
- 11.3了解分布式系统(通俗易懂)_分布式计算现实生活的案例
- 2分析 BAT 互联网巨头在大数据方向布局及大数据未来发展趋势_腾讯及阿里2012-2019年投资项目轮次分布(个)图
- 3C++常见经典面试题及详解_c++面试题
- 4大数据python论文毕设项目选题答疑
- 5Go 语言中常量和变量的定义、使用
- 6基于Java+SpringBoot+vue+elementui药品商城采购系统详细设计实现_java+vue商城项目
- 7谷歌浏览器安装JSON格式化插件简单教程_chrome 安装 json 转化插件
- 8web前端简易制作之HTML_web前端做网站含代码
- 9集合各实现类的底层实现原理_集合实现类的底层原理
- 10Redis实现延迟队列_redis延时队列
面向未来的开源 OLAP 技术架构探讨以及选型实践_开源olap系统
赞
踩
摘要:本文将介绍开源大数据 OLAP 的演化过程和最佳实践。文章将围绕下面六点展开:
1.开源 OLAP 综述
2.OLAP 场景思考
3.开源数据湖/流式数仓解决方案
4.StarRocks 介绍
5.客户案例
6.未来规划
一、开源 OLAP 综述

基于历史发展和开源社区的火热,现在的OLAP技术可以用百花齐放四个字来形容。
如图中最左边这一部分,是现在比较流行或者已经是业界标准的 OLAP 数据仓库/LakeHouse,包括 StarRocks、Doris、ClickHouse。第二部分是 SQL on Hadoop,该技术于10年前开始,以 HDFS 平台或者 OSS 为存储底座,包括 Presto 以及分支出来的 Trino、Impala。第三部分是预处理/Cube/NoSQL,已经使用得越来越少,麒麟、Druid 社区以及背后的商业化公司活跃度不高,Hbase 目前主要用在 Serving 的场景,社区相对比较老,稳定性尚可,解决了一部分业务场景,应用规模不小,但热度在逐渐下降。第四列是离线部分,目前的事实标准是 Spark,比较老的技术栈则是 Hive。
最底下这一部分是数据湖格式,之所以放在最下面,是有原因的。Delta Lake 在2019 年推出了增量数据湖格式,后期包括 Hudi,Iceberg,被大家称作数据湖三剑客。它们主要解决数据增量更新的问题。在大多情况下,作为 Presto、StarRocks 的外表,以读的方式作为 OLAP 来使用。Apache Paimon 是 Flink 社区推出的,原来叫 Flink Table Store,目前也贡献到了 Apache 社区,以 Flink 为基础,把整个存储留在湖里。
二、OLAP 场景思考
典型业务场景
OLAP 的业务场景主要有四大类:
第一类是面向用户的报表,比如一个比较典型的场景,给第三方广告主出报表,它可能是一个 ToB 的公司,利用 OLAP 引擎去做 Serving 服务;
第二类是面向经营人员、数据分析人员、老板的一些经营的报表,也是传统 BI 的 OLAP 行为;
第三类是用户画像,在游戏等行业里用得非常多,主要是把所有的用户标签统一到一张比较宽的表里,可以用各个维度去筛选出需要的客户;
第四类是流式的、实时的场景,包括直播、风控、实时预测。
接下来将介绍这几种业务场景对 OLAP 技术的需求及解决方案。

面向客户的报表

面向客户的报表,业务特点是按照客户的ID去检索数据,需要低延迟、高并发,而且需要明细数据,不仅仅是聚合模型。基于明细可以实现更灵活的自助分析,或者称作实时OLAP。但是实时 OLAP 性能也会受限制,比如三张表、十张表的 Join 查询的 latency 可能会非常的高,所以我们需要去做物化视图。总结起来,业务场景的需求是明细加上物化视图。
在技术上的需求,第一点是数据过滤,比如前缀索引、Bloom filter,以及一些更高级的filter,通过一些统计值有效过滤,减少读取的数据,使得点查或者范围查询更加快速。
第二点是向量化引擎,Presto、Hive、Spark 在某一个时间点上都有 OLAP 的尝试。当然现在 Presto、Trino 社区还是非常活跃的,尤其是在国外,它们是通过 Java 技术栈实现的,但是 Java 技术栈从语言层面而言没有 C++ 快,同时因为JVM向量化现在还不是特别成熟,也不能利用JVM的向量化模式。当然 Trino 社区在不断地去做这件事,不过到现在还没有一个完整的产品。另外 Presto,也在做 Native 的 Engine,去解决 OLAP 加上向量化的问题。但是有一些数据库,包括 ClickHouse、StarRocks、Doris,在几年前就已经布局了向量化引擎,因为其整个执行引擎本来就是用C++写的,所以会更快。
第三点是数据在机器的合理分布,数据分布对查询影响也是比较大的,包括数据是否有序、是否是 shard。
最后一点是对物化视图的支持是否足够好。
面向经营的报表
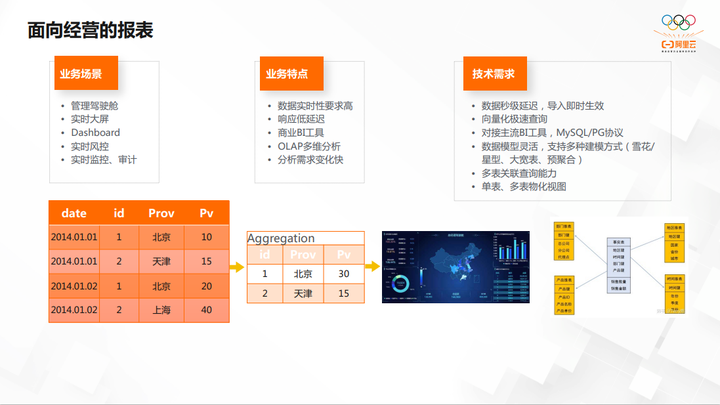
面向经营的报表,一般是企业内部提供给老板和数据分析人员查看的报表,比较典型的是实时风控场景。业务特点首先是需求变化特别快,要有明细表的存在,不只聚合成一种预设的模式,一般要把明细表直接导入到数据仓库中。第二是要求响应低延迟,对查询性能要求很高。
低延时对技术的需求包括向量化极速查询、多表关联查询能力、物化视图等等。
ClickHouse 针对宽表的场景,把整个数据通过 shard 分布,每一台机器进行分布式计算,最后将结果汇总起来形成查询的结果。ClickHouse 宽表比较快,但是宽表维护起来比较麻烦。所以我们思索是否有一种引擎可以对明细模型做高效的分布式 Join,在具有多机多核的同时也有核的向量化。
用户画像

用户画像场景是以一个ID为主键,构成一张列特别多的宽表。在 StarRocks 出现之前,更多用的是 Flink 或者 Spark 在外围加工出一张可能上千列的宽表,再直接 load 到数据库中,比较常见的是 ClickHouse 中。现在由于 StarRocks 逐渐崛起,很多需求都落到了 StarRocks 上。因为多表关联的能力也是需要的,如果用户画像只用宽表来做,还是有一些限制。在跟客户交流的过程中了解到,ClickHouse 这条链路会存在烟囱式开发的问题,维护起来有难度,所以 ClickHouse 的高效是牺牲了一定的运维能力。另外ClickHouse 对人员的要求也比较高,因为业务线的人员更多的是关注业务,这时要求业务线的人员去对 ClickHouse 进行维护就会存在困难。
订单分析

订单分析场景,在没有增量数据湖格式出现之前,用 Hive 或 Spark 一般是T+1的形式,如果要进一步提高时效,可能会用更短的时间去建分区,比如一个小时一个分区,但如果对这类分区表做全量刷新则会非常不友好,无论是对数据湖还是调度,压力都非常大。现在希望实时或者准实时地去分析数据,增量数据湖,包括 Delta Lake、Hudi、Iceberg 就是为了解决这一问题。
在线教育、企业订单、打车软件等场景,常常需要数据回刷,这对数据湖来说是一个非常大的挑战。在有了更新模型之后,很多企业开始把整个链路加到 Hudi,或者 Delta Lake上面。比如上一次的数据是一个小时之前的数据,下一个小时去更新这一批数据,但是如果做 OLAP 查询,速度会比较慢。因为直接查湖上的数据,受网络 IO 影响比较大。另外数据湖后台的 Compaction 要求比较高,尤其流量特别大的时候,很难同时保证数据查询的新鲜度和查询性能的要求。
StarRocks 引出了一部分主键模型,能够直接把 MySQL 或者原始数据直接打到主键模型里,通过主键的方式去更新,同一个主键,实现部分列的更新,是一种最佳实践。
技术需求思考
通过上述场景分析,对技术需求可以总结为如下几大类:
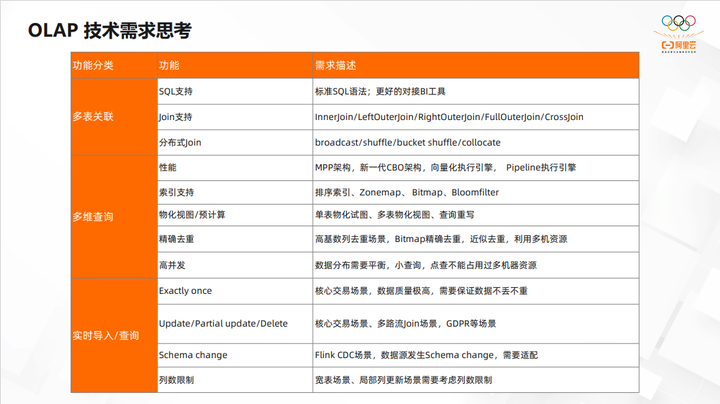
多表关联
首先是对 SQL 的支持,比如是否支持 IC SQL,还是会违背 IC SQL的语法,有很多自己的 SQL 语法。引申就是有没有一些 MySQL 协议或者是 PG 协议,直接可以去对接更好的BI工具,能够较少地去改动。
