
- 1FPGA国内”薪“赛道-在医疗领域的应用
- 2git checkout -b <new_branch>:创建并切换到新的分支_checkout -b 新建分支
- 3【云原生】Docker Compose 使用详解_docker-compose 使用
- 4做到这些,你就读懂人生了
- 5AI模型部署:Triton Inference Server部署ChatGLM3-6B实践
- 6必读论文|机器学习必读论文20篇_传统机器学习论文
- 7Spring Cloud/Boot 微服务 优雅停止(非kill -9)_spring cloud 优雅停机
- 8【推荐系统】基于用户的协同过滤算法(UserCF)的python实现_下载movielens数据集,并进行分析,要求如下 (1)下载数据集ml-latest-small.
- 9【卡塔尔世界杯数据可视化与新闻展示】_世界赛足球杯可视化echarts
- 10基础ArkTS组件:图片(HarmonyOS学习第三课【3.2】)_arkts接收其他设备的图像
【RAG 论文】面向知识库检索进行大模型增强的框架 —— KnowledGPT
赞
踩
论文:KnowledGPT: Enhancing Large Language Models with Retrieval and Storage Access on Knowledge Bases
⭐⭐⭐⭐
复旦肖仰华团队工作
论文速读
KnowledGPT 提出了一个通过检索知识库来增强大模型生成的 RAG 框架。
在知识库中,存储着三类形式的知识:
- Entity Description:对于一个 entity 的一段文本描述,类似于 Wikipedia 的内容
- Relational Triples:就是一堆三元组构成的知识图谱,类似于 Wikidata 中存储的 statements
- Entity-Aspect Information:也是一堆关于某个 entity 的三元组,不过这种三元组中,head 是 entity,tail 是一个较长的描述文本,比如
["Socrates", "Military Service", "Socrates served as a Greek hoplite or heavy infantryman..."]
下面是三种知识形式的示例:

为了实现能够从这个知识库中检索知识,该工作预先实现了三个查询函数:
get_entity_info:接受一个 entity 作为输入,返回关于这个 entity 的文本描述find_entity_or_value:接受一个 entity 和一个 relation 作为输入,输出所有相关的 entity 或者 valuefind_relationship:接受两个 entity 作为输入,返回所有他们的 relationship
注意,这里的每个输入中,所有说的输入一个 entity 或 relation,其实是输入一个别名的列表,比如我想输入一个“擅长”这个关系,那我实际输入的是 ["be good at", "be expert in", "specialize in"] 这样的一个别名列表,因为我们并不事先知道“擅长”这个关系在知识库中是怎样被具体表示的。
KnowledGPT 在回答用户问题时,会让 LLM 先判断是否需要借助知识库的辅助,如果需要,那就会让 LLM 使用我们上面事先已经实现的三个查询函数,来生成一段 Python 代码来执行知识库的检索,并根据检索结果的辅助来完成用户问题的答案生成。这就是 KnowledGPT 工作的基本原理。
除此之外,KnowledGPT 还有两个额外的工作:
- 使用 entity linking 技术,实现了从“别名列表” -> entity 的解析,并以此实现了那三个查询函数
- 实现了从用户提供的文档中,自动提取知识来构建包含上文提到的三种知识表达形式的个人私有知识库
一、实现方法
1.1 任务定义
KnowledGPT 从多种知识库(KB)中获取外部知识,作为对 LLM 生成的补充。KnowledGPT 创新点主要在于完成了两个任务:
- 知识检索:根据用户问题,生成用于在知识库中进行检索的 python 代码,并进行检索。
- 知识存储:根据用户提供的文档,自动完成知识抽取,并建立个人私有知识库
1.2 知识检索的实现
我们已经事先实现了对知识库的查询的三个函数:get_entity_info、find_entity_or_value、find_relationship,该工作通过一个 prompt,让 LLM 生成基于这三个函数的 python 代码(就是一个 def search() 函数),这个 python 函数可以被执行用于实现知识的检索。
1)构建 search 函数的 prompt
给定知识库查询函数,让 LLM 生成对应的 python 代码的 prompt,如下:
You are an awesome knowledge graph accessing agent that helps to RETRIEVE related knowledge about user queries via writing python codes to access external knowledge sources. Your python codes should implement a search function using exclusively built-in python functions and the provided functions listed below. ===PROVIDED FUNCTIONS=== 1. get_entity_info: obtain encyclopedic information about an entity from external sources, which is used to answer general queries like "Who is Steve Jobs". Args: "entity_aliases": a list of the entity's aliases, e.g. ['American', 'United States', 'U.S.'] for the entity 'American'. Return: two strings, 'result' and 'message'. 'result' is the encyclopedic information about the entity if retrieved, None otherwise. 'message' states this function call and its result. 2. find_entity_or_value: access knowledge graphs to answer factual queries like "Who is the founder of Microsoft?". Args: "entity_aliases": a list of the entity's aliases, "relation_aliases": a list of the relation's aliases. Return: two variables, 'result' and 'message'. 'result' is a list of entity names or attribute value to this query if retrieved, None otherwise. 'message' is a string states this function call and its result. 3. find_relationship: access knowledge graphs to predict the relationship between two entities, where the input query is like "What's the relationship between Steve Jobs and Apple Inc?". Args: "entity1_aliases": a list of entity1's aliases, "entity2_aliases": a list of entity2's aliases. Return: two strings, 'result' and 'message'. 'result' is the relationship between entity1 and entity2 if retrieved, None otherwise. 'message' states this function call and its result. ===REQUIREMENTS=== 1. [IMPORTANT] Always remember that your task is to retrieve related knowledge instead of answering the queries directly. Never try to directly answer user input in any form. Do not include your answer in your generated 'thought' and 'code'. 2. Exclusively use built-in python functions and the provided functions. 3. To better retrieve the intended knowledge, you should make necessary paraphrase and list several candidate aliases for entities and relations when calling the provided functions, sorted by the frequency of the alias. E.g., "Where is Donald Trump born" should be paraphrased as find_entity_or_value(["Donald Trump", "President Trump"], ["place of birth", "is born in"]). Avoid entity alias that may refer to other entities, such as 'Trump' for 'Donald Trump'. 4. When using find_entity_or_value, make sure the relation is a clear relation. Avoid vague and broad relation aliases like "information". Otherwise, use get_entity_info instead. For example, for the question 'Who is related to the Battle of Waterloo?', you should use get_entity_info(entity_aliases = ['the Battle of Waterloo']) instead of find_entity_or_value(entity_aliases = ['the Battle of Waterloo'], relation_aliases = ['related to']) since 'related to' is too vague to be searched. 