
VMware、KVM、Docker之虚拟化技术框架和原理——【转载自微信公众号开源linux】_虚拟容器化部署ppt架构图
赞
踩

说起虚拟化你会想到什么?从我们常用的虚拟机三件套VMware、VirtualPC、VirutalBox到如今大火的KVM和容器技术Docker?

这些技术是什么关系,背后的技术原理是怎样的,又有什么样的区别,各自应用的场景又是什么样的?
历史背景
虚拟化(技术)是一种资源管理技术,是将计算机的各种实体资源(CPU、内存、磁盘空间、网络适配器等),予以抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。
分区技术使得虚拟化层为多个虚拟机划分服务器资源的能力;使您能够在一台服务器上运行多个应用程序,每个操作系统只能看到虚拟化层为其提供的虚拟硬件。
虚拟机隔离让虚拟机是互相隔离,一个虚拟机的崩溃或故障(例如,操作系统故障、应用程序崩溃、驱动程序故障等等)不会影响同一服务器上的其它虚拟机。
封装意味着将整个虚拟机(硬件配置、BIOS 配置、内存状态、磁盘状态、CPU 状态)储存在独立于物理硬件的一小组文件中。这样,您只需复制几个文件就可以随时随地根据需要复制、保存和移动虚拟机
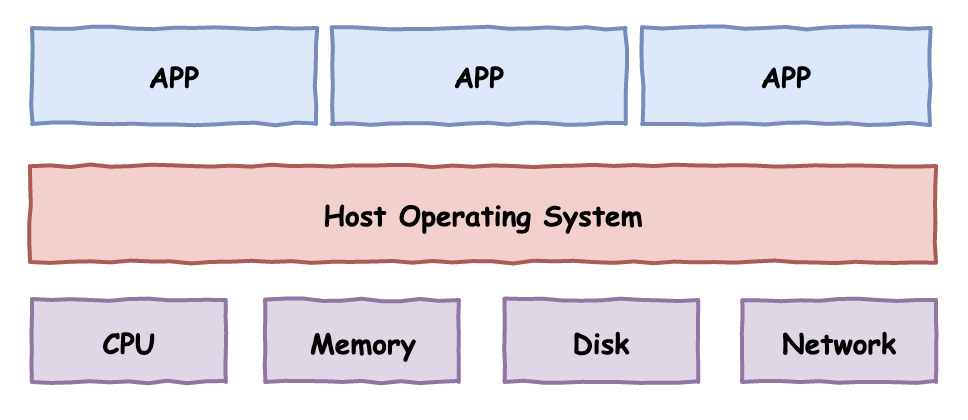
对于一台计算机,我们可以简单的划分为三层:从下到上依次是物理硬件层,操作系统层、应用程序层。
在计算机技术的发展历史上,出现了两种著名的方案,分别是I型虚拟化和II型虚拟化。
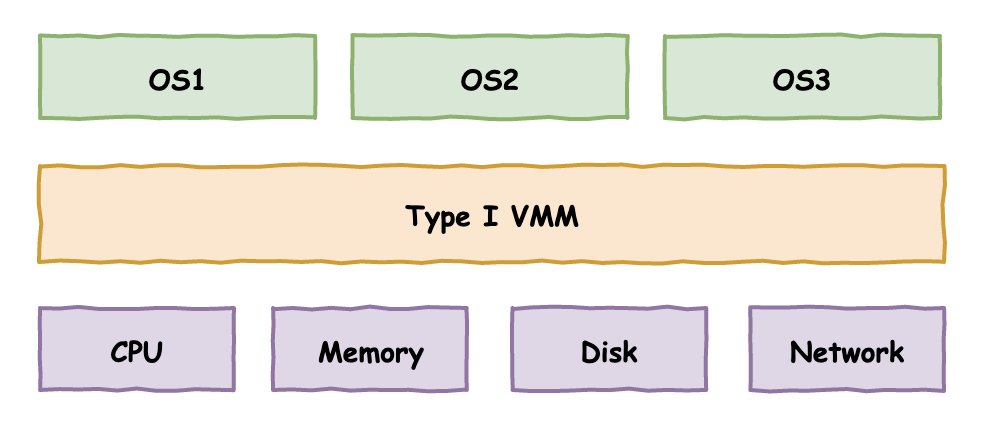
I型虚拟化
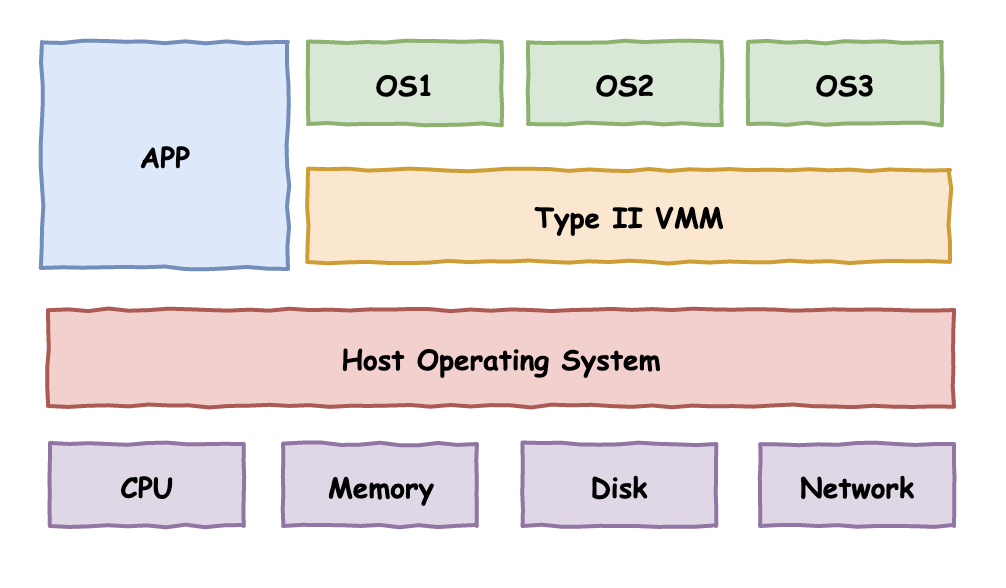
