
- 1jdbc连接mysql数据库的5种常用方法_javawebjdbc连接mysql数据库
- 2GIT常见问题_git postbuffer
- 3git下载ardupilot时出现“过早的文件结束符”问题解决方法_虚拟机中git 过早的文件结束符
- 4区块链|一份全面的区块链知识图谱_通过信息检索,制作一张区块链起源和发展的思维导图
- 5【SVD(奇异值分解)】详解及python-Numpy实现_numpy svd
- 6C#中常见集合类的底层原理与时间复杂度_c#集合类型时间复杂度
- 7感谢上天,我被失联2年后,终于活着从东南亚菠菜公司的技术“魔窟”逃出来了......
- 8git识别不到文件名大小写变更_git vscode校验文件大小写
- 9鸿蒙HarmonyOS实战-ArkTS语言基础类库(并发)_arkts线程(3)_鸿蒙arkts浅拷贝
- 10程序员每天会阅读哪些技术网站来提升自己?_程序员提升自己学习github上的项目吗
Kafka源码解析-生产者_akfka源码
赞
踩
1 Kafka源码解析-生产者
在平时使用kafka的过程,总觉得生产者发送消息是简单的,这是因为在工作中只需要确认生产者和消费者发送和接受消息的内容,就可以完成我们的工作,但是实际上不是的,我们需要考虑不同业务场景的适用性,调整我们的配置方案。
接下来,本文将主要介绍kakfa生产者的内容。PS:展示的Kafka源码版本为3.3.2。

1.1 原理分析
生产者的基本工作就是创建消息,并通过网络发送到对应服务器。但是在这简单步骤之中,Kafka又做了哪些改动,能够让我们业务上可以使用简单几行配置,就可以实现我们想要的能力呢?这也是我们需要学习原理的原因,清楚这些配置的影响。
