首选的大数据集合处理的解决方案。
MapReduce是单流程的优秀解决方案,不过对于需要多流程计算和算法的用例来说,并非十分高效。
数据处理流程中的每一步都需要一个Map阶段和一个Reduce阶段,而且如果要利用这一解决方案,需要将所有用例都转换成MapReduce模式。
在下一步开始之前,上一步的作业输出数据必须要存储到分布式文件系统中。因此,复制和磁盘存储会导致这种方式速度变慢。
另外Hadoop解决方案中通常会包含难以安装和管理的集群。而且为了处理不同的大数据用例,还需要集成多种不同的工具(如用于机器学习的Mahout和流数据处理的Storm)。
如果想要完成比较复杂的工作,就必须将一系列的MapReduce作业串联起来然后顺序执行这些作业。每一个作业都是高时延的,而且只有在前一个作业完成之后下一个作业才能开始启动。
而Spark则允许程序开发者使用有向无环图(DAG)开发复杂的多步数据管道。而且还支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一个数据。
Spark运行在现有的Hadoop分布式文件系统基础之上(HDFS)提供额外的增强功能。
它支持将Spark应用部署到现存的Hadoop v1集群(with SIMR – Spark-Inside-MapReduce)或Hadoop v2 YARN集群甚至是Apache Mesos之中。
我们应该将Spark看作是Hadoop MapReduce的一个替代品而不是Hadoop的替代品。其意图并非是替代Hadoop,而是为了提供一个管理不同的大数据用例和需求的全面且统一的解决方案。

关键区别
hadoop是批处理工具,更擅长处理离线数据,而spark在内存中处理数据,可以是实时处理。
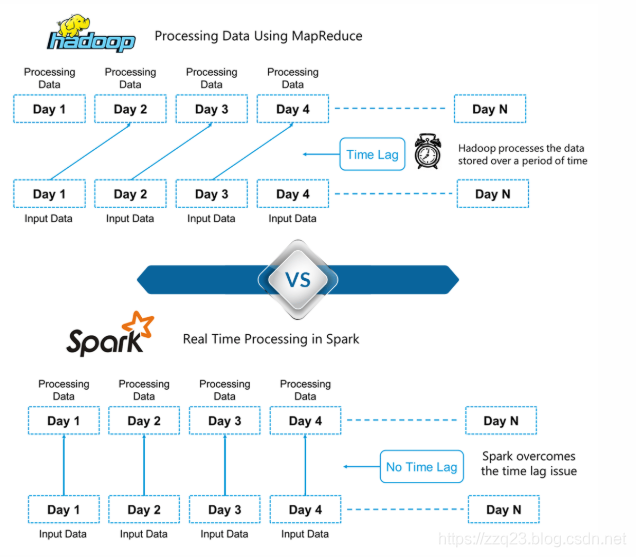
Hadoop基于大数据的批处理。 这意味着数据会在一段时间内先存储下来,然后使用Hadoop进行处理。
在Spark中,处理可以实时进行。
Spark中的这种实时处理能力帮助我们解决实时分析问题。
除此之外,Spark能够比Hadoop MapReduce( Hadoop处理框架)快100倍地进行批处理。
因此,目前Apache Spark是业界大数据处理的首选工具。
hadoop和spark发展的历史故事参考
https://www.zhihu.com/question/23036370?sort=created
组件框架的区别
针对核心关键的功能 ,Hadoop和Spark都发展出了相应的组件
| Hadoop | Spark | |
|---|---|---|
| 处理引擎 | Mapreduce | Spark RDD(Spark Core) |
| 交互式查询 | Hive | Spark SQL |
| 实时流计算 | Storm | Spark Streaming |
| 机器学习 | Mahout | MLlib |
| 图计算 | Hama或者 Giraph | GraphX |
Spark相关概念
Spark Shell
Spark的shell提供了一种学习API的简单方法,以及一种以交互方式分析数据的强大工具。
Spark Session
在早期版本的Spark中,Spark Context是Spark的入口点。 对于每个其他API,我们需要使用不同的上下文。 对于流式传输,我们需要StreamingContext,SQL sqlContext和hive HiveContext。 为了解决这个问题,SparkSession应运而生。 它本质上是SQLContext,HiveContext和StreamingContext的组合。
数据源
Data Source API提供了一种可插拔的机制,用于通过Spark SQL访问结构化数据。 Data Source API用于将结构化和半结构化数据读取并存储到Spark SQL中。 数据源不仅仅是简单的管道,可以转换数据并将其拉入Spark。
RDD
弹性分布式数据集(RDD)是Spark的基本数据结构。 它是一个不可变的分布式对象集合。 RDD中的每个数据集被划分为逻辑分区,其可以在集群的不同节点上计算。 RDD可以包含任何类型的Python,Java或Scala对象,包括用户定义的类。
RDD可被分发到集群各个节点上,进行并行操作。RDDs 可以通过 Hadoop InputFormats 创建(如 HDFS),或者从其他 RDDs 转化而来。
获得RDD的三种方式:
Parallelize:将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试
>>>sc.parallelize(['cat','apple','bat’])
- 1
MakeRDD:只有scala版本才有此函数,用法与parallelize类似
textFile:从外部存储中读取数据来创建 RDD
>>>sc.textFile(“file\\\usr\local\spark\README.md”)
- 1
RDD的两个特性:不可变;分布式。
RDD支持两种操作;
Transformation(转化操作:返回值还是RDD)如map(),filter()等。这种操作是lazy(惰性)的,即从一个RDD转换生成另一个RDD的操作不是马上执行,只是记录下来,只有等到有Action操作是才会真正启动计算,将生成的新RDD写到内存或hdfs里,不会对原有的RDD的值进行改变;
Action(行动操作:返回值不是RDD)会实际触发Spark计算,对RDD计算出一个结果,并把结果返回到内存或hdfs中,如count(),first()等。
RDD的缓存策略
Spark最为强大的功能之一便是能够把数据缓存在集群的内存里。这通过调用RDD的cache函数来实现:rddFromTextFile.cache,
调用一个RDD的cache函数将会告诉Spark将这个RDD缓存在内存中。在RDD首次调用一个执行操作时,这个操作对应的计算会立即执行,数据会从数据源里读出并保存到内存。因此,首次调用cache函数所需要的时间会部分取决于Spark从输入源读取数据所需要的时间。但是,当下一次访问该数据集的时候,数据可以直接从内存中读出从而减少低效的I/O操作,加快计算。多数情况下,这会取得数倍的速度提升。
广播变量
广播变量(broadcast variable)为只读变量,它由运行SparkContext的驱动程序创建后发送给会参与计算的节点。对那些需要让各工作节点高效地访问相同数据的应用场景,比如机器学习,这非常有用。Spark下创建广播变量只需在SparkContext上调用一个方法即可:
>>> broadcastAList = sc.broadcast(list(["a", "b", "c", "d", "e"]))
- 1
- 2
累加器Accumulator
在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark Streaming应用中记录某些事件的数量。
使用累加器时需要注意只有Driver能够取到累加器的值,Task端进行的是累加操作。
创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
后续我们会记录累加器的用法。
Dataset
Dataset是分布式数据集合。 数据集可以从JVM对象构造,然后使用功能转换(map,flatMap,filter等)进行操作。 数据集API在Scala和Java中可用。
DataFrames
DataFrame是命名列组织成数据集。 它在概念上等同于关系数据库中的表或R / Python中的数据框,但在引擎盖下具有更丰富的优化。 DataFrame可以从多种来源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。
RDD、Dataframe、DataSet区别
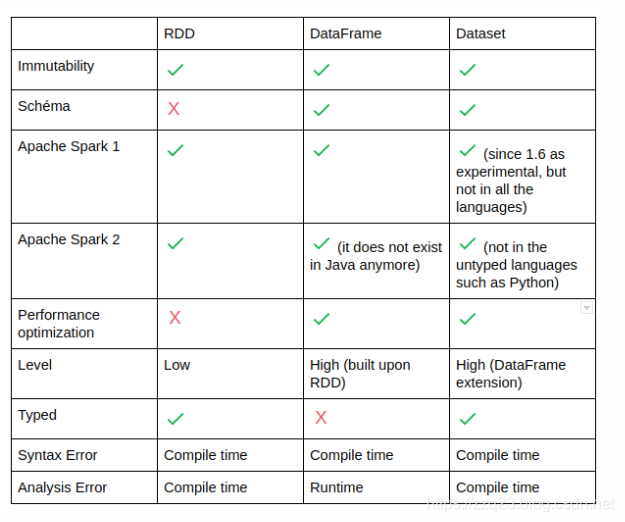
spark中 RDD、DataFrame、Dataset的关系及区别 以及相互转换
Spark 组件
Spark组件使Apache Spark快速可靠。 构建了很多这些Spark组件来解决使用Hadoop MapReduce时出现的问题。 Apache Spark具有以下组件:
Spark Core
Spark Streaming
Spark SQL
GraphX
MLlib (Machine Learning)
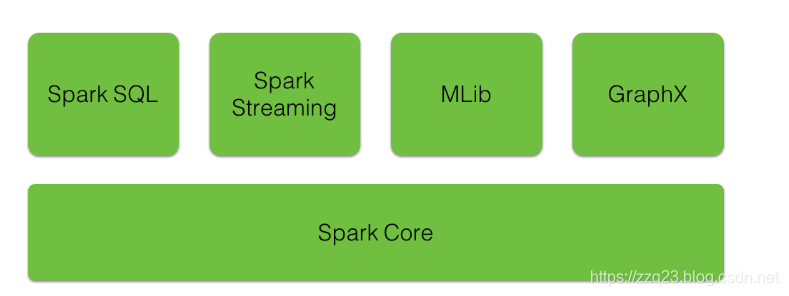
用户使用的SQL、Streaming、MLib、GraphX接口最终都会转换成Spark Core分布式运行。
Spark Core
Spark Core是大规模并行和分布式数据处理的基础引擎。 核心是分布式执行引擎,Java,Scala和Python API为分布式ETL应用程序开发提供了一个平台。 此外,在核心上构建的其他库允许用于流式传输,SQL和机器学习的各种工作负载。 它负责:
内存管理和故障恢复
在群集上调度,分发和监视作业
与存储系统交互
Spark Streaming
Spark Streaming是Spark的组件,用于处理实时流数据。 因此,它是核心Spark API的补充。 它支持实时数据流的高吞吐量和容错流处理。 基本流单元是DStream,它基本上是一系列用于处理实时数据的RDD(弹性分布式数据集)。
Spark Streaming是spark中一个非常重要的扩展库,它是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、以及TCP socket等,从数据源获取数据之后,可以使用诸如map、reduce和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统和数据库等。