其次是对 Join 的支持。对比 StarRocks 和 CK,可以看出来,StarRocks 对于分布式 Join 的支持是特别好的,因为它有 FE 去做整个的 CBO,比如有5张表去做 Join a,Join b,Join c,Join d、 Join e 以怎样的顺序去做 Join,这时就需要通过 CBO 算法来挑出一个最好的方式。
另外是分布式 Join 的支持。StarRocks 还有一些其它的特性,通过数据的分布,实现一些 Join 的高级特性,比如 broadcast Join、shuffle Join,对比起来 CK 这几点就比较弱,因为 CK 最开始的时候是类似于以单机的形式拓展的分布式,它不是 MPP 架构,而是 Scatter-Gather 的架构。Scatter-Gather 架构需要去手动地把整个数据分成不同的Shard,每一台机器计算自己的 Shard,再把整个数据回吐到一个中心节点,这样就相当于是两层架构,对于 Join 的支持是很有限的。
多维查询
需要关注性能和索引的支持是否完备,以及一些高级的特性比如物化视图。物化视图在 StarRocks 里是一种比较重要的特性,包括同步物化视图、异步物化视图、单表物化视图、多表物化视图等。
实时导入和查询
是否有 Exactly Once 的语法保证。StarRocks 是能够保证的。CK 也是支持事务的,但分布式事务存在一些缺陷。是否有 Update 功能,包括 Partial Update。Schema Change 的感知。列数的限制,宽表限制了1000列还是1万列是有本质区别的。

开发效率、架构和运维
对于企业,开发效率、架构、运维难度可能更加重要,很多情况下企业人员并不是那么充足,运维的简便就很重要,比如能否以最小代价弹性缩容,能否根据扩缩容来自动均衡,是否能够达到高可用等等,都是非常实际的问题。开发效率方面,比如函数的支持是否完备,UDF 支持是否完备。现在越来越多的客户也都是湖仓的架构,本身有一些湖数据,这些数据是否可以不导进来,可以直接查询,也是一个特别常见的刚需。
三、开源数据湖/流式数仓解决方案
整体架构
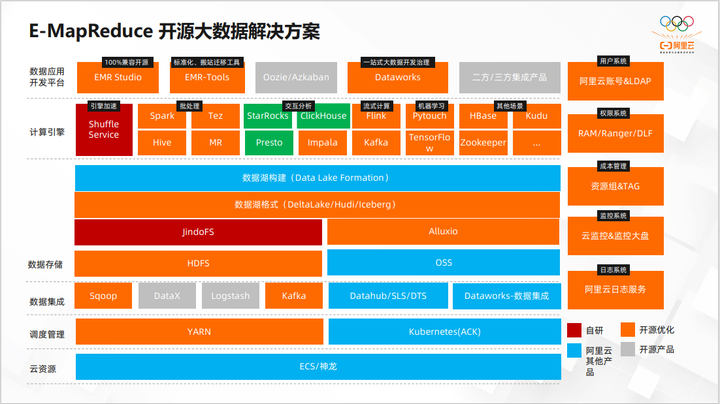
上图是EMR的整体架构。以 ECS 或 Kubernetes 作为底座,主推方向是存算分离。左边是 JindoFS 加上 OSS,我们叫做 HCFS, Hadoop Compatible FS。Spark、Presto 这些计算引擎,不需要更改任何接口,直接能够对接以 OSS 为底座的 HCFS。其中有一些引擎是比较活跃的,也有一些基本上已经退出了历史舞台。
上面是一些数据分析或者数据应用平台的组件,下面将介绍的是企业架构。
Lambda 架构
