
热门标签
热门文章
- 1Linux —— 信号量
- 2贵州省关于做好2024年职称工作有关事项的通知
- 3蚁剑连接不上远程shell的解决办法_蚁剑添加数据成功但连接不上
- 4五年十届WAVE SUMMIT,飞桨汇聚1070万AI开发者,星河社区全要素升级
- 5云原生监控——VictoriaMetrics_vmstorage
- 6FPGA 学习之路_verilog hdl程序设计与实践 xilinx大学计划pdf
- 7探索【Stable-Diffusion WEBUI】的插件:界面主题与中文翻译_stable diffusion 主题
- 8智能电销机器人《各版本机器人部署》_ai电销电话机器人php源码搭建部署(2022完整可用包安装使用
- 9Anaconda中安装cv2包详细教程_conda安装cv2
- 10云原生监控体系建设
当前位置: article > 正文
【爬虫】使用DrissionPage爬取网易云音乐热歌榜
作者:笔触狂放9 | 2024-06-05 05:06:22
赞
踩
drissionpage
DrissionPage
DrissionPage 是一个基于 python 的网页自动化工具。
它既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
它功能强大,内置无数人性化设计和便捷功能。
它的语法简洁而优雅,代码量少,对新手友好。
概述
SessionPage
用于收发数据包的页面对象,只能收发数据包,不能控制浏览器。
ChromiumPage
用于控制浏览器的对象。除了控制一个页面,还能对浏览器整体进行操作,如调整窗口大小位置、管理文件下载、增删标签页等。
WebPage
整合SessionPage和ChromiumPage两者功能的页面元素,拥有两者加起来的全部功能。运行时有 s 和 d 两种模式,能够在两种模式间同步登录信息。
使用SessionPage爬取网易云热歌榜
顾名思义,SessionPage是一个使用Session(requests 库)对象的页面,它使用 POM 模式封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
代码
# 导入 from DrissionPage import SessionPage from DataRecorder import Recorder # 创建页面对象 page = SessionPage() # 创建记录器对象 recorder = Recorder('music_data.csv') # 请求网站url 网易云音乐 热歌榜 top200 page.get('https://music.163.com/discover/toplist?id=3778678') # 遍历页面上所有 li 元素 获取热歌榜Top200的歌名和url for index,li in enumerate(page.eles('xpath://ul[@class="f-hide"]/li')): music_ranking = index + 1 # 排名 music_title = li.ele('tag:a').text music_url = li('tag:a').attr('href') # 请求歌曲url 获取歌手姓名 page.get(music_url) music_singer = page.ele('xpath://p[@class="des s-fc4"]/span').text # print(music_ranking,music_title,music_singer) # 写入到记录器 recorder.add_data((music_ranking,music_title,music_singer)) recorder.record()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行
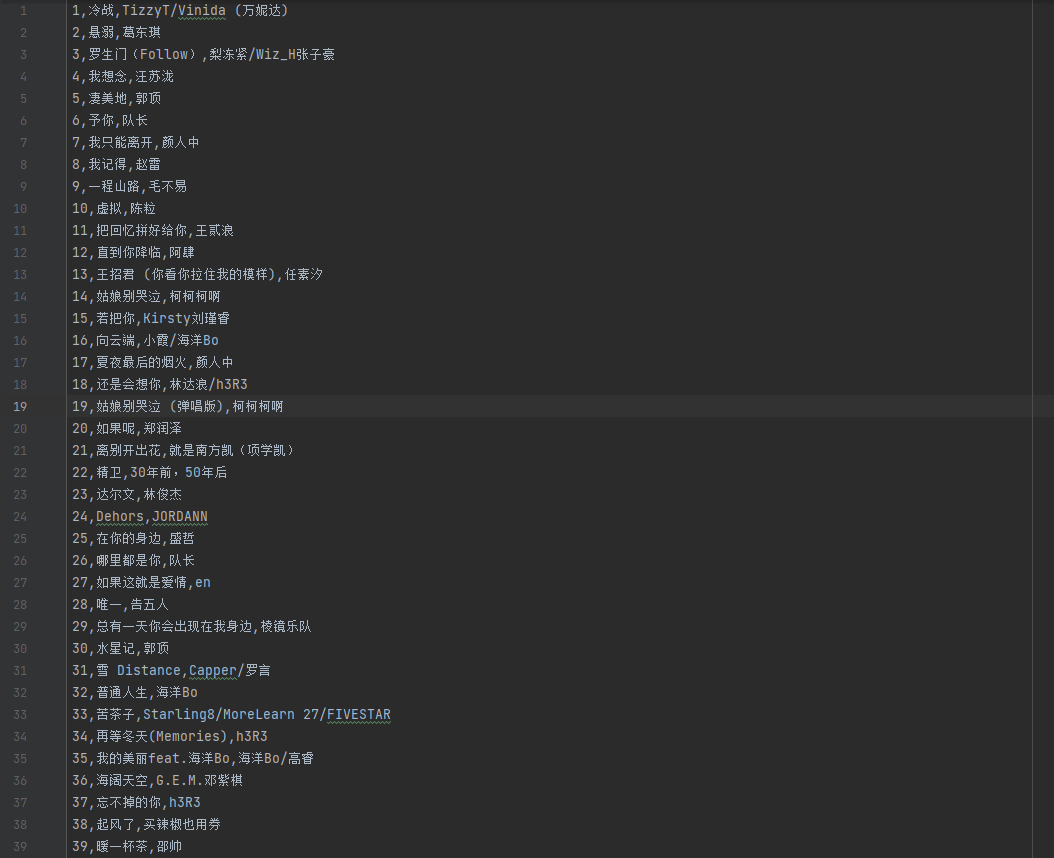
程序生成一个结果文件 data.csv,内容如下图:
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

