
- 1链表&;双指针-以快慢指针查找环形链表中链表环的第一个结点为例
- 2在 CentOS 上安装 PostgreSQL 的全面指南
- 3Java学生管理系统_学生管理系统java
- 4深入浅出剖析 LoRA 技术原理_prefix tuning的缺点
- 5HbuilderX启动 微信开发者工具_hbuilder怎么运行到微信开发者工具
- 6Anaconda/Pycharm下载安装时PIP Error:Cannot determine archive format..._cannot determine archive format of
- 7kafka的选型_kafka技术选型
- 8《文本大数据情感分析》读书报告_基于深度学习的社交媒体情绪信息抽取及其在灾 情分析中的应用研究
- 9secure boot 基本概念和框架
- 10Word 2003 长篇文档排版技巧(二)_双面打印,每一章从另页右页(奇数页)开始
一文看尽 6篇 CVPR2021 伪装目标检测、旋转目标检测论文
赞
踩
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达

导读
本文对 CVPR 2021 检测大类中的“伪装目标检测”、“旋转目标检测”领域的论文进行了盘点,将会依次阐述每篇论文的方法思路和亮点。在极市平台回复“CVPR21检测”,即可获得打包论文
6月25日,CVPR 2021 大会圆满结束,随着 CVPR 2021 最佳论文的出炉,本次大会所接收的论文也全部放出。CVPR2021 共接收了 7039 篇有效投稿,其中进入 Decision Making 阶段的共有约 5900 篇,最终有 1366 篇被接收为 poster,295 篇被接收为 oral,其中录用率大致为 23.6%,略高于去年的 22.1%。
CVPR 2021 全部接收论文列表:https://openaccess.thecvf.com/CVPR2021?day=all
从 CVPR2021 公布结果开始,极市就一直对最新的 CVPR2021 进行分类汇总,共分为33个大类,包含检测、分割、估计、跟踪、医学影像、文本、人脸、图像视频检索、三维视觉、图像处理等多个方向。所有关于CVPR的论文整理都汇总在了我们的Github项目中,该项目目前已收获7200 Star。
