
- 1首发AI原生应用开发平台——千帆AI原生应用开发工作台,加速企业AI应用落地_ai工作台
- 2OllamaFunctions 学习笔记_ollama function call
- 3springboot 国际化实践_message.properties
- 4绝对的宝藏文章:深入讲解LCD1602指令集(附上代码演示及现象讲解)_lcd1602初始化程序解释
- 5LeetCode 16 - 3Sum Closest
- 6毕业论文ai生成免费推荐哪家好用?_免费ai毕业设计论文
- 7git提交代码常用命令_git强制提交
- 8功能测试如何转型自动化测试_怎么从功能测试转型
- 9androidstudio汉化插件,Android高级工程师必看系列_安卓studio中文插件
- 10尚硅谷电商分析平台笔记1_尚硅谷电商用户行为数据分析笔记
bert简介_BERT在小米NLP业务中的实战探索
赞
踩
1 . 引言
近年来,预训练模型在自然语言处理(Natural Language Processing, NLP)领域大放异彩,其中最重要的工作之一就是Google于2018年发布的BERT预训练模型[1]。自被发布以来,BERT预训练模型就在多项自然语言理解任务上取得了优异的效果,并开启了预训练-微调的NLP范式时代,启发了NLP领域后续一系列的预训练模型工作。与此同时,BERT模型在NLP相关工业领域也得到了广泛应用,并取得了良好的效果。但由于工业领域相关业务的数据格式的复杂性,以及工业应用对推理性能的要求,BERT模型往往不能简单直接地被应用于NLP业务之中,需要根据具体场景和数据对BERT模型加以调整和改造,以适应业务的现实需求。
小米AI实验室NLP团队自创建以来,就积极探索NLP前沿领域,致力于将先进的NLP技术应用于公司的核心业务中,支撑信息流、搜索推荐、语音交互等业务对NLP技术的需求。近期,我们对BERT预训练模型在各项业务中的应用进行了探索研究工作,使用各项深度学习技术利用和改造强大的BERT预训练模型,以适应业务的数据形态和性能需求,取得了良好的效果,并应用到了对话理解、语音交互、NLP基础算法等多个领域。下面,我们将具体介绍BERT在小米NLP业务中的实战探索,主要分为三个部分:第一部分是BERT预训练模型简介,第二部分是BERT模型实战探索,第三部分是总结与思考。
2. BERT预训练模型简介
BERT预训练模型的全称是基于Transformer的双向编码表示(Bidirectional Encoder Representations from Transformers, BERT),其主要思想是:采用Transformer网络[2]作为模型基本结构,在大规模无监督语料上通过掩蔽语言模型和下句预测两个预训练任务进行预训练(Pre-training),得到预训练BERT模型。再以预训练模型为基础,在下游相关NLP任务上进行模型微调(Fine-tuning)。BERT预训练模型能够充分利用无监督预训练时学习到的语言先验知识,在微调时将其迁移到下游NLP任务上,在11项下游自然语言处理任务上取得了优异的效果,开启了自然语言处理的预训练新范式。接下来,我们具体介绍BERT模型的模型结构、预训练方法和微调方法。
2.1 模型结构
BERT 模型的结构主要由三部分构成:输入层、编码层和任务相关层,其中输入层和编码层是通用的结构,对于每一个任务都适用,因此我们主要介绍这两个部分。