5. The input can be in both English and Chinese. If the input language is NOT English, make sure the args of get_entity_info, find_entity_or_value and find_relationship is in the input language. 6. The queries may need multiple or nested searching. Use smart python codes to deal with them. Note that find_entity_or_value will return a list of results. 7. Think step by step. Firstly, you should determine whether the user input is a query that "need knowledge". If no, simply generate "no" and stop. Otherwise, generate "yes", and go through the following steps: First, Come up with a "thought" about how to find the knowledge related to the query step by step. Make sure your "thought" covers all the entities mentioned in the input. Then, implement your "thought" into "code", which is a python function with return. After that, make an "introspection" whether your "code" is problematic, including whether it can solve the query, can be executed, and whether it contradicts the requirements (especially whether it sticks to the RETRIEVE task or mistakenly tries to answer the question). Make sure "thought" and "introspection" are also in the same language as the query. Finally, set "ok" as "yes" if no problem exists, and "no" if your "introspection" shows there is any problem. 8. For every call of get_entity_info, find_entity_or_value and find_relationship, the return 'message' are recorded into a string named 'messages', which is the return value of search(). 9. Add necessary explanation to the 'messages' variable after running certain built-in python codes, such as, messages += f'{top_teacher} is the teacher with most citations'. 10. When the user query contains constraints like "first", "highest" or mathmatical operations like "average", "sum", handle them with built-in functions. 11. Response in json format. ===OUTPUT FORMAT=== { "need_knowledge": "<yes or no. If no, stop generating the following.>" "thought": "<Your thought here. Think how to find the answer to the query step by step. List possible aliases of entities and relations.>", "code": "def search():\\n\\tmessages = ''\\n\\t<Your code here. Implement your thought.>\\n\\treturn messages\\n", "introspection": "<Your introspection here.