但从Spark2.0开始,提出了新的实时流框架 Structured Streaming (2.0和2.1是实验版本,从Spark2.2开始为稳定版本)来替代Spark streaming,这时Spark streaming就进入维护模式。相比Spark Streaming,Structured Streaming的Api更加好用,功能强大。
Spark SQL
Spark SQL是Spark中的一个新模块,它使用Spark编程API实现集成关系处理。 它支持通过SQL或Hive查询查询数据。 对于那些熟悉RDBMS的人来说,Spark SQL将很容易从之前的工具过渡到可以扩展传统关系数据处理的边界。
Spark SQL通过函数编程API集成关系处理。 此外,它为各种数据源提供支持,并且使用代码转换编织SQL查询,从而产生一个非常强大的工具。
以下是Spark SQL的四个库。
Data Source API
DataFrame API
Interpreter & Optimizer
SQL Service
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。Spark SQL支持多种数据源类型,例如Hive表、Parquet以及JSON等。Spark SQL不仅为Spark提供了一个SQL接口,还支持开发者将SQL语句融入到Spark应用程序开发过程中,无论是使用Python、Java还是Scala,用户可以在单个的应用中同时进行SQL查询和复杂的数据分析。
GraphX
GraphX是用于图形和图形并行计算的Spark API。 因此,它使用弹性分布式属性图扩展了Spark RDD。
属性图是一个有向多图,它可以有多个平行边。 每个边和顶点都有与之关联的用户定义属性。 这里,平行边缘允许相同顶点之间的多个关系。 在高层次上,GraphX通过引入弹性分布式属性图来扩展Spark RDD抽象:一个定向多图,其属性附加到每个顶点和边。
为了支持图形计算,GraphX公开了一组基本运算符(例如,subgraph,joinVertices和mapReduceTriplets)以及Pregel API的优化变体。 此外,GraphX包含越来越多的图算法和构建器,以简化图形分析任务。
GraphX是Spark面向图计算提供的框架与算法库。GraphX中提出了弹性分布式属性图的概念,并在此基础上实现了图视图与表视图的有机结合与统一;同时针对图数据处理提供了丰富的操作,例如取子图操作subgraph、顶点属性操作mapVertices、边属性操作mapEdges等。GraphX还实现了与Pregel的结合,可以直接使用一些常用图算法,如PageRank、三角形计数等。
MlLib (Machine Learning)
MLlib代表机器学习库。 Spark MLlib用于在Apache Spark中执行机器学习。
MLlib是Spark提供的一个机器学习算法库,其中包含了多种经典、常见的机器学习算法,主要有分类、回归、聚类、协同过滤等。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语,包括一个通用的梯度下降优化基础算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
如何运行Spark程序
在实际编程中,我们不需关心以上调度细节.只需使用 Spark 提供的指定语言的编程接口调用相应的 API 即可.
在 Spark API 中, 一个 应用(Application) 对应一个 SparkContext 的实例。一个 应用 可以用于单个 Job,或者分开的多个 Job 的 session,或者响应请求的长时间生存的服务器。与 MapReduce 不同的是,一个 应用 的进程(我们称之为 Executor),会一直在集群上运行,即使当时没有 Job 在上面运行。
而调用一个Spark内部的 Action 会产生一个 Spark job 来完成它。 为了确定这些job实际的内容,Spark 检查 RDD 的DAG再计算出执行 plan 。这个 plan 以最远端的 RDD 为起点(最远端指的是对外没有依赖的 RDD 或者 数据已经缓存下来的 RDD),产生结果 RDD 的 Action 为结束 。并根据是否发生 shuffle 划分 DAG 的 stage.
Spark原生架构和运行原理
架构和粗流程描述
一个完整的Spark应用程序,在提交集群运行时,它的处理流程涉及到如下图所示的架构:
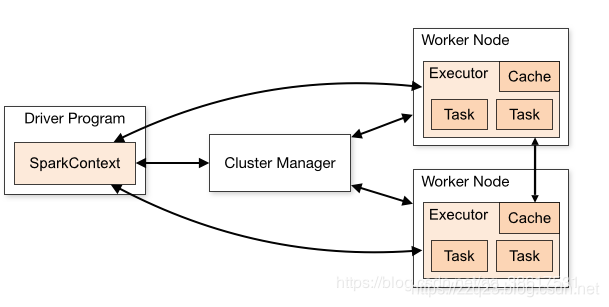
每个Spark应用都由一个驱动器程序(drive program)来发起集群上的各种并行操作。
驱动器程序包含应用的main函数。
驱动器负责创建SparkContext。
SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop YARN,Mesos进行通信。
获取到集群进行所需的资源后,SparkContext将得到集群中工作节点(Worker Node)上对应的Executor。
不同的Spark程序有不同的Executor,他们之间是相互独立的进程,Executor为应用程序提供分布式计算以及数据存储功能。
之后SparkContext将应用程序代码发送到各Executor,将任务(Task)分配给executors执行。
ClusterManager
在Standalone模式中即为Master节点(主节点),控制整个集群,监控Worker.在YARN中为ResourceManager
Worker
从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
Driver
运行Application的main()函数并创建SparkContect。
Executor
执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
SparkContext
整个应用的上下文,控制应用的生命周期。
RDD
Spark的计算单元,一组RDD可形成执行的有向无环图RDD Graph。
DAG Scheduler
根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
TaskScheduler
将任务(Task)分发给Executor。
SparkEnv
线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内构建并包含如下一些重要组件的引用。
1)MapOutPutTracker:负责Shuffle元信息的存储。
2)BroadcastManager:负责广播变量的控制与元信息的存储。
3)BlockManager:负责存储管理、创建和查找快。
4)MetricsSystem:监控运行时性能指标信息。
5)SparkConf:负责存储配置信息。
详细流程描述
使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。
根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。
而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standalone集群,也可以是其他的资源管理集群,比如使用YARN作为资源管理集群)申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。
YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。
Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批Task,然后将这些Task分配到各个Executor进程中执行。
Task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个Task处理的数据不同而已。
一个stage的所有Task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。
下一个stage的Task的输入数据就是上一个stage输出的中间结果。
如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。
如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。
可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。
因此一个stage刚开始执行的时候,它的每个Task可能都会从上一个stage的Task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个Task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:
第一块是让Task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让Task通过shuffle过程拉取了上一个stage的Task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
Task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。
一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个Task,都是以每个Task一条线程的方式,多线程并发运行的。
如果CPU core数量比较充足,而且分配到的Task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些Task线程。
以上就是Spark作业的基本运行原理的说明.