BERT 模型的输入层包括词嵌入(token embedding)、位置嵌入(position embedding)段嵌入(segment embedding)。与原始Transformer不同的是, BERT模型的位置嵌入是可学习的参数,最大支持长度为 512 个位置。同时, BERT模型的段嵌入用于在输入序列包含两个句子时区分两个句子。具体来说, BERT 模型在第一个句子上使用段A嵌入,在第二个句子上使用段B嵌入。另外, BERT模型在输入序列的第一个位置加上一个特殊的[CLS] 标记用于聚合句子表示信息,并在两个句子之间使用特殊标记[SEP] 用于分隔两个句子。 BERT 的输入层将每个词的词嵌入、位置嵌入和段嵌入相加得到每个词的输入表示,如图1所示。

图1. BERT模型的输入层
BERT模型的编码层直接使用了Transformer编码器[2]来编码输入序列的表示,将编码层的层数记为L,把隐藏层的维度记为H,把多头注意力的头数记为A,多头注意力中的每个头的子空间维度设为H/A,前馈神经网络的中间层维度设为4H。这样BERT模型的Transformer编码层就由L, H, A三个超参数决定。Devlin et al.[1]定义了两种尺寸的BERT模型:
- :L=12, H=768, A=12
- :L=24, H=1024, A=16
BERT模型的任务相关层则根据下游任务不同而有所不同,如对于文本分类任务,任务相关层通常为带softmax的线性分类器。
2.2 预训练方法
BERT 模型采用了两个预训练任务:一是掩蔽语言模型(Masked Language Model, MLM),二是下句预测(Next Sentence Prediction, NSP)。通过这两个预训练任务,BERT模型能够学习到先验的语言知识,并在后面迁移给下游任务。BERT模型的预训练方法如图2所示。
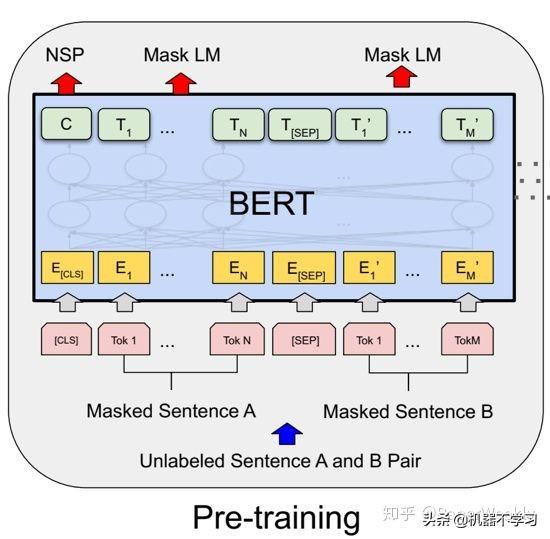
图2. BERT模型的预训练方法
BERT 模型的第一个预训练任务是掩蔽语言模型。掩蔽语言模型(MLM)的原理是:随机选取输入序列中的一定比例(15%)的词,其中80%的概率用掩蔽标记[MASK]替换,10%的概率随机替换成其他词,10%的概率保持不变,然后根据双向上下文的词预测这些被掩蔽的词。预训练时BERT模型通过最大化被掩蔽词的概率来预训练掩蔽语言模型。
BERT 模型的第二个预训练任务是下句预测。下句预测(NSP)任务的主要目标是:根据输入的两个句子 A 和 B,预测出句子 B 是否是句子 A 的下一个句子。下句预测任务使用 BERT 模型编码后第一个位置([CLS])对应的向量表示,来得到句子 B 是句子 A 下一个句子的概率 。预训练时,若句子 B 是句子 A 在语料中的下一个句子,BERT模型最大化如上所述的下句概率;否则最小化该下句概率。
BERT模型预训练的目标函数,是两个预训练任务的似然概率之和。
2.3 微调方法
经过预训练的 BERT 模型可以用于下游的自然语言处理任务。在使用时,主要是在预训练 BERT 模型的基础上加入任务相关部分,再在特定任务上进行微调(fine-tuning), BERT 模型在几个下游自然语言处理任务上的微调方法如图3所示。
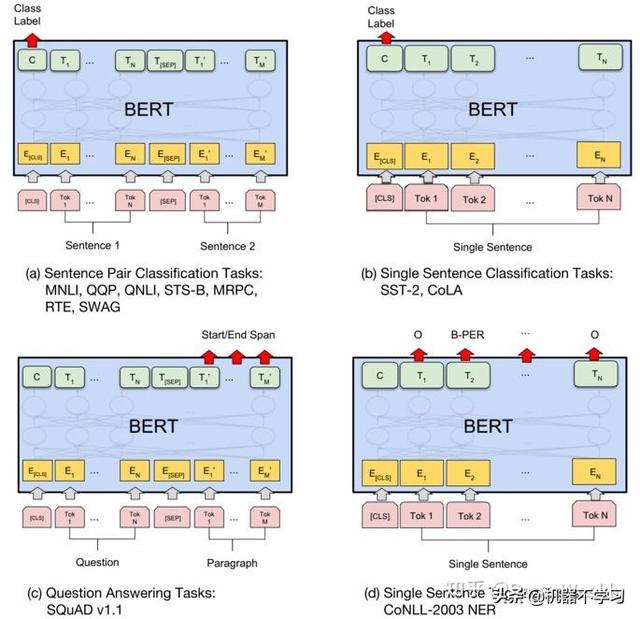
图3. BERT模型的微调方法
通常,我们取出 BERT 模型最后一层的向量表示,送入任务相关层中(通常是简单的线性变换层),就可以得到任务所要建模的目标概率。例如,在文本分类任务中,我们取出最后一层[CLS] 标记对应的向量表示,再进行线性变换和 softmax 归一化就可以得到分类概率。在微调时, BERT 模型和任务相关层的所有参数都一起更新,最优化当前下游任务的损失函数。
基于预训练-微调范式的 BERT 模型具有许多优点。通过在大规模无监督语料上的预训练, BERT 模型可以引入丰富的先验语义知识,为下游任务提供更好的初始化,减轻在下游任务上的过拟合,并降低下游任务对大规模数据的依赖。同时, BERT 模型使用的深层 Transformer 编码层具有很强的表征能力,因此下游任务不需要太复杂的任务相关层,这简化了下游任务的模型设计,为各项不同的自然语言处理任务提供一个统一的框架。
