
- 1【设计模式学习笔记】模板模式、命令模式、责任链模式、策略模式案例详解(C++实现)_开发 模板 责任链
- 2mysql双层not exists查询执行流程_mysql not exist
- 3net472无法建立到信任_信任危机:一旦感情破裂,6种修复信任的方法
- 4(leetcode学习)236. 二叉树的最近公共祖先
- 5蓝桥杯——3.矩阵按键仿真实验_矩阵键盘蓝桥杯
- 6MAC 电脑里面的“其他”文件是什么占用了_archives文件夹可以删除吗
- 7使用idea的git将多次commit合并为一条_idea squash commit
- 8无线通信设计秘密一:跳频技术_跳频通信
- 9【微信小程序】自己的小程序跳转到京东小程序商品详情页_京东小程序怎么跳转京东app
- 1020220413力扣每日一题_力扣每日一题在哪里
Calibrating Factual Knowledge in Pretrained Language Models 事实校准 emnlp2022
赞
踩
Abstract
背景:预训练模型可以存储事实知识,但存储在预训练模型中的数据不总是正确的。
目标:在不从头开始进行再训练的情况下,校准plm中的事实知识
本文:提出了一种简单而轻量级的方法来实现这一目标
方法:首先检测plm是否可以通过正确事实和虚假事实之间的对比分数来学习正确的事实。如果没有,我们使用轻量级的方法来添加和调整新的参数以适应特定的事实文本。
实验分析:对知识探测任务的实验表明了校准的有效性和有效性。此外,通过闭书问答,我们发现校准后的PLM经过微调后具有知识泛化能力。
除了校准性能外,我们还进一步研究和可视化了知识校准机制。这些代码和数据可以在https://github.com/dqxiu/CaliNet上获得。
introduction
为了处理虚假的事实,以前的工作集中于为特定的下游任务补充或修改知识。Yao等人(2022)提出在微调过程中检索外部知识。Cao等人(2021b)在微调后修改特定的知识。然而,这些方法并不适用于多个任务。
在本文中,我们探索了一种任务无偏( task-agnostic)的方法来直接校准plm中的一般事实知识,而无需从头开始进行再训练。我们的目的是纠正plm中的虚假事实。由于每个事实都有多个表面,我们也期望校准后的知识应该可以推广到不同的文本表面。图1说明了校准的过程。
首先,我们使用对比知识评估(CKA)方法来检测plm中的错误知识(如图2所示)。由于plm做出黑盒决策,我们通过plm的预测来评估其简化。CKA背后的关键动机是一个简单的论点,即当且仅当模型分配正确的事实比可能的负面事实得分更高时,PLM才会正确地学习一个事实。对于这些错误的知识,我们建议通过告诉plm什么是正确的事实来校准它们。

我们的方法并不改变PLM的原始参数,二是通过微调新的参数,校准新的知识,在校准的过程中,PLM原始参数保持不变。
Dai等人(2022)指出PLMs中的前馈网络(FFNs)存储事实知识,我们在PLM中扩展了一个特定的FFN,校准FFN由几个校准内存槽组成。如图3所示,在不修改原始PLM中的参数的情况下,我们的方法通过改写表达相应正确事实的自然句子来校准错误的知识。
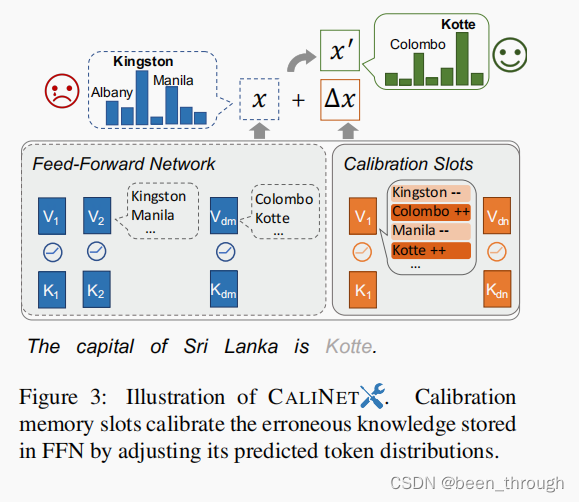
FFN是原PLM中就有的部分,是在FFN中又加了一个校准模块。
对探测任务和问题回答任务的大量实验表明,CaLiNet能有效地校准plm中的错误事实,并表现出显著的泛化能力。我们还分析了校准存储器插槽和校准机制,以更好地理解所提出的方法是如何工作的。此外,我们还解释了通过追踪模型预测的演变,如何以及在哪里来校准PLM中的事实知识。
总结:
- 通过a Contrastive Knowledge Assessment评估存储在PLM中的知识。
- 我们提出用CaLiNet计算来校准plm中不正确的事实知识。该方法在不影响参数的情况下,可以纠正错误知识并广泛推广。
- 我们还研究了CaLiNet是如何通过 calibration memory slots.工作的。
Contrastive Knowledge Assessment
校准的第一步是检测plm学习到哪些错误的事实。我们提出了Contrastive Knowledge Assessment(CKA),并实施它来识别plm中的错误知识。CKA是一个基于对比的度量标准。
传统的评价方法通常采用基于排名的度量方法。它根据
真实实体与其他实体的排名高度来评估一个PLM。
然而,它也带有两个主要的问题。一个是无穷无尽的答案。
基于排名的方法在多个验证预测上评估失败。
top-1 only只取排名最高的作为预测的结果,但真正的预测可能包含多个正确的结果。 独立地评估每个尾实体
另一个是频率偏差的问题。该排名特别容易受到训练前语料库中的标记频率的影响。
当尾部实体o经常与头部实体o共存时,即使它们对特定事实没有任何表达,模型在评估该事实时仍然会分配一个高等级。
此外,s在CKA分数的分子和分母中都有出现了,这中和了频率偏差的影响
为了解决这些限制问题,我们提出使用CKA来检测存储在plm中的虚假事实知识。其核心思想是以对比的方式评估积极正确事实和消极错误事实下的模型预测。对于每个事实,我们采样一个提示符,以将其转换为自然文本。
抽取三元组 <s,r,o>,s-subject entity;o-object entity.r-correct relation;r’-incorrect realtion。
r作为正向提示,r’作为反向提示。
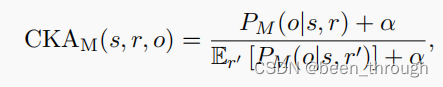
E是期望?CKA越大越好,通常设置一个小于1的threshold
Knowledge Calibration
CKA方法输出PLM学习到的错误事实。本节描述了我们如何校准它们。
假设我们在一个PLM中检测到了k个假事实。我们的目标是将它们校准为正确的任务,这样下游任务就不会从PLM中获取错误的事实知识。先前的工作(Geva等人,2021年;Dai等人,2022年)指出,transformer中的FFN可以被视为存储事实知识的关键价值记忆。受此启发,我们设计了一个类似FFN的底座,并利用FFN的特性直接校准FFN中的事实知识。同样重要的是要注意,所提出的方法可以用于参数的任何部分。在这项工作中,我们将该方法应用到FFN上,因为FFN被证明在存储事实时承担了更多的责任。
在本节中,我们将CaLiNet日历的体系结构,校准数据的构建,以及如何在一个预先训练好的模型上执行校准。
调整预先训练的transformer中FFN的输出
原本的前馈网络

H是attention layer的参数,K,V是两个linear的参数
改进:


