
- 1面试要准备复习些啥(前端开发)_前端面试前复习应该怎么复习
- 2GIT绑定远端码云官方库方法_git绑定码云
- 3软件开发-技术面试问题总结_软件开发面试
- 4认识张智勇!
- 5Django获取数据库的内容,显示到前端_django查询数据库输出给前端
- 6探索数据结构:链式队与循环队列的模拟、实现与应用_数据结构链式队列的实现及应用体会
- 7【Android】怎么使APP进行开机启动_android7.0 app开机启动
- 8解决vscode 通过Go:Install/Update Tools命令安装失败的问题_go install 失败
- 9PostgreSQL数据库安全加固(八)——用户功能与数据库管理功能分开_postgres 加固
- 10随机种子的作用,以Pytorch为例
西瓜书研读——第四章 决策树:ID3、C4.2、CSRT算法_id3算法西瓜决策树
赞
踩
西瓜书研读系列:
西瓜书研读——第三章 线性模型:一元线性回归
- 主要教材为西瓜书,结合南瓜书,统计学习方法,B站视频整理~
- 人群定位:学过高数会求偏导、线代会矩阵运算、概率论知道啥是概率
- 原理讲解,公式推导,课后习题,实践代码应有尽有,欢迎订阅
4 决策树
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题,决策树算法的本质是一种图结构。
决策树算法容易理解,适用各种数据,在解决各种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
4.1 基本概念与构造流程
以西瓜数据集为例,决策树是如何生成的?
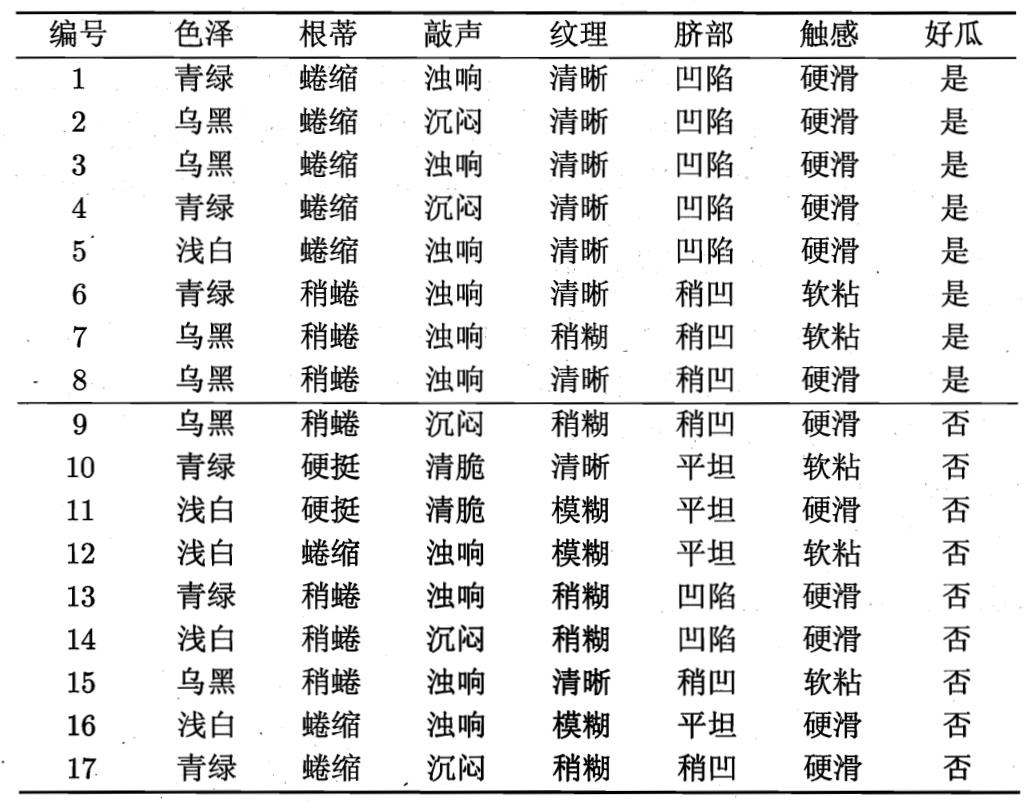
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。一般一棵决策树包含:一个根节点、若干个内部节点和若干个叶子节点,易知:
- 非叶节点:表示一个特征属性测试。
- 分支:代表这个特征属性在某个值域上的输出。
- 叶子节点:存放一个类别。
每个结点包含的样本集合根据属性测试的结果被划分到子结点中,而根结点包含了样本全集。
从根结点到每个叶结点的路径对应了一个判定测试序列
构造流程

决策树的生成是一个递归过程
三种会导致递归返回的情形
- 当前结点包含的样本全属于同一类别,无需划分
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
- 把当前结点标记为叶结点,并将其类别设定为该结点所含样本最多的类别
- 利用当前结点的后验分布
- 当前结点包含的样本集合为空,不能划分
- 把当前结点标记为叶结点,但将其类别设定为父结点所含样本做多的类别
- 把父结点的样本分布作为当前结点的先验分布
决策树各类算法的核心就就在于:如何解决“从A中选择最优划分属性”?
4.2 划分选择
核心问题:如何解决“从A中选择最优划分属性”?
划分目的:决策树分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高
点击查看信息论补充知识

信息熵(information entropy)
在决策树种,信息熵通常是用来度量样本集合纯度最常用的一种指标,信息量越大 信息熵越大,不确定性越大。
Ent
(
D
)
=
−
∑
k
=
1
∣
Y
∣
p
k
log
2
p
k
\operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|}p_k\log_{2}{p_k}
Ent(D)=−k=1∑∣Y∣pklog2pk
条件熵:表示的是在已知一个随机变量的条件下,另一个随机变量的不确定性。
具体地,假设有随机变量
X
X
X和
Y
Y
Y,且它们服从以下联合概率分布
P
(
X
=
x
i
,
Y
=
y
j
)
=
p
i
j
i
=
1
,
2
,
.
.
.
.
,
n
;
j
=
1
,
2
,
.
.
.
,
m
P(X = x_{i},Y = y_{j}) = p_{ij}\quad i = 1,2,....,n;j = 1,2,...,m
P(X=xi,Y=yj)=piji=1,2,....,n;j=1,2,...,m
那么在已知
X
X
X的条件下,随机变量
Y
Y
Y的条件熵为
H
(
Y
∣
X
)
=
∑
x
p
(
x
)
H
(
Y
∣
X
=
x
)
H(Y|X)=\sum_{x}p(x)H(Y|X=x)
H(Y∣X)=x∑p(x)H(Y∣X=x)
Ent ( Y ∣ X ) = ∑ i = 1 n p i Ent ( Y ∣ X = x i ) \operatorname{Ent}(Y|X) = \sum_{i=1}^np_i \operatorname{Ent}(Y|X = x_i) Ent(Y∣X)=i=1∑npiEnt(Y∣X=xi)
其中,$ p_i = P(X = x_i) ,i =1,2,…,n$。
在信息论中信息增益也称为互信息
互信息:信息熵和条件熵的差,它表示的是已知一个随机变量的信息后使得另一个随机变量的不确定性减少的程度。
具体地,假设有随机变量
X
X
X和
Y
Y
Y,那么在已知
X
X
X的信息后,
Y
Y
Y的不确定性减少的程度为
I
(
Y
;
X
)
=
Ent
(
Y
)
−
Ent
(
Y
∣
X
)
\operatorname{I}(Y;X) = \operatorname{Ent}(Y) - \operatorname{Ent}(Y|X)
I(Y;X)=Ent(Y)−Ent(Y∣X)
此即为互信息的数学定义。
证明 0 ≤ Ent ( D ) ≤ log 2 ∣ Y ∣ 0\leq\operatorname{Ent}(D)\leq\log_{2}|\mathcal{Y}| 0≤Ent(D)≤log2∣Y∣:
已知集合
D
D
D的信息熵的定义为
Ent
(
D
)
=
−
∑
k
=
1
∣
Y
∣
p
k
log
2
p
k
\operatorname{Ent}(D)=-\sum_{k=1}^{|\mathcal{Y}|} p_{k} \log _{2} p_{k}
Ent(D)=−k=1∑∣Y∣pklog2pk
其中,
∣
Y
∣
|\mathcal{Y}|
∣Y∣表示样本类别总数,
p
k
p_k
pk表示第
k
k
k类样本所占的比例,且
0
≤
p
k
≤
1
,
∑
k
=
1
n
p
k
=
1
0 \leq p_k \leq 1,\sum_{k=1}^{n}p_k=1
0≤pk≤1,∑k=1npk=1。若令
∣
Y
∣
=
n
,
p
k
=
x
k
|\mathcal{Y}|=n,p_k=x_k
∣Y∣=n,pk=xk,那么信息熵
Ent
(
D
)
\operatorname{Ent}(D)
Ent(D)就可以看作一个
n
n
n元实值函数,也即
Ent
(
D
)
=
f
(
x
1
,
.
