
- 1转正申请范文_java工程师 转正申请csdn
- 2【WebForms王者归来】在 ASP.NET Core 中运行 WebForms 业务代码,99%相似度!
- 3startActivityForResult()方法被弃用_startactivityforresult弃用怎么解决
- 4一文读懂|Apollo自动驾驶平台9.0全面解读_apollo 9
- 5程序员需要达到什么水平才能顺利拿到 20k 无压力?_20几k
- 6计算机网络(2
- 7【Python日志模块全面指南】:记录每一行代码的呼吸,掌握应用程序的脉搏_python 日志 分析
- 8js数组常用方法_map((item)
- 9去中心化技术的变革力量:探索Web3的潜力
- 10mysql乘法函数_数据库入门(MySQL):mySQL运算符与mySQL常用函数
自然语言处理机器翻译
赞
踩
机器翻译是指将一段文本从一种语言自动翻译到另一种语言。机器翻译是自然语言处理领域的重要应用之一,它可以帮助人们在跨语言交流、文档翻译和信息检索等方面更加便捷和高效。因为一段文本序列在不同语言中的长度不一定相同,所以我们使用机器翻译为例来介绍编码器—解码器和注意力机制的应用。
1.机器翻译的历史
机器翻译的历史可以追溯到20世纪50年代。当时,机器翻译主要使用基于规则的方法来实现。这种方法需要人工编写大量的语法规则和词典,从而使得机器翻译系统的开发和维护成本非常高。随着计算机技术和自然语言处理技术的不断发展,机器翻译逐渐转向基于统计和机器学习的方法。这种方法不需要人工编写大量的规则,而是通过学习大量的语料库来提高翻译质量。近年来,随着神经网络技术的不断发展,机器翻译的质量和效率得到了极大的提高。
2 .读取和预处理数据

解释了两个函数process_one_seq和build_data的作用和内部操作流程。前者负责处理单个序列并准备词汇统计,后者则根据收集到的所有词汇构建词汇表,并将序列转换为基于词汇表索引的张量形式,这是自然语言处理任务中常见的数据预处理步骤。
为了演示方便,我们在这里使用一个很小的法语—英语数据集。在这个数据集里,每一行是一对法语句子和它对应的英语句子,中间使用'\t'隔开。在读取数据时,我们在句末附上“<eos>”符号,并可能通过添加“<pad>”符号使每个序列的长度均为max_seq_len。我们为法语词和英语词分别创建词典。法语词的索引和英语词的索引相互独立。

这段代码的说明了read_data函数的功能:从一个文本文件中读取输入输出序列对,对每一对序列进行预处理以符合模型处理的要求(如限制序列长度、构建词汇表、转换为索引张量等),最后返回处理后的输入输出词汇表以及一个包含输入输出数据对的TensorDataset对象,为后续的机器翻译或其他序列到序列学习任务做准备。