1.1.1 整体架构
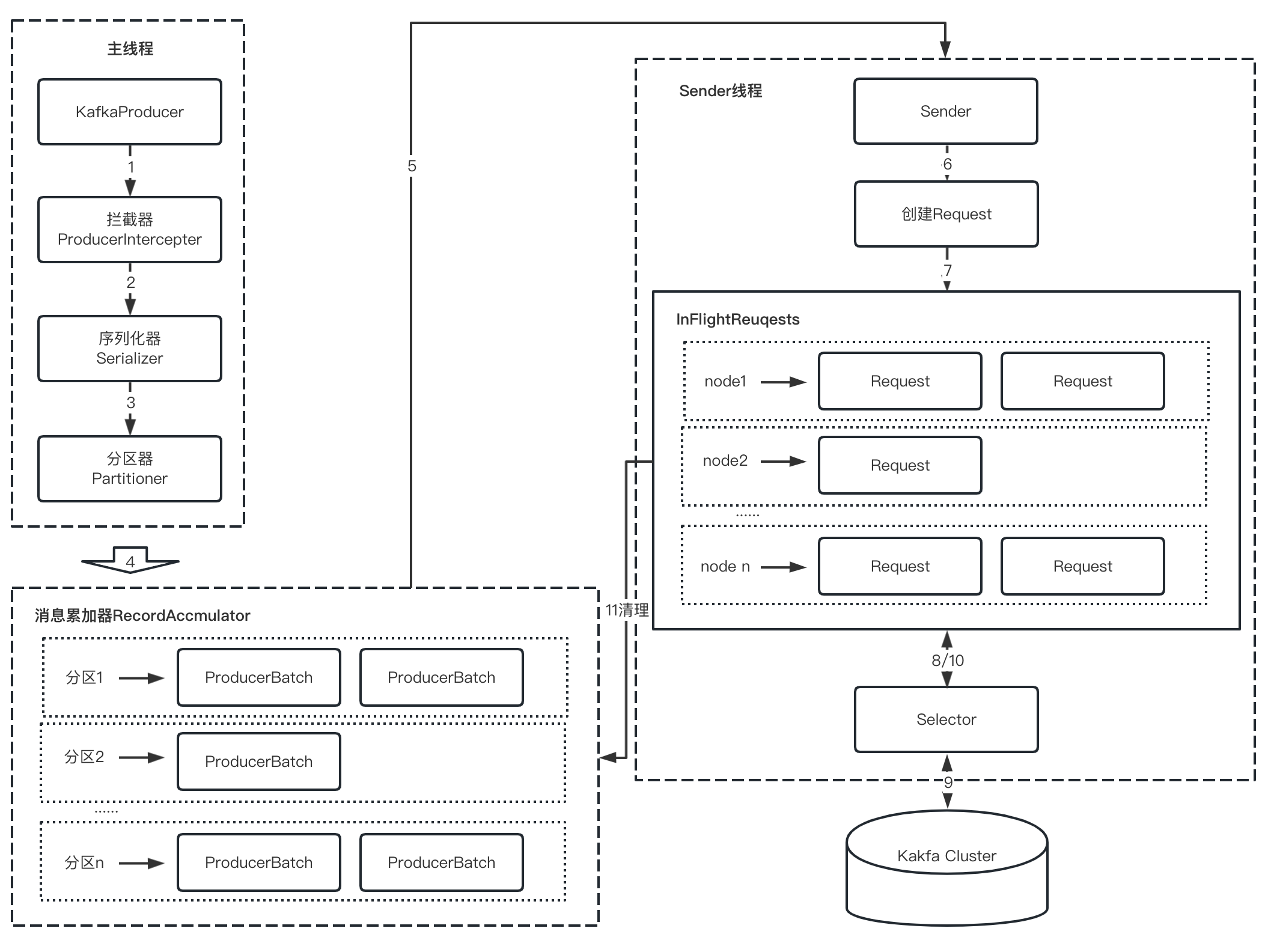
生产者的整体架构如上图所示,其所有工作分给了2个线程协作完成,一个是主线程(负责消息的预处理),第二个是发送线程(sender线程负责将发送消息以及接受发送的结果)。
接着,我们按照一个正常消息发送过程要经历的步骤进行介绍。
1 拦截器-onSend
拦截器是当我么调用 send 方法要经历的一个组件,但拦截器不是必要的功能,但是如果有需求对发送消息进行统一的修改等操作就变得有用,不需要用户单独再写业务逻辑。
添加拦截器需要实现的接口 ProducerInterceptor 中有3个方法,其中 *onSend *是在用户调用 send 方法之后,内部实际执行其他发送逻辑的 doSend 方法之前执行。
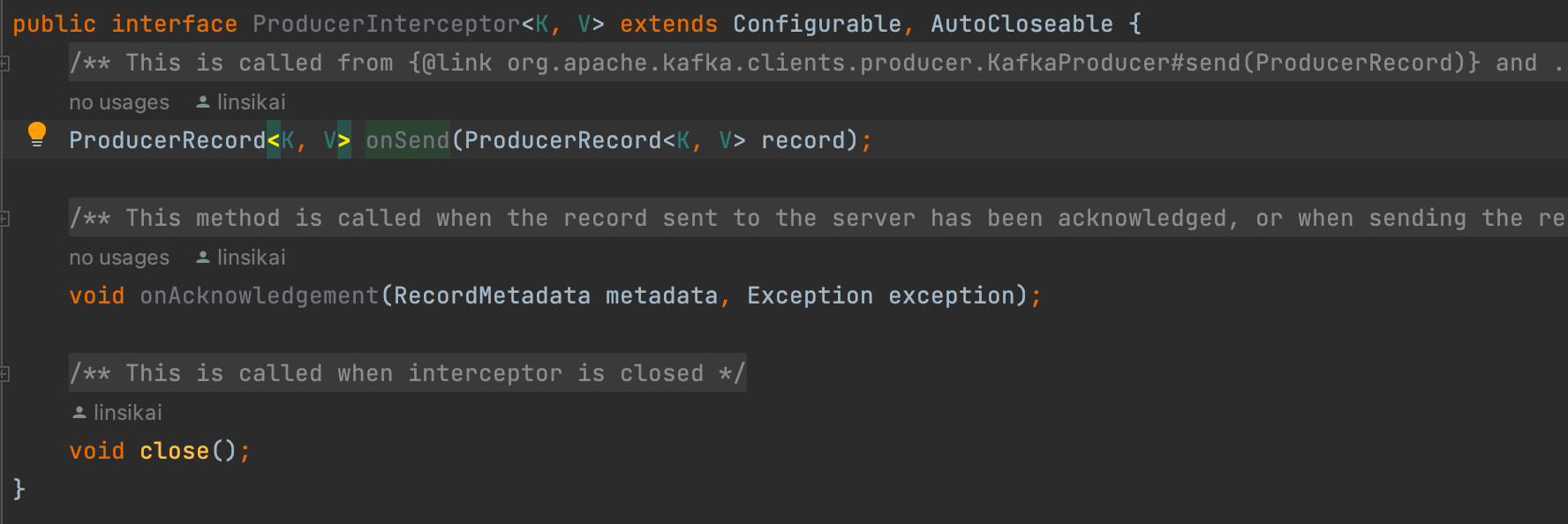
我们可以配置多个拦截器,多个拦截器将按照插入顺序形成拦截器链,值得注意的是拦截器发生异常抛出的异常会被忽略;此外,也要注意一种情况:如果某个拦截器依赖上一个拦截器的结果,但是当上一个拦截器异常,则该拦截器可能也不会正常工作,因为他接受到的是上一个成功返回的结果,而不是期望的上一个拦截器结果。源码中调用过程如下图所示:
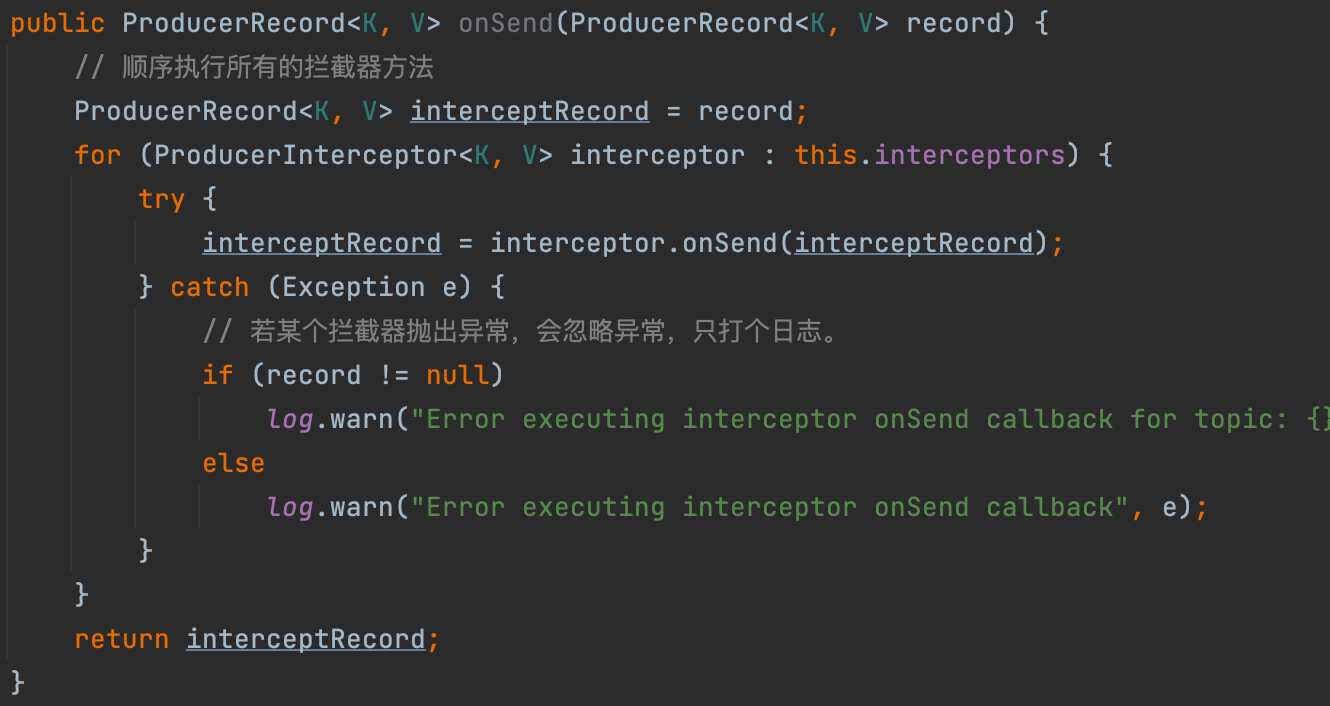
下面继续执行doSend方法。
2 序列化器