shuffle 和 stage
shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤.
RDD 的 Transformation 函数中,又分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作.
窄依赖跟宽依赖的区别在于 是否发生 shuffle(洗牌) 操作.
宽依赖会发生 shuffle 操作. 窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果,宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片, 看如下两个示例:
// Map: "cat" -> c, cat
val rdd1 = rdd.Map(x => (x.charAt(0), x))
// groupby same key and count
val rdd2 = rdd1.groupBy(x => x._1).
Map(x => (x._1, x._2.toList.length))
- 1
- 2
- 3
- 4
- 5
第一个 Map 操作将 RDD 里的各个元素进行映射, RDD 的各个数据元素之间不存在依赖,可以在集群的各个内存中独立计算,也就是并行化
第二个 groupby 之后的 Map 操作,为了计算相同 key 下的元素个数,需要把相同 key 的元素聚集到同一个 partition 下,所以造成了数据在内存中的重新分布,即 shuffle 操作.
shuffle 操作是 spark 中最耗时的操作,应尽量避免不必要的 shuffle.
宽依赖主要有两个过程: shuffle write 和 shuffle fetch.
类似 Hadoop 的 Map 和 Reduce 阶段.
shuffle write 将 ShuffleMapTask 任务产生的中间结果缓存到内存中, shuffle fetch 获得 ShuffleMapTask 缓存的中间结果进行 ShuffleReduceTask 计算,这个过程容易造成OutOfMemory.
shuffle 过程内存分配使用 ShuffleMemoryManager 类管理,会针对每个 Task 分配内存,Task 任务完成后通过 Executor 释放空间.
这里可以把 Task 理解成不同 key 的数据对应一个 Task.
早期的内存分配机制使用公平分配,即不同 Task 分配的内存是一样的,但是这样容易造成内存需求过多的 Task 的 OutOfMemory, 从而造成多余的 磁盘 IO 过程,影响整体的效率.
(例:某一个 key 下的数据明显偏多,但因为大家内存都一样,这一个 key 的数据就容易 OutOfMemory).
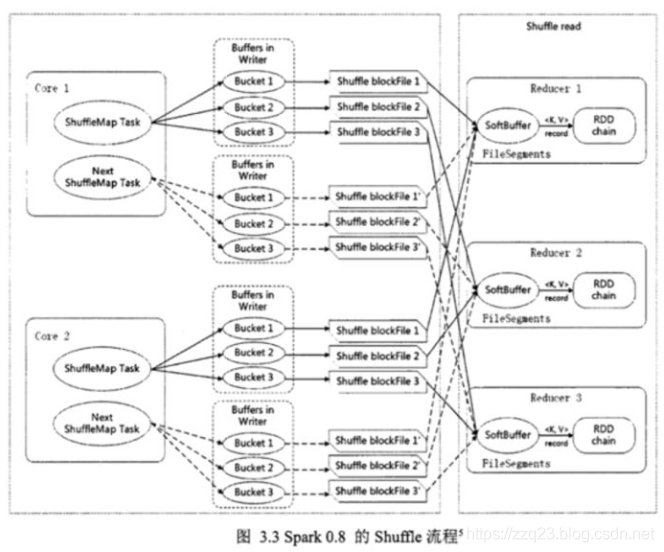
1.5版以后 Task 共用一个内存池,内存池的大小默认为 JVM 最大运行时内存容量的16%
分配机制如下:
假如有 N 个 Task,ShuffleMemoryManager 保证每个 Task 溢出之前至少可以申请到1/2N 内存,且至多申请到1/N
N 为当前活动的 shuffle Task 数
因为N 是一直变化的,所以 manager 会一直追踪 Task 数的变化,重新计算队列中的1/N 和1/2N.