II型虚拟化
图中的VMM意为Virtual Machine Monitor,虚拟机监控程序,或者用另一个更专业的名词:HyperVisor
全虚拟化:VMware 二进制翻译技术
不同于8086时代16位实地址工作模式,x86架构进入32位时代后,引入了保护模式、虚拟内存等一系列新的技术。同时为了安全性隔离了应用程序代码和操作系统代码,其实现方式依赖于x86处理器的工作状态。
这就是众所周知的x86处理器的Ring0-Ring3四个“环”。

操作系统内核代码运行在最高权限的Ring0状态,应用程序工作于最外围权限最低的Ring3状态,剩下的Ring1和Ring2主流的操作系统都基本上没有使用。
这里所说的权限,有两个层面的约束:
-
能访问的内存空间
-
能执行的特权指令
来关注一下第二点,特权指令。
CPU指令集中有一些特殊的指令,用于进行硬件I/O通信、内存管理、中断管理等等功能,这一些指令只能在Ring0状态下执行,被称为特权指令。这些操作显然是不能让应用程序随便执行的。处于Ring3工作状态的应用程序如果尝试执行这些指令,CPU将自动检测到并抛出异常。
回到我们的主题虚拟化技术上面来,如同前面的定义所言,虚拟化是将计算资源进行逻辑或物理层面的切割划分,构建出一个个独立的执行环境。
按照我们前面所说的陷阱 & 模拟手段,可以让虚拟机中包含操作系统在内的程序统一运行在低权限的Ring3状态下,一旦虚拟机中的操作系统进行内存管理、I/O通信、中断等操作时,执行特权指令,从而触发异常,物理机将异常派遣给VMM,由VMM进行对应的模拟执行。
这本来是一个实现虚拟化很理想的模式,不过x86架构的CPU在这里遇到了一个跨不过去的坎。
到底是什么问题呢?
回顾一下前面描绘的理想模式,要这种模式能够实现的前提是执行敏感指令的时候能够触发异常,让VMM有机会介入,去模拟一个虚拟的环境出来。
但现实是,x86架构的CPU指令集中有那么一部分指令,它不是特权指令,Ring3状态下也能够执行,但这些指令对于虚拟机来说却是敏感的,不能让它们直接执行。一旦执行,没法触发异常,VMM也就无法介入,虚拟机就露馅儿了!
这结果将导致虚拟机中的代码指令出现无法预知的错误,更严重的是影响到真实物理计算机的运行,虚拟化所谓的安全隔离、等价性也就无从谈起。
怎么解决这个问题,让x86架构CPU也能支持虚拟化呢?
VMware和QEMU走出了两条不同的路。
VMware创造性的提出了一个二进制翻译技术。VMM在虚拟机操作系统和宿主计算机之间扮演一个桥梁的角色,将虚拟机中的要执行的指令“翻译”成恰当的指令在宿主物理计算机上执行,以此来模拟执行虚拟机中的程序。你可以简单理解成Java虚拟机执行Java字节码的过程,不同的是Java虚拟机执行的是字节码,而VMM模拟执行的就是CPU指令。

另外值得一提的是,为了提高性能,也并非所有的指令都是模拟执行的,VMware在这里做了不少的优化,对一些“安全”的指令,就让它直接执行也未尝不可。所以VMware的二进制翻译技术也融合了部分的直接执行。
对于虚拟机中的操作系统,VMM需要完整模拟底层的硬件设备,包括处理器、内存、时钟、I/O设备、中断等等,换句话说,VMM用纯软件的形式“模拟”出一台计算机供虚拟机中的操作系统使用。
这种完全模拟一台计算机的技术也称为全虚拟化,这样做的好处显而易见,虚拟机中的操作系统感知不到自己是在虚拟机中,代码无需任何改动,直接可以安装。而缺点也是可以想象:完全用软件模拟,转换翻译执行,性能堪忧!
而QEMU则是完全软件层面的“模拟”,乍一看和VMware好像差不多,不过实际本质是完全不同的。VMware是将原始CPU指令序列翻译成经过处理后的CPU指令序列来执行。而QEMU则是完全模拟执行整个CPU指令集,更像是“解释执行”,两者的性能不可同日而语。
半虚拟化:Xen 内核定制修改
既然有全虚拟化,那与之相对的也就有半虚拟化,前面说了,由于敏感指令的关系,全虚拟化的VMM需要捕获到这些指令并完整模拟执行这个过程,实现既满足虚拟机操作系统的需要,又不至于影响到物理计算机。
但说来简单,这个模拟过程实际上相当的复杂,涉及到大量底层技术,并且如此模拟费时费力。
而试想一下,如果把操作系统中所有执行敏感指令的地方都改掉,改成一个接口调用(HyperCall),接口的提供方VMM实现对应处理,省去了捕获和模拟硬件流程等一大段工作,性能将获得大幅度提升。
这就是半虚拟化,这项技术的代表就是Xen,一个诞生于2003年的开源项目。

这项技术一个最大的问题是:需要修改操作系统源码,做相应的适配工作。这对于像Linux这样的开源软件还能接受,充其量多了些工作量罢了。但对于Windows这样闭源的商业操作系统,修改它的代码,无异于痴人说梦。
虚拟化软件架构分类
服务器虚拟化是云计算非常关键的技术之一,虚拟化的含义很广泛,包括服务器、存储、网络以及数据中心虚拟化。其宗旨就是将任何一种形式的资源抽象成另一种形式的技术都是虚拟化。今天我们讨论一下服务器虚拟化架构的分类。
寄居虚拟化: 虚拟化管理软件作为底层操作系统(Windows或Linux等)上的一个普通应用程序,然后通过其创建相应的虚拟机,共享底层服务器资源。
裸金属虚拟化: Hypervisor是指直接运行于物理硬件之上的虚拟机监控程序。它主要实现两个基本功能:首先是识别、捕获和响应虚拟机所发出的CPU特权指令或保护指令;其次,它负责处理虚拟机队列和调度,并将物理硬件的处理结果返回给相应的虚拟机。
操作系统虚拟化: 没有独立的hypervisor层。相反,主机操作系统本身就负责在多个虚拟服务器之间分配硬件资源,并且让这些服务器彼此独立。一个明显的区别是,如果使用操作系统层虚拟化,所有虚拟服务器必须运行同一操作系统(不过每个实例有各自的应用程序和用户账户),Virtuozzo/OpenVZ/Docker等等。
混合虚拟化: 混合虚拟化模型同寄居虚拟化一样使用主机操作系统,但不是将管理程序放在主机操作系统之上,而是将一个内核级驱动器插入到主机操作系统内核。这个驱动器作为虚拟硬件管理器(VHM)协调虚拟机和主机操作系统之间的硬件访问。可以看到,混合虚拟化模型依赖于内存管理器和现有内核的CPU调度工具。就像裸金属虚拟化和操作系统虚拟化架构,没有冗余的内存管理器和CPU调度工具使这个模式的性能大大提高。
内存虚拟化
在虚拟环境里,虚拟化管理程序就要模拟使得虚拟出来的内存仍符合客户机OS对内存的假定和认识。在虚拟机看来,物理内存要被多个客户OS同时使用;解决物理内存分给多个系统使用,客户机OS内存连续性问题。
要解决以上问题引入了一层新的客户机物理地址空间来让虚拟机OS看到一个虚拟的物理地址,并由虚拟化管理程序负责转化成物理地址给物理处理器执行。即给定一个虚拟机,维护客户机物理地址到宿主机物理地址之间的映射关系;截获虚拟机对客户机物理地址的访问,将其转化为物理地址。
内存全虚拟化: 虚拟化管理程序为每个Guest都维护一个影子页表,影子页表维护虚拟地址(VA)到机器地址(MA)的映射关系。
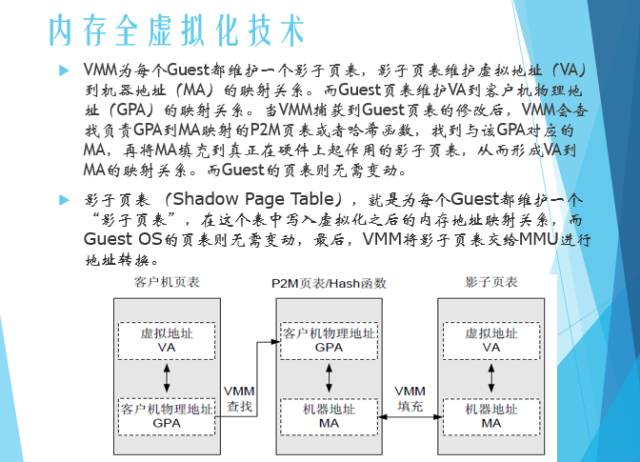
内存半虚拟化技术: 当Guest OS创建一个新的页表时,其会向VMM注册该页表,之后在Guest运行的时候,VMM将不断地管理和维护这个表,使Guest上面的程序能直接访问到合适的地址。

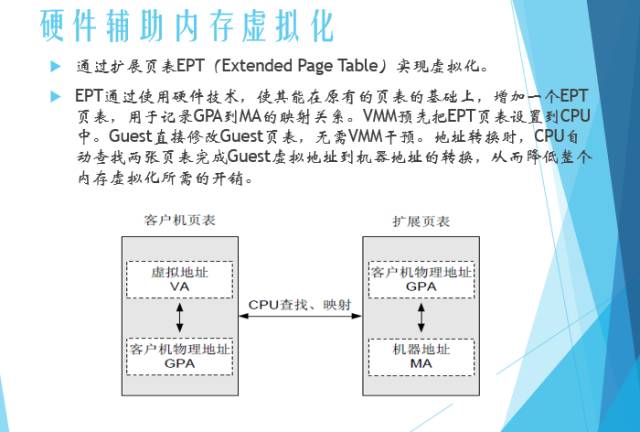
硬件辅助内存虚拟化: 在原有的页表的基础上,增加了一个EPT(扩展页表)页表,通过这个页表能够将Guest的物理地址直接翻译为主机的物理地址。
硬件辅助虚拟化 VT / AMD-v
折腾来折腾去,全都是因为x86架构的CPU天然不支持经典虚拟化模式,软件厂商不得不想出其他各种办法来在x86上实现虚拟化。
如果进一步讲,CPU本身增加对虚拟化的支持,那又会是一番怎样的情况呢?
在软件厂商使出浑身解数来实现x86平台的虚拟化后的不久,各家处理器厂商也看到了虚拟化技术的广阔市场,纷纷推出了硬件层面上的虚拟化支持,正式助推了虚拟化技术的迅猛发展。
这其中为代表的就是Intel的VT系列技术和AMD的AMD-v系列技术。
VT-x技术 为IA 32 处理器增加了VMX root operation 和 VMX non-root operation两种操作模式。VMM自己运行在 VMX root operation 模式,GuestOS运行在VMXnon-root operation 模式。两种操作模式都支持 Ring0-Ring 3特权运行级别,因此 VMM和 Guest OS 都可以自由选择它们所期望的运行级别。允许虚拟机直接执行某些指令,减少VMM负担。VT-x指至强处理器的VT技术,VT-i指安腾处理器的VT技术。
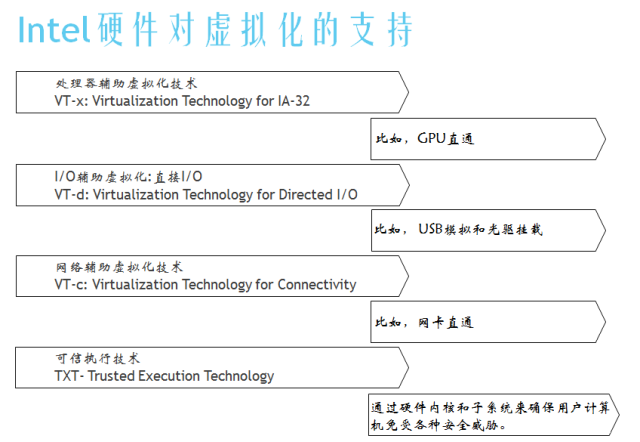
VT-d(VT for Direct I/O)主要在芯片组中实现,允许虚拟机直接访问I/O设备,以减少VMM和CPU的负担。其核心思想就是让虚拟机能直接使用物理设备,但是这会牵涉到I/O地址访问和DMA的问题,而VT-d通过采用DMA重映射和I/O页表来解决这两个问题,从而让虚拟机能直接访问物理设备。
VT-c(VTfor Connectivity)主要在网卡上实现,包括两个核心技术VMDq和VMDc。VMDq通过网卡上的特定硬件将不同虚拟机的数据包预先分类,然后通过VMM分发给各虚拟机,以此减少由VMM进行数据包分类的CPU开销。VMDc允许虚拟机直接访问网卡设备,Single Root I/O Virtualization(SR-IOV)是PCI-SIG规范,可以将一个PCIe设备分配给多个虚拟机来直接访问。
可信执行技术(TXT)通过使用高级的模块芯片,可以有效确保用户计算机免受各种安全威胁。主要是通过硬件内核和子系统来控制被访问的计算机资源。使得计算机病毒、恶意代码、间谍软件和其他安全威胁将不复存在。
KVM-QEMU
有了硬件辅助虚拟化的加持,虚拟化技术开始呈现井喷之势。VirtualBox、Hyper-V、KVM等技术如雨后春笋般接连面世。这其中在云计算领域声名鹊起的当属开源的KVM技术了。
KVM全称for Kernel-based Virtual Machine,意为基于内核的虚拟机。
在虚拟化底层技术上,KVM和VMware后续版本一样,都是基于硬件辅助虚拟化实现。不同的是VMware作为独立的第三方软件可以安装在Linux、Windows、MacOS等多种不同的操作系统之上,而KVM作为一项虚拟化技术已经集成到Linux内核之中,可以认为Linux内核本身就是一个HyperVisor,这也是KVM名字的含义,因此该技术只能在Linux服务器上使用。

KVM技术常常搭配QEMU一起使用,称为KVM-QEMU架构。前面提到,在x86架构CPU的硬件辅助虚拟化技术诞生之前,QEMU就已经采用全套软件模拟的办法来实现虚拟化,只不过这种方案下的执行性能非常低下。
KVM本身基于硬件辅助虚拟化,仅仅实现CPU和内存的虚拟化,但一台计算机不仅仅有CPU和内存,还需要各种各样的I/O设备,不过KVM不负责这些。这个时候,QEMU就和KVM搭上了线,经过改造后的QEMU,负责外部设备的虚拟,KVM负责底层执行引擎和内存的虚拟,两者彼此互补,成为新一代云计算虚拟化方案的宠儿。
GPU及GPU虚拟化技术
GPU直通将GPU设备直通给虚拟机;GPU共享则将GPU设备直通给GPU server虚拟机,GPU server可与GPU client共享其 GPU设备;GPU虚拟化是指将GPU设备可虚拟化为n个vGPU,对应的n个虚拟机可同时直接使用该GPU设备,支持虚拟化的GPU设备可配置为直通或虚拟化类型。
GPU虚拟化通过VGX GPU硬件虚拟化功能,把一个物理GPU设备虚拟为多个虚拟GPU设备供虚拟机使用,每个虚拟机通过绑定的vGPU可以直接访问物理GPU的部分硬件资源,所有vGPU都能够分时共享访问物理GPU的3D图形引擎和视频编解码引擎,并拥有独立的显存。
GPU虚拟化功能支持将一个物理GPU设备可同时供多个虚拟机使用,而GPU直通中一个GPU设备只能给一个虚拟机使用。GPU虚拟化使同时使用同一GPU物理设备的虚拟机间互不影响,系统自动分配物理GPU设备的处理能力给多个虚拟机,而GPU共享是通过GPU server挂载GPU设备,在主机上建立GPU Server与GPU client的高速通讯机制,使得GPU client可以共享GPU server的GPU设备,GPU client是否享有GPU功能完全依赖于GPU server。
I/O虚拟化技术
当虚拟化后,服务器的以太网端口被分割为多个后,网络、存储以及服务器之间的流量可能就不够用了。当遇到I/O瓶颈时,CPU会空闲下来等待数据,计算效率会大大降低。所以虚拟化也必须扩展至I/O系统,在工作负载、存储以及服务器之间动态共享带宽,能够最大化地利用网络接口。
I/O虚拟化的目标是不仅让虚拟机访问到它们所需要的I/O资源,而且要做好它们之间的隔离工作,更重要的是,减轻由于虚拟化所带来的开销。
全虚拟化: 通过模拟I/O设备(磁盘和网卡等)来实现虚拟化。对Guest OS而言,它所能看到就是一组统一的I/O设备,VMM截获Guest OS对I/O设备的访问请求,然后通过软件模拟真实的硬件。这种方式对Guest而言非常透明,无需考虑底层硬件的情况。比如Guest操作的是磁盘类型、物理接口等等。
半虚拟化: 通过前端、后端架构,将Guest的I/O请求通过一个环状队列传递到特权域(也被称为Domain0)。因为这种方式的相关细节较多,所以会在后文进行深入分析。

硬件辅助虚拟化: 最具代表性莫过于Intel的VT-d/VT-c,AMD的IOMMU和PCI-SIG的IOV等。这种技术也需要相应网卡配合实现,目前常见的网卡分为普通网卡、VMDq直通和SR-IOV。
普通网卡采用Domin0网桥队列。
VMDq通过VMM在服务器的物理网卡中为每个虚机分配一个独立的队列,虚机出来的流量可直接经过软件交换机发送到指定队列上,软件交换机无需进行排序和路由操作,Hyper-V就是采用这种模式。
SR-IOV通过创建不同虚拟功能(VF)的方式,给虚拟机使用物理独立网卡,实现虚拟机直接跟硬件网卡通信,不再经过软件交换机,减少了虚拟化管理程序层的地址转换。
容器技术-LXC & Docker
前面谈到的无论是基于翻译和模拟的全虚拟化技术、半虚拟化技术,还是有了CPU硬件加持下的全虚拟化技术,其虚拟化的目标都是一台完整的计算机,拥有底层的物理硬件、操作系统和应用程序执行的完整环境。
为了让虚拟机中的程序实现像在真实物理机器上运行“近似”的效果,背后的HyperVisor做了大量的工作,付出了“沉重”的代价。
虽然HyperVisor做了这么多,但你有没有问过虚拟机中的程序,这是它想要的吗?或许HyperVisor给的太多,而目标程序却说了一句:你其实可以不用这样辛苦。
确实存在这样的情况,虚拟机中的程序说:我只是想要一个单独的执行执行环境,不需要你费那么大劲去虚拟出一个完整的计算机来。
这样做的好处是什么?
虚拟出一台计算机的成本高还是只虚拟出一个隔离的程序运行环境的成本高?答案很明显是前者。一台物理机可能同时虚拟出10台虚拟机就已经开始感到乏力了,但同时虚拟出100个虚拟的执行环境却还是能够从容应对,这对于资源的充分利用可是有巨大的好处。
近几年大火的容器技术正是在这样的指导思想下诞生的。

不同于虚拟化技术要完整虚拟化一台计算机,容器技术更像是操作系统层面的虚拟化,它只需要虚拟出一个操作系统环境。
LXC技术就是这种方案的一个典型代表,全称是LinuX Container,通过Linux内核的Cgroups技术和namespace技术的支撑,隔离操作系统文件、网络等资源,在原生操作系统上隔离出一个单独的空间,将应用程序置于其中运行,这个空间的形态上类似于一个容器将应用程序包含在其中,故取名容器技术。
举个不是太恰当的比喻,一套原来是三居室的房子,被二房东拿来改造成三个一居室的套间,每个一居室套间里面都配备了卫生间和厨房,对于住在里面的人来说就是一套完整的住房。
如今各个大厂火爆的Docker技术底层原理与LXC并不本质区别,甚至在早期Docker就是直接基于LXC的高层次封装。Docker在LXC的基础上更进一步,将执行执行环境中的各个组件和依赖打包封装成独立的对象,更便于移植和部署。

容器技术的好处是轻量,所有隔离空间的程序代码指令不需要翻译转换,就可以直接在CPU上执行,大家底层都是同一个操作系统,通过软件层面上的逻辑隔离形成一个个单独的空间。
容器技术的缺点是安全性不如虚拟化技术高,毕竟软件层面的隔离比起硬件层面的隔离要弱得多。隔离环境系统和外面的主机共用的是同一个操作系统内核,一旦利用内核漏洞发起攻击,程序突破容器限制,实现逃逸,危及宿主计算机,安全也就不复存在。
总结
本文简单介绍了虚拟化技术的基本概念和基本要求。随后引出由于早期的x86架构不支持经典的虚拟化方案,各家软件厂商只能通过软件模拟的形式来实现虚拟化,其代表是早期的VMware WorkStation和Xen。
不过纯粹依靠软件的方式毕竟有性能的瓶颈,好在Intel和AMD及时推出了CPU硬件层面的虚拟化支持,软件厂商迅速跟进适配,极大的改善了虚拟化的性能体验。这一时期的代表有新版本的VMware WorkStation、Hyper-V、KVM等。

近年来,随着云计算和微服务的纵深发展,对虚拟化技术的虚拟粒度逐渐从粗到细。从最早的虚拟化完整的计算机,到后来只需虚拟出一个操作系统,再到后来虚拟出一个微服务需要的环境即可,以Docker为代表的容器技术在这个时期大放异彩