生产者需要通过序列化器(Serializer)将对象转换字节数组才能通过网络发送到 Broker,而在消费者端需要使用对应的反序列化器将字节数组转化为相应的对象。目前客户端支持的序列化类型有如下这些:包括 ByteArray、ByteBuffer、Double、Float 和 String 等等。每种类型对应序列化和反序列化器。

PS:其中的 Serde 和 Serdes 是将序列化器和反序列化器放在一起,用时再讨论。 每个序列化器均实现了Serializer接口,此接口有3种方法:

-
configure:默认是UTF8编码,也可以使用
key.serializer.encoding、value.serializer.encoding或serializer.encoding指定编码格式; -
serialize:将String类型转换为byte[]类型。
自定义序列化器实现接口方法即可,不赘述。
3 分区器
在调用doSend发送消息到过程中,分区逻辑如下:

-
若发送的记录ProducerRecord有指定分区使用指定分区
-
若提供自定义的分区器,则使用
-
若有key且不忽略,则使用hash算法+取余得出分区
-
未知分区代表会被分配给任意可用分区
对于未知分区,在加入到消息累加器之前,会通过一个内建分区器 BuiltInPartitioner 去从可用分区中轮询得出下一个分区号。
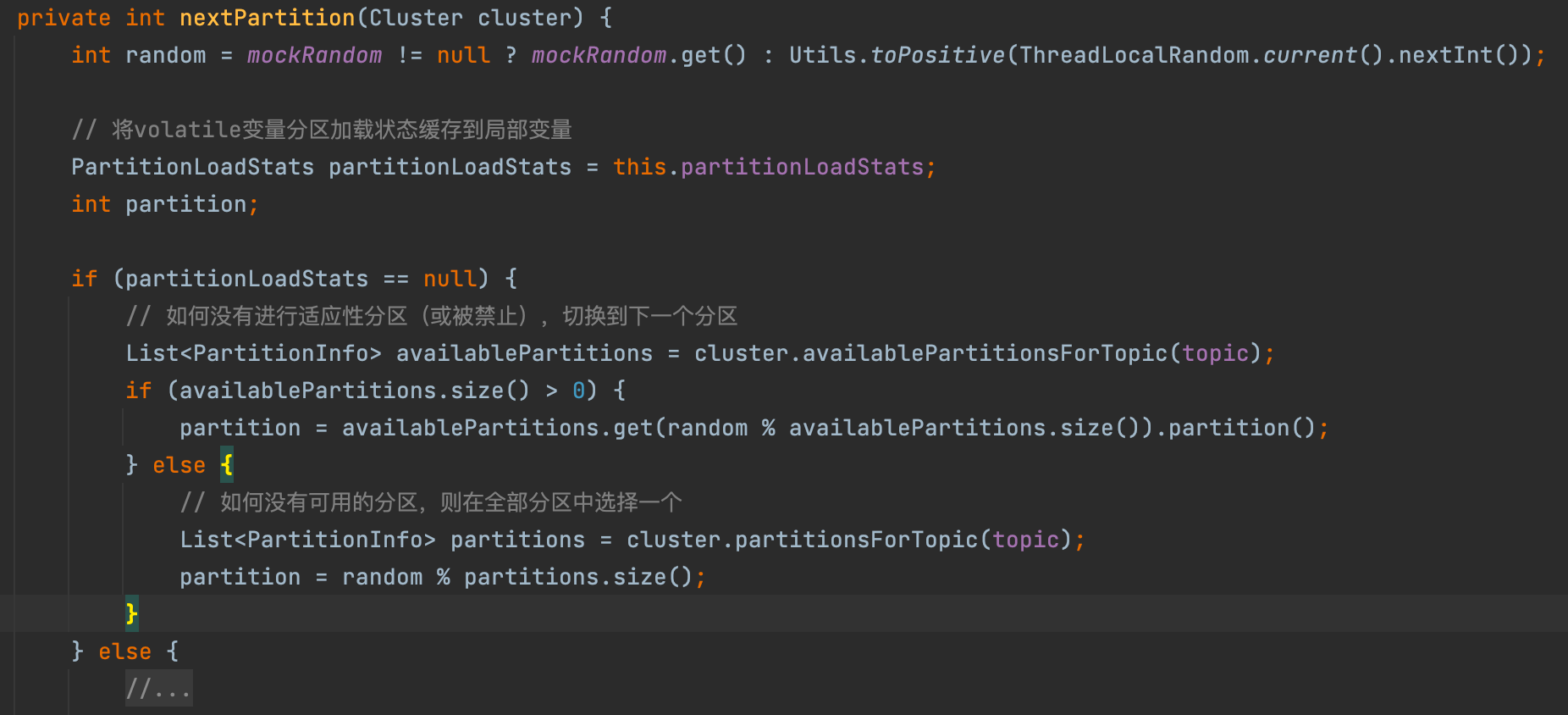
自定义分区器需要实现Partitioner接口,不再赘述。
4 数据放入消息累加器
