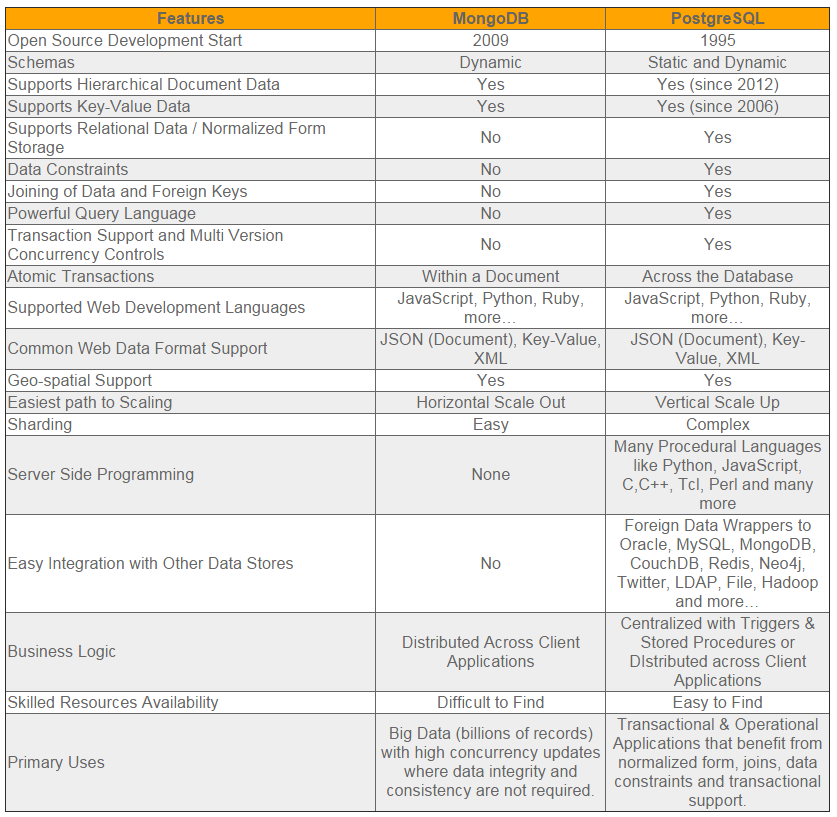
之前我们在和开发团队所设计框架里面的MongoDB标准组件PK时,曾经找了一些PG与MongoDB的对比材料。
今天得空又具体看了下,简单总结一下,供大家借鉴参考:
一、先搞清楚它们支持的数据类型。
PG支持的数据类型叫JSON,从PostgreSQL 9.3版本开始,JSON已经成为内置数据类型,不仅仅是一个扩展了。
PG从9.4开始,又推出了新的JSONB的数据类型。
Document Database – JSON
Document database capabilities in Postgres advanced significantly
when support for the JSON data type was introduced in 2012 as part of
Postgres 9.2. JSON (JavaScript Object Notation) is one of the most
popular data-interchange formats on the web. It is supported by
virtually every programming language in use today, and continues to
gain traction. Some NoSQL-only systems, such as MongoDB, use
JSON (or its more limited binary cousin BSON) as their native data
interchange format.
Postgres offers robust support for JSON. Postgres has a JSON data
type, which validates and stores JSON data and provides functions for
extracting elements from JSON values. And, it offers the ability to
easily encode query result sets using JSON. This last piece of
functionality is particularly important, as it means that applications that
prefer to work natively with JSON can easily obtain their data from
Postgres in JSON.
Below are some examples of using JSON data in Postgres:


In addition to the native JSON data type, Postgres v9.3, released in
2013, added a JSON parser and a variety of JSON functions. This
means web application developers don't need translation layers in
the code between the database and the web framework that uses
JSON. JSON-formatted data can be sent directly to the database
where Postgres will not only store the data, but properly validate it
as well. With JSON functions, Postgres can read relational data
from a table and return it to the application as valid JSON formatted
strings. And, the relational data can be returned as JSON for either a single value or an entire record.