3. BERT模型实战探索
在BERT模型的实际应用中,往往需要根据具体业务形态对BERT模型进行调整。原始的BERT模型只能对文本序列进行建模,缺乏对其他特征的建模能力;同时BERT模型的参数过多,推理速度较慢,不能满足业务上线性能需求;另外,BERT模型需要针对每个细分任务都各自进行微调,缺乏通用性,也不能很好地利用任务之间的共享信息。在实践过程中,我们使用了特征融合、注意力机制、集成学习、知识蒸馏、多任务学习等多种深度学习技术对BERT模型进行增强或改造,将BERT模型应用到了多项具体任务之中,取得了良好的业务效果。下面,我们主要介绍BERT模型在对话系统意图识别、语音交互Query判不停、小米NLP平台多粒度分词这三项业务中的实战探索。
3.1 对话系统意图识别
意图识别是任务型对话系统的重要组成部分,对于用户对话的自然语言理解起着非常重要的作用。给定一个用户Query,意图识别模块能够将用户所要表达的意图识别出来,从而为后续的对话反馈提供重要的意图标签信息。但在意图识别的过程中,由于实体槽位知识稀疏性的问题,完全基于用户Query文本的意图识别模型很难进一步提升效果。在对Query文本进行建模时,如果能够融合槽位知识特征,模型的意图识别效果可能会得到进一步提升。因此,我们构建的意图识别模块的输入是用户Query文本和槽位标签,输出是意图类别,如下面的例子所示。
- Query文本/槽位标签:播 放 张/b-music_artist/b-mobileVideo_artist 杰/i-music_artist/i-mobileVideo_artist 的 歌
- 意图类别:music
不同于一般的意图识别只有Query文本特征,我们的融合槽位特征的意图识别模型输入还包括槽位标签特征,而且每一个位置还可能包括不止一个槽位标签。在尝试将BERT模型应用于意图识别任务时,如何将槽位标签特征合适地与BERT模型结合起来就成为一个需要解决的重要问题。由于BERT预训练模型在预训练时并没有输入槽位信息,如果直接将槽位标签特征直接放入BERT模型的输入中,将会扰乱BERT预训练模型的输入,使得预训练模型过程失去意义。因此,我们需要考虑更合理的方式融合槽位标签特征。经过探索和实验,最终我们采取了槽位注意力和融合门控机制的方法来融合槽位特征,融合了槽位特征的意图识别模型结构如图4所示。

图4. 融合槽位特征的意图识别模型
首先,我们使用预训练BERT模型编码Query文本,得到融合了预训练先验知识的文本向量Q。
接着,我们将槽位标签进行嵌入,得到槽位嵌入ES。由于每个位置可能有多个槽位标签,我们需要对槽位嵌入进行池化操作,这里我们采用了槽位注意力机制对多个槽位嵌入进行加权求和。我们采用了缩放点积注意力(Scaled Dot-Product Attention)[2]作为我们的槽位注意力机制,同时,在应用点积注意力机制之前,我们先对文本向量和槽位嵌入进行线性变换,将其映射到同一个维度的子空间。经过槽位注意力之后,多个槽位嵌入被加权平均为一个槽位向量S。
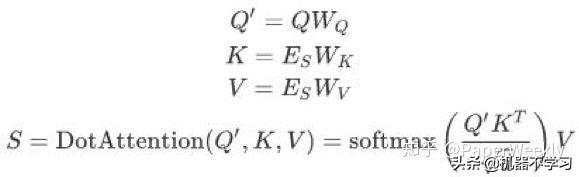
然后,我们使用融合门控机制对文本向量Q和槽位向量S进行融合,得到融合后的向量F。这里的融合门控机制类似长短期记忆网络(Long Short-Term Memory, LSTM)中的门控机制。

融合后的向量F表示每个位置的文本信息和槽位信息,但是由于融合门控机制是在每个位置上进行的,因此,单个位置上的融合向量缺乏其他位置的槽位上下文信息。为了对上下文信息进行编码,我们又使用了一个带残差连接和层归一化的多头注意力机制(Multi-Head Attention)[2]编码融合向量F,得到最终的输出向量O。
最后,我们取出第一个位置([CLS]标记对应位置)的输出向量,拼接上文本长度特征,送入带softmax的线性分类器中,得到每个意图类别上的概率,进而预测出Query对应的意图类别标签。
在业务数据上的微调实验表明,融合了槽位特征的BERT意图识别模型比只使用文本信息的BERT模型能够实现更好的效果。
3.2 语音交互Query判不停
用户在语音输入过程中会有停顿、语句不完整的现象,经过ASR识别后,得到的query文本存在不完整的情况,会影响到后续的意图识别和槽位提取。因此在送入中台之前,需要经过判不停模块识别,对于不完整query返回给ASR继续接收输入,完整query才进入中台。我们提出的语音交互query判不停模块,就是用于判断用户query是否完整的重要模块。判不停模块输入用户query文本,输出一个判不停标签,表明该query是否完整,其中'incomplete'表示query不完整,'normal'表示query完整,如下例所示。
- Query文本:播放张杰的
- 判不停标签:incomplete
判不停模型的主要难点在于线上用户query请求量大,对模型推理速度有比较严格的限制,因此普通的BERT模型无法满足判不停业务的线上性能需求。但是,能够满足性能需求的小模型由于结构过于简单,模型的准确度往往不如BERT模型。因此,我们经过思考,采取了“集成学习+知识蒸馏”的判不停系统框架,先通过集成学习,集成BERT等业务效果好的模型,实现较高的准确度。再使用知识蒸馏的方法,将集成模型的知识迁移给Albert Tiny小模型[3],从而在保证推理速度的基础上,大幅提升模型效果。“集成学习+知识蒸馏”的判不停框架如图5所示。

图5. 集成学习+知识蒸馏判不停框架
判不停框架的第一步是集成学习。目的是通过融合多个模型,减缓过拟合的问题,提升集成模型的效果。首先,我们在判不停业务数据集上训练BERT模型等多个效果好的大模型,这些效果好的大模型称之为教师模型。接着,对于每个教师模型,我们都使用它预测出每条数据对应的logits,logits本质上是softmax之前的2维向量,代表了教师模型在数据上的知识。最后,对于每条数据,我们对多个教师模型预测的logits进行集成,得到的集成logits就对应了一个集多个教师模型优点于一身的集成模型,这样的集成模型具有比单个BERT教师模型更好的效果。
判不停框架的第二步是知识蒸馏。由于推理性能限制,集成模型无法直接应用于线上判不停业务。因此我们使用知识蒸馏[4]的方法,把集成模型的知识迁移给能满足线上性能需求的小模型Albert Tiny模型,这样的小模型也被称为学生模型。蒸馏学生模型时,我们同时使用集成logits和真实标签训练学生模型,使得学生模型能够学到集成模型的知识,进一步提升学生模型的效果。具体来说,对于第i条训练数据,我们先使用Albert Tiny模型预测出该条数据对应的学生logits,记为z。另外,该条数据对应的集成模型logits记为t,对应的真实标签记为y。我们使用真实标签y和学生logits z得到通常的交叉熵损失函数,同时,我们使用集成logits t和学生logits z得到带温度平滑的蒸馏交叉熵损失函数,最终的损失函数是两种损失函数的加权求和。
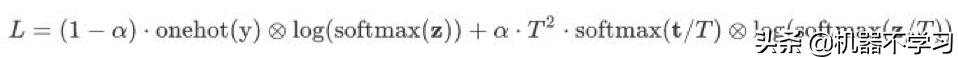
最终,经过“集成学习+知识蒸馏”的判不停框架得到的Albert Tiny小模型能够达到BERT单模型的效果,同时也能很好地满足线上的推理性能需求。
3.3 小米NLP平台多粒度分词
中文分词已经成为了众多NLP任务的基础需求,为下游任务提供基础分词服务。小米NLP平台(MiNLP平台)也开发了中文分词功能,为公司内其他NLP相关业务提供中文分词服务支撑。在实践中我们发现,不同业务对中文分词的粒度需求有所差异,短文本相关业务往往需要粒度较细的分词服务,而长文本相关业务则希望分词的粒度能够更粗一些。针对不同业务对不同粒度分词的需求,我们开发了多粒度分词算法,能够支持粗/细两种粒度的中文分词服务。多粒度分词的示例如下:
- 文本:这是一家移动互联网公司
- 粗粒度分词:这/是/一家/移动互联网/公司
- 细粒度分词:这/是/一/家/移动/互联网/公司
我们在开发基于BERT模型的多粒度分词算法时,发现如果分别在每个粒度分词的数据集上进行微调,则需要训练并部署多个不同粒度的BERT分词模型,总的模型资源消耗量与粒度的数量成线性相关。同时,不同粒度的分词结果虽然有一些差异,但依然有着很大的共性,各自训练不同粒度的BERT分词模型不能充分利用这些共性知识来提升分词效果。为了充分利用不同粒度分词的共性信息,并减少训练和部署成本,我们基于多任务学习的思路,提出了一种“基于BERT的统一多粒度分词模型"[5],用一个统一的BERT模型训练了支持多个粒度的中文分词器。
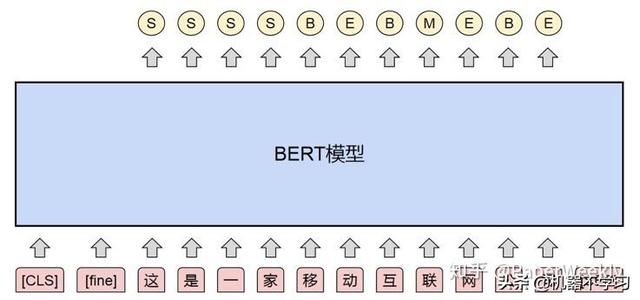
图6. 基于BERT的统一多粒度分词模型
我们提出的统一多粒度分词模型如图6所示,其主要思想是:先在输入文本中加入一个特殊的粒度标记表示粒度信息,如[fine]表示细粒度,[coarse]表示粗粒度。然后把加入了粒度标记的文本字符送入BERT模型中,再经过一个带softmax的线性分类器,把每个位置的表示映射为BMES四个分词标签上的概率。四个分词标签的含义分别是:B-词的开始,M-词的中间,E-词的结束,S-单独成词。如上面的文本得到的细粒度分词标签序列就是:
- 细粒度分词标签:这/S 是/S 一/S 家/S 移/B 动/E 互/B 联/M 网/E 公/B 司/E
最后对整个文本序列的分词标签进行解码就得到了最终的分词结果。
我们提出的统一多粒度分词模型,不仅在公司内部的多粒度分词数据上取得了更好的效果,同时也在公开多标准分词数据集上取得了SOTA(State-of-the-Art)的性能,实验结果可以参见参考文献[5]。
4 总结与思考
小米AI实验室NLP团队通过BERT模型在具体业务中的实战探索,使用特征融合、集成学习、知识蒸馏、多任务学习等深度学习技术,改造和增强了BERT预训练模型,并在对话系统意图识别、语音交互Query判不停、小米NLP平台多粒度分词等多个任务上取得了良好的效果。
同时,我们对如何进一步应用BERT模型提出一些简单的想法,留待于未来的探索和研究。首先,如何将非文本特征尤其是外部知识特征更有效地融入BERT模型之中,是一个值得深入研究的问题。另外,有些具体业务对线上推理性能有着严格的要求,这种场景下BERT模型往往不能直接进行应用,我们需要进一步探究大模型到小模型的知识迁移或模型压缩,在保证推理性能的基础之上提升模型效果。最后,公司内部的各项业务往往各自为战,在使用BERT模型时存在一些重复工作,并且不能很好地利用多个任务的共性信息,在多任务学习的基础上,打造一个各业务充分共享的BERT模型平台,服务并助益多项业务需求,是我们下一步需要努力的方向。
5. 参考文献
[1] Devlin. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL. 2019.
[2] Vaswani. Attention is all you need. NIPS. 2017.
[3] Lan. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. ICLR. 2020.
[4] Hinton. Distilling the Knowledge in a Neural Network. NIPS. 2014.
[5] Ke. Unified Multi-Criteria Chinese Word Segmentation with BERT. 2020.

