
- 1[图解]SysML和EA建模住宅安全系统-04_sysml案例 ea
- 2idea 换maven项目jdk版本_idea maven 更换项目的jdk
- 3fpga快速入门书籍推荐_fpga入门书推进
- 4实验 5 Spark SQL 编程初级实践
- 5Git忽略已经上传的文件和文件夹_git 忽略文件以及忽略已上传文件
- 6解决哈希碰撞:选择合适的方法优化哈希表性能
- 7idea java 插件开发_IDEA插件开发之环境搭建过程图文详解
- 8《五》Word文件编辑软件调试及测试
- 9ubuntu下faster-whisper安装、基于faster-whisper的语音识别示例、同步生成srt字幕文件_装faster whisper需要卸载whisper吗
- 10大疆 植保无人机T60 评测_大疆t60无人机参数
MySQL8.0 优化器介绍(一)
赞
踩
前言
线上,遇到一些sql性能问题,需要手术刀级别的调优。optimizer_trace是一个极好的工具,已经有很多资料介绍optimizer_trace怎么使用与阅读。有必要再介绍一下我们平时不太能注意到,但是又对sql性能起着绝对作用的优化器。
优化器是啥?在sql整个生命周期里处于什么样的位置,起到什么样的作用,cmu15445 课程(https://15445.courses.cs.cmu.edu/fall2022/notes/14-optimization.pdf)中对此有一些直观的描述。
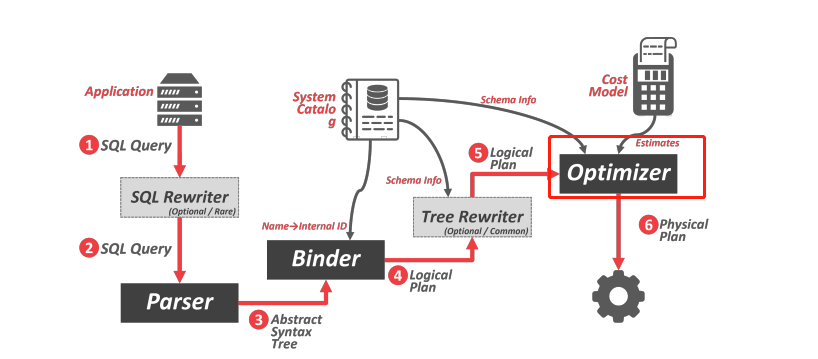
以上图片有6大模块,每一个模块都是一个单独的领域。以优化器为例,从1979年到现在,已经发展出来9个细分的研究领域:
Planner framework
Transformation
Join Order Optimization
Functional Dependency and Physical Properties
Cost Model
Statistics
Query feedback loop
MPP optimization
BENCHMARK
接下来会选几个领域做一些更底层的介绍,基于篇幅的限制,某些知识点,点到为止,可以作为以后工作再深入的一个入口。
要让优化器能够得到足够好的plan,有几个必要条件:
数据库中的表设置了合适的数据类型。
数据库中设置了合适的索引。并且索引上有正确的统计信息。
合理的数据分布。
查询优化器的作用:
当我们将查询提交给MySQL执行时,大多数的查询都不像 select * from single_table;那样简单,从单个表读取所有数据就行了,不需要用到高级的检索方式来返回数据。大多数查询都比较复杂,有些更复杂并且完全按照编写的方式执行查询绝不是获得结果的最有效方式。我们可以有很多的可能性来优化查询:添加索引、联接顺序、用于执行联接的算法、各种联接优化以及更多。这就是优化器发挥作用的地方。
优化器的主要工作是准备查询以执行和确定最佳查询计划。第一阶段涉及对查询进行转换,目的是重写的查询可以以比原始查询更低的成本执行查询。第二阶段包括计算查询可以执行的各种方式的成本,确定并执行成本最低的计划。
这里有一个注意的点:优化器所做的工作并不精确科学,因为数据及其分布的变化,优化器所做的工作并不精确。转换优化器的选择和计算的成本都是基于某种程度的估计。通常这些估计值足以得到一个好的查询计划,但偶尔你需要提供提示(hint)。如何配置优化器是另外一个话题。
查询改写(Transformations)
优化器有几种更改查询的改写,在仍然返回相同结果的同时,让查询变为更适合MySQL。
当然,优化的前提是返回的结果符合期望,同时响应时间变短:减少了IO或者cpu时间。改写的前提是原始查询与重写查询逻辑一致,返回相同的查询结果是至关重要的。为什么不同的写法,可以返回相同的结果,又是一门学问:关系数据库基于数学集理论的研究。
举个查询改写简单的例子:
- SELECT *
- FROM world.country
- INNER JOIN world.city
- ON city.CountryCode = country.Code
- WHERE city.CountryCode = 'AUS'
这个查询有两个条件:city.CountryCode = 'AUS',city.CountryCode=country.Code。从这两个条件可以得出country.Code='AUS'。优化器使用这些知识来直接过滤country。由于code列是country表的主键,这意味着优化器知道最多只有一行符合条件,并且优化器可以将country表视为常数( constant)。实际上,查询最终是使用country表中的列值作为选择列表中的常量(constant)执行扫描CountryCode='AUS'的city表中的行。