但是这样仍然容易造成内存需要多的 Task 任务溢出,所以最近有很多相关的研究是针对 shuffle 过程内存优化的.
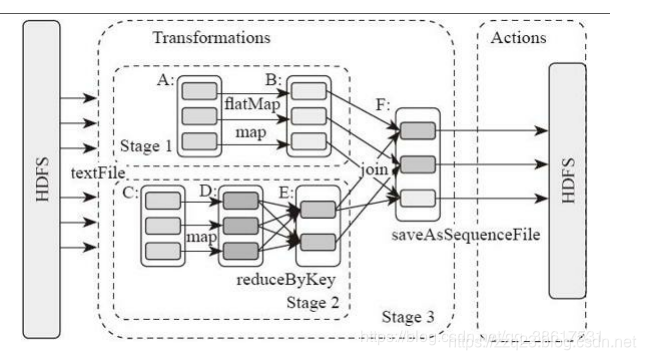
如下 DAG 流程图中,分别读取数据,经过处理后 join 2个 RDD 得到结果
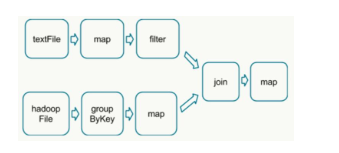
在这个图中,根据是否发生 shuffle 操作能够将其分成如下的 stage 类型:
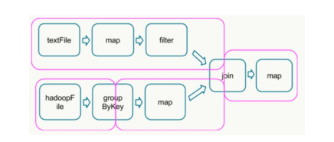
(join 需要针对同一个 key 合并,所以需要 shuffle)
运行到每个 stage 的边界时,数据在父 stage 中按照 Task 写到磁盘上,而在子 stage 中通过网络按照 Task 去读取数据。这些操作会导致很重的网络以及磁盘的I/O,所以 stage 的边界是非常占资源的,在编写 Spark 程序的时候需要尽量避免的 。父 stage 中 partition 个数与子 stage 的 partition 个数可能不同,所以那些产生 stage 边界的 Transformation 常常需要接受一个 numPartition 的参数来觉得子 stage 中的数据将被切分为多少个 partition[^demoa]。
PS:shuffle 操作的时候可以用 combiner 压缩数据,减少 IO 的消耗
Spark原生框架处理数据流程
1、Client提交应用。
2、Master找到一个Worker启动Driver
3、Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph
4、再由DAGSchedule将RDD Graph转化为Stage的有向无环图提交给TaskSchedule。
5、再由TaskSchedule提交任务给Executor执行。
6、其它组件协同工作,确保整个应用顺利执行。
Executor执行任务原理
Executor完成一个任务需要做两部分工具,一部分就是加载数据源,也就是Spark的基础数据单元RDD。
RDD的数据来源可以是多种多样的,我们这里以HDFS为例。
Spark支持两种RDD操作:transformation和action。
transformation操作
transformation操作会针对已有的RDD创建一个新的RDD。
transformation具有lazy特性,即transformation不会触发spark程序的执行,它们只是记录了对RDD所做的操作,不会自发的执行。
只有执行了一个action,之前的所有transformation才会执行。
常用的transformation介绍:
map :将RDD中的每个元素传人自定义函数,获取一个新的元素,然后用新的元素组成新的RDD。
filter:对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除。
flatMap:与map类似,但是对每个元素都可以返回一个或多个元素。
groupByKey:根据key进行分组,每个key对应一个Iterable。
reduceByKey:对每个key对应的value进行reduce操作。
sortByKey:对每个key对应的value进行排序操作。
join:对两个包含<key,value>对的RDD进行join操作,每个keyjoin上的pair,都会传入自定义函数进行处理。