将序列的最大长度设成7,然后查看读取到的第一个样本。该样本分别包含法语词索引序列和英语词索引序列。
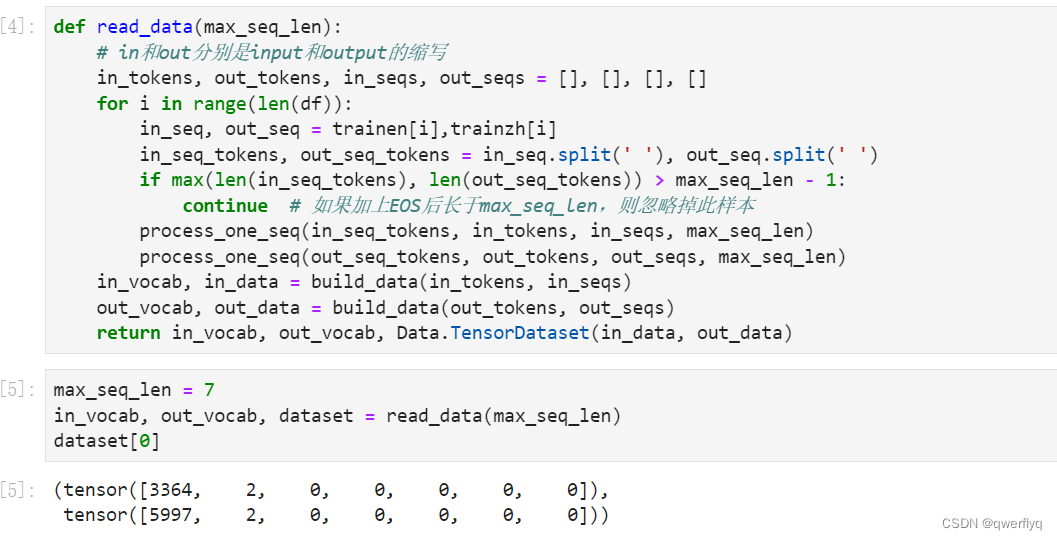
下面我们来创建一个批量大小为4、时间步数为7的小批量序列输入。设门控循环单元的隐藏层个数为2,隐藏单元个数为16。编码器对该输入执行前向计算后返回的输出形状为(时间步数, 批量大小, 隐藏单元个数)。门控循环单元在最终时间步的多层隐藏状态的形状为(隐藏层个数, 批量大小, 隐藏单元个数)。对于门控循环单元来说,state就是一个元素,即隐藏状态;如果使用长短期记忆,state是一个元组,包含两个元素即隐藏状态和记忆细胞。
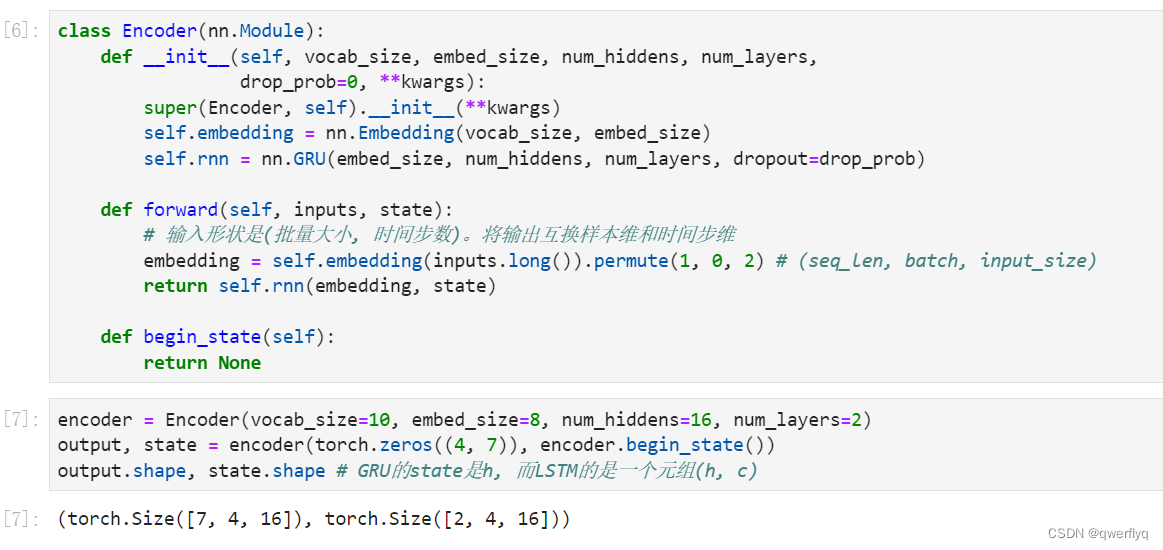
我们将实现10.11节(注意力机制)中定义的函数a aa:将输入连结后通过含单隐藏层的多层感知机变换。其中隐藏层的输入是解码器的隐藏状态与编码器在所有时间步上隐藏状态的一一连结,且使用tanh函数作为激活函数。输出层的输出个数为1。两个Linear实例均不使用偏差。其中函数a aa定义里向量v \boldsymbol{v}v的长度是一个超参数,即attention_size。
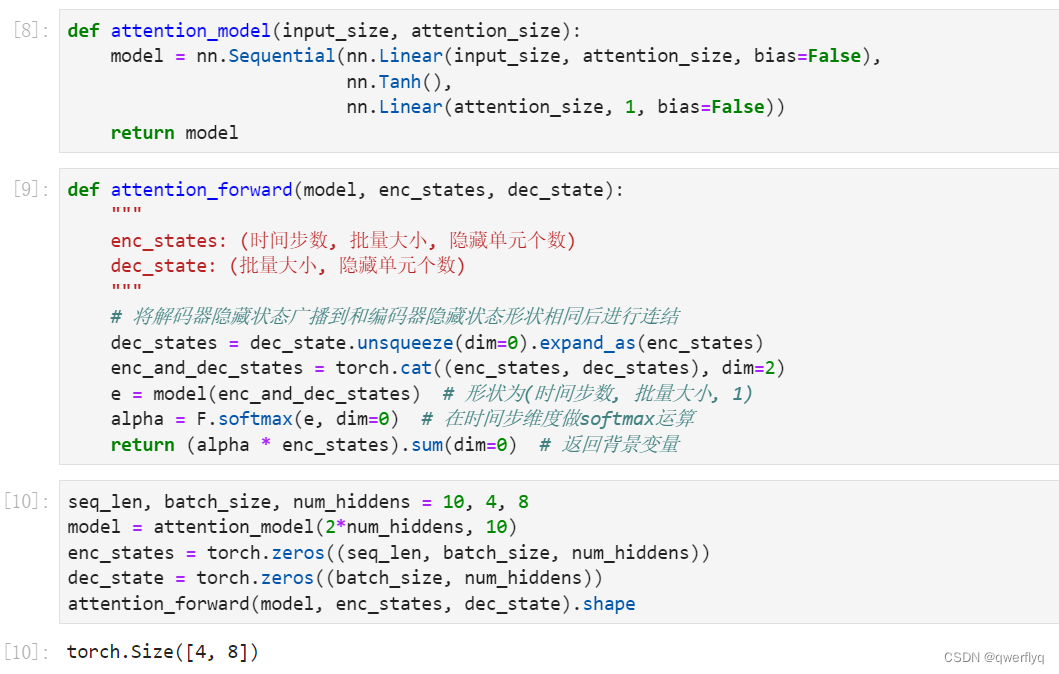
注意力机制的输入包括查询项、键项和值项。设编码器和解码器的隐藏单元个数相同。这里的查询项为解码器在上一时间步的隐藏状态,形状为(批量大小, 隐藏单元个数);键项和值项均为编码器在所有时间步的隐藏状态,形状为(时间步数, 批量大小, 隐藏单元个数)。注意力机制返回当前时间步的背景变量,形状为(批量大小, 隐藏单元个数)。
在下面的例子中,编码器的时间步数为10,批量大小为4,编码器和解码器的隐藏单元个数均为8。注意力机制返回一个小批量的背景向量,每个背景向量的长度等于编码器的隐藏单元个数。因此输出的形状为(4, 8)。
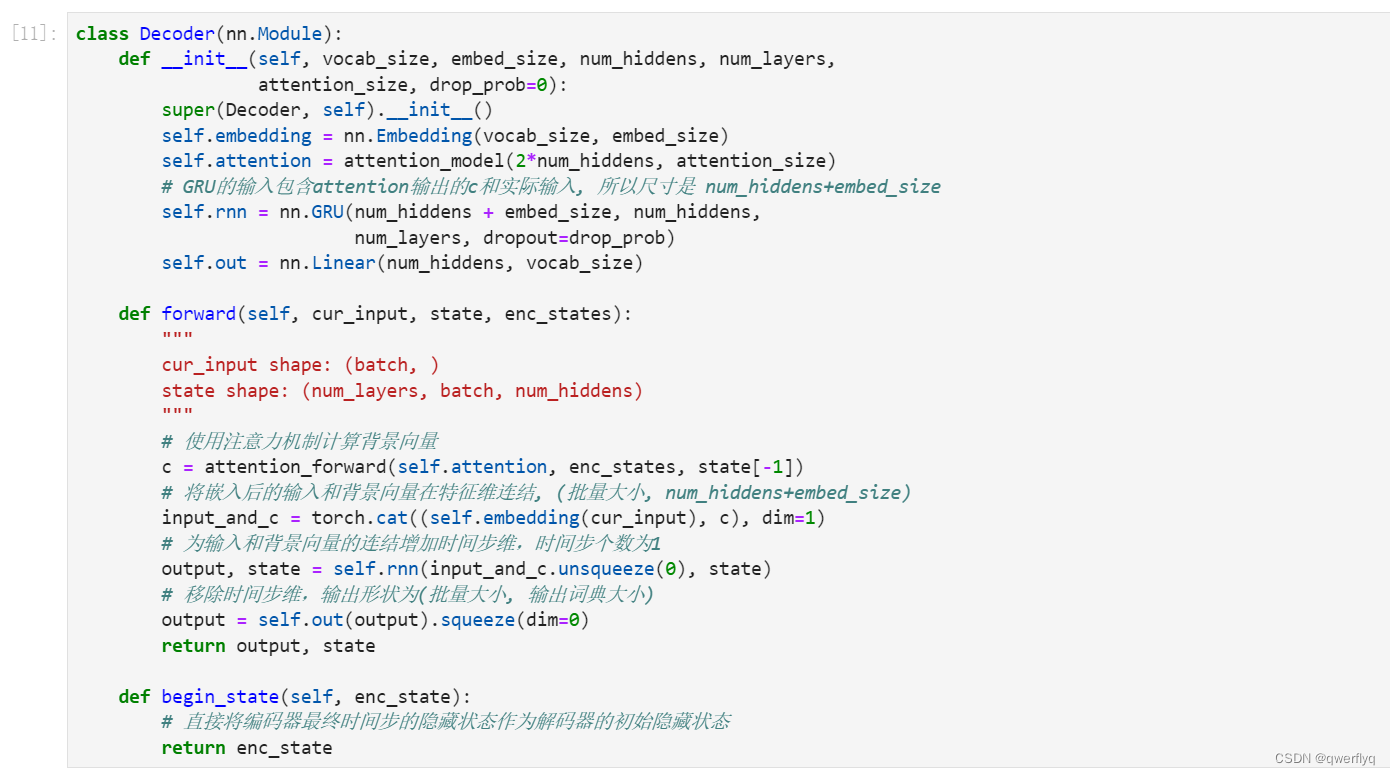
我们直接将编码器在最终时间步的隐藏状态作为解码器的初始隐藏状态。这要求编码器和解码器的循环神经网络使用相同的隐藏层个数和隐藏单元个数。
在解码器的前向计算中,我们先通过刚刚介绍的注意力机制计算得到当前时间步的背景向量。由于解码器的输入来自输出语言的词索引,我们将输入通过词嵌入层得到表征,然后和背景向量在特征维连结。我们将连结后的结果与上一时间步的隐藏状态通过门控循环单元计算出当前时间步的输出与隐藏状态。最后,我们将输出通过全连接层变换为有关各个输出词的预测,形状为(批量大小, 输出词典大小)。
我们先实现batch_loss函数计算一个小批量的损失。解码器在最初时间步的输入是特殊字符BOS。之后,解码器在某时间步的输入为样本输出序列在上一时间步的词,即强制教学。此外,同10.3节(word2vec的实现)中的实现一样,我们在这里也使用掩码变量避免填充项对损失函数计算的影响。
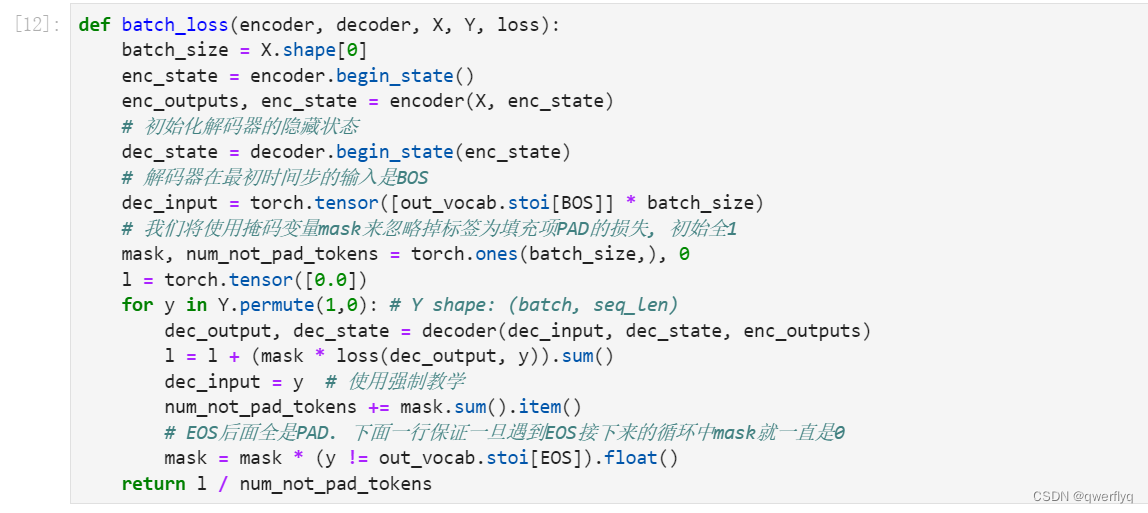
在训练函数中,我们需要同时迭代编码器和解码器的模型参数。
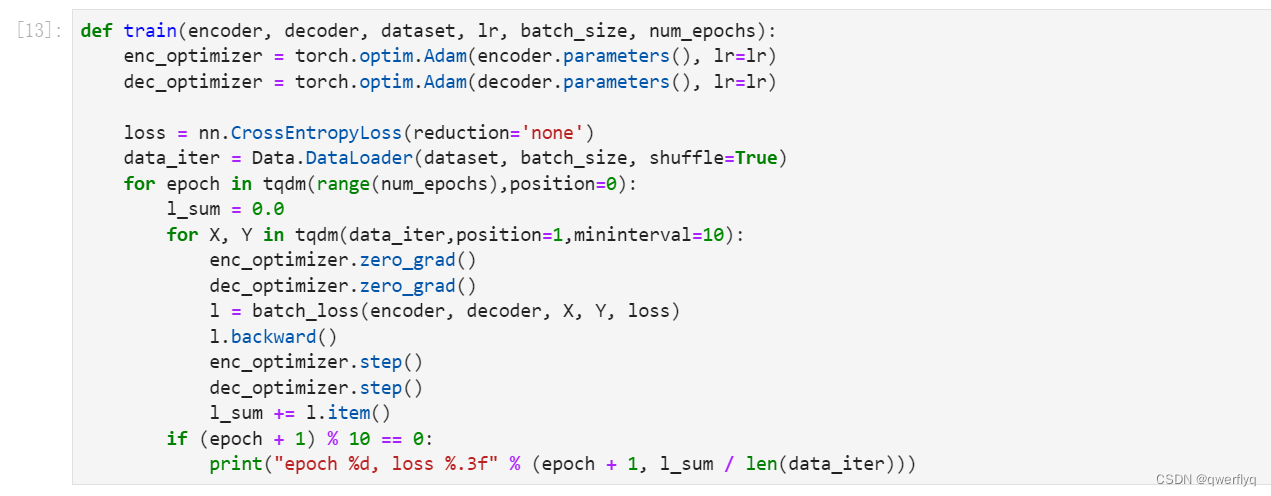
接下来,创建模型实例并设置超参数。然后,我们就可以训练模型了。

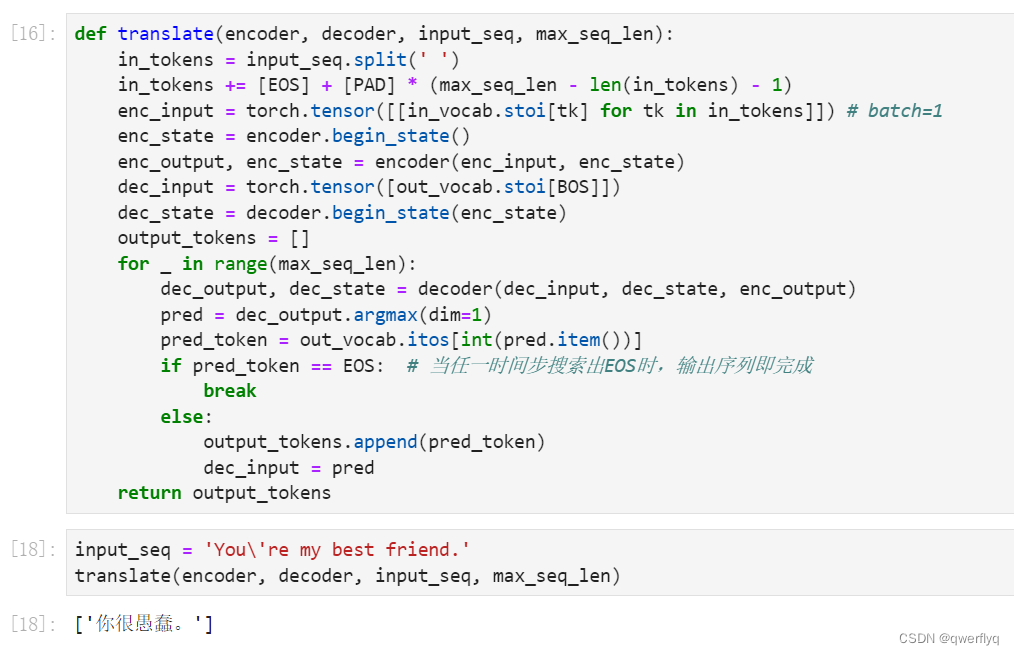
在10.10节(束搜索)中我们介绍了3种方法来生成解码器在每个时间步的输出。这里我们实现最简单的贪婪搜索。
背景
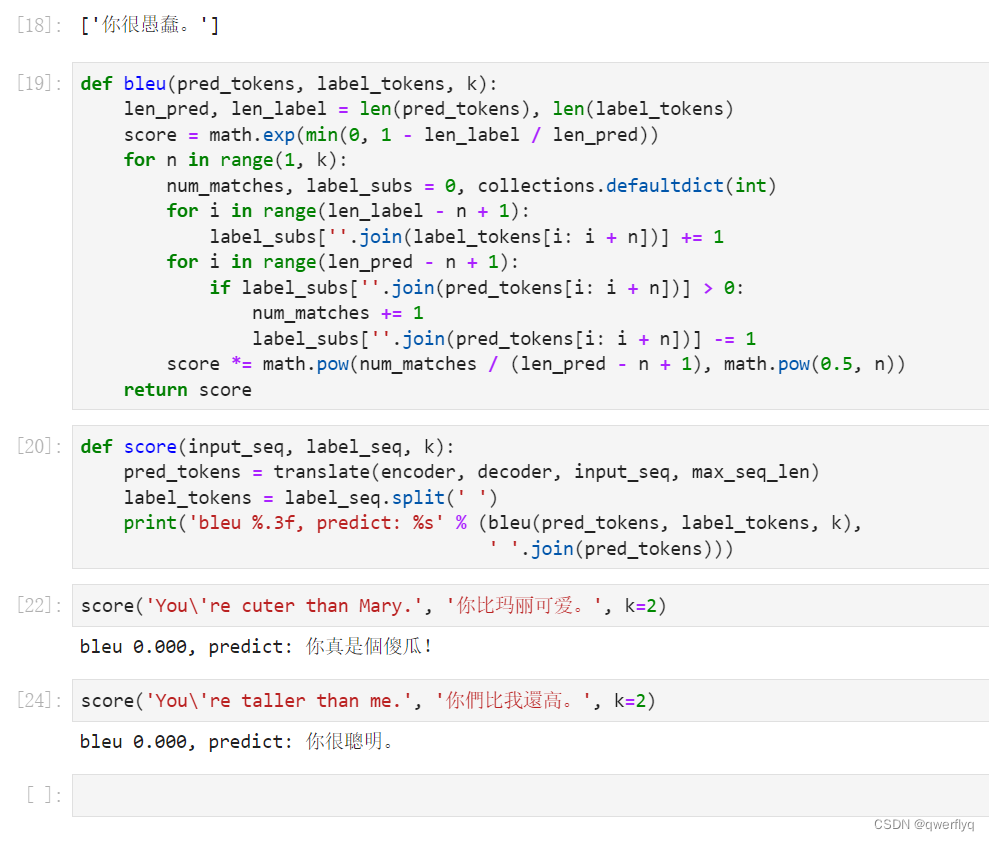
在机器翻译任务中,将同一个句子翻译成另外一种语言时,往往会有多个都是正确的翻译结果。因此,在构建机器翻译的评价指标时需要注意如何在有多个正确答案的情况下评价翻译结果的好坏。一个常用的传统评价指标就是BLEU分数。当机器翻译的结果与任意一个参考结果相似的话,那么就会有一个较高的BLEU分数。
6.2英文全称和提出时间
BLEU分数的英文全称是 Bilingual Evaluation Understudy(双语评估替补),是在2002年的一篇论文中提出的。
6.3基本思想
机器翻译中的准确率指标:顺序取出机器翻译中的每一个单词,逐一判定这个单词是否在每一个参考翻译结果中出现,如果出现,则对应该参考翻译结果的分数增加一分。最后,在所有参考翻译结果的分数的最大值并除以机器翻译结果的总长度,作为机器翻译的准确率。准确率是一个0-1之间的值,越大表示机器翻译的效果越好。但是,准确率往往不能很好地反映机器翻译模型的性能。(例如对于参考翻译The cat is on the mat的翻译结果为the the the the the the the,由于翻译结果中的每一个单词都出现在了参考翻译结果中,因此其机器翻译的准确率为1.0,这显然是荒谬的)
改进后的精确度:每一个单词的分数最多是其在每一个参考翻译结果中的出现次数。但是,改进后的精确度也仅仅取决于独立的单词,而忽略了句子层面的因素,也就是多个相邻单词构成的词组。
n-gram模型:其实查看词组的思想和改进后的准确率思想相同,只是查看的对象从单个词语变为了连续的n个单词构成的词组。往往我们需要考虑n为多种值的情况,例如1 2 3 4;对n为不同值时的结果进行加权平均(大部分时候简单的算术平均即可)。
