
- 1python web 前后端分离_前后端分离篇
- 2uni-app小程序提示信息(信息提示)_uniapp提示信息
- 3探索深度感知新境界:MiDaS——跨数据集零样本迁移的鲁棒单目深度估计
- 4Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具_edge tts
- 5数据结构-----算法复杂度(大O表示法)_o(n!)
- 6hive优化:让一个MR做更多的事情_如何让hive任务只跑一个mr
- 7AI深入应用,生态越加开放,开发者的机会在哪里?
- 8前端npm项目启动报错:error:0308010C:digital envelope routines::unsupported_angular前端工程运行npm run dev提示:0308010c:digital envelo
- 9Postman接口测试之断言
- 10python建立窗口并美化_Python GUI教程(十六):在PyQt5中美化和装扮图形界面
狂奔的羊驼-llama3生态大爆发_llmam3
赞
踩
重要的时刻
llama3的发布在我看来是一个非常重要的时刻,特别是其8B的模型,超越了3.5的能力,但由于其模型参数小带来了无穷的想象力。
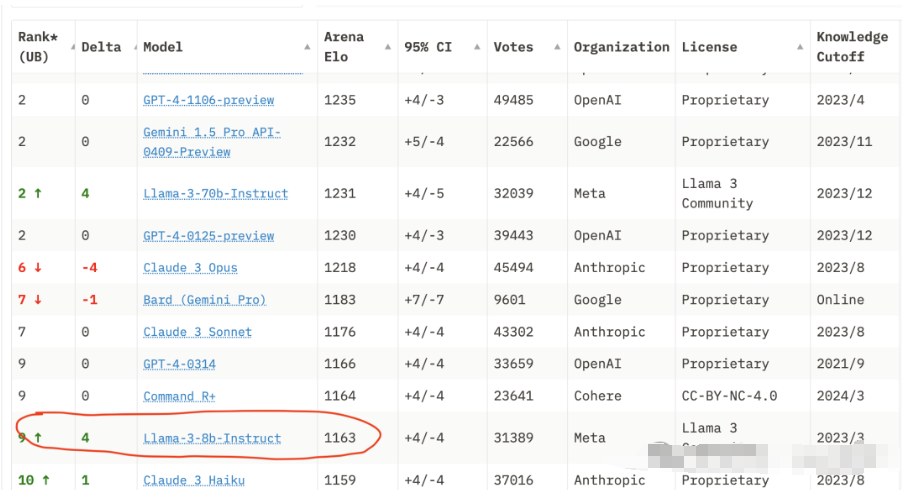
你不必在这张图寻找GPT3.5了,它的排名已经到了20多位。
两个重要变化
llama3发布带来了2个非常重大的变化
1.fine-tune成本骤减,任何人都可以以较低成本fine-tune llama3,社区创造力被释放。
2.由于模型较小,推理成本降低,这一点带来了2种可能:
1.极致的推理速度,比如使用Groq的情况下,可以达到惊人的速度。
2.本地化端侧模型使用,个人电脑端达到较好的体验,移动端达到可用。
果不其然,llama3仅仅发布2周,社区中涌现出非常多有趣的案例
百花齐放的Fine-tune模型
首先是各种各样的fine-tune模型,我们来看看huggingface上llama3 fine-tune模型数量,截止目前为止llama3仅仅发布2周,已经出现5000+ fine-tune模型,可见社区的火热。
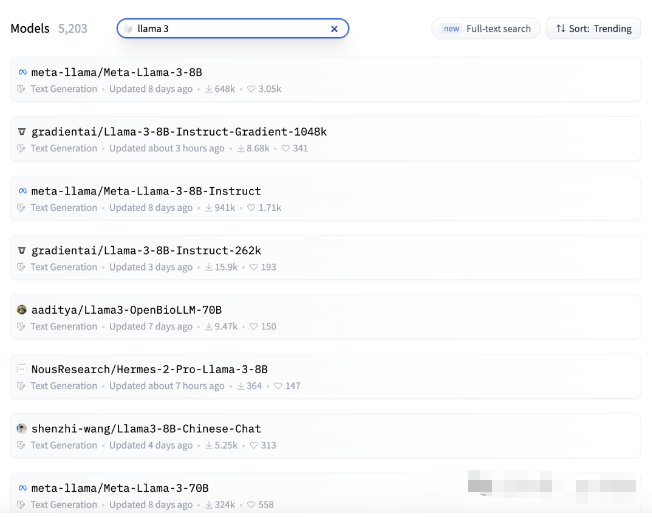
下面我们从几个维度来看看llama3 社区fine-tune模型给我们带来了哪些有趣的创造力。
长文本,可达1M上下文
之前长文本能力一直是各家大模型追逐的热点,在这个维度上,首先发布的是8B模型使用POSE方案将模型提升到256K 的llama-3-8b-256k-PoSE,256K已经超过目前很多模型的上限. 不过这远并没有结束,gradientai 随即发布了1M上下文的8B模型Llama-3-8B-Instruct-Gradient-1048k,直击当初Google Gemini 1M context的核心卖点。
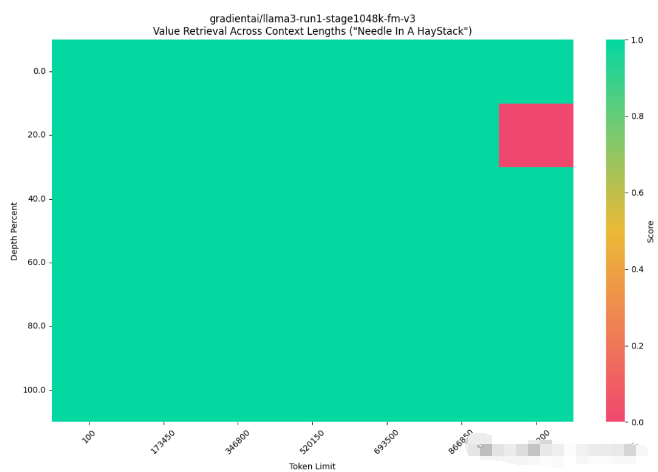
社区不仅仅基于8B模型fine-tune出了long context, 基于70B模型也fine-tune了Llama-3-Giraffe-70B 模型 支持128K context, 该模型也是使用了POSE的方案来拓展上下文。
不过,大模型能够支持超长上下文的前提下,能否在其中较好地大海捞针(从给定较长上下文中找到有用信息)也是极为重要,目前暂时还没有测试表明,它们的大海捞针能力足够优秀,还需要进一步测试。
视觉能力-vision模型
当GPT4-vision发布的时候,令人惊叹其深刻的视觉理解能力,但现在基于llama3 也出现了vision模型,下面是LLaVA-Meta-Llama-3-8B-Instruct 模型的效果展示,该模型结合LLaVA v1.5 与LLama3 8B训练而成,具备了较好的推理能力。这种将llama3 8B作为多模态中一环进行融合的方式相信在未来会让llama3 产生更大的能量,类似的Vision模型还有 Bunny-Llama-3-8B-V等。

特定任务的模型
比如专门为函数调用而fine-tune的模型: llama-3-8B-Instruct-function-calling,function-calling是实现Agent的重要一环,如果该能力有较高提升,对Agent整体效果也会有较大增幅。
其它一些专业任务的模型这里就不一一列举了。
此外,社区中还有一些模型是希望增强目前的llama3的整体能力,它们使用质量比较好的数据对基础llama3的能力进行调优。
模型能力增强
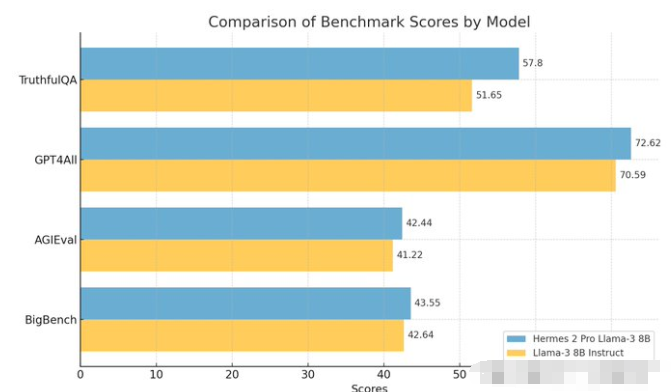
比如: Hermes-2-Pro-Llama-3-8B, 该模型有较为出色的对话能力,支持函数调用和JSON数据返回,在各项测试指标上均超过了官方的llama-3 8B instruct。
特定语言增强