改写如下:
- SELECT 'AUS' AS `Code`,
- 'Australia' AS `Name`,
- 'Oceania' AS `Continent`,
- 'Australia and New Zealand' AS `Region`,
- 7741220.00 AS `SurfaceArea`,
- 1901 AS `IndepYear`,
- 18886000 AS `Population`,
- 79.8 AS `LifeExpectancy`,
- 351182.00 AS `GNP`,
- 392911.00 AS `GNPOld`,
- 'Australia' AS `LocalName`,
- 'Constitutional Monarchy, Federation' AS `GovernmentForm`,
- 'Elisabeth II' AS `HeadOfState`,
- 135 AS `Capital`,
- 'AU' AS `Code2`,
- city.*
- FROM world.city
- WHERE CountryCode = 'AUS';

从性能的角度来看,这是一个安全的转变,且是优化器可以自动实现的,并且对外提供了一个开关。
某些转换会更加复杂,且并不总是提高性能。因此set optimizer_switch =on or off 是可选的,
optimizer_switch 的内容 以及 何时怎么使用 optimizer hints 会在下一篇文章中讨论。
有对查询改写怎么实现感兴趣的朋友,可以在GreatSQL社区留言,为大家准备了大概9篇论文。
基于成本优化(Cost-Based Optimization)
一旦优化器决定要进行哪些转换,就需要确定如何执行重写查询。业内目前有两条路径来解决,rule model 和 cost model。如果您已经熟悉对optimizer_trace输出的解读,作为dba已经对cost model 了解的足够多了。
我再试着从优化器的角度来解读一下成本优化。
单表查询
无论查询如何,计算成本的原则都是相同的,但是,查询越复杂,成本估算就越复杂。
举一个简单的例子,一个查询单个表的sql,where条件使用二级索引列。
- mysql> SHOW CREATE TABLE world.city\G
- **************************** 1. row ****************************
- Table: city
- Create Table: CREATE TABLE `city` (
- `ID` int(11) NOT NULL AUTO_INCREMENT,
- `Name` char(35) NOT NULL DEFAULT ",
- `CountryCode` char(3) NOT NULL DEFAULT ",
- `District` char(20) NOT NULL DEFAULT ",
- `Population` int(11) NOT NULL DEFAULT '0',
- PRIMARY KEY (`ID`),
- KEY `CountryCode` (`CountryCode`),
- CONSTRAINT `city_ibfk_1` FOREIGN KEY (`CountryCode`) REFERENCES `country`
- (`Code`)
- ) ENGINE=InnoDB AUTO_INCREMENT=4080 DEFAULT CHARSET=utf8mb4
- COLLATE=utf8mb4_0900_ai_ci
- 1 row in set (0.0008 sec)
- SELECT * FROM world.city WHERE CountryCode = 'IND'
优化器可以选择两种方式来获取匹配的行。一种方法是使用CountryCode上的索引查找索引中的匹配行,然后查找请求的行值。另一种方法是进行全表扫描并检查每一行确定它是否符合where条件。
这些访问方法中哪一种成本最低(最快)不是可以直接确定。这取决于几个因素:
索引的选择性:cost_单行直接获取<cost_二级索引查询逐渐后获取<cost_全表扫描
索引必须显著减少要检查的行数。越多选择指数,使用它相对便宜。(这里行数不太准确,应该是IO次数,以及IO的方式,顺序IO 还是随机IO) 《MySQL是怎样运行的》有介绍一行数据是怎么读取到的。
索引覆盖度:如果索引包含所有列查询需要,可以跳过对实际行的读取。
读取记录的代价:取决于几个因素,索引和行记录是否都在innodb_buffer_pool中,如果不在,从磁盘读取的代价和速度是多少。使用二级索引时,在切换读取索引和读取主键索引之间,将需要更多的随机I/O,查找记录需要耗费的索引寻找次数(一般索引高度来决定)变得非常重要。
MySQL8.0 的优化器可以讯问InnoDB是否查询所需的记录可以在缓冲池中找到,或者是否
必须从从磁盘上读取记录。这对执行计划的改进,有巨大的帮助。
读取记录的所需cost是很复杂的问题,MySQL不知道硬件的性能,MySQL8.0 默认磁盘读取的成本是4倍内存读取。
- mysql> select cost_name, default_value from mysql.server_cost;
- +------------------------------+---------------+
- | cost_name | default_value |
- +------------------------------+---------------+
- | disk_temptable_create_cost | 20 |
- | disk_temptable_row_cost | 0.5 |
- | key_compare_cost | 0.05 |
- | memory_temptable_create_cost | 1 |
- | memory_temptable_row_cost | 0.1 |
- | row_evaluate_cost | 0.1 |
- +------------------------------+---------------+
- 6 rows in set (0.00 sec)
-
- mysql> select engine_name,cost_name,default_value from mysql.engine_cost;
- +-------------+------------------------+---------------+
- | engine_name | cost_name | default_value |
- +-------------+------------------------+---------------+
- | default | io_block_read_cost | 1 |
- | default | memory_block_read_cost | 0.25 |
- +-------------+------------------------+---------------+
- 2 rows in set (0.00 sec)
表关联顺序(Table Join Order)
多表关联时,outer and straight joins,join 顺序是固定的。inner join时,优化器会自由选择join顺序,为每一种组合计算代价。计算复杂度和表数量的关系:
N张表,需要做N! 的计算。5张表,组合度为5!=5*4*3*2*1=120
MySQL支持连接多达61个表,在这种情况下可能有61!计算成本的组合。计算组合的成本过高且可能需要更长时间而不是执行查询本身。因此,优化器默认情况下会删除基于成本的部分评估查询计划,因此只有最有希望的计划会被完全评估。
在给定的表之后,还可以通过参数optimizer_prune_level和optimizer_search_depth 配置搜索裁剪、搜索深度,来停止评估。比如10张表关联,理论上需要评估10!=3628800次,默认最多62次。
最佳联接顺序 有两个个因素影响,表自身的大小,经过过滤器后每个表减少的行数。
默认过滤效果(Default Filtering Effects)
多表关联时,知道每张表有多少行数据参与join,很有意义。
当使用索引时,当过滤器与其他表不相关时,优化器可以非常准确地估计与索引匹配的行数。如果没有索引,直方图统计可用于获得良好的滤波估计。当没有过滤列的统计信息时,就会出现困难。在这种情况下,优化器会后退基于内置默认估计。
那到底是怎么估算的呢?详见以下这篇大名鼎鼎的论文:
《Access Path Selection in a Relational Database Management System》(https://dl.acm.org/doi/pdf/10.1145/582095.582099)