JSONB – Binary JSON
Postgres 9.4 introduces JSONB, a second JSON type with a binary
storage format. There are some significant differences between
JSONB in Postgres and BSON, which is used by one of the largest
document-only database providers. JSONB uses an internal
storage format that is not exposed to clients; JSONB values are
sent and received using the JSON text representation. BSON
stands for Binary JSON, but in fact not all JSON values can be
represented using BSON. For example, BSON cannot represent an
integer or floating-point number with more than 64 bits of precision,
whereas JSONB can represent arbitrary JSON values. Users of
BSON-based solutions should be aware of this limitation to avoid
data loss.

引用Francs的blog:jsonb 的出现带来了更多的函数, 更多的索引创建方式, 更多的操作符和更高的性能。
关于PG的JSON和JSONB的具体介绍和测试,参考Francs的blog:
http://francs3.blog.163.com/blog/static/40576727201452293027868/
http://francs3.blog.163.com/blog/static/40576727201442264738357/
http://francs3.blog.163.com/blog/static/40576727201341613630793/
MongoDB支持的数据类型叫BSON
其实BSON就是JSON的一个扩展,BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。
二者的区别参考:
http://www.tuicool.com/articles/iUNbyi
BSON是由10gen开发的一个数据格式,目前主要用于MongoDB中,是MongoDB的数据存储格式。BSON基于JSON格式,选择JSON进行改造的原因主要是JSON的通用性及JSON的schemaless的特性。
BSON主要会实现以下三点目标:
1.更快的遍历速度
对JSON格式来说,太大的JSON结构会导致数据遍历非常慢。在JSON中,要跳过一个文档进行数据读取,需要对此文档进行扫描才行,需要进行麻烦的数据结构匹配,比如括号的匹配,而BSON对JSON的一大改进就是,它会将JSON的每一个元素的长度存在元素的头部,这样你只需要读取到元素长度就能直接seek到指定的点上进行读取了。
2.操作更简易
对JSON来说,数据存储是无类型的,比如你要修改基本一个值,从9到10,由于从一个字符变成了两个,所以可能其后面的所有内容都需要往后移一位才可以。而使用BSON,你可以指定这个列为数字列,那么无论数字从9长到10还是100,我们都只是在存储数字的那一位上进行修改,不会导致数据总长变大。当然,在MongoDB中,如果数字从整形增大到长整型,还是会导致数据总长变大的。
3.增加了额外的数据类型
JSON是一个很方便的数据交换格式,但是其类型比较有限。BSON在其基础上增加了“byte array”数据类型。这使得二进制的存储不再需要先base64转换后再存成JSON。大大减少了计算开销和数据大小。
当然,在有的时候,BSON相对JSON来说也并没有空间上的优势,比如对{“field”:7},在JSON的存储上7只使用了一个字节,而如果用BSON,那就是至少4个字节(32位)
二、PG和MongoDB在读写方面的测试对比:
PG的商业版EnterpriseDB公司在2014.9月发布了一份针对MongoDB v2.6 to Postgres v9.4 beta的对比报告(如果其对比MongoDB 3.0版本可能测试结果会有差别), 简单翻译其测试报告结果如下:
5000万文档型数据查询、加载、插入时:
1, 大量数据的加载,PG比MongoDB快2.1倍
2, 同样的数据量,MongoDB的占用空间是PG的1.33倍。
3, Insert操作MongoDB比PG慢3倍
4, Select操作MongoDB比PG慢2.5倍。