Github项目地址(点击阅读原文即可跳转):https://github.com/extreme-assistant/CVPR2021-Paper-Code-Interpretation
在之前极市平台曾对 CVPR 2021中 “2D目标检测” 、“异常检测”领域的论文进行了盘点,今天我们继续盘点 CVPR 2021 检测大类中的“伪装目标检测和旋转目标检测”领域的论文,将依次阐述每篇论文的方法思路和亮点。接下来还会继续进行其他领域的 CVPR2021 论文盘点。如有遗漏或错误,欢迎大家在评论区补充指正。
Ⅰ 伪装目标检测篇
论文一
Camouflaged Object Segmentation with Distraction Mining
题目:带有干扰挖掘的伪装对象分割

论文:https://arxiv.org/pdf/2104.10475.pdf
代码:https://github.com/Mhaiyang/CVPR2021_PFNet
伪装对象分割 (COS) 旨在识别“完美”融入周围环境的对象,具有广泛的应用价值。COS 的关键挑战在于目标对象和噪声背景之间存在高度的内在相似性。本文中开发了一个仿生框架,称为定位和聚焦网络 (PFNet),它模仿了自然界中的捕食过程。具体来说,文中的PFNet包含两个关键模块,即定位模块(PM)和聚焦模块(FM)。PM 旨在模拟捕食中的检测过程,以从全局角度定位潜在目标对象,然后使用 FM 执行捕食中的识别过程,通过关注模糊区域来逐步细化粗略预测。
本文的亮点/贡献是:
(1)将去干扰的概念引入伪装物体分割任务,为干扰区域的发现和去除开发了一种新的挖掘策略,以帮助伪装物体的精确分割。
(2)提出了一个新颖的伪装物体分割方法,称为定位和聚焦网络(PFNet)。该方法首先通过探索长范围的语义依赖关系来定位潜在的目标物体,然后聚焦于分心区域的发现和去除以逐步细化分割结果。
网络结构:
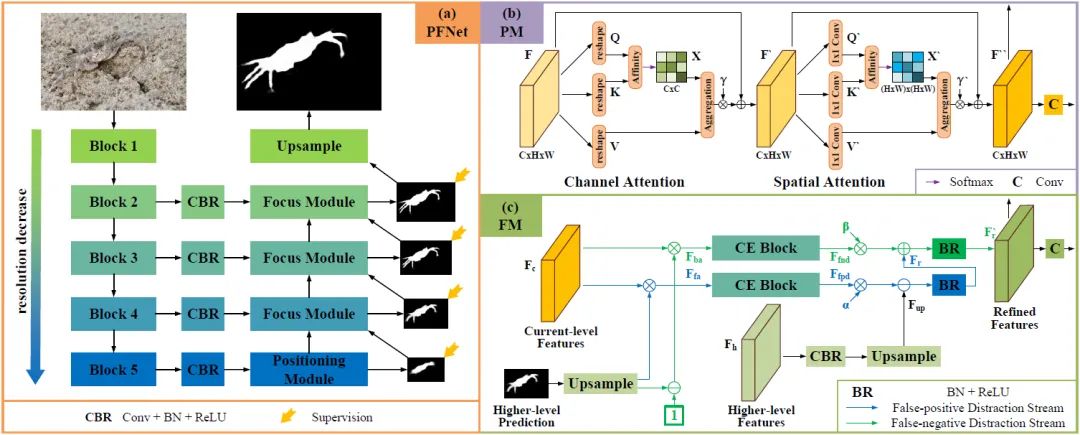
如图, (a)所示,给定一幅RGB图像,本文首先将其送入ResNet-50网络提取多级特征,然后将这些特征送入四个卷积层中进行通道缩减。然后,在最深层特征上应用(b) 定位模块(PM)和(c)聚焦模块(FM)对潜在物体进行定位。最后,利用多个聚焦模块(FMs)逐步发现和去除假阳性和假阴性干扰,实现伪装物体的准确分割。
实验结果
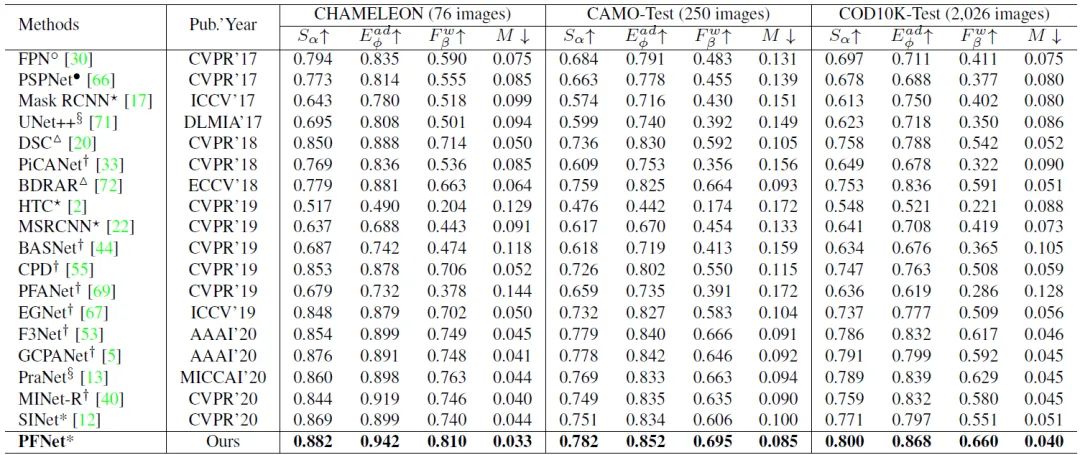

 大量实验表明,本文的 PFNet 实时运行 (72 FPS),并在四个标准指标下的三个具有挑战性的基准数据集上显着优于 18 个尖端模型。
大量实验表明,本文的 PFNet 实时运行 (72 FPS),并在四个标准指标下的三个具有挑战性的基准数据集上显着优于 18 个尖端模型。
论文二
Mutual Graph Learning for Camouflaged Object Detection
题目:用于伪装目标检测的互图学习

论文:https://arxiv.org/abs/2104.02613
代码:https://mhaiyang.github.io/CVPR2021_PFNet/index
对于当前模型来说,自动检测/分割与其周围环境融合的对象是困难的,这些前景对象和背景环境之间的内在相似性使得深度模型提取的特征无法区分。本文的方法灵感来自生物学研究的发现:捕捉真实的身体/物体形状是识破伪装的关键。一个理想的伪装目标检测模型应该能够从给定的场景中寻找有价值的、额外的线索,并将它们合并到一个联合学习框架中,用于特征表示联合增强。
受此启发,本文主要进行了以下工作:
(1)设计了一种新的基于图、交互式学习的伪装目标检测方法,叫做交互式图学习模型(MGL)。将传统的交互式学习思想从规则网格推广到图域。具体来说,MGL将一幅图像分解成两个特定任务的特征图:一个用于粗略定位目标,另一个用于精确捕捉其边界细节——并通过图形反复推理它们的高阶关系来充分利用互利。
(2)使用基于图的伪装目标检测技术来利用两个紧密相关任务(COD和COEE)之间的相互指导知识,用于完全挖掘嵌入的导航信息。该方法能够获取语义指导知识和空间支持信息,相互促进两个任务的执行。与传统的交互式学习方法不同,MGL集成了两个不同的基于图的交互模块来推理类型关系:RIGR用于从COE最小化分割指导信息来辅助COEE,ECGR用于结合真实的边先验来增强COD底层表示。
方法概述:
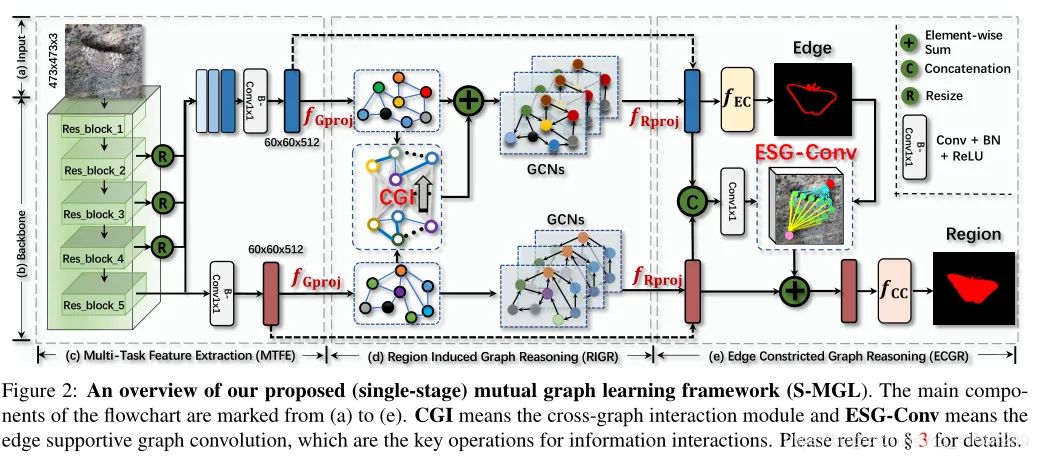
MGL主要由三个部分组成: Multi-Task Feature Extraction (MTFE), Region-Induced Graph Reasoning (RIGR) module和Edge-Constricted Graph Reasoning (ECGR)。该模型将常规互学习的思想从规则网格推广到图域。具体来说,MGL 将图像解耦为两个特定于任务的特征图:一个用于粗略定位目标,另一个用于准确捕获其边界细节——并通过通过图形反复推理它们的高阶关系来充分利用他们的互利性。
MTFE:给定输入图像I(H×W×3),一个multi-task backbone被解耦为两个特定于任务的表示。Fc(h×w×c)用于粗略的检测目标,Fe(h×w×c)用于正确的捕捉真实边缘。
RIGR:将Fc和Fe通过图像投影操作fGproj转换为依赖样本的语义图Gc=(Vc,Ec)和Ge=(Ve,Ee)。语义图中,具有相似特征的像素形成顶点,边测量特征空间中顶点之间的affinity。交叉图交互式模块(CGI)fcgi用来捕获两个语义图之间的高级依赖关系,并将语义信息从Vc变成Ve’。然后通过图卷积进行图推理(fGR)获得最终的Vc和Ve’。最后将Vc和Ve’通过fRproj投影回原始坐标空间。
ECGR:在空间关系分析之前,先将Fe送入边缘分类器fEC,得到伪装的目标感知边缘图E。另外将Fe和Fc进行拼接形成新的特征图Fc‘,然后使用边缘支持图卷积(ESG-Conv)对边缘信息进行编码,在E的引导下增强Fc’更好地定位目标。最后我们将Fc’送到分类器fcc中,获得最终结果C。
在MGL中,利用RIGR和ECGR两个新的神经模块,在多个层次的相互作用空间上对COD和COEE之间的相互关系进行了推理。通过明确地推理它们之间的关系,有价值的相互指导信息可以直观地准确传播,以便在表征学习过程中相互帮助。值得一提的是,RIGR和ECGR可以连续堆叠,以实现反复性的相互学习。
总结
训练集是CAMO和COD10K的组合,使用ImageNet预训练的ResNet50。对数据进行随机裁剪,左右翻转和[0.75, 1.25]范围内缩放。使用SGD优化策略。学习率调整图下公式,base_lr=1e-7,power=0.9。
与大多数使用共享函数来建模所有任务间交互的相互学习方法不同,MGL 配备了类型化函数来处理不同的互补关系,以最大化信息交互。在具有挑战性的数据集(包括 CHAMELEON、CAMO 和 COD10K)上进行的实验证明了 MGL 的有效性,其性能优于现有的最先进方法。
论文三
Uncertainty-aware Joint Salient Object and Camouflaged Object Detection
题目:不确定度联合显着物体和伪装物体检测)

论文:https://arxiv.org/abs/2104.02628
