
- 1Sovit3D数字孪生平台 助力智慧海上风电场项目加速_三维数字孪生 智慧风电场
- 2低代码+智慧水务:随需应变,降本增效_智慧水务 这类的口号
- 3MySQL 深潜 - 一文详解 MySQL Data Dictionary Hope Lee
- 4Qt UDP通信聊天程序(单播、广播、组播)_qudpsocket设置广播通信
- 5第三方API(pytdx)获取实时行情数据_期货实时数据接口api
- 6Hadoop集群的搭建与深入理解
- 7数学建模---评价类模型总结_数学建模 评价方法选择
- 8【学习笔记】python编程:从入门到实践(第二章 变量和简单数据类型)课后练习_2-9 最喜欢的数字:将你最喜欢的数字存储在一个变量中,再使用这个变量创建一 条消
- 9Linux故障恢复技巧(转)
- 10android framework-Pixel3真机制作开机动画实战_怎么获取 bootanimation.zip
python文件操作和异常之文件的操作_在src目录下的test.py文件中编写程序,读取sample.txt文件的内容,统计文件中字母的
赞
踩
从文件中读取数据:
1:读取整个文件
首先创建一个文件,它包含一些文本信息,注意:如果该文件为.py文件,则再进行操作的时候可以不写路径,如果不是.py文件,则必须标明路径。
现在我们创建一个python文件,名为text.py,给他写入如下文本信息:
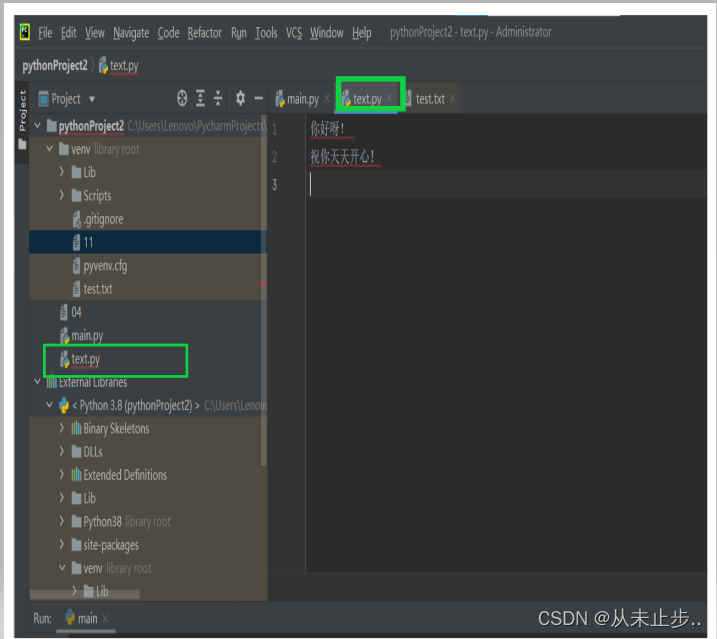
下面的程序打开并读取这个文件,再将其内容显示到屏幕上:
with open('text.py') as pythonProject2:#open(要打开的文件名称)
#open函数返回一个表示文件test.py的对象,python将该对象赋给pythonProject2
cc=pythonProject2.read()
print(cc)
- 1
- 2
- 3
- 4
 python在当前执行的文件所在目录中查找指定的文件
python在当前执行的文件所在目录中查找指定的文件
关键字 with 在不再需要访问文件后将其关闭在这个程序中,注意到我们调用了 open(),但没有调用 close()。也可以调用 open()和 close()来打开和关闭文件,但这样做时,如果程序存在 bug 导致方法 close()未执行,文件将不会关闭。这看似微不足道,但未妥善关闭文件可能导致数据丢失或受损。如果在程序中过早调用 close(),你会发现需要使用文件时它已关闭(无法访问),这会导致更多的错误。并非在任何情况下都能轻松确定关闭文件的恰当时机,但通过使用前面所示的结构(with open(需要打开的文件名称) as 赋给另一个对象),可让 Python 去确定:你只管打开文件,并在需要时使用它,Python 自会在合适的时候自动将其关闭。
细心的同学已经发现了,我们上文所输出的内容多了一行空格,原因是:read()到达文件末尾的时候返回一个空的字符串,而将这个空字符串显示出来就是一个空格,而想要删除空行只需要使用我们之前学习过的rstrip()函数。
为什么要提供文件路径?
将类似于 .txt 的简单文件名传递给函数 open()时,Python 将在当前执行的文件(即物程序文件)所在的目录中查找。
根据你组织文件的方式,有时可能要打开不在程序文件所属目录中的文件。例如,你可能将程序文件存储在了文件夹 python_work
中,而该文件夹中有一个名为 text_files 的文件夹用于存储程序文件操作的文本文件。虽然文件夹 text_files 包含在文件夹
python_work 中,但仅向 open()传递位于前者中的文件名称也不可行,因为 Python 只在文件夹 python_work
中查找,而不会在其子文件夹 text_files 中查找。要让 Python 打开不与程序文件位于同一个目录中的文件,需要提供文件路径,让
Python 到系统的特定位置去查找。
否则会出现如下图所示:python会告诉你找不到该文件
 那么该怎么解决这个问题呢?
那么该怎么解决这个问题呢?
这里我们就需要用绝对路径,例如,我们现在建立一个.txt在桌面。
下面我们使用相对路径(仅提供文件名的方式),去打开:
with open(r"新建文本文档.txt",'r',encoding='utf-8') as f:
ff=f.read()
print(ff)
- 1
- 2
- 3
我们发现文件根本打不开。
 现在我们使用绝对路径(提供具体的位置信息),去打开:
现在我们使用绝对路径(提供具体的位置信息),去打开:
with open(r"C:\Users\Lenovo\Desktop\新建文本文档.txt",'r',encoding='utf-8') as f:
ff=f.read()
print(ff)
- 1
- 2
- 3
文件内容被很好的显示出来了。

注:encoding='utf-8的作用是为了避免出现乱码。
上图所示程序,不加encoding='utf-8,就会出现以下情况;

注:显示文件路径时,Windows系统使用反斜杠(\),而不是斜杠(/),但在代码中仍可以使用斜杠。
如果在文件路径中直接使用反斜杠,将引发错误,因为反斜杠用于对字符串中的字符进行转义。
举例:
C:\path\to\file.txt
- 1
其中的\t会被解读为制表符,如果一定要使用反斜杠,可对相对路径中的每个反斜杠都进行转义:
C:\\path\\to\\file.txt
- 1
逐行读取:
读取文件时,常常需要检查其中的每一行:可能要在文件中查找特定的信息,或者要以某种方式修改文件中的文本。
直接使用for循环的方法:
在该目录下的文件读取:
for line in open("123.txt",encoding='utf-8'):
print(line)
- 1
- 2
计算机其他位置中的:
for line in open(r"C:\Users\Lenovo\Desktop\新建文本文档.txt",encoding='utf-8'):
print(line)
- 1
- 2
使用while循环:
在该目录下的文件读取:
f=open("123.txt",encoding='utf-8')
line=f.readline()
while line:
print(line)
line=f.readline()
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
计算机其他位置中的:
f=open(r"C:\Users\Lenovo\Desktop\新建文本文档.txt",encoding='utf-8')
line=f.readline()
while line:
print(line)
line=f.readline()
f.close()
- 1
- 2
- 3
- 4
- 5
- 6
使用with…as结构:
在该目录下的文件读取:
with open("123.txt",encoding='utf-8') as f:
for line in f:
print(line)
- 1
- 2
- 3
计算机其他位置中的:
with open(r"C:\Users\Lenovo\Desktop\新建文本文档.txt",encoding='utf-8') as f:
for line in f:
print(line)
- 1
- 2
- 3
运行上面两个文件的结果:
hi,python
早上好
晚上好
你好
- 1
- 2
- 3
- 4
- 5
- 6
- 7
窗前明月光,疑似地上霜
举头望明月,低头思归乡
鹅鹅鹅,曲项向天歌
白毛浮绿水,红掌拨清波
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们不难发现,空白行变得更多了,原因是:在这个文件中,每行末尾都有一个看不见的换行符,而print函数在调用的时候也会产生一个换行符,因此每行末尾都会有两个换行符,一个来自文件,一个来自print函数的调用,要想消除这些换行符,可在调用print函数的时候,使用rstrip():
print(line.rstrip())
- 1
处理之后的结果:
窗前明月光,疑似地上霜
举头望明月,低头思归乡
鹅鹅鹅,曲项向天歌
白毛浮绿水,红掌拨清波
- 1
- 2
- 3
- 4
hi,python
早上好
晚上好
你好
- 1
- 2
- 3
- 4
创建一个包含文件各行内容的列表:
使用关键字 with 时,open()返回的文件对象只在 with 代码块内可用。如果要在 with 代码块外访问文件的内容,可在 with 代码块内将文件的各行存储在一个列表中,并在 with 代码块外使用该列表:可以立即处理文件的各个部分,也可以推迟到程序后面再处理。
with open("123.txt",encoding='utf-8') as f:
lines=f.readlines()#使用readlines()从文件中读取每一行,并将其存储在一个列表中
//这样处理后,在with代码块外仍然可以使用变量lines
for line in lines:
print(line)
- 1
- 2
- 3
- 4
- 5
输出结果:
hi,python
早上好
晚上好
你好
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用文件中的内容:
举例:
with open("123.txt",encoding='utf-8') as f:
lines=f.readlines()
pi=str()#创建空的字符串用于存储文本内容
for line in lines:
pi+=line.rstrip()#将每行末尾的空行去掉
print(pi)
print(len(pi))#输出字符串的长度
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1234562345671038417968539
25
- 1
- 2
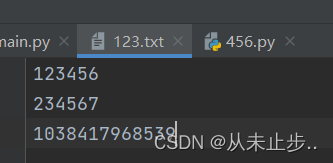 注:读取文本文件的时候,python会自动将所有的文本文件解读成字符串,如果文本文件中的内容为数值,并且要作为数值使用,就必须使用int()函数,或者float()函数将其进行转化。
注:读取文本文件的时候,python会自动将所有的文本文件解读成字符串,如果文本文件中的内容为数值,并且要作为数值使用,就必须使用int()函数,或者float()函数将其进行转化。
举例:
如果上述例子中的123.txt中的内容要作为数值使用,则程序应进行修改:
如下:
with open("123.txt",encoding='utf-8') as f:
lines=f.readlines()
pi=int()#进行强制转化
#pi=float()
for line in lines:
pi+=int(line)
#pi+=float(line)
print(pi)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1038418326562
- 1
包含千位以上的大型文件:
前面我们所分析的都是包含几行的文本文件,现在假设我们有一个文件,其中包含精确到小数点后千位而不是30位的圆周率,也可创建一个字符串将他包含到里面,有的小伙伴想到这个问题会觉得很棘手,程序该怎么写呢?
其实,我们前面编撰好的程序就可以直接进行传递使用:
with open("123.txt",encoding='utf-8') as f:
lines=f.readlines()
pi=str()#创建空的字符串用于存储文本内容
for line in lines:
pi+=line.rstrip()#将每行末尾的空行去掉
print(f"{pi[:52]}.....")#为了避免显示的内容不停的滚动,只打印前52位
print(len(pi))#输出字符串的长度
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1234562345671038417968539168519635885951538287826636.....
1596
- 1
- 2
同理,对于万位,百万位等等更大的文件,我们的程序仍然可以使用。
圆周率中包含你的生日吗?
with open("123.txt",encoding='utf-8') as f:
lines=f.readlines()
pi=str()#创建空的字符串用于存储文本内容
for line in lines:
pi+=line.rstrip()#将每行末尾的空行去掉
you_birthday=str(input("请输入你的生日"))
if you_birthday in pi:
print("yes")
else:
print("NO")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
请输入你的生日0904
yes
- 1
- 2
写入文件:
1:写入空文件:
要将文本写入文件,你在调用open()时,需要提供另一个参数,告诉python,你要写入打开的文件.
举例:
with open("123.txt",'w',encoding='utf-8') as f:
f.write("晚上好")
- 1
- 2
打开该文件:

#open(名称,操作模式 )#操作模式包括:w:写,r:读取 ,a:附加,r+:读写`
- 1
如果省略了操作模式,python自动以只读的方式打开,如果要写入的文件不存在,python的open()函数将自动创建它,以写入的模式(w)打开,如果该文件已存在,则python会自动清空之前的内容。
python只能将字符串写入文本文件文件,要是想将数据存储到文本文件中,需要先用str()将其转化为字符串格式。
写入多行:
函数write()不会在写入的文本末尾添加换行符,因此如果写入多行时没有指定换行符,文件看起来可能不是我们想要的那样:
举例:
with open("123.txt",'w',encoding='utf-8') as f:
f.write("早上好---good morning")
f.write("中午好---good afternoon")
f.write("晚上好---good evening")
- 1
- 2
- 3
- 4
如下图所示,所有的内容都被显示在一行:
 怎么解决这种问题呢?需要在方法调用write()中包含换行符:
怎么解决这种问题呢?需要在方法调用write()中包含换行符:
with open("123.txt",'w',encoding='utf-8') as f:
f.write("早上好---good morning\n")
f.write("中午好---good afternoon\n")
f.write("晚上好---good evening\n")
- 1
- 2
- 3
- 4
现在文本内容呈现在不同行中:
 像显示到终端一样,还可以使用空格,制表符和空行来设置这些输出的格式。
像显示到终端一样,还可以使用空格,制表符和空行来设置这些输出的格式。
附加到文件:
如果要给文件添加内容而不是覆盖原来的内容,可以以附加模式打开文件,以附加模式打开文件时,python不会在返回文件对象前清空文件的内容,而是将写入文件的行添加到文件末尾,如果指定的文件不存在,python会为你创建一个空文件。
举例:
with open("123.txt",'a',encoding='utf-8') as f:#以附加模式打开
f.write("hello,world")#将hello,world写入文件
- 1
- 2
原内容并没有被清空。