需要中文版的朋友可以留言到GreatSQL社区。
System R针对join ordering问题,开创性的使用基于动态规划的方法,结合Interesting Order形成等价类的方式,来对search space进行高效搜索。不仅如此,其对于selectivity的计算,cost的计算方式,影响非常深远,相信早期的商业数据库大多采用类似的代价估算方式(MySQL直至今日仍然如此)。
论文太深奥了 ,来点大家看得懂的

这个列表并不详尽,但它应该能让您很好地了解MySQL是如何实现过滤估计的。默认过滤效果显然不是非常准确,特别是对于大表,因为数据不遵循这样的严格规则。这就是为什么索引和直方图对于获得良好的查询计划非常重要。在确定查询计划的最后,会对单个部分和整个查询进行成本估算。这些信息有助于了解优化器到达查询执行计划。
(这里也可以看出MySQL的优化器的参考值相对Oracle是比较简单的,导致的结果就是MySQL解析sql很快,快到几乎不用缓存执行计划,Oracle为了解决生成计划慢的问题, 引入了软简析,软软简析,绑定执行计划等方案,当然MySQL的优化器短板也很明显,为DBA们制造了大量sql优化的需求)
查询成本(The Query Cost)
有5种方式查看optimizer 估算出来的成本。每一种都值得独立开篇来讨论,每一种都有它使用的场景,(生产上做操作有绝对的安全保障吗?)。
1、explain(explain 后面的sql,真的不会执行 or 产生cost吗?如果会,什么场景会触发cost)
2、explain format= tree (8.0.16) or explain format= json
3、explain analyze(8.0.18) 在format= tree的基础上,增加了多种信息( actual cost 怎么定义 的?actual cost又是一个量化分析的话题,它是一个绝对的概念还是一个相对 explain的概念),执行成本、返回行数、执行时间、循环次数等,本质上,EXPLAIN ANALYZE只适用于显式查询,因为它需要从头到尾监视查询。另一方面,简单的EXPLAIN语句也可以用于正在进行的查询。详见语法:(https://dev.mysql.com/doc/refman/8.0/en/explain.html#explain-analyze)
- mysql> explain format=tree SELECT * FROM t1 WHERE t1.a IN (SELECT t2.b FROM t2 WHERE id < 10);
- *************************** 1. row ***************************
- -> Nested loop inner join (cost=4.95 rows=9)
- -> Filter: (`<subquery2>`.b is not null) (cost=2.83..1.80 rows=9)
- -> Table scan on <subquery2> (cost=0.29..2.61 rows=9)
- -> Materialize with deduplication (cost=3.25..5.58 rows=9)
- -> Filter: (t2.b is not null) (cost=2.06 rows=9)
- -> Filter: (t2.id < 10) (cost=2.06 rows=9)
- -> Index range scan on t2 using PRIMARY (cost=2.06 rows=9)
- -> Index lookup on t1 using a (a=`<subquery2>`.b) (cost=2.35 rows=1)
- 1 row in set (0.01 sec)
-
- mysql> explain analyze SELECT * FROM t1 WHERE t1.a IN (SELECT t2.b FROM t2 WHERE id < 10)\G
- *************************** 1. row ***************************
- -> Nested loop inner join (cost=4.95 rows=9) (actual time=0.153..0.200 rows=9 loops=1)