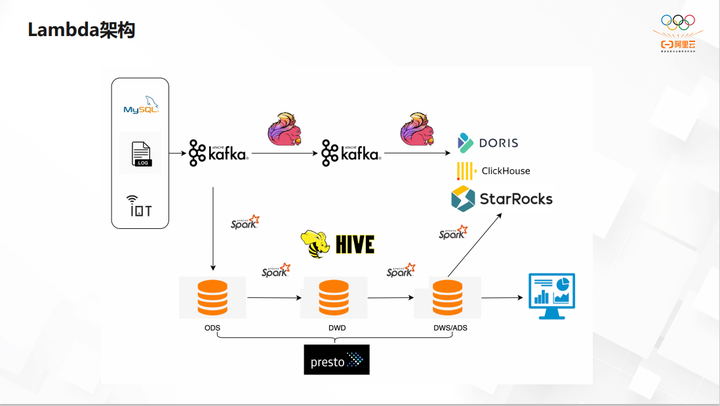
第一个是 Lambda 架构,是最传统的一套架构,也是大厂现在用得最多的。离线和实时分别走不同的链路。图中这一块分层 ODS、DWD、DWS,放在 OLAP 的数据仓库里,这一层直接体现了报表的查询响应速度,可以用类似 Presto、Trino 这类引擎去查询,这是比较传统的架构,这里最终加工出来的最后一层的报表,直接放在 OLAP 里。
实时数据湖解决方案
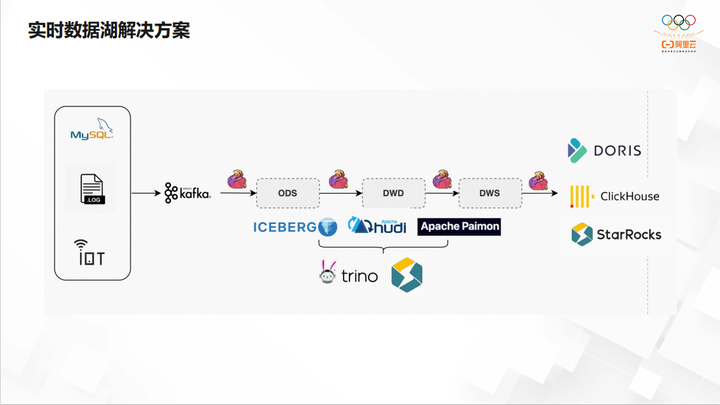
第二个是相对比较新的一种架构,它提供了按主键 merger into 的能力,解决增量更新的场景。
这套架构计算会比较频繁,原来只是T+1,现在则需要实时或者近实时,比如半小时,几分钟去做更新,逐渐向流批一体靠拢。因为Iceberg、Hudi两个数据湖格式对批引擎和流引擎是完全适用的,这点在选型时大家也会着重考虑。对于查询数据湖,有越来越多的客户,从 Trino 或者 Presto 迁移到 StarRocks 上,因为目前 StarRocks 对于 Data Lake Analytics(DLA),也就是读外表的数据,支持是非常好的。
大家如果关注 StarRocks 社区版3.0会了解到,除了 UDF,StarRocks 能够提供和 Presto一模一样的语法,叫做 Presto Gateway,可以在不改 Presto 的 SQL 的情况下,就能够查询湖数据。这个能力将会包含在EMR 2.5的版本上。
最开始我们是最后一层 ADS 导入到 OLAP 中,现在有很多客户是希望 ODS、DWD、DWS 里面挑选一些比较关键的表,提供比较高的性能,也导入到 OLAP 中,然后通过 OLAP 完成高效的查询。
实时分析解决方案
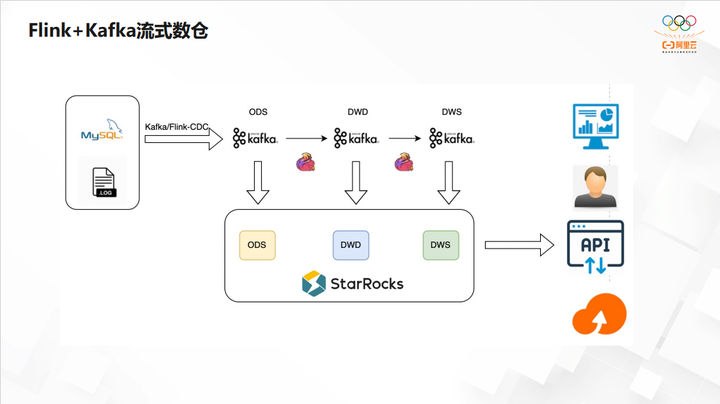
上图是传统的 Kappa 架构,对于一些垂直业务线部门,不是数据中台部门,需要做这样一套数仓来解决其业务问题。通常是用 Flink CDC 把 MySQL 的数据同步到 Kafka 里,数据一般存储7天或者3天。虽然商业版的 Kafka 可以提供 KSQL,但在 Kafka 里查询数据,性能一直都是不太好的。
所以通常把整个 Kafka 数据通过 routine load 直接导到数据仓库里面,或者直接导到StarRocks 里面,这样就能保证 ODS、DWD、DWS 这三层数据全部可以增量查到,也能够去做整个的 OLAP,ODS 和 DWD 这两层的表也可以去做一些 Join。
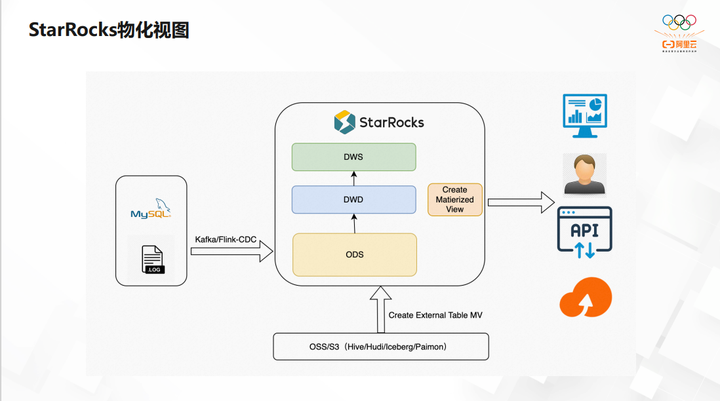