详细可以参阅:
当然,EnterpriseDB的测试报告有商业宣传意味,而且据国内数据库同仁skykiker的blog的模拟测试的结果,可以看得出EnterpriseDB是有水分的。参考《 为什么PostgreSQL比MongoDB还快? 》:
http://blog.chinaunix.net/uid-20726500-id-4960138.html
但是, EDB的这份报告里面的下面这段话与我们之前对开发的说法是一致的,也简单翻译了一下,这个我个人理解其实也是企业内复杂应用环境下面,选择使用PG对比MongoDB的核心优势,大家可以对开发这样去灌输这些理念:
对于应用开发的自由性:
PG的最新版本引领了一个新的开发灵活性的领域, 超过了原来只使用NoSQL带来的开发自由性。对于像MongoDB这样在针对性优势而细分出来的市场中的使用一直在增长,因为开发人员需要从传统的关系型数据库的结构化数据中解放出来,他们需要快速交付并且处理新的数据类型。他们选择强大但是有限制的解决方案可以快速满足需求,让他们不用在做任何变动的时候等待DBA。
但是,很多企业发现成功的应用经常需要结构化的数据来落地(down the road这句话我认为用得很好),这种数据对企业更加有价值。PG给到开发人员新的有力的解决方案,从非结构化数据开始着手,当需求变化或增多时,可以将结构化和非结构化的数据在同一个数据库里面进行有机结合,而且是在一个具有ACID特性的环境。
原文如下:
Developer Freedom
With the newest version, PostgreSQL has ushered in a new era of developer flexibility exceeding the freedom they discovered with NoSQL-only solutions. The use of niche solutions, like MongoDB, increased because developers needed freedom from the structured data model required by relational databases. They needed to move quickly and work with new data types. They choose powerful but limited solutions that addressed immediate needs, that let them make changes without having to wait for a DBA.
However, many organizations have discovered that successful applications often require structure down the road, as data becomes more valuable across the organization. Postgres gives developers broad new powers to start out unstructured, and then when the need arises, combine unstructured and structured data using the same database engine and within an ACID-compliant environment.
- See more at: http://www.enterprisedb.com/postgres-plus-edb-blog/marc-linster/postgres-outperforms-mongodb-and-ushers-new-developer-reality#sthash.wPT3crV7.dpuf
对于我们DBA面对的开发人员来讲,即使把大量关系型数据同步到hadoop来进行运算、分析,但是最终产出分析报表,还是要回到关系型数据库来做精细化的加工处理。从rdbms -> hadoop -> rdbms可以看到要经过hadoop中转一道,一方面存在数据同步时效(时间和效率)的问题,另一方面提供实时查询功能不足,另外可能还需要hive的开发技能。而如果使用PG例如Greenplumb时,直接全部都可以在一个PG集群里面完成,上述问题都迎刃而解。
上面这段话是我现在经常用来向开发推销GP的一种说辞。
以下是2个PG对于关系型数据和非关系型数据整合操作的例子:
1,Combining ANSI SQL Queries and JSON Queries
One of Postgres’ key strengths is the easy integration of conventional
SQL statements, for ANSI SQL tables and records, with JSON and
HSTORE references pointing documents and key-value pairs. Because
JSON and HSTORE are extensions of the underlying Postgres model,
the queries use the same syntax, run in the same ACID transactional
environment, and rely on the same query planner, optimizer and
indexing technologies as conventional SQL-only queries.
这真是一个大杀器,可以将传统SQL语言和JSON查询语言联合一起实现对结构化和非结构化数据的访问!

2,Bridging Between ANSI SQL and JSON
Postgres provides a number of functions to bridge between JSON and
ANSI SQL. This is an important capability when applications and data
models mature, and designers start to recognize emerging data
structures and relationships.
Postgres can create a bridge between ANSI SQL and JSON, for
example by making a ANSI SQL table look like a JSON data set. This
capability allows developers and DBAs to start with an unstructured
data set, and as the project progresses, adjust the balance between
structured and unstructured data.

更多PG支持的NoSQL的特性和场景, 参考:
http://www.enterprisedb.com/nosql-for-enterprise?src=edb-blog