- -> Filter: (`<subquery2>`.b is not null) (cost=2.83..1.80 rows=9) (actual time=0.097..0.100 rows=9 loops=1)
- -> Table scan on <subquery2> (cost=0.29..2.61 rows=9) (actual time=0.001..0.002 rows=9 loops=1)
- -> Materialize with deduplication (cost=3.25..5.58 rows=9) (actual time=0.090..0.092 rows=9 loops=1)
- -> Filter: (t2.b is not null) (cost=2.06 rows=9) (actual time=0.037..0.042 rows=9 loops=1)
- -> Filter: (t2.id < 10) (cost=2.06 rows=9) (actual time=0.036..0.040 rows=9 loops=1)
- -> Index range scan on t2 using PRIMARY (cost=2.06 rows=9) (actual time=0.035..0.038 rows=9 loops=1)
- -> Index lookup on t1 using a (a=`<subquery2>`.b) (cost=2.35 rows=1) (actual time=0.010..0.010 rows=1 loops=9)
- 1 row in set (0.01 sec)
explain format= json 怎么算 参考 format= json 怎么算
explain analyze 怎么读?参考
(https://www.mmzsblog.cn/articles/2022/05/07/1651914715938.html)
4、MySQL Workbench Visual Explain diagram 大部分的mysql客户端都提供可视化的执行计划功能。
- SELECT ci.ID,
- ci.Name,
- ci.District,
- co.Name AS Country,
- ci.Population
- FROM world.city ci
- INNER JOIN (SELECT Code,
- Name
- FROM world.country
- WHERE Continent = 'Europe'
- ORDER BY SurfaceArea LIMIT 10 ) co
- ON co.Code = ci.CountryCode
- ORDER BY ci.Population DESC
- LIMIT 5;
可视化执行计划展示:
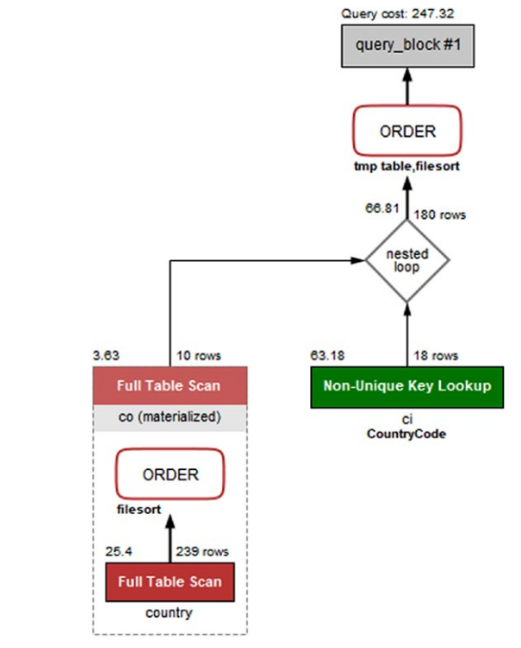
12种数据表访问方式作色
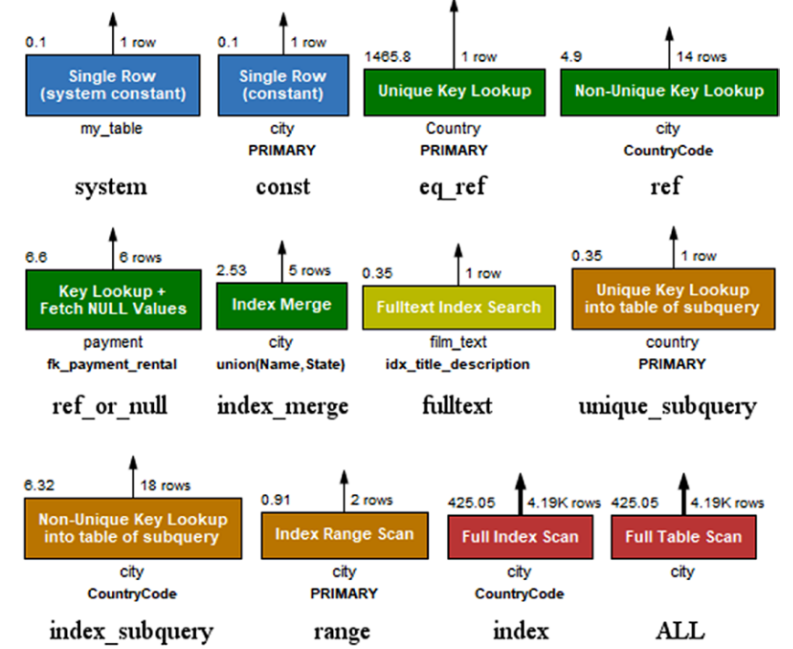
作色与表访问方式成本大小的关系
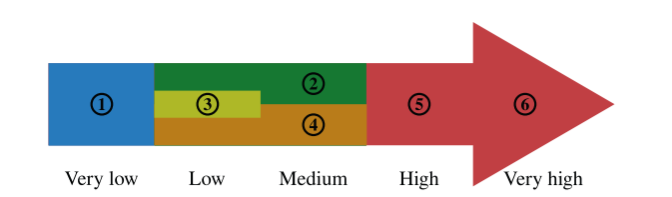
Blue (1) is the cheapest; green (2), yellow (3), and orange (4) represent low to medium costs; and the most expensive access types and operations are red symbolizing a high (5) to very high (6) cost.
以上都只是一个平均值or 经验值,可视化执行计划的颜色展示不是绝对的真理。
可以思考一下:索引look up 一定比全表扫描好吗?索引只会带来查询上的正向优化吗?
5、终极武器 optimizer trace
影响以上输出的因素有:(不好意思,以下每种,又是一个开篇话题 :) 我真是太讨厌了。。。)
1、sql_mode
2、optimizer switch
3、index statistics
4、mysql.engine_ cost and mysql.server_cost tables
done,待续
Enjoy GreatSQL :)
《深入浅出MGR》视频课程
戳此小程序即可直达B站
https://www.bilibili.com/medialist/play/1363850082?business=space_collection&business_id=343928&desc=0
文章推荐:
想看更多技术好文,点个“在看”吧!


