
- 1巨杉TechDay回顾 | 微服务下的分布式数据库架构演进与实践_分布式数据库和微服务架构
- 2WinCC数据报表控件_wincc报表控件免费版下载
- 3
false - 4Lambda表达式使用及详解
- 5git新建用户和仓库以及设置用户权限_git用户权限设置
- 6Python办公自动化之Excel做表自动化:全网最全,看这一篇就够了!python操作Excel教程_excel办公自动化python
- 7xcode 开发者证书创建流程_xcode 证书
- 8Android Gradle配置详解一:gradle插件和gradle区别_gradle和gradle插件
- 9洛谷P1135 奇怪的电梯 C++ 思路&代码_奇怪的电梯c++
- 10【LeetCode刷题】新手一看就会的——动态规划详解—入门_运筹学动态规划解题思路
机器学习顶会ICML 2024今日开放投稿,CCF A类,中稿率27.94%(附ICML23杰出论文+18篇高分论文)_icml2024
赞
踩
ICML 2024今天开放投稿了!距离截稿还有24天,想冲ICML的同学速度!
ICML 全称 International Conference on Machine Learning,由国际机器学习学会(IMLS)举办,与NIPS一同被认为是人工智能、机器学习领域难度最高的国际会议(含金量也超高)。
值得一提的是,ICML收录的文章中,中国作为第一作者单位的占比最高,高达51.45%。
文末附ICML2023杰出论文+18篇大模型、域自适应高分论文&代码
会议信息
ICML属于CCF A类会议,Core分类 A*,H5指数254,影响力32.40。今年的ICML 2024大会将于7月21日在奥地利维也纳举办,为期一周(27日)。
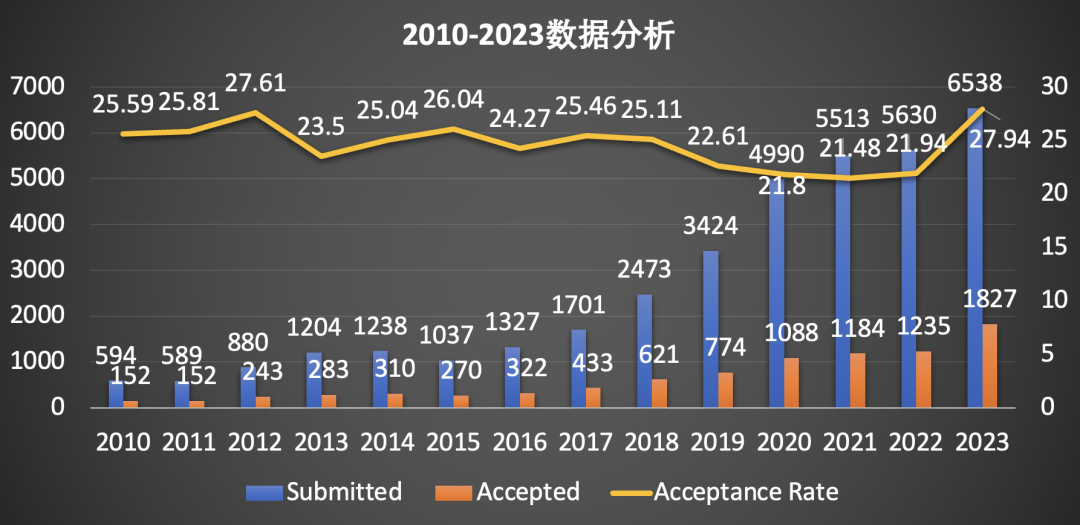
据官网数据(https://icml.cc/Conferences/2024/)显示,2023年共收到 6538 份投稿,有1827 份被接收,录用率为27.94%,比之往年增长明显。
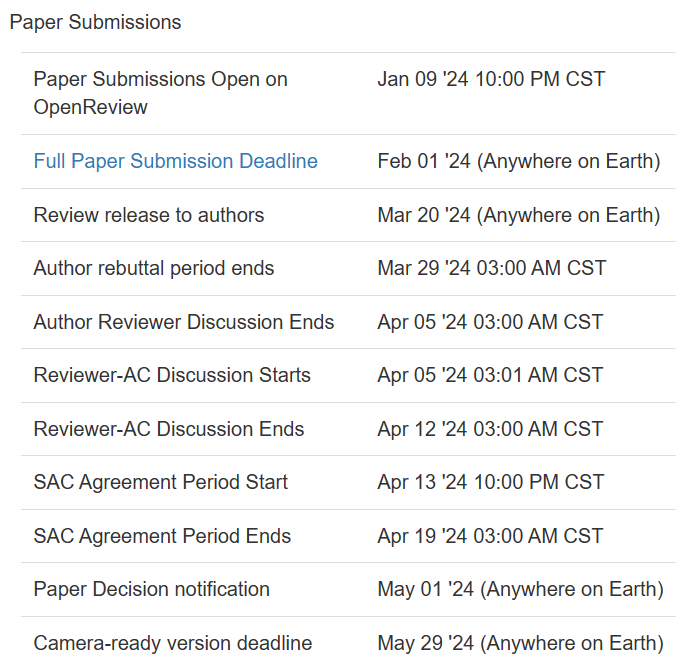
截稿时间
ICML 2024全文截稿时间为2024年2月1日,还剩24天,想发顶会的同学注意时间。
投稿地址:https://openreview.net/group?id=ICML.cc/2024/Conference
-
开放投稿时间:2024.1.9
-
全文截稿时间:2024.2.1
-
录用通知时间:2024.5.1
-
会议时间:2024.7.21
其他详细截稿时间看下图:
征稿范围
感兴趣的主题包括(但不限于):
-
通用机器学习(主动学习、聚类、在线学习、排名、强化学习、监督学习、半监督和自监督学习、时间序列分析等)
-
深度学习(架构、生成模型、深度强化学习等)
-
学习理论(博弈论、统计学习理论等)
-
优化(凸优化和非凸优化、矩阵/张量方法、随机、在线、非光滑、复合等)
-
概率推理(贝叶斯方法、图模型、蒙特卡洛方法等)
-
可信机器学习(可解释性、因果关系、公平性、隐私保护、鲁棒性等)
-
应用(计算生物学、众包、医疗保健、神经科学、社会公益、气候科学等)
审稿要求
所有提交必须匿名,并且不得包含任何有意或无意违反双盲审稿政策的信息,包括但不限于引用作者以前的工作或以可以推断出任何作者身份或机构的方式分享链接,以及向潜在审稿人透露作者身份的行为。
作者可以在预印本服务器(如arXiv)上发布其作品的版本。在审稿期间,作者还可以向限制性受众就提交给ICML的工作进行演讲。如果已经在ICML做出决定之前在线发布了非匿名版本的论文,那么提交的版本不得引用该非匿名版本。
ICML强烈反对在向ICML提交论文期间在社交媒体或新闻中宣传预印本。在任何情况下,作者的工作都不应在审稿期间(即从提交论文到接受/拒绝决定的传达之间)明确标识为ICML提交。
精选论文
从近五年ICML录用论文关键字来看,机器学习、深度学习等频次最高。2023年的杰出论文关键词则广泛涉及无学习率、为 LLM 加水印、未见过域泛化、不完全信息零和博弈的近优策略、MCMC 和频率顺序学习的贝叶斯设计原则等。
这6篇杰出论文我在这里也分享了,另外还整理了18篇ICML 2023 域自适应/域泛化、大模型相关的高分论文。
杰出论文
1.Learning-Rate-Free Learning by D-Adaptation
「标题:」基于D-Adaptation的无学习率学习
「作者:」Aaron Defazio (FAIR), Konstantin Mishchenko (Samsung AI Center)
「内容:」本文介绍了一种有趣的方法,旨在解决获得非平滑随机凸优化的学习率自由最优边界的挑战。作者提出了一种克服传统学习率选择在优化此类问题时所施加的限制的新方法。这项研究对优化领域做出了有价值和实际的贡献。

2.A Watermark for Large Language Models
「标题:」大语言模型的数字水印
「作者:」John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein (马里兰大学)
「内容:」本文提出了一种对大型语言模型输出进行水印处理的方法,即将信号嵌入到生成的文本中,这些文本对人类来说是不可见的,但可以通过算法检测到。无需重新训练语言模型即可生成水印,无需访问 API 或参数即可检测到水印。本文还提出了一种用于检测具有可解释p值的水印的统计检验,以及用于分析其敏感性的信息理论框架。该方法简单新颖,理论分析扎实,实验扎实。鉴于在检测和审计LLM生成的合成文本方面出现的关键挑战,本文有可能对社区产生重大影响。

3.Generalization on the Unseen, Logic Reasoning and Degree Curriculum
「标题:」对未见的泛化,逻辑推理和程度课程
「作者:」Emmanuel Abbe(EPFL,Apple),Samy Bengio(Apple),Aryo Lotfi(EPFL),Kevin Rizk(EPFL)
「内容:」这项工作在学习布尔函数方面取得了重大进展,特别是针对看不见的泛化(GOTU)设置,这提出了一个具有挑战性的分布外泛化问题。本文广泛探讨了这一重要主题,提供了一种由理论分析和广泛实验支持的结构化方法。此外,它通过概述深度神经网络领域的一个关键研究方向而脱颖而出。
4.Adapting to game trees in zero-sum imperfect information games
「标题:」适应零和不完全信息博弈中的博弈树
「作者:」Côme Fiegel (CREST, ENSAE, IP Paris), Pierre MENARD (ENS Lyon), Tadashi Kozuno (Omron Sinic X), Remi Munos (Deepmind), Vianney Perchet (CREST, ENSAE, IP Paris and CRITEO AI Lab), Michal Valko (Deepmind)
「内容:」本文介绍了不完全信息零和博弈的近优策略。它严格地建立了一种新的下界,并提出了平衡FTRL和自适应FTRL两种算法。这些贡献极大地推动了不完全信息游戏中的优化领域。实验证实了这些说法,为研究结果提供了充足的支持。

5.Self-Repellent Random Walks on General Graphs - Achieving Minimal Sampling Variance via Nonlinear Markov Chains
「标题:」在通用图上的自排斥随机游走 - 通过非线性马尔可夫链实现最小采样方差
「作者:」Vishwaraj Doshi (IQVIA Inc), Jie Hu (北卡罗来纳州立大学), Do Young Eun (北卡罗来纳州立大学)
「内容:」本文解决了一组具有挑战性的开放问题,即具有自排斥随机游走的MCMC。它超越了传统的非回溯方法,为MCMC采样的新研究方向铺平了道路。作者对马尔可夫链蒙特卡洛文学做出了原创性且非平凡的贡献;值得注意的是,这个过程可以被严格分析和证明。这篇论文写得很好,对主要概念进行了清晰直观的解释。结果令人信服和全面。

6.Bayesian Design Principles for Frequentist Sequential Learning
「标题:」用于频率学顺序学习的贝叶斯设计原理
「作者:」徐云北,阿萨夫·泽维(哥伦比亚大学)
「内容:」本文解决了设计强盗和其他顺序决策策略的非常普遍的问题。它提出了使用称为算法信息比率的新量来界定任何策略的遗憾的方法,并推导出了优化该边界的方法。该界限比类似的早期信息理论量更严格,并且这些方法在随机和对抗性强盗设置中都表现良好,实现了世界上最好的。特别有趣的是,这篇论文可能为一系列全新的勘探开发策略打开了大门,超越了著名的汤普森采样和土匪UCB。这个原则延伸到强化学习的事实是非常有希望的。该文件得到了专家审评员的一致和大力支持。

域自适应/域泛化
-
On Balancing Bias and Variance in Unsupervised Multi-Source-Free Domain Adaptation
-
Sequential Counterfactual Risk Minimization
-
Provably Invariant Learning without Domain Information
-
Taxonomy-Structured Domain Adaptation
-
Generalization Analysis for Contrastive Representation Learning
-
Moderately Distributional Exploration for Domain Generalization
-
Distribution Free Domain Generalization
-
In Search for a Generalizable Method for Source Free Domain Adaptation
-
RLSbench: Domain Adaptation Under Relaxed Label Shift
大模型
-
Scaling Vision Transformers to 22 Billion Parameters
-
Specializing Smaller Language Models towards Multi-Step Reasoning
-
Pretraining Language Models with Human Preferences
-
Whose Opinions Do Language Models Reflect?
-
Mimetic Initialization of Self-Attention Layers
-
Cross-Modal Fine-Tuning: Align then Refine
-
Evaluating Self-Supervised Learning via Risk Decomposition
-
Delving into Noisy Label Detection with Clean Data
-
ODS: Test-Time Adaptation in the Presence of Open-World Data Shift
关注下方《学姐带你玩AI》

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