.
.
,
x
n
)
=
−
∑
k
=
1
n
x
k
log
2
x
k
\operatorname{Ent}(D)=f(x_1,...,x_n)=-\sum_{k=1}^{n} x_{k} \log _{2} x_{k}
Ent(D)=f(x1,...,xn)=−k=1∑nxklog2xk
其中,
0
≤
x
k
≤
1
,
∑
k
=
1
n
x
k
=
1
0 \leq x_k \leq 1,\sum_{k=1}^{n}x_k=1
0≤xk≤1,∑k=1nxk=1,下面考虑求该多元函数的最值。首先我们先来求最大值,如果不考虑约束
0
≤
x
k
≤
1
0 \leq x_k \leq 1
0≤xk≤1,仅考虑
∑
k
=
1
n
x
k
=
1
\sum_{k=1}^{n}x_k=1
∑k=1nxk=1的话,对
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)求最大值等价于如下最小化问题
min
∑
k
=
1
n
x
k
log
2
x
k
s.t.
∑
k
=
1
n
x
k
=
1
显然,在
0
≤
x
k
≤
1
0 \leq x_k \leq 1
0≤xk≤1时,此问题为凸优化问题,而对于凸优化问题来说,能令其拉格朗日函数的一阶偏导数等于0的点即为最优解。根据拉格朗日乘子法可知,该优化问题的拉格朗日函数为
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
=
∑
k
=
1
n
x
k
log
2
x
k
+
λ
(
∑
k
=
1
n
x
k
−
1
)
L(x_1,...,x_n,\lambda)=\sum_{k=1}^{n} x_{k} \log _{2} x_{k}+\lambda(\sum_{k=1}^{n}x_k-1)
L(x1,...,xn,λ)=k=1∑nxklog2xk+λ(k=1∑nxk−1)
其中,
λ
\lambda
λ为拉格朗日乘子。对
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
L(x_1,...,x_n,\lambda)
L(x1,...,xn,λ)分别关于
x
1
,
.
.
.
,
x
n
,
λ
x_1,...,x_n,\lambda
x1,...,xn,λ求一阶偏导数,并令偏导数等于0可得
∂
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
∂
x
1
=
∂
∂
x
1
[
∑
k
=
1
n
x
k
log
2
x
k
+
λ
(
∑
k
=
1
n
x
k
−
1
)
]
=
0
=
log
2
x
1
+
x
1
⋅
1
x
1
ln
2
+
λ
=
0
=
log
2
x
1
+
1
ln
2
+
λ
=
0
⇒
λ
=
−
log
2
x
1
−
1
ln
2
∂
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
∂
x
2
=
∂
∂
x
2
[
∑
k
=
1
n
x
k
log
2
x
k
+
λ
(
∑
k
=
1
n
x
k
−
1
)
]
=
0
⇒
λ
=
−
log
2
x
2
−
1
ln
2
⋮
∂
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
∂
x
n
=
∂
∂
x
n
[
∑
k
=
1
n
x
k
log
2
x
k
+
λ
(
∑
k
=
1
n
x
k
−
1
)
]
=
0
⇒
λ
=
−
log
2
x
n
−
1
ln
2
∂
L
(
x
1
,
.
.
.
,
x
n
,
λ
)
∂
λ
=
∂
∂
λ
[
∑
k
=
1
n
x
k
log
2
x
k
+
λ
(
∑
k
=
1
n
x
k
−
1
)
]
=
0
⇒
∑
k
=
1
n
x
k
=
1
整理一下可得
{
λ
=
−
log
2
x
1
−
1
ln
2
=
−
log
2
x
2
−
1
ln
2
=
.
.
.
=
−
log
2
x
n
−
1
ln
2
∑
k
=
1
n
x
k
=
1
\left\{
由以上两个方程可以解得
x
1
=
x
2
=
.
.
.
=
x
n
=
1
n
x_1=x_2=...=x_n=\cfrac{1}{n}
x1=x2=...=xn=n1
又因为
x
k
x_k
xk还需满足约束
0
≤
x
k
≤
1
0 \leq x_k \leq 1
0≤xk≤1,显然
0
≤
1
n
≤
1
0 \leq\cfrac{1}{n}\leq 1
0≤n1≤1,所以
x
1
=
x
2
=
.
.
.
=
x
n
=
1
n
x_1=x_2=...=x_n=\cfrac{1}{n}
x1=x2=...=xn=n1是满足所有约束的最优解,也即为当前最小化问题的最小值点,同时也是
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)的最大值点。将
x
1
=
x
2
=
.
.
.
=
x
n
=
1
n
x_1=x_2=...=x_n=\cfrac{1}{n}
x1=x2=...=xn=n1代入
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)中可得
f
(
1
n
,
.
.
.
,
1
n
)
=
−
∑
k
=
1
n
1
n
log
2
1
n
=
−
n
⋅
1
n
log
2
1
n
=
log
2
n
f(\cfrac{1}{n},...,\cfrac{1}{n})=-\sum_{k=1}^{n} \cfrac{1}{n} \log _{2} \cfrac{1}{n}=-n\cdot\cfrac{1}{n} \log _{2} \cfrac{1}{n}=\log _{2} n
f(n1,...,n1)=−k=1∑nn1log2n1=−n⋅n1log2n1=log2n
所以显然
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)在满足约束
0
≤
x
k
≤
1
,
∑
k
=
1
n
x
k
=
1
0 \leq x_k \leq 1,\sum_{k=1}^{n}x_k=1
0≤xk≤1,∑k=1nxk=1时的最大值为
log
2
n
\log _{2} n
log2n。
求完最大值后下面我们再来求最小值,如果不考虑约束
∑
k
=
1
n
x
k
=
1
\sum_{k=1}^{n}x_k=1
∑k=1nxk=1,仅考虑
0
≤
x
k
≤
1
0 \leq x_k \leq 1
0≤xk≤1的话,
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)可以看做是
n
n
n个互不相关的一元函数的加和,也即
f
(
x
1
,
.
.
.
,
x
n
)
=
∑
k
=
1
n
g
(
x
k
)
f(x_1,...,x_n)=\sum_{k=1}^{n} g(x_k)
f(x1,...,xn)=k=1∑ng(xk)
其中,
g
(
x
k
)
=
−
x
k
log
2
x
k
,
0
≤
x
k
≤
1
g(x_k)=-x_{k} \log _{2} x_{k},0 \leq x_k \leq 1
g(xk)=−xklog2xk,0≤xk≤1。那么当
g
(
x
1
)
,
g
(
x
2
)
,
.
.
.
,
g
(
x
n
)
g(x_1),g(x_2),...,g(x_n)
g(x1),g(x2),...,g(xn)分别取到其最小值时,
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)也就取到了最小值。所以接下来考虑分别求
g
(
x
1
)
,
g
(
x
2
)
,
.
.
.