代码:https://github.com/JingZhang617/Joint_COD_SOD
视觉显着物体检测(SOD)旨在找到吸引人类注意力的显着物体,而伪装物体检测(COD)则相反,旨在发现隐藏在周围的伪装物体。本文提出了一种利用矛盾信息来增强显着物体检测和伪装物体检测的检测能力的范例。
首先利用 COD 数据集中的简单正样本作为 SOD 任务中的硬正样本,以提高 SOD 模型的鲁棒性。然后,引入了一个 enquote 相似性度量模块来显式地对这两个任务的矛盾属性进行建模。此外,考虑到两个任务数据集中标记的不确定性,提出了一个对抗性学习网络来实现高阶相似性度量和网络置信度估计。
基准数据集的实验结果表明,本文的解决方案为这两个任务带来了最先进的 (SOTA) 性能。
本文的网络架构和GAN有点类似,其中生成器采用的是Encoder-Decoder框架。其中信息有:
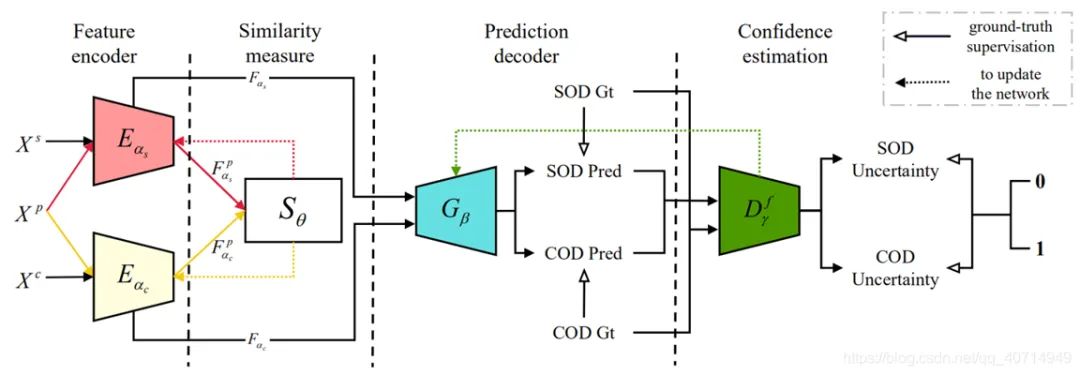
个人感觉看起来像个GAN,其中生成器采用的是Encoder-Decoder框架。其他的信息有:
数据集中的图像
COD数据集中的图像
用于SOD的Encoder, backbone为ResNet50
用于COD的Encoder, backbone为 Net 50
PASCAL VOC 2007 数据集中的图像
相似度度量模块
共同decoder, 能够生成SOD或者COD的预测结果
判别器
性能超越了11个最近模型,包括NLDF(CVPR 2017)、PiCANet(CVPR 2018)、CPD(CVPR 2019)、SCRN(ICCV 2019)、PoolNet(CVPR 2019)、BASNet(CVPR 2019)、EGNet(ICCV 2019)、AFNet(CVPR 2019)、CSNet(ECCV 2020)、F3Net(AAAI 2020)、ITSD(CVPR 2020)。
本文的最大创新点是将Joint Training应用到了SOD、COD这两个近乎相反的任务上。SOD与COD的关注点不同,SOD寻找局部特征的能力有助于COD获得更精确的伪装边界,而COD处理全局信息的能力能帮助SOD减少对背景噪声的误识别。从SOD的角度讲,暂时跳出了如何提升特征融合能力上限这一研究点。
论文四
Simultaneously Localize, Segment and Rank the Camouflaged Objects
