
热门标签
热门文章
- 1学习腾讯的NLP文本分类_nlp的roi
- 2【LeetCode之MySQL】175. Combine Two Tables_mysql 175. combine two tables
- 3JMeter 接口自动化测试的最佳实践
- 4Python酷库之旅-比翼双飞情侣库(04)
- 5二、Crazepony1无人机源码分析-(5)50Hz循环_无人机源代码
- 6android的危险权限(dangerous)授权_android 危险权限
- 7智能算法挑战赛小学组全年级——模拟考试_全国青少年信息素养大赛智能算法应用挑战赛初赛试题
- 8如何开发一个车牌识别,车牌识别系统,车辆识别系统毕业设计毕设作品_车牌识别系统开发
- 9搭建Hadoop报错汇总(那些曾经踩过的坑)_hdfs namenode -format bash: hdfs: command not foun
- 10Image recognition&NLP_图像分割置信度
当前位置: article > 正文
大模型训练营Day3 基于 InternLM 和 LangChain 搭建你的知识库_langchain 中模型训练
作者:笔触狂放9 | 2024-07-01 13:35:57
赞
踩
langchain 中模型训练

本次的授课人是一个提示词开发项目的负责人。下面一起进入本期课程吧》
本次课程内容主要如下:

开篇交代了大模型的局限性,然后引出主题:
简单总结,大模型是根据数据集训练,很难使用具有实时性的数据进行重新训练(因为训练成本需要海量资源)。并且,通用模型的专业场景应用很差。而且很难专门定制特定的大模型。

大模型的开发范式呢,主要有以下两种模式:
建立知识库和微调,知识库是传统AI专家系统中就有的概念;微调呢是冻结一定层的参数然后去训练改变其产生分类的少数几层的参数。二种方法都能减少训练成本,但是有一定的差别。
前者不需要算力,可以实时加入新知识,但是基座模型的上限极大程度决定其模型的上限。;而后者无法实时更新,但是由于其是一个改变少数层的新的大模型,仍然具有大模型的广阔知识的优势

RAG建立数据库的具体思路如下:
先将用户输入向量化(用向量表示),然后与数据库中的知识匹配,最后变成提示词传递给大模型。

而LangChain这个开源框架能够比较好地用于RAG这个方面的构建,为MIT一个创业者的发起,目前为大模型领域比较火的框架。
其核心组件为链,而最有代表性的是检索问答链,也是本节课所用。

以下是使用之构建应用的框图和工作步骤:
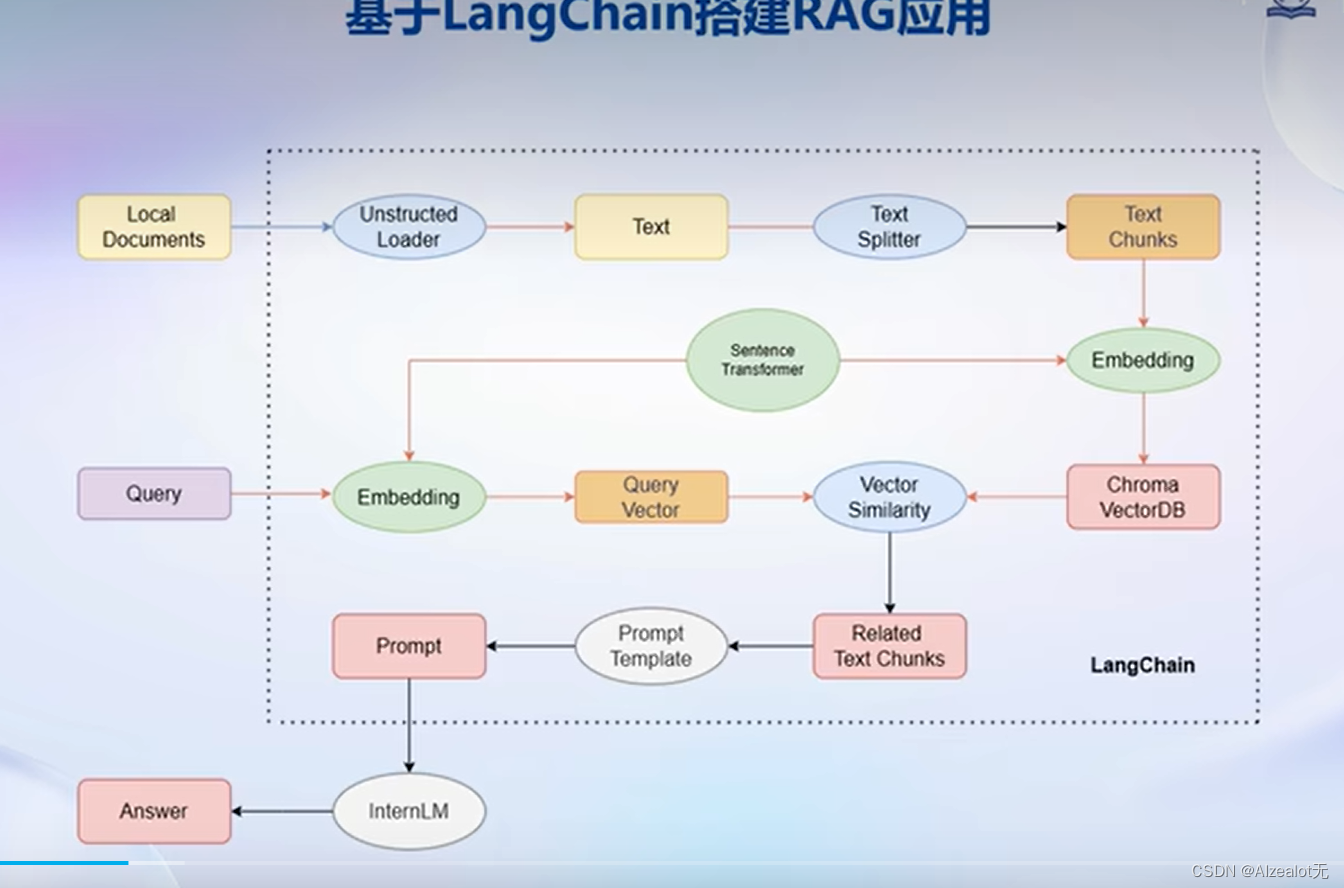
构建向量数据库主要步骤如下:

下面开始介绍知识库助手的搭建:

即调用这个组件,能够实现全部流程:

RAG有以下局限性和可能的优化方案:

以下开始部署Web Demo:
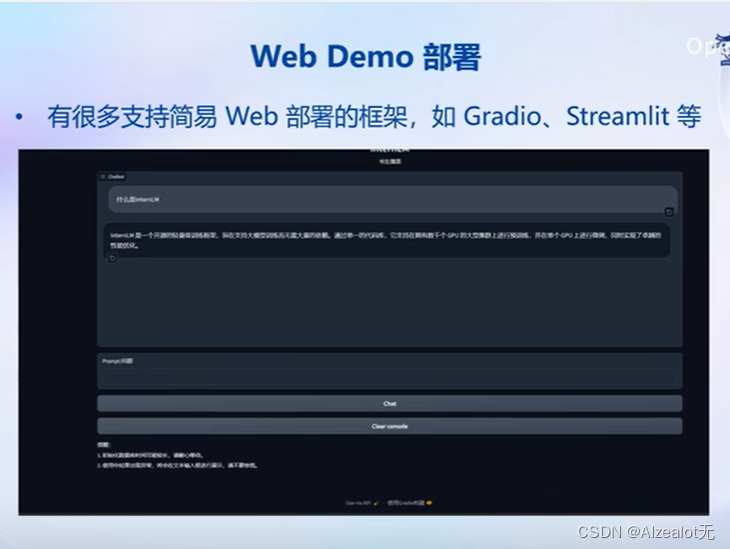
前两次作业的运行自动启动的是streamlit,本次基于Gradio。
按照文档一步步执行,即可。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/776573
推荐阅读
相关标签