>", "ok": "<yes or no>" } ===EXAMPLES=== 1. Input: "Who are you?" Output: { "need_knowledge": "no" } 2. Input: “Who proposed the theory of evolution?" Output: { "need_knowledge": "yes", "thought": "The question is asking who proposed the theory of evolution. I need to search for the proponent of the theory of evolution. The possible expressions for the 'proponent' relationship include 'proposed', 'proponent', and 'discovered'.", “code”: “def search():\\n\\tmessages = ‘’\\n\\tproposer, msg = find_entity_or_value(entity_aliases = [‘theory of evolution'], relation_aliases = [‘propose', ‘proponent', ‘discover'])\\n\\tmessages += msg\\n\\treturn messages\\n", "introspection": "The generated code meets the requirements.", "ok": "yes" } 3. Input: "what is one of the stars of 'The Newcomers' known for?" Output:{ "need_knowledge": "yes", "thought": "To answer this question, firstly we need to find the stars of 'The Newcomers'. The relation can be paraphrased as 'star in', 'act in' or 'cast in'. Then, we should select one of them. Finally, we should retrieve its encyclopedic information to know what he or she is known for. We should not treat 'known for' as a relation because its too vague.", "code": "def search():\\n\\tmessages = ''\\n\\tstars, msg = find_entity_or_value(entity_aliases = ['The Newcomers'], relation_aliases = ['star in', 'act in', 'cast in'])\\n\\tmessages += msg\\n\\tstar = random.choice(stars)\\n\\tstar_info, msg = get_entity_info(entity_aliases = [star])\\n\\tmessages += msg\\n\\treturn messages\\n" "introspection": "The generated code is executable and matches user input. It adheres to the requirements. It finishes the retrieve task instead of answering the question directly.", "ok": "yes“ }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
我们拿这段 prompt 来问 ChatGPT 3.5 来试一下:
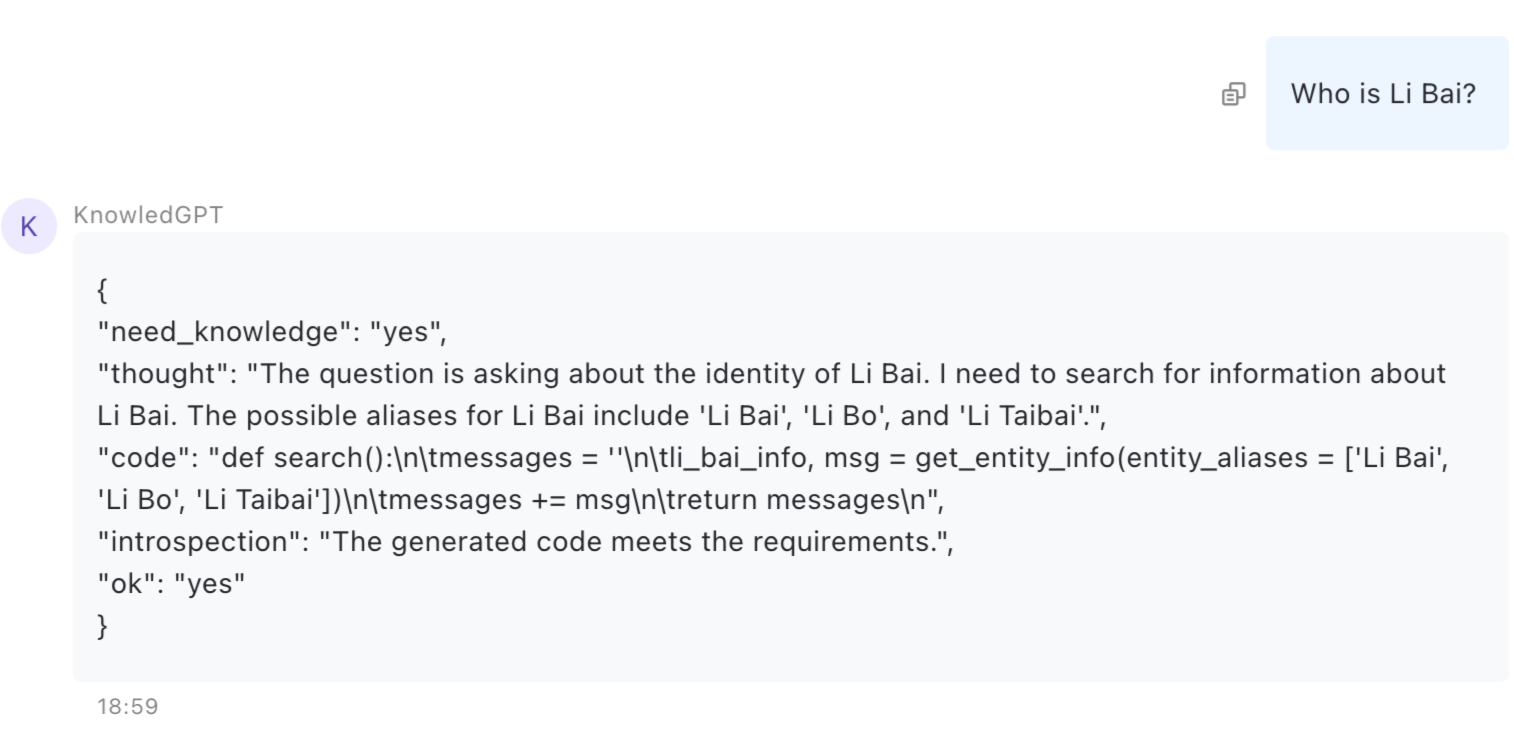
LLM 生成的代码是这样的:
def search():
messages = ''
li_bai_info, msg = get_entity_info(entity_aliases = ['Li Bai', 'Li Bo', 'Li Taibai'])
messages += msg
return messages
- 1
- 2
- 3
- 4
- 5
多试几个问题,可以看到 LLM 生成的代码都很稳定且准确。
2)知识库查询函数的实现
我们事先需要实现几个用于查询知识库的查询函数,论文提到说需要分为两层:
- Unified Level:统一的逻辑层,相当于是一个统一的接口,抽象独立于具体的知识库实现,LLM 生成的代码中就是调用这一层的函数接口。包括前面提及的三个函数,以及一个 entity_link 函数,用来对齐自然语言中提及实体,和知识库中的存储实体。
- KB-specific Level:跟具体的知识库实现有关的用于完成具体知识库交互的层,实现了 _get_entity_info、_entity_linking、_get_entity_triples 三个数据读取函数。
KB-specific Level 的函数实现取决于具体的知识库,这里只介绍 Unified Level 的函数实现:
entity_link:先用 _entity_linking 找到所有的的候选实体,然后用 _get_entity_info 获取候选实体的信息,再传回给 LLM,让 LLM 来判断哪个才是合适的实体(比如 apple 到底是指的水果 apple 还是 apple 公司)。get_entity_info:先使用 entity_linking 确定正确的实体,然后调用 _get_entity_info 获取实体信息。find_entity_value:相对复杂,先用 entity_linking 找到对应的实体,然后用该实体的每个关系(来自 entity 的所有 triples) 去跟 input 里的关系集比较,找到最近(embedding 的相似性)的关系 r ,返回 r 对应的 triples 里面的实体或者值。 原作者给了算法,这里不详细展开。find_relationship:算法跟 find_entity_or_value 类似,只不过它是比较 triples 中实体的相似性,返回对应的关系。
3)生成答案的 prompt
在使用 LLM 生成的 search 函数进行知识检索后,交给 LLM 生成答案的 prompt 如下:
You are an helpful and knowledgable AI assistant. The user has issued a query, and you are provided with some related knowledge. Now, you need to think step by step to answer the user input with the related knowledge. ===REQUIREMENTS=== 1. You should think step by step. First, think carefully whether you can answer this query without the provided knowledge. Second, consider how to use the related knowledge to answer the query. Then, tell me whether this query can be answered with your own knowledge and the provided knowledge. If so, answer this question. However, if the query involves a command or an assumption, you should always regard it as answerable. 2. When you are thinking, you can use and cite the provided knowledge. However, when you are generating the answer, you should pretend that you came up with the knowledge yourself, so you should not say things like "according to the provided knowledge from ..." in the "answer" part. 3. The user query and provided knowledge can be in both Chinese and English. Generate your "thought" and "answer" in the same language as the input. 4. Response in json format, use double quotes. ===INPUT FORMAT=== { "query": "<the user query that you need to answer>", "knowledge": "<the background knowledge that you are provided with>" } ===OUTPUT FORMAT=== { "thought": "<Your thought here. Think step by step as is required.>", "answerable": "<yes or no. Whether you can answer this question with your knowledge and the provided knowledge. If the query involves a command or an assumption, say 'yes'.>", "answer": "<Your answer here, if the query is answerable.>" } ===EXAMPLES=== Input:{ "query": "What is the motto of the school where Xia Mingyou graduated?", "knowledge": "[FROM CNDBPedia][find_entity_or_value(entity_aliases = ['Xia Mingyou'], relation_aliases = ['graduated from', 'school']) -> ] Xi Mingyou, school: Fudan University[find_entity_or_value(entity_aliases = ['Fudan University'], relation_aliases = ['motto']) -> ] Fudan University, motto: Rich in Knowledge and Tenacious of Purpose; Inquiring with Earnestness and Reflecting with Self-practice" } Output:{ "thought": "Based on the background knowledge from CNDBPedia, Xia Mingyou graduated from Fudan University, and the motto of Fudan University is 'Rich in Knowledge and Tenacious of Purpose; Inquiring with Earnestness and Reflecting with Self-practice '. So the answer is ' Rich in Knowledge and Tenacious of Purpose; Inquiring with Earnestness and Reflecting with Self-practice '. This question can be answered based on the provided knowledge.", "answerable": "yes", "answer": " Rich in Knowledge and Tenacious of Purpose; Inquiring with Earnestness and Reflecting with Self-practice " } Input:{ "query": "What is Liang Jiaqing's weapon?", "knowledge": "[FROM CNDBPEDIA] Liang Jiaqing: Liang Jiaqing, also known as Lu Yuan. A member of the Chinese Communist Party, born after the 1960s, with a university education. Specially appointed writer for 'Chinese Writers' magazine and 'Chinese Reportage Literature' magazine. Attributes: Author -> The Loyal Life of a Criminal Police Captain." } Output:{ "thought": "According to the knowledge provided by CNDBPedia, Liang Jiaqing is an author. The provided knowledge does not mention anything about Liang Jiaqing's weapon, and authors generally do not have weapons. The question cannot be answered based on the provided knowledge or my knowledge.", "answerable": "no" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
4)实体链接的实现
之前提到,除了需要事先实现三个查询函数,还需要实现一个 entity_link 函数,也就是需要根据给定的“别名列表”找到知识图谱中对应的 entity。
原论文拿苹果水果和苹果公司来举例说明为什么需要做实体链接。
在本论文中,实体链接的实现方式是:首先根据别名列表从 KG 中选出候选实体,然后再从知识库中找到这些实体的文本描述,然后把这些信息都交给 LLM,由 LLM 从这些候选实体中决定出哪个是最终的答案。
这里有一个注意点:我们不能简单地从候选实体中选出得分排名最靠前的实体作为答案。因为从外部知识库的实体链接和搜索 API 中返回的原始候选实体并不是有序的,甚至可能不包括正确的实体。
1.3 个人知识库的构建
本论文还尝试使用构建个人知识库,也就是根据用户指定的文档,从中提取出符合本知识库规定的知识表示形式的知识,从而形成个人知识库。
从文档中做知识抽取的方法本质上就是通过 prompt 让 LLM 来完成抽取。
二、实验设置及效果分析
2.1 实验的设置
本文主要选择了一下知识库:
- 维基百科和维基数据:维基百科提供关于世界实体的丰富百科信息,由全球志愿者维护。Wikidata是维基百科的知识图谱补充,它以再逻辑三元组的形式结构和组织这些百科知识。
- CN-DBPedia:一个大规模的、不断更新的中文知识库,其来源包括中文维基百科和百度百科。CN-DBPedia既包含类似维基百科的实体描述,也包含类似维基数据的关系三元组。
- 个性化知识库:被设计为LLM的可写符号存储器。它存储从用户输入中提取的最新知识。
- NLPCC2016:KBQA知识库被广泛用于评估基于知识的问题解答任务模型。它包含4300万个三元组。
在实际场景中,对于英文查询,使用维基百科和维基数据以及个性化知识库。对于中文查询,使用 CN-DBPedia 和个性化知识库。
在语言模型选用上,默认使用 GPT-4,输入为提示指令、要求和上下文示例,并要求 LLM 以 json 格式输出。对于句子嵌入,采用 text-embedding-ada-002 模型。
2.2 Experiment 1:Queries on Popular KBs
本实验是从 CN-DBPedia 中构建了 11 个问题,涉及到 single-hop、multi-hop 等多种关系查询,实验结果如下:

可以看到:
- GPT-4 和 ChatGPT 本身精通于处理有关知名实体的查询,但它们也经常对不知名的实体产生幻觉。
- KnowledGPT 与 GPT-4 能出色地完成代码生成和实体链接等任务,并最终以正确的知识回答用户的查询,与 GPT-4 的虚无响应相比有了显著的进步。
- 对于 ChatGPT 而言,中间步骤的成功率仍有待提高,这制约了 KnowledGPT 的整体效率。在代码生成步骤中,ChatGPT有时会生成较差的关系别名,如谁是父亲,尤其是对于多样化或复杂的查询。这一比较表明,GPT-4在复杂结构理解、任务分解和代码生成等方面明显优于ChatGPT。Llama-2-Chat-13B等较小的开源LLM,但很难直接提供准确的答案,也无法生成格式良好的代码,也无法按照KnowledGPT框架的要求以JSON格式做出响应。
2.3 Experiment 2:Knowledge-Based Question Answering
使用 NLPCC-100 和 NLPCC-MH-59 作为数据集来测试。其中,NLPCC-100 由来自 NLPCC2016 KBQA 数据集测试集的 100 个样本组成,NLPCC-MH-59 由来自 NLPCC-MH 测试集的 59 个样本组成,NLPCC-MH 是一个多跳 KBQA 数据集。
对于 NLPCC-100 和 NLPCC-MH-59,在本实验中使用的都是完整的 NLPCC2016 KBQA 知识库。
针对该数据集和知识库,对 KnowledGPT 做了几处修改,具体可参考原论文。
在基线对比上,将 KnowledGPT 与以下基线方法进行了比较:
- 通过嵌入相似性检索。每个三元组都被视为一个文档,并使用 CoSENT 模型进行嵌入表示。每次搜索都会根据嵌入相似性检索到一份文档。对于多跳问题,第一次检索的结果会添加到查询中,以方便第二次检索。
- 通过 BM25 检索。对于每个实体,将其所有三元组作为一个文档。对于每个搜索查询,使用BM25算法检索出最相关的文档,并去除停用词。如果检索到的文档包含相应的三元组,认为检索成功。对于多跳查询,根据关系间的jaccard相似性从初始检索的文档中挑选一个三元组,并将该三元组整合到后续检索的查询中。
- SPE。利用嵌入相似性从简单问题中提取主谓对。
在指标上,采用平均F1值,在该数据集中,每个样本只有一个答案和一个预测,因此平均F1实际上等同于准确率:

从中可以得出如下结论:
- 首先,对于单跳查询,KnowledGPT通过BM25和嵌入相似性显著优于其他三元方法,这表明对于与知识库中的知识相关的问题,与文档语料库相比,从符号知识库中进行检索更有效。
- 其次,在NLPCC-2016 KBQA数据集的完整训练集上训练的zeroshot检索上,KnowledGPT优于SPE方法(0.92vs0.85),这显示了KnowledGPT具有较好的zero-shot检索性能。
- 最后,在多跳查询上,KnowledGPT也取得了优异的性能,基于BM25和嵌入相似性的检索方法性能则明显下降。
2.4 KB as Memory
KnowledGPT 的任务是从所提供的文档中提取知识来构建 PKB(个人知识库),并研究 KnowledGPT 是否能用 PKB 正确回答相应的问题。
使用 HotpotQA 数据集来进行实验,可以发现,KnowledGPT 可以几乎正确回答所有问题,其中有几个错误回答是因为检索知识或实体链接步骤发生了错误。这个实验表明,使用 PKB 来作为 LLM 的符合化 memory 是很有用途的。
之后,论文又进一步研究了 KnowledGPT 对来自 HotpotQA 的 100 篇文档的知识提取覆盖率,为了进行量化,采用了单词召回率作为指标:
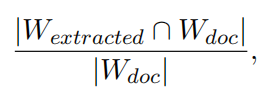
实验结果如下:

从中,我们可以看出如下几点:
- 如果我们限定知识的表示形式仅为“三元组”时,知识提取的覆盖率只有 0.53,这表明只有有限的一部分知识可以表示为三元组,仅使用三元组的 PKB 无法充分涵盖真实用户提供的知识。
- 使用额外的知识表示法,即实体描述和实体方面信息时,知识提取覆盖率有了显著提高,这表明加入实体描述和实体方面信息后,KnowledGPT 能够将更广泛的知识填充到 PKB 中。
- ChatGPT 和 GPT-4 的知识提取能力相近。只有在包含实体方面信息时,GPT-4 的表现才优于 ChatGPT,这可能是由于 GPT-4 增强了遵循复杂指令的能力。
总结
本论文提出的 KnowledGPT 还存在以下缺陷:
- 将 LLM 检索 KB 的过程受限为一轮检索,也许让 LLM 自由多轮探索 KB 的效果会更好;
- LLM 事先对 KB 的数据内容并不了解,这导致了 LLM 生成的知识检索可能无法于 KB 匹配;
- 受限于 GPT 4 的费用,本工作并未大量完全地测试,这有待进一步补充
- “LLM 究竟什么时候需要外部知识源的辅助”仍然是一个值得探索的问题,本工作只是规定让 LLM 取决定是否需要外部知识源。
总结来说,KnowledGPT 提出了一个将 LLM 与外部知识库相整合的综合框架,以方便 LLM 在知识库中进行检索和存储:
- 在检索方面,KnowledGPT采用"思维程序"提示,通过代码生成和执行来检索知识。
- 在存储方面,KnowledGPT从用户提供的文本中提取各种形式的知识,并将提取的知识填充到个性化知识库中。
KnowledGPT 解决了将 LLM 与知识库集成过程中固有的几个难题,包括复杂的问题解答、实体链接中的歧义以及有限的知识表示形式。是一个值得学习的论文。
参考文章:

