- 1使用OpenAI的Whisper 模型进行语音识别
- 2python 模拟键盘鼠标操作_python 模拟操作qq
- 3远程控制技术:应用与趋势
- 4Java学习笔记(视频:韩顺平老师)2.0_韩顺平java
- 5【Kafka专题】Kafka快速实战以及基本原理详解_kafka专栏
- 6解决Django报错 raise ImproperlyConfigured(‘SQLite 3.8.3 or later is required (found %s).‘ % Database.s_watching for file changes with statreloader except
- 7OpenCV + Python 实现视频通道分离与合并_opencv通道分离合成python
- 8MySQL【部署 03】8.0.25离线部署(下载+安装+配置)Failed dependencies 问题处理及8.0配置参数说明_numactl离线安装
- 9探索边缘计算与云计算之间的区别
- 10Gartner发布零信任网络访问ZTNA市场指南_中国零信任网络访问市场指南
JAVA(数据库篇)面试题整理_java数据库面试题
赞
踩
逻辑执行顺序:
- FROM:指定要查询的表或视图。
- WHERE:对表中的数据进行筛选,只返回满足条件的行。
- GROUP BY:按指定列对结果集进行分组。
- HAVING:对分组后的结果集进行筛选。
- SELECT:选择要查询的列。
- ORDER BY:对结果集进行排序。
- LIMIT/OFFSET:限制返回的行数和偏移量。
书写顺序:
- SELECT:指定要查询的列。
- FROM:指定要查询的表或视图。
- WHERE:对表中的数据进行筛选。
- GROUP BY:按指定列对结果集进行分组。
- HAVING:对分组后的结果集进行筛选。
- ORDER BY:对结果集进行排序。
- LIMIT/OFFSET:限制返回的行数和偏移量。
原子性(Atomicity):事务中的所有操作要么全部成功提交,要么全部失败回滚,保证事务的完整性。
一致性(Consistency):事务执行前后,数据库从一个一致性状态转换到另一个一致性状态,不会破坏数据的完整性和约束。
隔离性(Isolation):多个事务并发执行时,每个事务的操作应该相互隔离,互不干扰,避免数据不一致的情况发生。
持久性(Durability):一旦事务提交,其所做的修改将会永久保存在数据库中,即使系统发生故障也不会丢失。
MYSQL使用存储引擎来管理数据存储和访问,而ORCALE通过表空间来管理存储结构。
MYSQL:
INNODB:MySQL的默认存储引擎,支持事务和行级锁定,提供了较好的性能和可靠性。
MYISAM:另一个常用的存储引擎,不支持事务和行级锁定,但在一些特定场景性能较好。
MEMORY:将表存储在内存中,适用于临时表和缓存数据。
MySQL还有其他存储引擎如Archive、CSV、Blackhole等.
ORCALE:
Oracle数据库并没有像MySQL那样明确的存储引擎概念,而是通过表空间(tablespace)来管理存储结构。表空间可以选择不同的存储参数和存储结构,如数据文件、日志文件等,以满足不同的存储需求。
事务支持:
MyISAM:不支持事务,不具备事务处理能力,因此在并发读写时可能会出现数据不一致的情况。
InnoDB:支持事务,具有ACID特性,可以保证数据的一致性、隔离性和持久性,适合于需要事务支持的应用场景。
行级锁定:
MyISAM:采用表级锁定,即在对表进行读写操作时会锁定整个表,可能导致并发性能较差。
InnoDB:采用行级锁定,只锁定需要操作的行,可以提高并发性能,减少锁冲突。
外键约束:
MyISAM:不支持外键约束,需要应用程序自行维护数据的完整性。
InnoDB:支持外键约束,可以保证数据的完整性,避免数据不一致的情况。
索引:
MyISAM:索引存储在不同的文件中,查询速度较快,但不支持全文搜索。
InnoDB:索引和数据存储在一起,支持全文搜索和外键约束,适合于需要频繁更新和查询的场景。
崩溃恢复:
MyISAM:在数据库崩溃时,可能会导致数据损坏,恢复较困难。
InnoDB:具有更好的崩溃恢复能力,支持事务的回滚和恢复,可以保证数据的一致性
悲观锁:
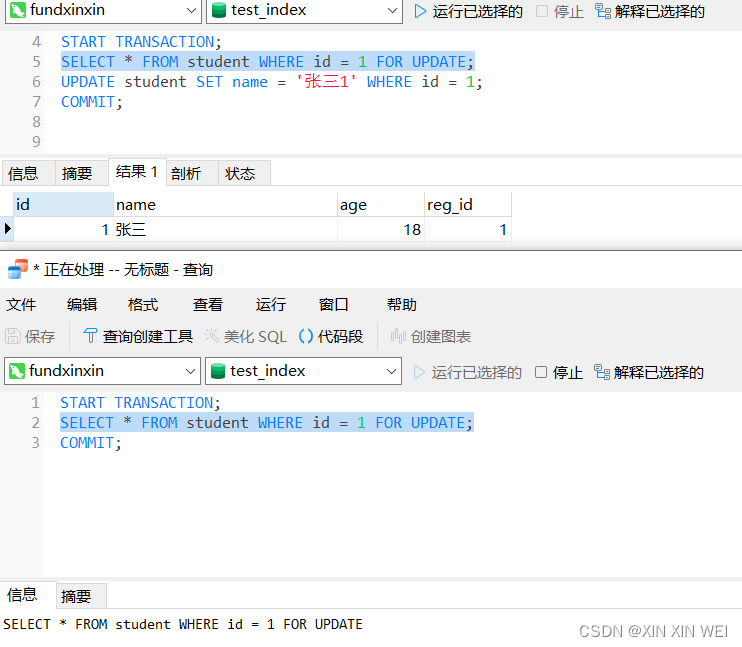
- MYSQL:在MySQL中,可以使用SELECT ... FOR UPDATE语句来实现悲观锁。该语句会在读取数据时对数据行加锁,阻止其他事务对该数据行进行修改,直到当前事务释放锁。
- ORCALE:在Oracle中,可以使用SELECT ... FOR UPDATE语句来实现悲观锁,类似于MySQL的用法。此外,Oracle还支持使用LOCK TABLE语句对整个表进行加锁。
乐观锁:
- MYSQL:在MySQL中,可以通过在表中增加一个版本号字段,每次更新数据时增加版本号,更新时检查版本号是否匹配来实现乐观锁。也可以使用UPDATE ... WHERE语句来实现乐观锁。
- ORACLE:在Oracle中,可以使用ROWVERSION或者使用触发器来实现乐观锁。ROWVERSION是一种自动维护的时间戳,每次更新时会自动更新时间戳,可以用于检测数据是否被修改。
MYSQL:
原数据就用 ID = 1 的数据验证;
需要两个窗口;
窗口1:开启事务1;ID = 1 加锁;修改数据;提交事务;
窗口2:开启事务2;ID = 1 加锁;
可以看到窗口2无法操作 ID = 1 的行数据;超时之后报错;
再次执行窗口2的 ID = 1 行数据加锁;然后执行窗口1 修改数据,提交事务;查看窗口2锁定的数据;
窗口2返回锁定的数据:是窗口1 修改完成的数据。
第二个窗口的语句会被阻塞,直到第一个窗口中的事务提交或回滚,这就是悲观锁的效果。
LACK TABLE READ;读锁,其他可以查询。LACK TABLE WRITE;写锁,其他不可以进行任何操作。
- 第一范式(1NF):所谓第一范式(1NF)是指在关系模型中,对于添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
- 第二范式(2NF):第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。每一行的数据只能与其中一行有关即主键,一行数据只能做一件事情或者表达一个意思,只要数据出现重复,就要进行表的拆分
- 第三范式(3NF):在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
都是B+树的数据结构
数据存储方式:
聚簇索引:表的数据行按照索引的顺序存储在磁盘上。每张表只能有一个聚簇索引,因此聚簇索引决定了表的物理存储顺序。
非聚簇索引:索引和数据行是分开存储的,索引文件和数据文件是分开的。表可以有多个非聚簇索引。
查找效率:
聚簇索引:由于数据行按照索引的顺序存储,因此通过聚簇索引可以快速找到需要的数据行,减少了磁盘 I/O 操作。
非聚簇索引:通过非聚簇索引查找数据时,首先定位到索引,然后再根据索引中的指针去找到对应的数据行,需要多一次查找过程,相对效率稍低一些。
索引的更新:
聚簇索引:由于数据行的顺序和索引的顺序一致,因此对于聚簇索引的更新可能会引发数据行的移动和重新排序,影响性能。
非聚簇索引:对于非聚簇索引的更新只需要更新索引文件,不会引起数据行的移动,因此更新性能相对更好。
- 如果条件中带有 OR,即使条件带有索引也不会使用;想要使用 OR,又不想索引失效,只能将 OR 条件中的每一列都加上索引。
- 模糊查询 LIKE 以 % 开头,索引失效,% 结尾、中间索引不失效。
- 如果列类型是 字符串,在条件中需要将数据用引号引起来,否则不使用索引,类型转化问题
- 组合索引要遵循 最左匹配原则,否则索引失效
- 查询条件中有 (<、>、<>)等操作符,索引失效
- 使用 is not null 、not like 索引失效
- 在索引列上进行了计算、函数、类型转换
- 组合索引 范围条件右边的列索引失效