
- 1JavaScript全解析——node实现mongodb数据库的操作_javascript操作mongodb
- 2Spark的cache与checkpoint优化_spark checkpoint必须cache
- 3【腾讯云TDSQL-C Serverless 产品体验】新时代数据库大杀器_cms启停
- 4pdps安装oracle12安装,Tecnomatix PDPS安装教程适用于Oracle版本11g
- 5目标检测和跟踪:结合YOLOv和DeepSORT_目标检测跟踪
- 6使用iPhone配置实用工具编辑APN设…_iphone apn描述文件
- 7vue 报错 Uncaught TypeError: Cannot assign to read only property ‘exports‘ of object ‘#<Object>‘
- 82021-08-10_分别调用mesh,surf,surfl,surfc函数绘制曲面z =cosxsiny的图像。
- 9macos brew python3 error: externally-managed-environment_if you wish to install a python library that isn't
- 10讲真,一位8 年 Java 经验大牛的面试总结,你照猫画虎还怕收不到offer?_8年java经验面试都问啥
排序算法:选择排序(直接选择排序、堆排序)
赞
踩
朋友们、伙计们,我们又见面了,本期来给大家解读一下有关排序算法的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、

目录
前言:
承接这一篇文章:排序算法:插入排序(直接插入排序、希尔排序)在这篇文章中我们了解过了排序算法的种类以及如何实现插入排序,那么在这一期的文章中,我们再来学习一下新的排序算法:选择排序。
1.选择排序
1.1基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的 数据元素排完 。
1.2直接选择排序
①在元素集合array[i]--array[n-1]中选择关键码最大(小)的数据元素
②若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
③在剩余的array[i]--array[n-2](array[i+1]--array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
简而言之(排升序)就是在全部的数据中选择出最小的依次放在前面的位置,来完成排序。
这样的排序方式一次只可以选择一个数据,我们可以再次基础上进行改良,我们可以一次选择排序两个数据:设置两个下标,前面的下标从前往后找最小的数,后面的下标从后往前找最大的数,依次进行排序,这种方法明显是比前面的方法更优,那么我们就来入手这个算法:
::算法思路
首先呢,我们需要有两个起始的下标,一个下标在数据的开头,一个下标在数据的末尾,然后需要再来两个下标来记录最大值和最小值,将记录最大最小值的下标初始设置为第一个输一局,紧接着开始进行一趟的比较,在数据开头的下标从头开始往后遍历跟最小值进行比较然后找到最小值,在数据末尾的下标从后往前开始遍历于最大值进行比较找到最大值,然后将最小值与开头的第一个值进行交换,将最大值与末尾的值进行交换,这样子就将最小值排到了最前面,将最大值排到了最后面,然后将区间缩小,开头的下标++变为新的开头,末尾的下标--变为新的末尾,然后进行新一轮的比较,当开头和下标和末尾的下标重合即可结束排序。
代码演示:
我们可以用一组数据来演示一下:9,8,5,6,3,2,1,4,7,0
可以发现,本次排序结果并不是我们想要的结果,那这是什么原因呢?我们可以通过调试来发现问题:


所以当为了防止begin和maxi重叠这种特殊情况的发生,在完成第一次交换之后,此时mini的位置就是最大值的位置,所以直接将mini赋给maxi,即可完成正确的交换。
优化代码:
::直接排序算法完整代码
1.3直接选择排序算法特性
直接选择排序的特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
2.堆排序
堆排序在之前的文章都有所介绍,在这里就直接上手,如果有什么不懂的可以去看之前的文章:排序算法:堆排序
我们知道堆排序最优的方法是向下调整建堆,在建堆时要注意的点就是:排降序建小堆,排升序建大堆、向下调整算法使用的前提是向下调整的结点的下面必须是堆。
::堆排序算法完整代码
- //交换函数
- void Swap(int* p1, int* p2)
- {
- int tmp = *p1;
- *p1 = *p2;
- *p2 = tmp;
- }
-
- //向下调整
- void AdjustDown(int* a, int n, int parent)
- {
- //假设左孩子为左右孩子中最小的节点
- int child = parent * 2 + 1;
-
- while (child < n) //当交换到最后一个孩子节点就停止
- {
- if (child + 1 < n //判断是否存在右孩子
- && a[child + 1] > a[child]) //判断假设的左孩子是否为最小的孩子
- {
- child++; //若不符合就转化为右孩子
- }
- //判断孩子和父亲的大小关系
- if (a[child] > a[parent])
- {
- Swap(&a[child], &a[parent]);
- //更新父亲和孩子节点
- parent = child;
- child = parent * 2 + 1;
- }
- else
- {
- break;
- }
- }
- }
-
- //O(N * logN)
- void HeapSort(int* a, int n)
- {
- //建堆--向下调整算法建堆
- //时间复杂度为O(N)
- for (int i = ((n - 1) - 1) / 2; i >= 0; --i)
- {// 这里的n-1表示最后一个叶子节点
- // 最后一个叶子节点的父亲就是:
- // (n-1)-1/2;
- AdjustDown(a, n, i);
- }
-
- //O(N * logN)
- int end = n - 1;
- while (end > 0)
- {
- //交换堆顶和最后一个数据的位置
- Swap(&a[0], &a[end]);
- //向下调整,找次小的
- AdjustDown(a, end, 0);
- end--;
- }
- }

2.1堆排序算法特性
1. 堆排序使用堆来选数,效率就高了很多。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
3.算法效率比较
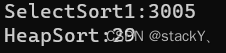
比较算法的快慢我们依旧使用这样的一段代码来进行检测:
可以看到堆排序比直接选择排序快了不止100倍,所以在平时呢直接选择排序不会经常使用,我们只需要学习它的思想,然而堆排序是比较好的算法,我们需要熟练掌握。
朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!