,
g
(
x
n
)
g(x_1),g(x_2),...,g(x_n)
g(x1),g(x2),...,g(xn)
各自的最小值,由于 g ( x 1 ) , g ( x 2 ) , . . . , g ( x n ) g(x_1),g(x_2),...,g(x_n) g(x1),g(x2),...,g(xn)的定义域和函数表达式均相同,所以只需求出 g ( x 1 ) g(x_1) g(x1)的最小值也就求出了 g ( x 2 ) , . . . , g ( x n ) g(x_2),...,g(x_n) g(x2),...,g(xn)的最小值。下面考虑求 g ( x 1 ) g(x_1) g(x1)的最小值,首先对 g ( x 1 ) g(x_1) g(x1)关于 x 1 x_1 x1求一阶和二阶导数
g ′ ( x 1 ) = d ( − x 1 log 2 x 1 ) d x 1 = − log 2 x 1 − x 1 ⋅ 1 x 1 ln 2 = − log 2 x 1 − 1 ln 2 g^{\prime}(x_1)=\cfrac{d(-x_{1} \log _{2} x_{1})}{d x_1}=-\log _{2} x_{1}-x_1\cdot \cfrac{1}{x_1\ln2}=-\log _{2} x_{1}-\cfrac{1}{\ln2} g′(x1)=dx1d(−x1log2x1)=−log2x1−x1⋅x1ln21=−log2x1−ln21
g
′
′
(
x
1
)
=
d
(
g
′
(
x
1
)
)
d
x
1
=
d
(
−
log
2
x
1
−
1
ln
2
)
d
x
1
=
−
1
x
1
ln
2
g^{\prime\prime}(x_1)=\cfrac{d\left(g^{\prime}(x_1)\right)}{d x_1}=\cfrac{d\left(-\log _{2} x_{1}-\cfrac{1}{\ln2}\right)}{d x_1}=-\cfrac{1}{x_{1}\ln2}
g′′(x1)=dx1d(g′(x1))=dx1d(−log2x1−ln21)=−x1ln21
显然,当
0
≤
x
k
≤
1
0 \leq x_k \leq 1
0≤xk≤1时
g
′
′
(
x
1
)
=
−
1
x
1
ln
2
g^{\prime\prime}(x_1)=-\cfrac{1}{x_{1}\ln2}
g′′(x1)=−x1ln21恒小于0,所以
g
(
x
1
)
g(x_1)
g(x1)是一个在其定义域范围内开口向下的凹函数,那么其最小值必然在边界取,于是分别取
x
1
=
0
x_1=0
x1=0和
x
1
=
1
x_1=1
x1=1,代入
g
(
x
1
)
g(x_1)
g(x1)可得
g
(
0
)
=
−
0
log
2
0
=
0
g
(
1
)
=
−
1
log
2
1
=
0
g(0)=-0\log _{2} 0=0 \\ g(1)=-1\log _{2} 1=0
g(0)=−0log20=0g(1)=−1log21=0
所以,
g
(
x
1
)
g(x_1)
g(x1)的最小值为0,同理可得
g
(
x
2
)
,
.
.
.
,
g
(
x
n
)
g(x_2),...,g(x_n)
g(x2),...,g(xn)的最小值也为0,那么
f
(
x
1
,
.
.
.
,
x
n
)
f(x_1,...,x_n)
f(x1,...,xn)的最小值此时也为0。
综上可知,当 f ( x 1 , . . . , x n ) f(x_1,...,x_n) f(x1,...,xn)取到最大值时: x 1 = x 2 = . . . = x n = 1 n x_1=x_2=...=x_n=\cfrac{1}{n} x1=x2=...=xn=n1,此时样本集合纯度最低;当 f ( x 1 , . . . , x n ) f(x_1,...,x_n) f(x1,...,xn)取到最小值时: x k = 1 , x 1 = x 2 = . . . = x k − 1 = x k + 1 = . . . = x n = 0 x_k=1,x_1=x_2=...=x_{k-1}=x_{k+1}=...=x_n=0 xk=1,x1=x2=...=xk−1=xk+1=...=xn=0,此时样本集合纯度最高。
- Ent ( D ) \text{Ent}(D) Ent(D) 的值越小,则 D D D 的纯度越高
- Ent ( D ) \text{Ent}(D) Ent(D) 的最小值为0,最大值为 log 2 ∣ Y ∣ \log_2|\mathcal{Y}| log2∣Y∣
4.2.1 信息增益 ( ID3算法)
一般而言,信息增益越大,即取值后样本集的不确定性减小的程度越大,则意味着使用属性
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