消息在主线程中经过拦截器、序列化器和分区器后,被缓存到消息累加器(RecordAccumulator)中。sender 线程则负责将在 RecordAccumulator 中的消息发送到 Kafka 。
消息累加器的作用是缓存消息以便sender线程可以批量发送,进而减少网络传输的资源消耗提升性能。消息累加器的缓存大小可以通过生产者参数 buffer.memory 配置,默认为32MB。若主线程发送消息的速度超过sender线程发送消息的速度,会导致消息累加器被填满,这时候再调用生产者客户端的send方法会被阻塞,若阻塞超过60秒(由参数max.block.ms控制),则会抛出异常 BufferExhaustedException 。
主线程发送的数据由这样的结构保存:首先按照 Topic 进行划分,每个 Topic 会有一个 Map(key:Topic,value:TopicInfo);之后,按照分区进行划分,TopicInfo 里也有一个 Map(key:分区号,value:Deque<ProducerBatch>),每个双端队列会保存多个消息批次。当有消息发送时,会从对应 Topic 、对应分区的双端队列的尾部取出一个批次,将消息追加到后面。这种结构的目的在于:
-
使用字节的使用更加紧凑,节约空间
-
多个小的消息组成一个批次一起发送,减少网络请求次数提升吞吐量。因为 sender 线程发送消息的基本单位时批次,它会从双端队列的头部取数据发送。
ProducerBatch 的大小与 batch.size 参数(默认16KB)密切相关。此外,Kafka 生产者使用 BufferPool 实现内存的复用。
消息累加器的基本结构如下图所示,红色+绿色区域总大小32MB,一个池中单位 ByteBuffer 大小16KB。
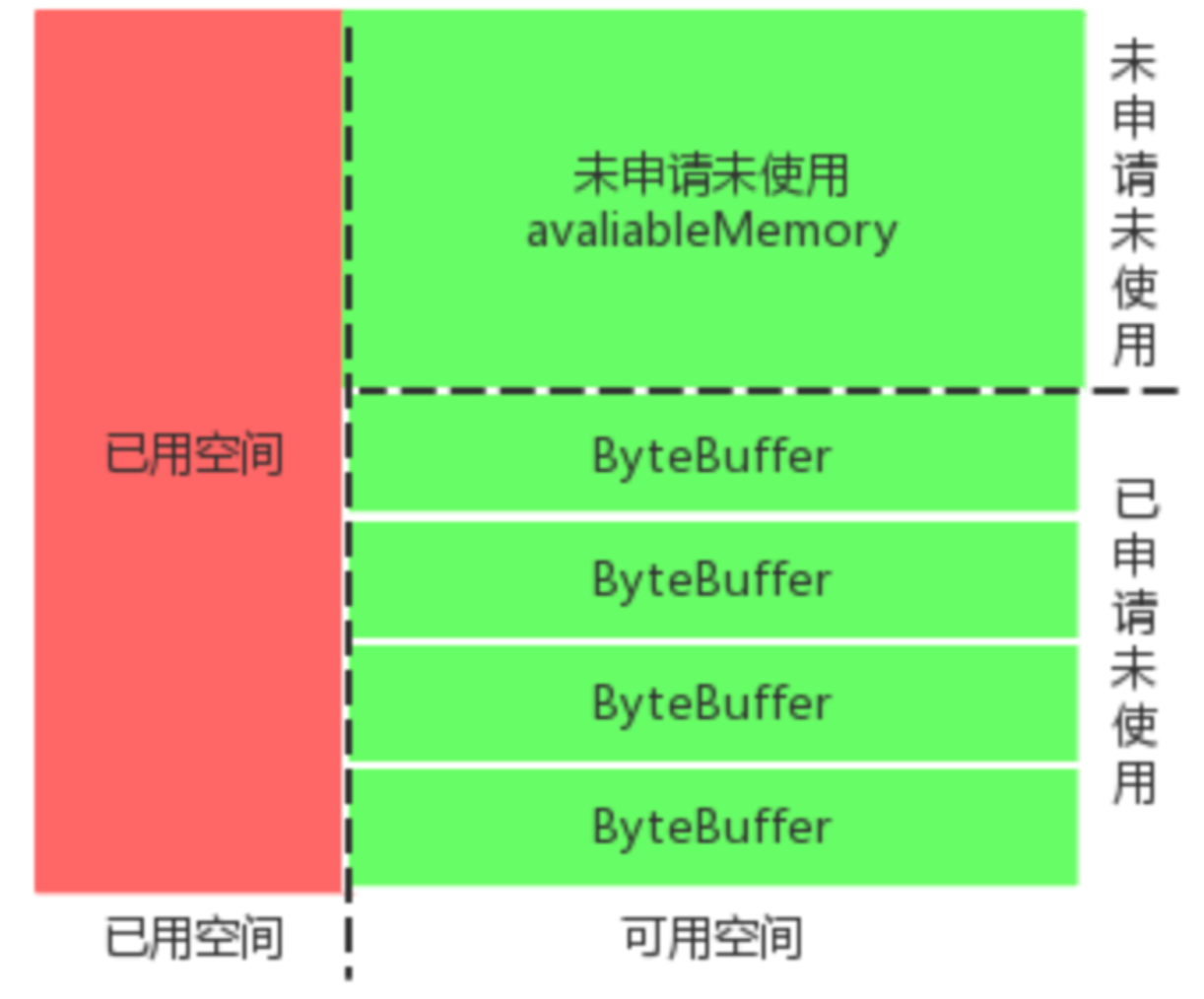
举个例子:假设刚启动新插入一条消息,对应的 Topic 、对应的 Deque<ProducerBatch> 为空,这时执行如下代码尝试开辟空间:

allocate 方法的过程拆解如下:
-
如果申请空间的大小最大大小(
buffer.memory默认32MB),则直接抛出异常; -
操作缓存池之前尝试获取可重入锁,若获取的空间(size)正好等于每个批次预设大小(
batch.size默认16KB),则直接从Deque<ByteBuffer>中取出第一个 ByteBuffer 返回;否则只能是 size大小大于批次预设大小,进行下一步。 -
计算剩余的空闲空间,即池中空闲空间+池外空闲空间(nonPooledAvailableMemory)。如果剩余的空闲空间大于size,则进行第4步;如果小于size,则进行第5步;
-
直接使用池外空闲空间分配,若不够在取池内空闲空间,最后返回。
-
将当前线程加入到等待队列(waiters)的尾部,如果等待超时也没有足够的空间,则抛出异常;若中途被唤醒,则进行下一步;
-
中途唤醒后有两种情况,当释放的空间正好等于一个批次大小且自己没有累计获得空间,则获取后返回;否则累计获取释放空间,满足后才会返回。