cogroup:同join,但是每个key对应的Iterable都会传入自定义函数进行处理。
action操作
action操作主要对RDD进行最后的操作,比如遍历,reduce,保存到文件等,并可以返回结果给Driver程序。
action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行,这是action的特性。
常用的action介绍:
reduce:将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。
collect:将RDD中所有元素获取到本地客户端(一般不建议使用)。
count:获取RDD元素总数。
take(n):获取RDD中前n个元素。
saveAsTextFile:将RDD元素保存到文件中,对每个元素调用toString方法。
countByKey:对每个key对应的值进行count计数。
foreach:遍历RDD中的每个元素。
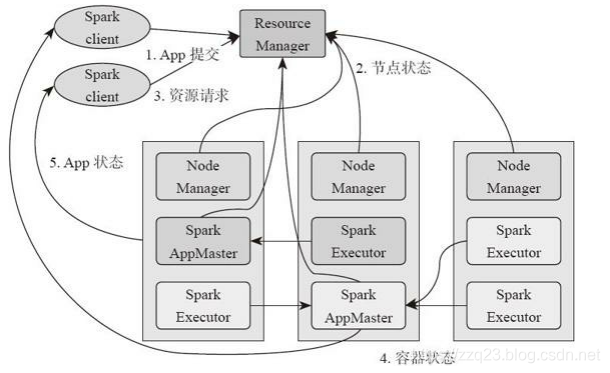
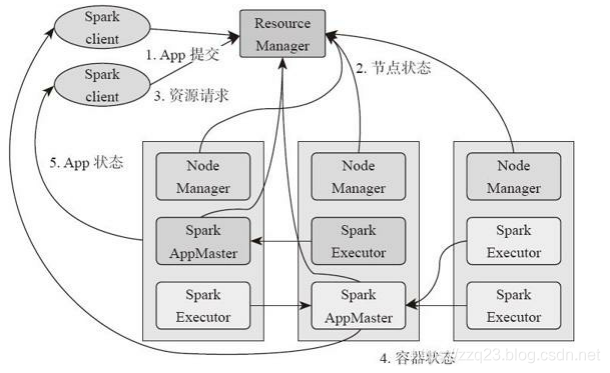
Spark on yarn 框架处理数据流程
1、基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager。
2、ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager。
3、NodeManager启动SparkAppMaster。
4、SparkAppMastere启动后初始化然后向ResourceManager申请资源。
5、申请到资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor。
6、SparkExecutor向SparkAppMaster汇报并完成相应的任务。
7、SparkClient会通过AppMaster获取作业运行状态。
如何运行Spark程序
在实际编程中,我们不需要关心调度细节.
只需使用 Spark 提供的指定语言的编程接口调用相应的 API 即可.
在 Spark API 中, 一个 应用(Application) 对应一个 SparkContext 的实例。
一个 应用 可以用于单个 Job,或者分开的多个 Job 的 session,或者响应请求的长时间生存的服务器。
与 MapReduce 不同的是,一个 应用 的进程(我们称之为 Executor),会一直在集群上运行,即使当时没有 Job 在上面运行。
而调用一个Spark内部的 Action 会产生一个 Spark job 来完成它。
为了确定这些job实际的内容,Spark 检查 RDD 的DAG再计算出执行 plan 。
这个 plan 以最远端的 RDD 为起点(最远端指的是对外没有依赖的 RDD 或者 数据已经缓存下来的 RDD),产生结果 RDD 的 Action 为结束 。
并根据是否发生 shuffle 划分 DAG 的 stage.
参考链接:
https://www.aboutyun.com/forum.php?mod=viewthread&tid=24883
https://www.cnblogs.com/cxxjohnson/p/8909578.html