还有对特定语言进行增强的模型,llama3 8B的原始中文能力不够好,社区中就出现了很多使用优质中文数据进行fine-tune的模型,比如下面的 Llama3-8B-Chinese-Chat

除了针对中文增强的,还有针对日文增强的模型suzume-llama-3-8B-japanese 等等。
促使fine-tune工具的爆发
由于fine-tune需求增加,社区中还涌现出大量用于fine-tune的工具
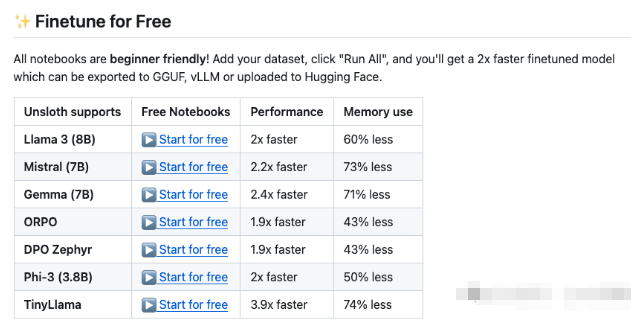
1.unsloth
unsloth直接给出了 fine-tune 的colab链接,只需要点击运行,等待一会即可完成训练,unsloth可以以更短的时间以及更少的显存完成对llama的fine-tune, 这无疑为llama 3 8B本来低成本的fine-tune如虎添翼。unsloth支持4位和16位的量化。
2.mac即可fine-tune *MLX-LM*
因为没有N卡的支持,mac用户在大模型使用方面处于不利的形势,,mac推出的mlx框架可以使得在mac上fine-tune llama3 8B成为可能,使用mlx-lm,只需要简单几个步骤,即可完成对llama3 的fine-tune。
3.fine-tune平台
使用https://monsterapi.ai/ 这样的平台更是可以让一个完全没有代码经验的人,完成对模型的fine-tune, 只需要上传你的数据即可即可完成模型fine-tune。
看完fine-tune,接下来我们继续看看推理侧的一些变化。
极致的推理速度
说到推理速度,其中最让人记忆深刻的是groq,它使用特定的推理硬件加速模型的推理,
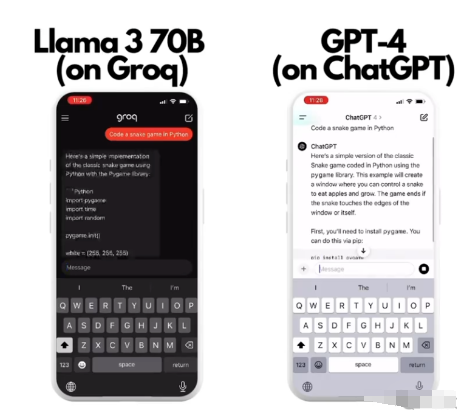
llama3 8B和70B 本身模型较小具备的较快推理速度叠加特定的LPU加速,使得groq上推理llama3 70B 可达284 tokens/s 推理 llama3 8B 可达 876 tokens/s。
有一个非常有趣的视频对比,在groq中使用llama3 70B 和 GPT4共同执行一段编码任务,groq中的llama 一瞬间完成,而GPT4还在慢慢地编码
端侧的应用
llama3 8B由于体积小,可以被个人电脑,甚至移动设备所本地部署使用。
个人电脑较好地使用LLAMA
社区中出现了很多可以在个人电脑中比较方便使用llama的工具,比如LM Studio以及ollama等, 可以非常容易地在个人电脑上进行llama3的推理。
而他们的背后都在使用 llama.cpp这个非常不错的项目,该项目针对各个系统的推理进行优化,并使用C重写。其支持的gguf 格式也成为社区中fine-tune模型的热门支持格式。可以说大部分个人电脑上llama推理工具都是基于llama.cpp的封装。
移动设备可用
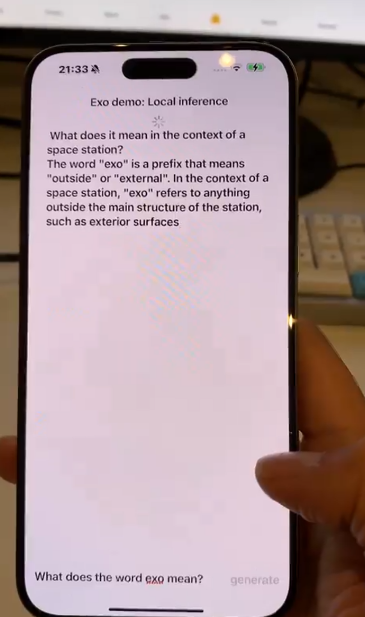
我一直认为所谓端侧模型仅仅能够运行在个人电脑上是不足以称之为大变革的,因为在移动时代,手机设备的使用比个人电脑要多很多,所以可以在移动设备运行大模型是1个重要时刻。llama3-8B可以做到这一点。
比如下面社区中有小伙伴就使用Meta-Llama-3-8B-Instruct-4bit 这样的4位量化模型,加之将其转化为苹果优化的mlx格式,在iPhone上流畅的运行。
有趣的应用
社区中还涌现出非常多有趣的llama3应用:
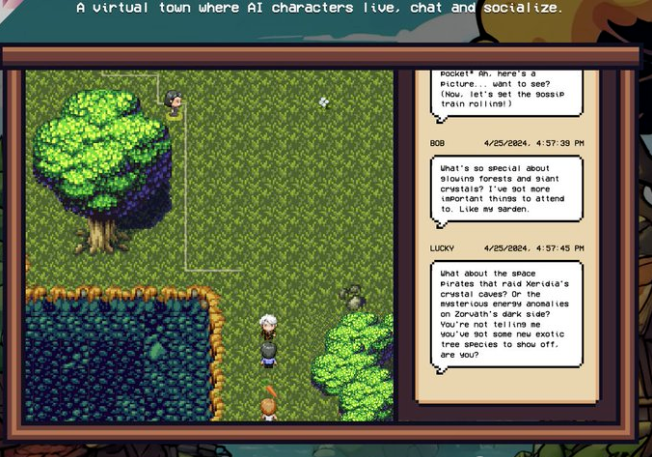
本地llama3 驱动的AI小镇
比如之前爆火的AI小镇,现在可以完全本地llama3驱动了
使用llama 本地完成视频总结
在本地通过ollama使用llama3, 将较长的视频分块,并自动形成摘要。
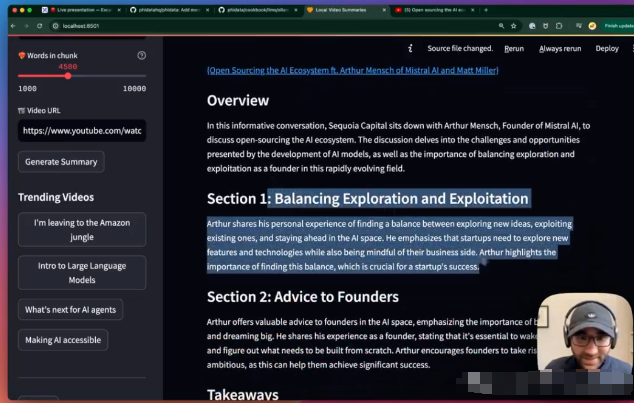
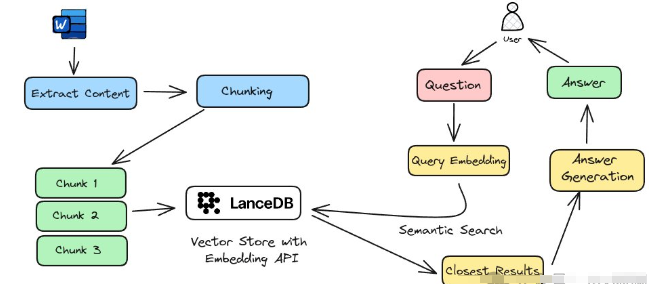
使用llama构建本地RAG系统
通过提取内容,递归分块,chunks embedding, 语义搜索,并最终送给llmam3这样的常规RAG流程完成了本地运行的RAG系统。
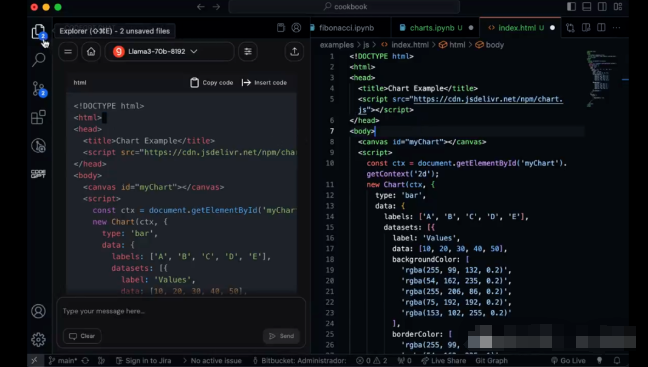
搭建vscode Copilot
借助groq 上llama3 极致的推理速度,加上 Code-GPT插件,完全可以自己打造1个vscode copilot。
总结
从llama3发布后理论上预测社区的爆发,到接下来的2周见证社区的持续火热,llama3带给我们非常多惊喜,未来会有更加参数小而能力强的模型出现,但llama3是1个重要的开始,fine-tune的低成本促进了社区创意的发挥,而这些创意产生的新模型又推进了应用生态的繁荣。另外本地化模型正在变得越来越好用,这进一步降低了大模型成本以及满足了离线使用模型的需求。期待在未来移动端也可以变得像现在个人电脑那样可以有非常好的使用大模型体验,令人憧憬的未来!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