sender 线程从消息累加器获取准备好可以发送消息(等待时候是否超过linger.ms参数设置的时间、或批次个数大于1或第一个批次已满)后,遍历每个 Topic 下的分区批次,根据分区 leader,将数据有转变成<Node,List<ProducerBatch>>的形式( Node 代表 Broker 节点)以便向各个目的 Node 发送数据。 在实际发送之前,消息还会将批次列表消息保存到 InFlightRequest 请求中,即转变成 Map<NodeId, Deque<InFlightRequest>>结构,这样做的目的是缓存已经发出去但没收到响应的请求,NodeId 对应一个 broker 节点 id ,也就是一个连接,每个连接最多堆积的未完成请求为5个(max.in.flight.requests.per.connection参数配置)。
1.1.2 元数据的更新
通过获取 InFlightRequest 请求中未确认请求的数量确定各个节点目前负载情况,即未确认数越多,负载越大。负载最小节点被称为 LeastLoadedNode,选择该节点发送更新元数据,可以尽量避免因网络阻塞等问题。
元数据是什么?
是指Kafka集群的元数据,记录了集群中有哪些主题,这些主题有哪些分区,每个分组的 leader 副本、follower 副本分别在那个节点上,哪些副本在 AR、ISP 等集合中,集群中有哪些节点,控制器节点又是哪些。
元数据更新时机?
-
当客户端中没有需要的元数据信息
-
超过5分钟(
metadata.max.age.ms参数配置)没有更新元数据。
1.2 重要的生产者参数
-
acks:确认数量配置参数
acks=1:保证分区中的 leader 副本写入成功,是吞吐量和可靠性的折中方案。
acks=0:只负责发送,不确认写入结果,吞吐量最高,可靠性最低。
acks=-1/all:保证所有 ISR 集合所有副本均确认写入成功,最可靠,由于ISR中可能只有 leader 副本,因此需要配合 min.insync.replicas 参数配合。
-
max.request.size:生产者发送消息的最大值,默认1MB,调整时注意会不会被broker端的 message.max.bytes 参数拒收。
-
retries和retry.backoff.ms:发生可重试异常时的重试次数,以及两个重试之间的时间间隔。 如果要保证写入顺序有序,一定要将 max.in.flight.requests.per.connection 设置为1。
-
compression.type:压缩数据的方式。
-
connections.max.idle.ms:空闲连接多久之后会被关闭,默认9分钟。
-
linger.ms:发送数据之前等待的最长时间,这段时间内可以积累更多的待发送数据一起发出去,默认为0。如果消息累加器被填满,不用等到 linger.ms 时间用完也会立即发送。
-
reveive.buffer.bytes:设置接收消息缓冲区的大小,默认值为32KB,设置为-1会使用OS的默认值。
-
send.buffer.bytes:设置发送消息缓冲区的大小,默认值为128KB,设置为-1会使用OS的默认值。
-
request.timeout.ms:生产者等待响应的最长时间,默认值为30秒,这个参数应该要比 broker 端的 replica.lag.time.max.ms 大,以减少因客户端重试而导致消息重复的可能性。