StarRocks 的物化视图会在2. 5版本或者之后的几个小版本才能够比较稳定地跑起来,现在提供的是类似于全量物化视图,或是分区物化视图,而不是那种完全的 Incremental 物化视图。另外2. 5版本有外表物化视图,也可以把一些比较重的表,或者是我们通常叫做大湖小仓,把所有的数据放到湖里,需要的数据导到仓里。导入到仓里的时候也提供了一种比较暖心的方式,会去做外表的优化视图进行数据的导入。比如按时间,每10分钟导一次,把外表物化视图直接导进 StarRocks 里边,而不是用灌数据的方式。直接通过物化视图的方式,内部也会起更多的物化视图,也会在物化视图里边去建物化视图,这样把每一层的数据全部都物化起来,这也是 StarRocks 社区版中主推的。
四、StarRocks 介绍
接下来介绍 StarRocks 的价值和一些关键技术。
StarRocks 价值&架构
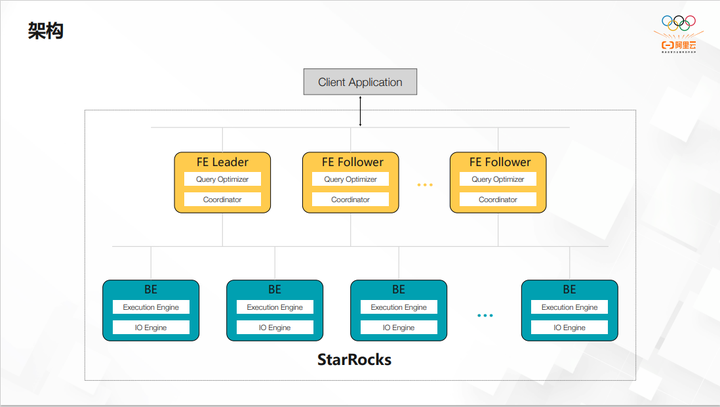

StarRocks 主打极速统一的概念,3. 0也会主打云原生这一概念。统一方面,StarRocks可以进行多维分析、实时分析,包括高并发查询、AD hoc 查询,包括前面介绍的所有场景,希望能够都统一起来,逐步在演化过程中,也慢慢地都开始做到了。在极速方面,StarRocks 对特别多的细节优化得也相当到位。通过 StarRocks 可以解决目前的大部分问题。
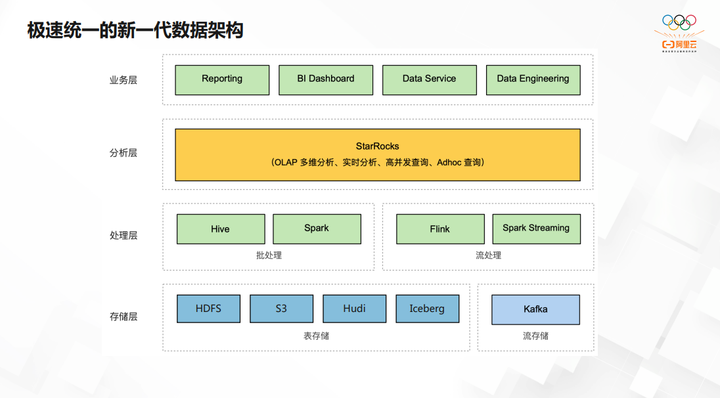
StarRocks 架构简单。FE 如果是高可用,则是有三个节点,它是通过 BDB 的库去做journal log 同步,类似于 raft 协议。BE 包括执行引擎和 IO 的引擎。比如查数据湖时,数据不在本地,所以整个 BE 节点,没必要去启动存储引擎,只需要计算引擎就可以。
StarRocks 核心技术特性

上图中列出了向量化的优化效果(2.1版本)。对于几个算子,比如 filter、group、shuffle Join、broadcast Join 等算子的性能提升是比较明显的。只要查询是非常重计算,轻 IO 的,最后整个查询的性能提升会非常明显。

StarRocks CBO 优化器采用 Cascades 框架。其中 Join 的推算是用动态规划算法实现的。
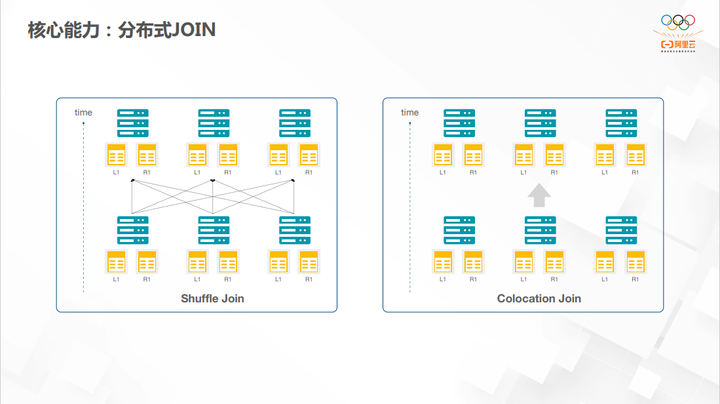
分布式 Join 的能力包括 Shuffle Join、Bucket Join、Colocation Join 等。Colocation Join 是指不需要网络传输,事先把两张表的数据,需要被 Join 的 key 置于同一台机器上,可以不走网络,不走 shuffle 的过程,这样能够显著加速 Join 的过程。但这种方式使用起来还是有一些门槛的,实际中不仅需要非常懂业务,还需要懂 Colocation Join 命中的规则,才能将其真正用起来。但是一般情况下 Shuffle Join,Bucket Join,Broadcast Join 也都够用了。

实时分析方面,StarRocks 有一个比较重要的特性——主键模型,也是不断地在优化中。1. 9的版本开始出现主键模型,一直优化到2. 5版本,经历了一年多,所以稳定性、内存的使用、以及 Partial Update 这些方面都表现优异。
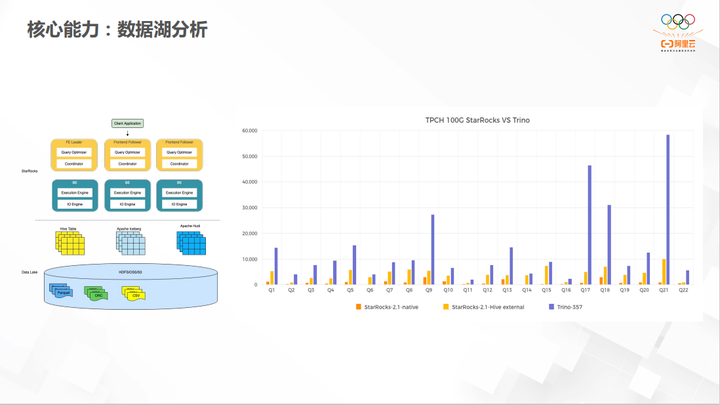
整体性能方面,如果是查询数据湖外表,采用 TPCH 的标准跟 Trino 对比是3- 5倍的差距,数据来源 StarRocks 官网,或者是阿里云EMR官网。如果是在自己的业务,自己的 SQL 上,可能会有差异,但是有好有坏,如果查询是IO瓶颈的,那无论计算还是索引优化得多么好,也不一定有多大的提升,瓶颈卡在IO上,StarRocks 的向量化计算,包括一些高级的索引都没用上。但IO用的不是特别多,主要都是在函数计算,或其它方面,算子运行时间长,那么提升可能会非常多。
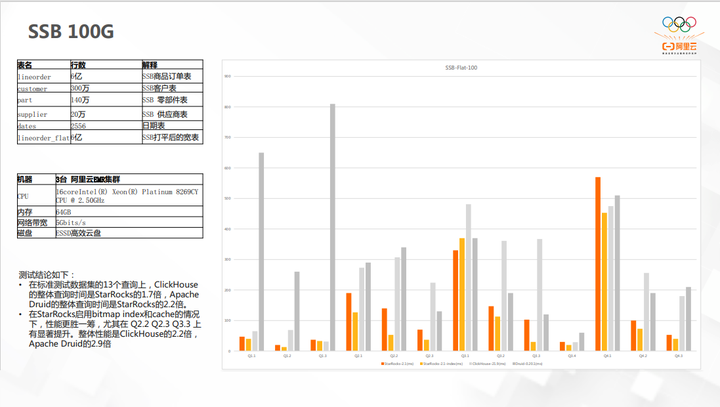
SSB 100G对比的是单表场景,数据来源 ClickBench 网站。在 CK 的优势领域,单表查询上,StarRocks 目前表现也是比较突出。如果感兴趣可以访问 ClickBench 官网。

StarRocks 目前也有资源隔离能力,如果要自建 StarRocks,资源隔离能力用得是比较多的。如果是在阿里云的场景上,或者后续要推出存算分离的场景,资源隔离能力,可以去官网上参考,但是在我们的客户里边用的并不是特别多。

最后是副本自动平衡的能力。如果去扩一台机器或者缩一台机器,不需要去手动做副本平衡,或者一台机器坏了,或者一个副本坏了,都是由 FE 的 task 去做平衡。
五、客户案例
某社交领域客户
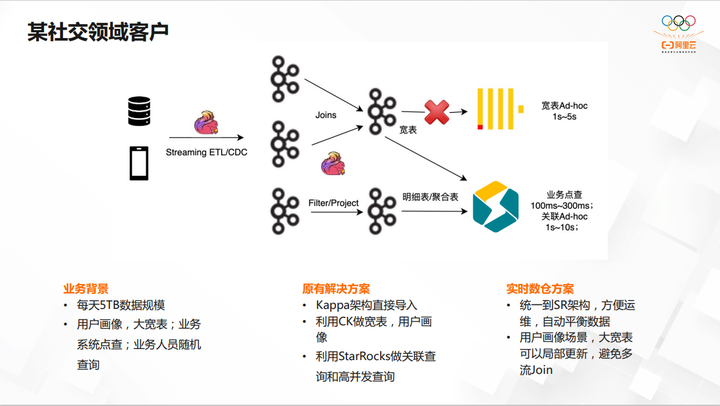
第一个案例是某社交领域客户,他们最开始用的是CK。在StarRocks 2. 1时,他们开始用 StarRocks 去做整个的关联查询,用CK去做宽表的查询。但后来他们不愿意去维护两个技术栈,所以就去掉了CK,目前基本上用 StarRocks 支撑了所有的业务,包括用户画像、点查,以及传统的 OLAP 多表关联查询。
某电商领域客户

第二个案例是一个电商领域的客户,它们有着非常强烈的统一 OLAP 的需求。之前他们的 OLAP 由于历史原因用得特别乱,运维人员又比较少,维护困难。最后统一到了 StarRocks 里。首先,他们看中了阿里云的专家支持能力;同时,也看中了社区的发展,在社区中提出的问题总能得到较快的回答;另外,StarRocks 基本满足了他们所有的需求。
某在线教育客户

在线教育这个案例中,之前是通过 Hive 做小时级的更新,也无法实现 Upsert 场景,后面迁移到了 Hudi 数据湖上,中间链路除了 Flink 也使用了 Spark。属于大湖小仓,他们把一些关键的、性能要求高的数据都导到 StarRocks 里,对性能要求不那么高的就通过外表的方式直接查询 Hudi。经过数月的生产实践,目前已非常稳定。
六、未来规划
StarRocks3.x:极速统一&云原生
最后来介绍一下 StarRocks 3.x 版本的规划。
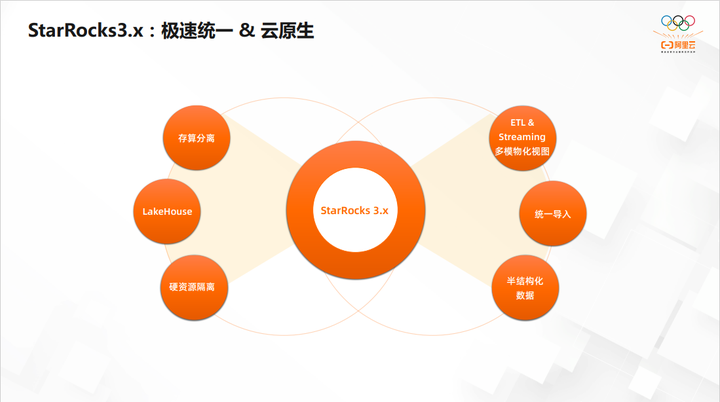
包括几条线,第一,继续坚持极速统一这一特性;第二,积极配合去做云原生,存算分离。
大家可能会有一个比较大的困惑,如果用 StarRocks 做仓,那么我们提供的都是云盘,毕竟从成本上来看是要比 OSS 贵不少。所以是否能够类似于 Snowflake,把整个数据全部放到 OSS 里边,只是把云盘作为缓存层去做。
在 LakeHouse 这一部分,2. 3的版本外表查询已经比较完备了,但是对于 Iceberg、 Hudi 的支持,还有很多工作要做。因为StarRocks社区是全球化的,在海外客户对于 Iceberg 用的还是比较多的。
在 ETL 方面和 Snowflake 对标,从3. 0 StarRocks 已经不是纯内存去做ETL了,会有 spill 框架。如果做一个比较大的 ETL 可以 Spill,有限的内存就可以把数据算好。比如做 Hashmap,Hashmap就可以去不断地往磁盘里面去写,有Spill的框架去支撑整个算子。
做ETL的时候并不像 Spark 那样 stage by stage,把每一个 stage 数据都存下来,保证容错性。思路是做得足够快,比Spark快上几倍,即使中间有问题,直接可以通过重算 Job来解决。
但是 ETL 也有资源隔离的问题。资源硬隔离,指的不是用现在已有资源组的方式,而是用跟 Snowflake 一样的架构,不同的节点去算不同的数据,相当于 OLAP 用一系列节点, ETL 用一系列节点,数据都存在 OSS 里边,这样能够保证两个 Workload 同时发生,但互不影响,这也是很多客户需要的。
目前 StarRocks 也在做多模的物化视图,包括增量的物化视图,流式的物化视图。
还有一些比较小的点,包括统一导入、半结构化数据。
以上就是本次分享的内容,谢谢大家。
点击立即免费试用云产品 开启云上实践之旅!
本文为阿里云原创内容,未经允许不得转载。