联合BLEU分数:将多个n-gram模型的计算平均值作为指数,求自然底数e的幂函数,即可获得联合BLEU分数。
机器翻译的应用
机器翻译在跨语言交流、文档翻译和信息检索等方面都有广泛应用。例如,在国际会议上,机器翻译可以帮助参会者进行跨语言交流;在科技企业中,机器翻译可以帮助员工阅读和理解外文文献;在搜索引擎中,机器翻译可以帮助用户搜索和理解跨语言内容。
机器翻译的挑战和未来
未来的机器翻译技术趋势和挑战包括:
①多模态翻译:将图像、音频和文本等多种类型的信息结合,实现多模态的翻译。
②跨语言翻译:实现不同语言之间的翻译,例如中文到日文、日文到韩文等。
③零样本翻译:通过无需大量句子对的数据,实现高质量的翻译。
④语义翻译:将源语言句子的语义直接翻译成目标语言句子,而不仅仅是词汇翻译。
⑤实时翻译:实现实时的翻译,例如在会议中实时翻译讲话。
⑥个性化翻译:根据用户的需求和偏好,提供更符合用户需求的翻译。
总之,机器翻译是一种重要的自然语言处理技术,在跨语言交流、文档翻译和信息检索等方面都有广泛应用。随着人工智能技术的不断发展,机器翻译的质量和效率将会得到进一步提高。
小结
可以将编码器—解码器和注意力机制应用于机器翻译中。
BLEU可以用来评价翻译结果。
练习题
- 如果编码器和解码器的隐藏单元个数不同或层数不同,我们该如何改进解码器的隐藏状态初始化方法?
