
热门标签
热门文章
- 1k近邻法的原理与实现_试简述k近邻算法,并描述k值选择对算法的结果的影响,假设给定6个二维数据点
- 2一文看懂各种场景的git撤销回滚操作_git stage的怎么撤销
- 3服务器安装SSH远程管理和sshd_config文件找不到怎么解决_etc目录中没有sshd
- 4Android:实现安卓小程序-记事本(备忘录)的开发_备忘录app开发
- 5一文了解tcp/ip协议的运行原理_tcpip协议是如何工作的
- 6【gitlib】linux系统rpm安装gitlib最新版本及修改clone地址_linux升级gitlab
- 7在github.io部署个人博客hugo,2023新教程_github .io
- 8MySQL8 忽略大小写配置lower_case_table_names = 1 (CentOS7)_mysql8 忽略数据库大小写
- 9SQL Server 查询处理过程_sql server怎么把调试改成查询
- 10将针孔模型相机 应用到3DGS_opengl 3dgs
当前位置: article > 正文
书生·浦语大模型实战营笔记-第六节 OpenCompass 大模型评测_opencompass评测数据集选择
作者:笔触狂放9 | 2024-06-11 20:47:53
赞
踩
opencompass评测数据集选择
书生·浦语大模型实战营笔记
第六节 OpenCompass 大模型评测
前言
提示:这里可以添加本文要记录的大概内容:
介绍大模型评测的基本知识,OpenCompass工具介绍,并实现一个评测的demo
提示:以下是本篇文章正文内容,下面案例可供参考
一、模型评测
1.为什么需要评测
公平统一的了解模型的效果

2.测评的维度
知识语言推理、情感倾向、长文本生成、agent、垂直领域问答
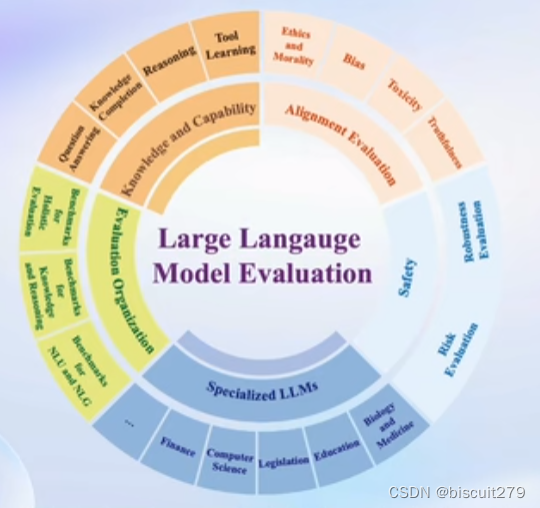
3.如何进行评测
基座模型和微调后的模型有所不同
客观评测和主观评测(人工评价和模型评价)
提示词工程:换prompt看是否还能答对
二、OpenCompass评测框架
1.主流的大模型评测框架

2.OpenCompass
成熟完善的测评平台架构
丰富的模型支持
成熟的流水线设计:开源模型和API模型都可以测评,易于拓展到自己的模型和数据集
有模型能力榜单
多模态模型有MMBench框架
专家领域也有特有的评测集
三、大模型评测demo
1.环境安装与数据准备
首先准备环境
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base # 创建环境
conda activate opencompass # 激活环境
- 1
- 2
随后下载安装opencompass项目:
git clone https://github.com/open-compass/opencompass # 下载opencompass项目
pip install -e . # 安装opencompass项目
- 1
- 2
git连接不稳定,报错HTTP503,选择下载zip包之后上传到开发机,解压
unzip opencompass-main.zip
cd opencompass-main
pip install -e .
- 1
- 2
- 3
数据准备:
cp /share/temp/datasets/OpenCompassData-core-20231110.zip ./ # 拷贝数据
unzip OpenCompassData-core-20231110.zip # 解压
- 1
- 2
查看支持的数据集和模型
python tools/list_configs.py internlm ceval
- 1

2.启动测评
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
- 1
分别指定了hf格式的模型路径、hf格式的tokenizer路径,tokenizer参数,模型参数,最大序列长度,最大token数量,batch大小,GPU数量,debug模型
也可以用python run.py configs/xxxx.py,现将model,Dataset,infer写好,直接运行
运行结束后,可以再output/default下找到一个用时间命名的文件夹,里面存放了模型的评估结果,下图展示了单个实验的汇总评估结果。

总结
主要介绍了模型评测的基础知识,opencompass工具的使用方法,随后实现了internlm7b模型在C-Eval数据集下的效果。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/704737
推荐阅读
相关标签

