
热门标签
当前位置: article > 正文
分层K折交叉验证
作者:笔触狂放9 | 2024-08-09 15:38:05
赞
踩
分层k折交叉验证
K折交叉验证(K-fold Cross Validation)是一种
评估机器学习模型性能的常用技术和方法,其目的是通过将数据集分成K个子集(或“折”),来
估计模型在独立数据上的预测能力,以此来
减少因模型
过拟合训练数据而导致的评估偏差。下面是K折交叉验证的基本步骤和原理:
基本原理
-
数据分割:首先,将原始数据集
随机均匀地分割成K个不重叠的子集(或“fold”)。每个子集应尽可能保持数据分布的一致性,特别是当类别标签存在时,要保证各个类别在不同子集中比例相近,这可以通过分层抽样实现。 -
循环训练与验证:接下来,进行K轮迭代。在每一轮中:
- 选择其中一个子集作为
验证集(validation set)。 - 剩余的K-1个子集合并作为
训练集(training set)。 - 使用训练集训练模型。
- 利用验证集评估模型性能,通常通过计算某种性能度量,比如准确率、精确度、召回率、F1分数、AUC-ROC曲线下的面积等。
- 选择其中一个子集作为
-
结果汇总:完成K轮迭代后,将每轮验证集上的评估结果(如预测误差)平均起来,得到一个单一的评估指标,作为模型性能的综合估计。这一步骤考虑到了模型在不同数据子集上的表现,提高了评估的
稳定性和可靠性。
作用与优势
- 减少偏差与方差:通过在不同的数据子集上评估模型,K折交叉验证有助于
减小由于数据划分随机性导致的评估偏差,同时提供了模型性能的一致性估计。 - 模型选择与调参:可以用来比较不同模型之间的性能,帮助
选择最佳模型;也适用于超参数调优,找到使模型性能最优的参数组合。 - 避免过拟合:能够更好地评估模型在未见过的数据上的
泛化能力,降低过拟合风险。 - 资源高效:相较于单独保留一个大型测试集,K折交叉验证更加高效地利用了数据资源,尤其是在数据量相对有限时。
注意事项
- K值选择:K值的选择会影响验证结果的稳定性与准确性。较大的K值(如K=10)可以提供
更稳定的模型性能估计,但训练时间也会相应增加。较小的K值(如K=2,称为两重交叉验证或简单交叉验证)可能导致较大的方差。实践中,K=5或K=10是常见的选择。 - 计算成本:K折交叉验证相比单次训练和测试需要更多的计算资源,特别是在数据集庞大或模型复杂时。
- 分层处理分类数据:在分类任务中,为了保持训练集和验证集中类别比例一致,可采用分层K折交叉验证。
当然,让我们通过一个具体的例子来理解K折交叉验证的过程。假设我们有一个包含100条记录的数据集,我们要使用K折交叉验证(这里取K=5)来评估一个线性回归模型的性能。
步骤分解
-
数据准备:首先,将数据集按行编号为1到100。
-
数据分割:将这100条记录均匀分成5个子集(每个子集20条记录)。
-
开始验证:
- 第一轮:
选取子集1作为验证集,子集2到5作为训练集。使用这80条记录训练模型,然后用子集1(20条记录)评估模型性能,记录下该轮的评估指标(比如均方误差MSE)。 - 第二轮:
选取子集2作为验证集,子集1、3、4、5作为训练集。同样,训练模型并评估性能。 重复以上步骤,直到每个子集都被用作验证集一次。
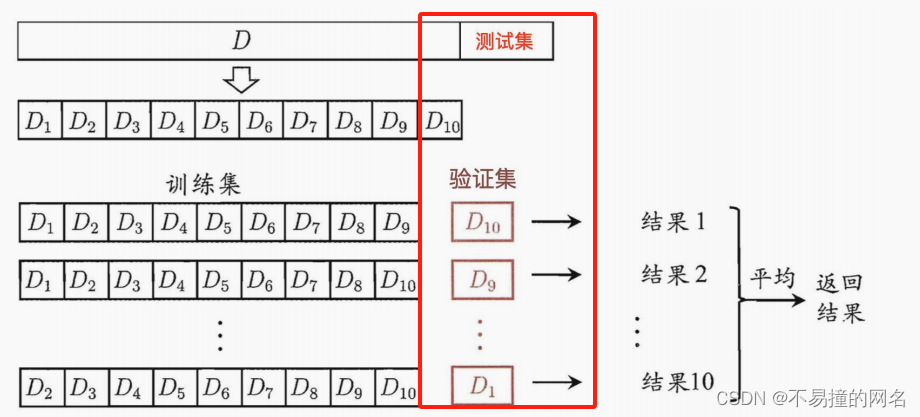
- 第一轮:
-
结果整合:在五轮结束后,我们将得到五次评估的结果。为了得到一个综合的性能指标,我们通常会计算这些结果的
平均值(如果评估的是误差,则取平均误差;如果是准确率,则取平均准确率)。
示例代码(Python + Scikit-learn)
from sklearn.model_selection import KFold from sklearn.linear_model import LinearRegression from sklearn.datasets import make_regression from sklearn.metrics import mean_squared_error # 生成示例数据集 X, y = make_regression(n_samples=100, n_features=10, noise=0.1) # 初始化线性回归模型 model = LinearRegression() # 初始化5折交叉验证 kf = KFold(n_splits=5, shuffle=True, random_state=42) mse_scores = [] # 进行K折交叉验证 for train_index, test_index in kf.split(X): # 分割数据 X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] # 训练模型 model.fit(X_train, y_train) # 预测并计算均方误差 y_pred = model.predict(X_test) mse = mean_squared_error(y_test, y_pred) mse_scores.append(mse) # 输出平均均方误差 print("Average Mean Squared Error:", sum(mse_scores)/len(mse_scores))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这段代码首先生成了一个具有100个样本的回归问题数据集,然后定义了一个线性回归模型,并使用5折交叉验证来评估模型的性能,输出所有轮次的平均均方误差。这样,我们就可以基于这个综合指标来判断模型在未知数据上的预测能力。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/953982
推荐阅读
相关标签