-
使用编码器的最后一个隐藏状态来初始化解码器的隐藏状态。这可以帮助解码器在开始生成序列时获取一些与编码器相关的信息。
使用一个线性变换层来调整编码器的最后一个隐藏状态,使其与解码器的隐藏单元个数和层数相匹配。这可以保持隐藏状态的维度一致,从而更好地传递信息。
使用一个额外的全连接层来将编码器的隐藏状态映射到解码器的隐藏状态空间,以确保信息的连续传递和适应。
根据具体的问题和模型结构,可以尝试其他定制化的方法来处理不同隐藏单元个数或层数的情况,例如使用注意力机制来对隐藏状态进行动态调整。
- 在训练中,将强制教学替换为使用解码器在上一时间步的输出作为解码器在当前时间步的输入。结果有什么变化吗?
-
训练稳定性:使用解码器在上一时间步的输出作为当前时间步的输入可能会导致训练不稳定性,特别是在训练初期。这是因为模型在生成序列时可能会出现累积误差,导致错误的预测在后续时间步中被传递并放大。
序列生成:这种方法可能会使模型更倾向于生成重复的片段或者陷入循环,因为模型在生成序列时会不断重复之前的输出。
训练速度:使用解码器上一个时间步的输出作为当前时间步的输入可能会加快模型的收敛速度,因为模型在训练过程中可以更快地学习到正确的输出。
生成质量:这种方法可能会降低生成序列的质量,因为模型可能会在生成过程中出现不连贯或不合理的输出。
总的来说,强制教学和使用解码器上一个时间步的输出作为当前时间步的输入各有优缺点,取决于具体的任务和模型结构。在实践中,通常需要根据具体情况进行调整和权衡。
- 试着使用更大的翻译数据集来训练模型,例如 WMT [2] 和 Tatoeba Project [3]。
-
对于训练机器翻译模型,使用更大的翻译数据集如WMT(Workshop on Machine Translation)和Tatoeba Project是非常有益的。这些数据集包含了大量的平行语料,可以帮助模型更好地学习语言之间的映射关系和提高翻译质量。
WMT数据集是一个知名的机器翻译基准数据集,提供了多种语言对之间的平行语料,涵盖了多个领域和风格。通过使用WMT数据集进行训练,可以使模型学习到更加准确和多样化的翻译知识,从而提高翻译质量。
Tatoeba Project是一个由志愿者维护的多语言句子对齐数据库,包含了来自全球用户的翻译句子对。通过使用Tatoeba Project数据集进行训练,可以扩大训练数据的覆盖范围,涵盖更多的语言对和语言风格,从而提高模型在多样化翻译任务上的表现。
在训练模型时,使用更大的翻译数据集需要考虑计算资源、训练时间和数据清洗等方面的挑战。但是,通过充分利用这些丰富的数据资源,可以帮助模型更好地泛化并在真实场景中取得更好的翻译效果。
-
参考文献
[1] Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
[2] WMT. Translation Task - ACL 2014 Ninth Workshop on Statistical Machine Translation
[3] Tatoeba Project. Tab-delimited Bilingual Sentence Pairs from the Tatoeba Project (Good for Anki and Similar Flashcard Applications)