题目:同时定位,分割和排序伪装的对象

论文:https://arxiv.org/abs/2103.04011
代码:https://github.com/JingZhang617/COD-Rank-Localize-and-Segment
伪装是整个物种的一个关键防御机制,伪装物体检测(COD)旨在分割隐藏在周围环境中的伪装物体。现有的COD模型是建立在二元地面实况的基础上,对伪装的物体进行分割,而没有说明伪装的程度。
本文重新审视了这一任务,并认为对伪装物体在特定背景下的显眼程度进行建模,不仅可以更好地理解动物的伪装和进化,还可以为设计更复杂的伪装技术提供指导;而且正是伪装物体的一些特定部分,使它们能够被捕食者发现。
基于上述对伪装物体的理解,本文提出了第一个基于排名的COD网络(Rank-Net),以同时对伪装物体进行定位、分割和排名。定位模型的提出是为了找到使伪装物体明显的鉴别性区域。分割模型对伪装物体的全部范围进行分割。排名模型推断出不同伪装对象的可探测性。
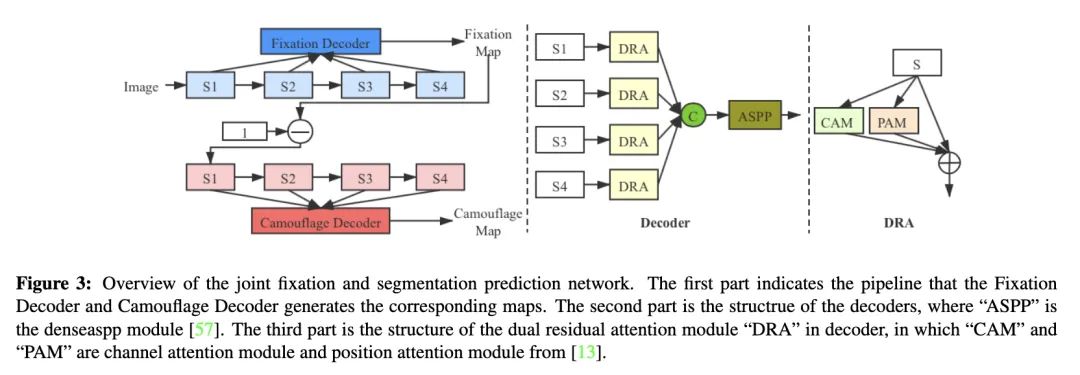
本文主要贡献:
(1)提出了伪装目标排序(COR)和伪装目标鉴别区域定位(COL)这两个新任务,以估计伪装对象的难度并识别伪装对象明显的区域。前者旨在找到使伪装对象可被察觉的辨别区域,而后者试图解释伪装的程度。
(2)在一个联合学习框架中构建了本文的网络(Inferring the ranks of camouflaged objects),以同时定位、分割和排列被标记的对象。其中Fixation Decoder 生成 discriminative region,该区域与周围的环境有更高的对比度,其实也就是大致的伪装对象的位置。Camouflage Decoder生成最终的预测图,使用反向关注的思想,来获得结构化的信息。
(3)提供了一个大型的COD测试集来评估COD模型的泛化能力。实验结果表明,本文模型达到了新的先进水平,导致了一个更可解释的COD网络。此外,生成的区分区域和等级图为理解伪装的本质提供了见解。此外,新测试数据集NC4K可以更好地评估伪装目标检测模型的泛化能力。
Ⅱ 旋转目标检测(Rotation Object Detection)
论文五
ReDet: A Rotation-equivariant Detector for Aerial Object Detection
题目:ReDet:用于航空物体检测的等速旋转检测器)

论文:https://arxiv.org/abs/2103.07733
代码:https://github.com/csuhan/ReDet
航空图像中的物体检测因方向任意分布,检测器需要更多的参数来编码方向信息,这些参数往往是高度冗余和低效的。此外,普通的CNN没有对方向变化进行明确建模,因此需要大量的旋转增强数据来训练一个准确的物体检测器。
本文针对这种问题提出了一个旋转等值检测器(ReDet)。它明确地编码了旋转等值和旋转不变性:将旋转等值网络纳入检测器,以提取旋转等值特征、以准确预测方向,并导致模型大小的巨大减少。基于旋转不变的特征,我们还提出了旋转不变的RoI Align(RiRoI Align),它根据RoI的方向,从等值特征中自适应地提取旋转不变的特征。
在几个具有挑战性的航空图像数据集DOTA-v1.0、DOTA-v1.5和HRSC2016上进行的大量实验表明,我们的方法在航空物体检测任务上可以达到最先进的性能。与以前的最佳结果相比,我们的ReDet在DOTA-v1.0、DOTA-v1.5和HRSC2016上分别获得了1.2、3.5和2.6的mAP,同时参数数量减少了60/%(313Mb vs. 121Mb)。
在本文中,我们提出了旋转等变检测器(ReDet)来解决这些问题,它明确地编码了旋转等方差和旋转不变性。更准确地说,我们将等速旋转网络合并到检测器中以提取等速旋转特征,这些特征可以准确地预测方向并导致模型尺寸大大减小。
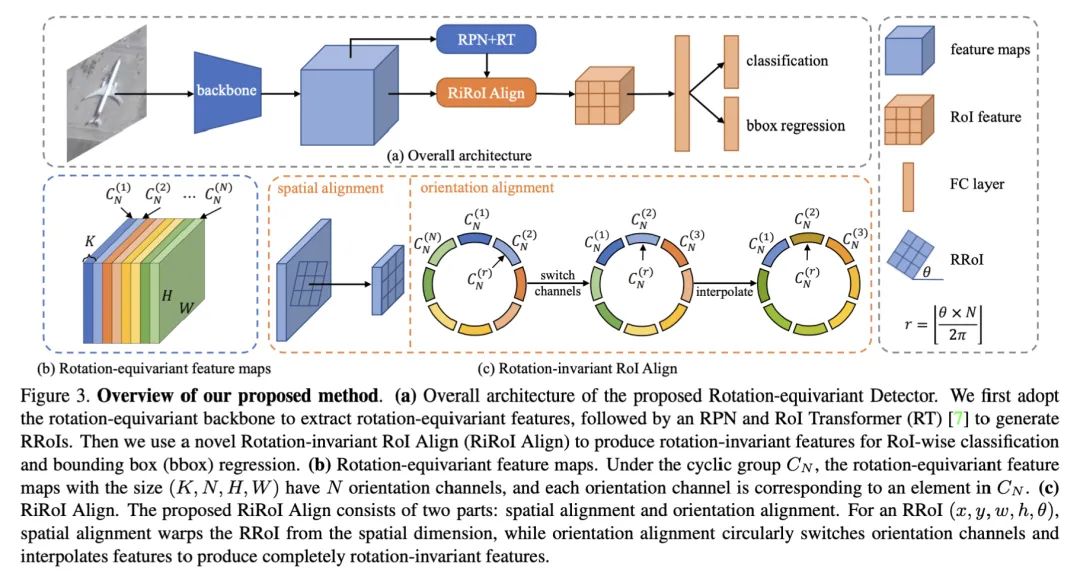
基于旋转不变特征,我们还提出了旋转不变RoI对齐(RiRoI Align),它根据RoI的方向从等变特征中自适应提取旋转不变特征。
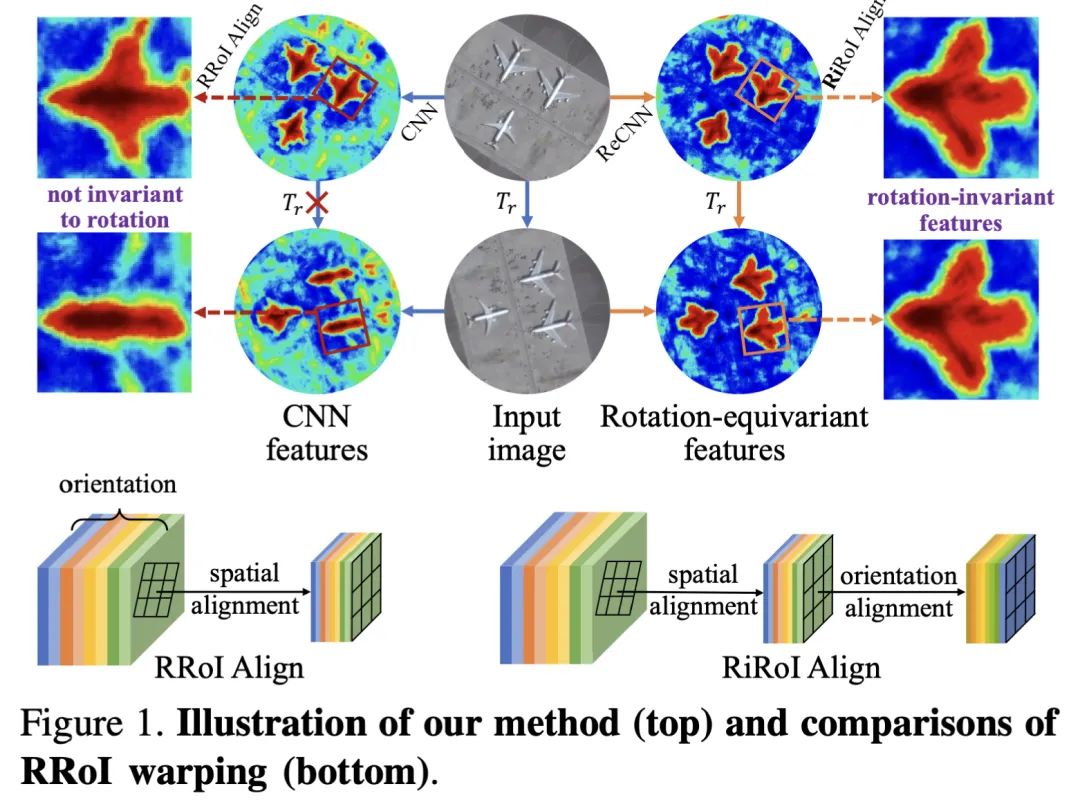
实验结果
在几个具有挑战性的航空影像数据集DOTA-v1.0,DOTA-v1.5和HRSC2016上进行的广泛实验表明,我们的方法可以在航空物体检测任务上实现最先进的性能。与以前的最佳结果相比,我们的ReDet在DOTA-v1.0,DOTA-v1.5和HRSC2016上分别获得了1.2、3.5和2.6 mAP的性能,同时将参数数量减少了60%(313 Mb对121 Mb)。


论文六
Dense Label Encoding for Boundary Discontinuity Free Rotation Detection
题目:解读-DCL:旋转目标检测新方法

论文:https://arxiv.org/abs/2011.09670
代码:https://github.com/yangxue0827/RotationDetection
在许多涉及航空图像、场景文本和人脸等的视觉应用中,旋转检测是一个基本的构建模块。与主要的基于回归的方向检测方法不同,本文探索了一种相对较少研究的基于分类的方法,希望能从本质上解决基于回归的检测器所遇到的边界不连续问题。
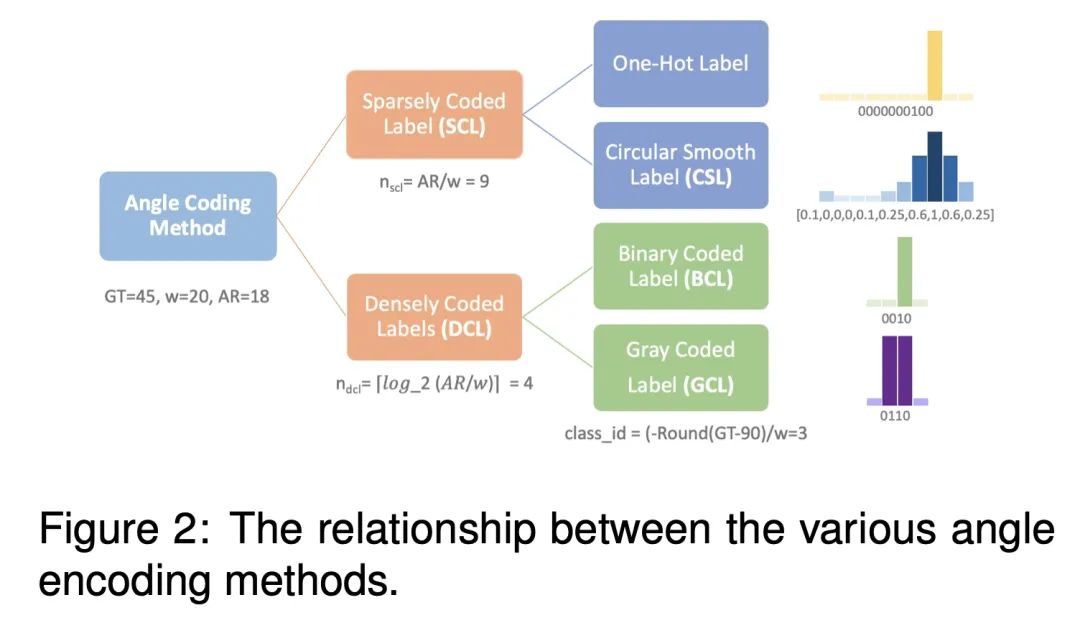
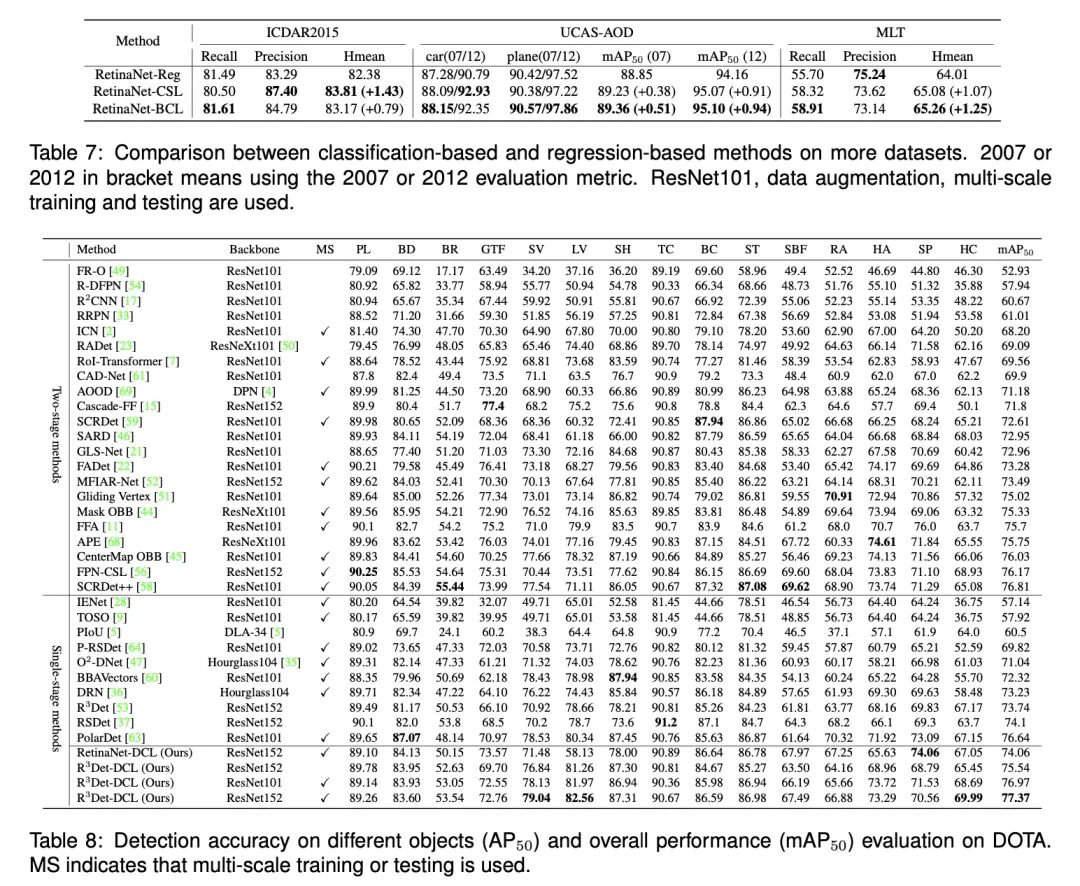
本文从两个方面发展了基于分类的旋转检测方法的研究思路:
(1)新的编码机制:对于预测层,可通过缩短代码长度来实现更轻的预测层。本文设计两个用于角度分类的密集编码标签(DCL),以取代现有的基于分类的检测器中的稀疏编码标签(SCL),此举明显加快了基于方向分类的检测器中的稀疏编码标签模型的训练速度。
(2)进一步提出了角距离和长宽比敏感加权技术(ADARSW)。该技术通过使基于DCL的检测器对角距离和物体的长宽比敏感而进一步提高性能。在不同的检测器和数据集上进行的广泛实验表明,准确性和效率方面都有较好优化。
参考链接
https://blog.csdn.net/qq_41684249/article/details/116483919
https://blog.csdn.net/qq_41684249/article/details/115739761
http://mtw.so/6wm2Rs
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:深度学习,即可下载深度学习算法、3D深度学习、深度学习框架、目标检测、GAN等相关内容近30本pdf书籍。
下载2
在「计算机视觉工坊」公众号后台回复:计算机视觉,即可下载计算机视觉相关17本pdf书籍,包含计算机视觉算法、Python视觉实战、Opencv3.0学习等。
下载3
在「计算机视觉工坊」公众号后台回复:SLAM,即可下载独家SLAM相关视频课程,包含视觉SLAM、激光SLAM精品课程。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 

